
本文介绍MaxCompute查询加速MaxQA引擎(MaxCompute Query Accelerator 2.0)功能,包括系统架构、应用场景、使用限制和使用方法。
MaxQA功能正式商业化,欢迎使用。如有相关问题可提交工单,MaxCompute技术团队将协助解决。
更多公测及具体功能介绍,请参见查询加速MaxQA操作指南。
功能介绍
MaxQA(MaxCompute Query Accelerator 2.0,原MCQA2.0)是阿里云MaxCompute推出的一款查询加速解决方案,旨在满足日益增长的实时、近实时数据分析需求。基于独享的加速资源池,通过对管控链路、查询优化器、执行引擎、存储引擎及缓存机制的全方位优化,显著降低查询响应时间。特别适用于BI场景、交互式分析以及近实时数仓等对延迟要求高且稳定的场景。
MaxCompute MaxQA(原MCQA2.0)功能提供如下能力:
高性能查询与插入
针对TB级别内的数据量,为查询和数据插入作业提供加速优化,最快执行时间可达亚秒级。
SQL兼容性
完全兼容MaxCompute的SQL功能,包括UDF、Delta Table、Delta Live MV增量物化视图特性等。
资源隔离与弹性管理
支持隔离的查询加速资源池,独享服务于本租户,稳定性更高。
支持自定义查询加速资源池和批处理资源池的分时资源分配规则,支持交互式Quota组和批处理Quota组的分时自动伸缩,提高资源整体利用率。
支持全链路Cache,作业会自动将多个环节的执行结果写入临时缓存,后续执行的作业在全链路的多个环节都可能命中Cache,加快执行速度。
多款BI工具支持(FineBI、Tableau、QuickBI)。
适用范围
仅支持在MaxQA中执行DDL/DML/DQL语句(如权限操作语句、Tunnel相关语句、上传/下载资源等)。
在MaxQA中支持运行用户定义函数(UDF),但这将涉及在现场启动UDF的安全隔离环境。为了防止性能出现剧烈波动,一个MaxQA实例中最多仅限于使用50%的资源来运行UDF。
对于DQL语句,默认最多返回100万行数据,可通过将
odps.sql.select.auto.limit参数设置为更大的值来突破此限制(建议根据业务实际需求谨慎设置,过大的返回值可能影响执行效率)。暂不支持执行计划中要求Worker常驻的作业,如Distributed MapJoin。
如果因上述限制导致MaxQA作业失败,需要手动重试或尝试将作业提交到批处理配额组中。
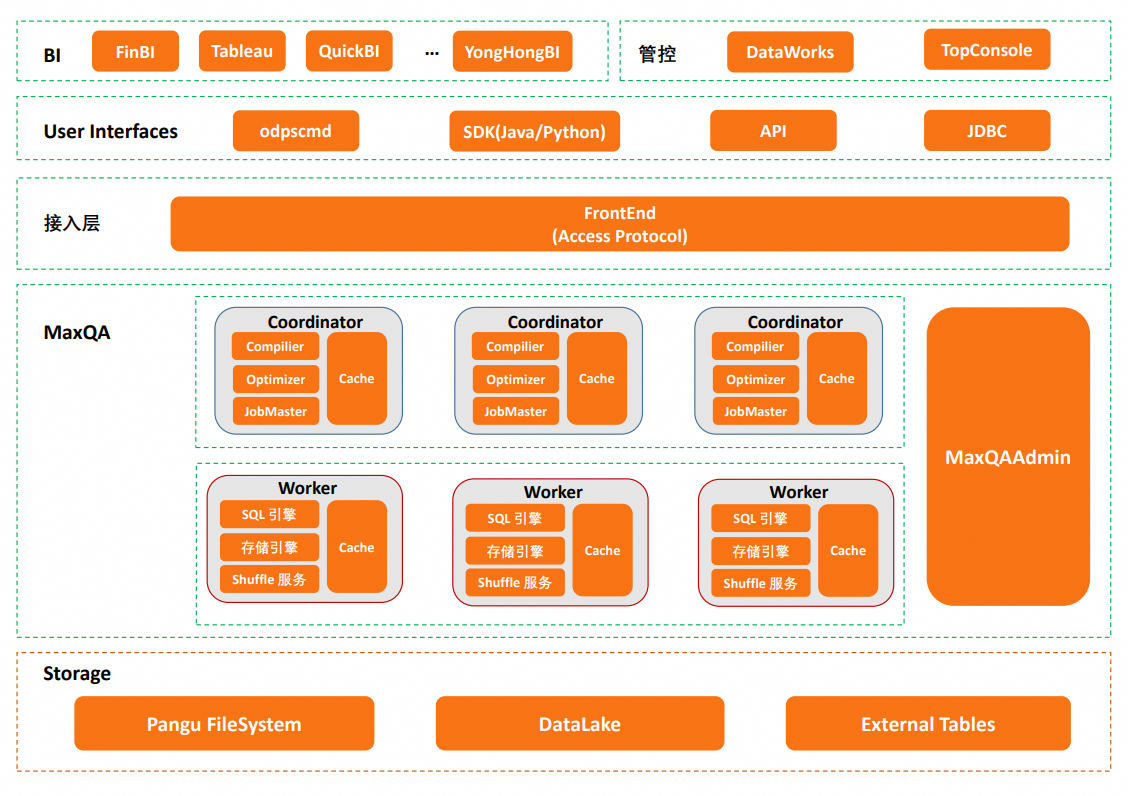
产品架构
MaxQA的核心技术优势是通过智能化动态隔离的资源池、全链路缓存Cache机制、本地化IO、面向延迟优化的执行计划(QueryPlan)以及更高效的执行引擎来提高查询效率。
智能化动态隔离的资源池
每个MaxQA实例是完全隔离的计算环境,一个租户可以创建多个实例(对应多个交互式Quota组),避免了多租户环境中常见的干扰问题,确保查询延迟稳定。
全链路缓存机制
