MaxCompute支持您将MaxCompute项目中的数据导出至外部存储(OSS、Hologres),以供其他计算引擎使用。本文为您介绍UNLOAD命令的使用方法及具体示例。
本文中的命令您可以在如下工具平台执行:
功能介绍
MaxCompute支持使用unload命令将MaxCompute的数据导出至OSS、Hologres外部存储,OSS支持以CSV格式或其他开源格式存储数据。其中:
MaxCompute的数据需要先导出至OSS中,才可以通过OSS导出至其他计算引擎,例如Amazon Redshift和BigQuery。
重复导出不会覆盖已导出的文件,会追加新的导出文件。
使用限制
UNLOAD命令的使用限制如下:
导出至OSS的文件的分割方式和文件名称由系统自动生成,不支持自定义导出文件名称或文件后缀。
将MaxCompute数据导出至Hologres中,不支持使用双签名授权模式。
不支持将MaxCompute数据导出至Hologres分区表中。
导出的开源格式文件不支持添加后缀名。
注意事项
UNLOAD命令本身不计费,UNLOAD命令中的查询子句需要扫描数据并使用计算资源计算结果,因此查询子句按照普通SQL作业计费。
通过OSS存储结构化数据在一些场景中可以节省存储费用,但需要提前做好费用估算。
MaxCompute存储费用为0.12元/GB/月,更多存储计费信息,请参见存储费用。数据导入MaxCompute后有5倍左右的压缩率,计费依据的数据量是压缩后的数据。
OSS存储标准型单价为0.12元/GB/月,另有其他低频访问型、归档型、冷归档型存储,请参见存储费用。
如果您导出数据只是为了节省存储费用,建议您根据数据特征测试估算压缩率,根据导出时的查询语句估算UNLOAD费用,以及后续对导出数据的访问方式进行合理评估,避免因不必要的数据迁移产生额外费用。
前提条件
操作账号已具备MaxCompute的相关权限。
执行
unload操作前,操作账号需要具备MaxCompute项目中待导出表数据的读取权限(Select)。授权操作请参见MaxCompute权限。操作账号已具备外部存储数据对应数据源的相关权限。
从MaxCompute导出数据至外部存储前,您需要先对外部存储(OSS或Hologres)进行授权,允许MaxCompute访问外部存储。
unload命令的授权模式沿用了MaxCompute外部表的授权模式,OSS和Hologres的授权引导如下。外部存储:OSS
您可以一键授权,具备更高安全性。详情请参见STS模式授权。
说明本文示例采用一键授权方式,角色名称定义为AliyunODPSDefaultRole。
外部存储:Hologres
您可创建一个RAM角色,为其授权允许MaxCompute访问的权限,并将角色添加至Hologres实例,完成授权,操作详情请参见创建Hologres外部表(STS模式)。
完成上述授权的前期准备后,您需要根据导出数据的格式类型,选择对应的导出方式:
通过内置Extractor导出(StorageHandler)
命令格式
UNLOAD FROM {<select_statement>|<table_name> [PARTITION (<pt_spec>)]} INTO LOCATION <external_location> STORED BY <StorageHandler> [WITH SERDEPROPERTIES ('<property_name>'='<property_value>',...)];参数说明
外部存储:OSS
参数
是否必填
说明
select_statement
否
SELECT查询子句,从源表(分区表或非分区表)中查询需要插入目标OSS路径的数据。更多SELECT信息,请参见SELECT语法。
table_name、pt_spec
否
使用表名称或表名称加分区名称的方式指定需要导出的数据。该导出方式不产生查询语句,不会产生费用。pt_spec格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。external_location
是
指定导出数据存储的目标OSS路径,格式为
'oss://<oss_endpoint>/<object>'。更多OSS路径信息,请参见通过IPv6协议访问OSS。StorageHandler
是
指定内置的StorageHandler名称。固定取值为
com.aliyun.odps.CsvStorageHandler或com.aliyun.odps.TsvStorageHandler,是内置的处理CSV、TSV格式文件的StorageHandler,定义了如何读或写CSV、TSV文件。相关逻辑已经由系统实现,您只需要指定该参数。此方法导出的文件默认添加.csv、.tsv后缀名。使用方法和MaxCompute外部表一致,请参见创建OSS外部表。'<property_name>'='<property_value>'
否
property_name为属性名称,property_value为属性值。支持的属性和MaxCompute外部表一致。更多属性信息,请参见创建OSS外部表。
外部存储:Hologres
参数
是否必填
说明
select_statement
否
SELECT查询子句,从源表(非分区表)中查询需要插入目标Hologres路径的数据。更多SELECT信息,请参见SELECT语法。table_name
否
使用表名称的方式指定需要导出的数据。该导出方式不产生查询语句,不会产生费用。
external_location
是
指定导出数据存储的目标Hologres路径,格式为
'jdbc:postgresql://<endpoint>:<port>/<database>?ApplicationName=MaxCompute&[currentSchema=<schema>&][useSSL={true|false}&]table=<holo_table_name>/'。更多Hologres路径信息,请参见创建Hologres外部表。StorageHandler
