
Delta Lake和Hudi是数据湖方案中常用的存储机制,为数据湖提供流处理、批处理能力。MaxCompute基于开源的Hadoop集群提供了支持Delta或Hudi存储机制的湖仓一体架构。您可以通过MaxCompute查询到实时数据,即时洞察业务数据变化。
背景信息
MaxCompute基于开源的Hadoop集群和阿里云EMR(E-MapReduce)提供了支持Delta Lake和Hudi存储机制的湖仓一体架构。架构图如下:
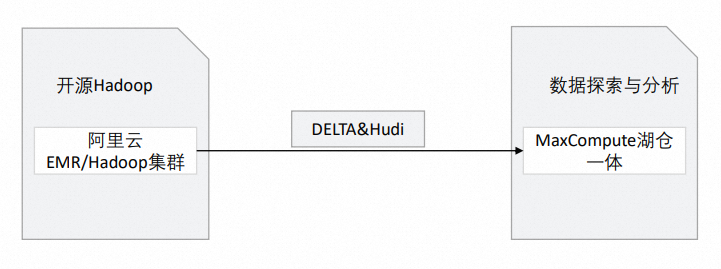
涉及模块 | 对应阿里云产品 | 说明 |
开源Hadoop |
| 原始数据存储在Hadoop集群中。 |
基于Hadoop集群支持Delta Lake或Hudi湖仓一体架构
前提条件
已创建MaxCompute项目(非External Project)。具体操作请参见创建MaxCompute项目。
使用限制
基于Hadoop集群支持Delta Lake或Hudi存储机制湖仓一体方案,使用限制如下:
仅华东1(杭州)、华东2(上海)、华北2(北京)、华南1(深圳)、中国香港、新加坡和德国(法兰克福)地域支持构建湖仓一体能力。
操作流程
本文以阿里云EMR的Hadoop集群为例,构建Hadoop集群的湖仓一体。操作流程如下:
若已有本地机房搭建或云上虚拟机搭建的Hadoop集群,无需再次创建。
在集群中创建数据库,准备数据。
步骤三:基于MaxCompute实时分析Hadoop集群数据。
通过DataWorks控制台的数据湖集成界面创建External Project,对Hadoop集群数据进行分析。
步骤一:创建EMR集群
在EMR控制台创建Hadoop集群。
创建Hadoop集群的具体操作请参考创建EMR集群。在创建Hadoop集群的过程中,您需要重点关注以下配置项,其余配置项可参考EMR集群:
配置区域
配置项
示例
描述
软件配置
业务场景
自定义集群
请根据实际需求选择业务场景。
产品版本
EMR-3.43.0
选择基于Hadoop 2.x和Hive 2.x构建的EMR-3.x版本。
可选服务
Hadoop-Common、HDFS、Hive、YARN、Spark3、DeltaLake、Hudi、ZooKeeper
选择相关的Hadoop、HDFS、Hive、Spark、DeltaLake及Hudi组件,被选中的组件会默认启动相关的服务进程。
元数据
内置MySQL
选择内置MySQL或者自建RDS。
自建RDS:表示使用自建的阿里云RDS作为元数据库。
选择该方式时,需要配置相关的数据库连接参数,详情请参见配置自建RDS。
内置MySQL:表示元数据存储在集群本地环境的MySQL数据库中。
说明仅限在测试场景下使用该方式,生产场景建议选择自建RDS。
集群创建成功后,单击目标集群操作列的节点管理。
在节点管理页面,单击emr-master节点组下的目标节点ID,进入ECS控制台。
选择合适的工具,连接节点ECS实例,详情请参见ECS远程连接方式概述。
说明本文使用Workbench远程连接实例,登录密码为创建集群时所设置的密码。
步骤二:准备数据
登录集群后,可以通过Spark SQL方式创建Delta Lake表和Hudi表。
E-MapReduce的Hudi 0.8.0版本支持Spark SQL对Hudi进行读写操作,详情请参见Hudi与Spark SQL集成。本文以创建Hudi表为例,在终端输入如下命令启动spark-sql。
spark-sql \ --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \ --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'进入spark-sql后,建表并插入数据,命令如下。
说明若没有新建数据库,则默认数据会被存储在default库中。
-- 建表 CREATE TABLE h0 ( id BIGINT, name STRING, price DOUBLE, ts LONG ) USING hudi tblproperties ( primaryKey="id", preCombineField="ts" ); -- 插入数据 INSERT INTO h0 VALUES (1, 'a1', 10, 1000); -- 查表 SELECT id, name, price, ts FROM h0;
步骤三:基于MaxCompute实时分析Hadoop集群数据
基于已创建的MaxCompute项目以及Hadoop集群表数据,再创建External Project,用于Hadoop集群,并映射至已创建的MaxCompute项目。后续可通过映射的MaxCompute项目对External Project进行数据分析操作。仅MaxCompute项目的所有者(Project Owner)或具备Admin、Super_Administrator角色的用户可以创建External Project。
Tenant的Super_Administrator角色可以在MaxCompute控制台的用户管理页签授权。仅主账号或已经拥有Tenant的Super_Administrator角色的子账号可以操作授权。详情请参见将角色赋予用户。
在DataWorks控制台创建External Project。
登录DataWorks控制台,选择地域。
在左侧导航栏,选择。
在数据湖集成(湖仓一体)页面,单击现在开始创建。
在新建数据湖集成页面,按照界面指引进行操作。参数示例如下所示。
单击完成创建并预览后,再单击预览。如果能预览Hadoop集群中数据库表的信息,则表示操作成功。
说明上述使用的External Project是在DataWorks控制台创建的,如果您需要通过SQL方式管理External Project,请参见使用SQL管理外部项目。
在DataWorks临时查询页面,新建ODPS SQL节点,查看External Project下的表。命令示例如下。
SHOW TABLES IN test_extproject_ddd; -- 返回结果如下 ALIYUN$***@test.aliyunid.com:h0说明DataWorks临时查询操作请参见使用临时查询快速查询SQL(可选)。
在DataWorks临时查询页面,查询External Project的表数据。命令示例如下。
SELECT * FROM test_extproject_ddd.h0;返回结果:

通过Workbench登录Hadoop集群,进入Spark SQL的终端,在命令执行区域,输入SQL语句更新h0表中的数据。命令如下。
INSERT INTO h0 VALUES (2, 'a2', 11, 1000);在DataWorks临时查询页面,查看数据更新结果。命令示例如下。
SELECT * FROM test_extproject_ddd.h0 WHERE id ='2';返回结果:

相关文档
通过MaxCompute与Hadoop构建湖仓一体的最佳实践,请参见MaxCompute+Hadoop搭建实践。
若您想通过MaxCompute与DLF和OSS构建湖仓一体,可参见基于DLF、RDS或Flink、OSS支持Delta Lake或Hudi存储机制。