作业扫描过的表及元数据、生成的执行计划、执行过程中多个环节的中间结果及查询结果都会自动缓存,后续执行的作业在全链路的多个环节都可能命中Cache,加快执行速度。由于是实例级别隔离的计算环境,缓存具有更长的有效期,不会被其他实例的作业影响。
本地化IO
最大限度地将源表读取在执行过程中的 Shuffle、Spill 等操作的IO数据都保留在本地存储设备上,以减少对外部系统的依赖,提高延迟稳定性。
面向延迟优化的执行计划
从物理执行计划选择、并发度计算、压缩算法选择等多个维度均以延迟优先。
简化管控链路
前端直接连接协调器,控制链路架构优化以及异步化改造,提升交互效率。
MaxQA技术架构图如下所示。
应用场景
MaxQA功能的应用场景涵盖了从日常运营报告到高级数据分析的各种需求,特别适合对查询响应时间和稳定性有较高要求的业务场景。无论是短期决策支持还是长期战略规划,MaxQA都能为企业提供强有力的技术支撑,提升数据驱动的价值创造能力。
场景 | 说明 | 场景特点 | 示例 |
即席查询(Ad Hoc) | 用户可以根据实际需求灵活选择查询条件,快速获取查询结果并调整查询逻辑。适用于数据开发或数据分析人员,他们希望使用熟悉的客户端工具开展查询分析。 | • 查询时延要求在几秒或几十秒内。 • 使用者通常为掌握SQL技能的数据开发或数据分析师。 • 灵活选择查询条件,快速响应业务需求变化。 | • 数据科学家进行探索性数据分析。 • 数据工程师调试ETL流程中的临时查询。 |
商业智能(BI) | 利用MaxCompute搭建企业级数据仓库,通过ETL将数据加工处理为面向业务可消费的聚合数据。借助MaxQA的低延时、资源隔离、弹性并发、数据缓存等特性,满足多并发、快速响应的报告生成、统计分析及固定报表分析需求。 | • 查询的数据对象通常为聚合后的结果数据。 • 适用于数据量较小、多维查询、固定查询、高频查询场景。 • 查询延时要求高,秒级返回(例如大部分查询不超过5秒)。 | • 生成每日销售报告。 • 实时监控关键业务指标。 • 定期生成财务报表。 |
交互式数据分析 | 自助式 BI 工具和交互式数据探索平台使得非技术人员也能轻松进行复杂的数据分析。这类工具通常通过一系列短查询来实现动态筛选、排序、聚合等功能,提供灵活且直观的操作体验。 | • 支持拖拽式操作,无需编写复杂的 SQL 语句。 • 快速反馈查询结果,帮助用户迭代分析过程。 • 适用于各种层次的数据分析师,从初学者到专家。 | • 使用Tableau或Fine BI进行可视化分析。 • 在线数据分析平台上的数据探索。 |
海量数据明细查询分析 | MaxQA 可以自动识别查询作业特征,既能快速响应处理小规模作业,同时还可以自动匹配大规模作业资源需求,满足分析人员分析不同规模和复杂度的查询作业的需求。 | • 需要探索的历史数据量大,但真正需要的有效数据量不大。 • 查询延时要求适中,介于即时性和批量处理之间。 • 使用者通常为业务分析人员,他们需要从明细数据中探寻业务规律,发现业务机会,验证业务假设。 | • 用户行为路径分析。 • 客户细分与画像构建。 • 产品使用模式挖掘。 |