是
指定内置的StorageHandler名称。固定取值为
com.aliyun.odps.jdbc.JdbcStorageHandler,使用JdbcStorageHandler连接方式。'<property_name>'='<property_value>'
否
property_name为属性名称,property_value为属性值。数据导出至Hologres必填如下参数:
'odps.properties.rolearn'='<ram_arn>':指定RAM角色的ARN信息,用于STS认证。您可以在RAM访问控制页面,单击目标RAM角色名称后,在基本信息区域获取。
'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver':指定连接Hologres数据库的驱动程序。固定取值为
org.postgresql.Driver。'odps.federation.jdbc.target.db.type'='holo':指定连接的数据库类型。固定取值为
holo。
Hologres支持的属性和MaxCompute外部表一致。更多属性信息,请参见创建Hologres外部表。
使用示例
外部存储:OSS
假设将MaxCompute项目中表sale_detail的数据导出至OSS。sale_detail的数据如下:
+------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | | null | c5 | NULL | 2014 | shanghai | | s6 | c6 | 100.4 | 2014 | shanghai | | s7 | c7 | 100.5 | 2014 | shanghai | +------------+-------------+-------------+------------+------------+登录OSS管理控制台,创建OSS Bucket目录
mc-unload/data_location/,区域为oss-cn-hangzhou,并组织OSS路径。更多创建OSS Bucket信息,请参见控制台创建存储空间。
根据Bucket、区域、Endpoint信息组成OSS路径如下:
oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location登录MaxCompute客户端,执行UNLOAD命令,将sale_detail表的数据导出至OSS。命令示例如下:
示例1:将sale_detail表中的数据导出为CSV格式并压缩为GZIP。命令示例如下。
--控制导出文件个数:设置单个Worker读取MaxCompute表数据的大小,单位为MB。由于MaxCompute表有压缩,导出到OSS的数据一般会膨胀4倍左右。 SET odps.stage.mapper.split.size=256; --导出数据。 UNLOAD FROM (SELECT * FROM sale_detail) INTO LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location' STORED BY 'com.aliyun.odps.CsvStorageHandler' WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole', 'odps.text.option.gzip.output.enabled'='true'); --等效于如下语句。 SET odps.stage.mapper.split.size=256; UNLOAD FROM sale_detail INTO LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location' STORED BY 'com.aliyun.odps.CsvStorageHandler' WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole', 'odps.text.option.gzip.output.enabled'='true');示例2:将sale_detail表中分区为sale_date='2013',region='china'的数据导出为TSV格式并压缩为GZIP。
--控制导出文件个数:设置单个Worker读取MaxCompute表数据的大小,单位为MB。由于MaxCompute表有压缩,导出到OSS的数据一般会膨胀4倍左右。 SET odps.stage.mapper.split.size=256; --导出数据。 UNLOAD FROM sale_detail PARTITION (sale_date='2013',region='china') INTO LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location' STORED BY 'com.aliyun.odps.TsvStorageHandler' WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole', 'odps.text.option.gzip.output.enabled'='true');
'odps.text.option.gzip.output.enabled'='true'用于指定导出文件为GZIP压缩格式,当前仅支持GZIP压缩格式。登录OSS管理控制台,查看目标OSS路径的导入结果。
示例1结果如下。

示例2结果如下。

外部存储:Hologres
假设将MaxCompute项目中表