不同CU规格对应的系统参数说明
CU数 | 最大并行作业数 | 作业默认超时时间(min) | 单作业并发度上限 |
25CU | 25CU | 120min | CU 数 * 30 |
50CU | 50CU | 120min | CU 数 * 30 |
75CU | 75CU | 120min | CU 数 * 30 |
100CU | 100CU | 120min | CU 数 * 30 |
125CU | 125CU | 120min | CU 数 * 30 |
150CU | 150CU | 120min | CU 数 * 30 |
200CU | 200CU | 120min | CU 数 * 30 |
[200, 600)CU | 和 CU 数一致 | 120min | CU 数 * 30 |
[600, 1000)CU | 和 CU 数一致 | 120min | CU 数 * 30 |
[1000, 2000)CU | 和 CU 数一致 | 240min | CU 数 * 30 |
[2000, 3000)CU | 和 CU 数一致 | 360min | CU 数 * 30 |
[3000, 4000)CU | 和 CU 数一致 | 480min | CU 数 * 30 |
[4000, 5000)CU | 和 CU 数一致 | 600min | CU 数 * 30 |
[5000, 6000)CU | 和 CU 数一致 | 720min | CU 数 * 30 |
TPC-DS性能测试结果
不同地域的结果略有区别,以实际测试为准。
规格 | 10GB | 100GB | 1TB |
25CU | 550s | 498s | 3634s |
50CU | 203s | 295s | 1531s |
100CU | 198s | 260s | 692s |
以上性能测试报告是基于华北2(北京)地域的测试环境获得。
详细测试方案与内容请参见TPC-DS性能测试。
和MCQA(原查询加速,已停止新开放)的能力对比优化
对比项 | MCQA | MaxQA(MCQA2.0) |
架构 | 基于Serverless资源池。 | 单租隔离计算环境。 |
延迟稳定性 | 一般。 | 好。 |
计算性能 | 比离线模式明显好,但稳定性不够。 | 汇集了多项优化,性能更优。 |
支持的作业类型 | 仅支持DQL。 | 全类型的SQL能力,包括 DDL、DQL、DML。 |
使用方式 | 打开交互式模式。 | 提交作业时指定交互式Quota组的名称,详情请参见MaxQA功能接入方式。 |
Quota 路由 | 支持。 | 暂不支持。 |
后付费模式 | 支持。 | 暂不支持。 |
Session概念 | 有,同一客户端相邻时段提升的作业可能归属一个Session,每个Session对应一个Instance ID。 | 无,每个SQL作业都对应一个Instance ID。 |
回退机制 | 有自动回退批处理模式的能力。 | 不支持自动回退。 |
使用方法
MaxQA的具体使用方法请参见查询加速MaxQA操作指南。