data_test的数据导出至Hologres。data_test的数据如下:+------------+------+ | id | name | +------------+------+ | 3 | rgege | | 4 | Gegegegr | +------------+------+在Hologres创建数据接收表
mc_2_holo(所在数据库名称为test),您可以在HoloWeb的SQL编辑器中执行建表语句,详情请参见连接HoloWeb并执行查询。建表语句如下:说明数据接收表的字段类型需与MaxCompute表字段类型对应,详情请参见MaxCompute与Hologres的数据类型映射。
CREATE TABLE mc_2_holo (id INT, name TEXT);登录MaxCompute客户端,执行UNLOAD命令,将
data_test表的数据导出至Hologres。命令示例如下:UNLOAD FROM (SELECT * FROM data_test) INTO LOCATION 'jdbc:postgresql://hgprecn-cn-5y**********-cn-hangzhou-internal.hologres.aliyuncs.com:80/test?ApplicationName=MaxCompute¤tSchema=public&useSSL=false&table=mc_2_holo/' STORED BY 'com.aliyun.odps.jdbc.JdbcStorageHandler' WITH SERDEPROPERTIES ( 'odps.properties.rolearn'='acs:ram::13**************:role/aliyunodpsholorole', 'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver', 'odps.federation.jdbc.target.db.type'='holo' );在Hologres中查询导出数据:
SELECT * FROM mc_2_holo;返回结果示例如下:
id name 4 Gegegegr 3 rgege
导出其他开源格式数据
命令格式
UNLOAD FROM {<select_statement>|<table_name> [PARTITION (<pt_spec>)]} INTO LOCATION <external_location> [ROW FORMAT SERDE '<serde_class>' [WITH SERDEPROPERTIES ('<property_name>'='<property_value>',...)] ] STORED AS <file_format> [PROPERTIES ('<tbproperty_name>'='<tbproperty_value>')];参数说明
参数
是否必填
说明
select_statement
否
SELECT查询子句,从源表(分区表或非分区表)中查询需要插入目标OSS路径的数据。更多SELECT信息,请参见SELECT语法。
table_name、pt_spec
否
使用表名称或表名称加分区名称的方式指定需要导出的数据。该导出方式不产生查询语句,不会产生费用。pt_spec格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。external_location
是
指定导出数据存储的目标OSS路径,格式为
'oss://<oss_endpoint>/<object>'。更多OSS路径信息,请参见通过IPv6协议访问OSS。serde_class
否
使用方法和MaxCompute外部表一致,请参见创建OSS外部表。
'<property_name>'='<property_value>'
否
property_name为属性名称,property_value为属性值。支持的属性和MaxCompute外部表一致。更多属性信息,请参见创建OSS外部表。
file_format
是
指定导出数据文件格式。例如ORC、PARQUET、RCFILE、SEQUENCEFILE和TEXTFILE。使用方法和MaxCompute外部表一致,请参见创建OSS外部表。
'<tbproperty_name>'='<tbproperty_value>'
否
tbproperty_name为外部表扩展信息属性名称,tbproperty_value为外部表扩展信息属性值。例如开源数据支持导出SNAPPY或LZO压缩格式,设置压缩属性为
'mcfed.parquet.compression'='SNAPPY'或'mcfed.parquet.compression'='LZO'。使用示例
假设将MaxCompute项目中表sale_detail的数据导出至OSS。sale_detail的数据如下:
+------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | | null | c5 | NULL | 2014 | shanghai | | s6 | c6 | 100.4 | 2014 | shanghai | | s7 | c7 | 100.5 | 2014 | shanghai | +------------+-------------+-------------+------------+------------+登录OSS管理控制台,创建OSS Bucket目录
mc-unload/data_location/,区域为oss-cn-hangzhou,并组织OSS路径。更多创建OSS Bucket信息,请参见控制台创建存储空间。根据Bucket、区域、Endpoint信息组成OSS路径如下:
oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location登录MaxCompute客户端,执行UNLOAD命令,将sale_detail表的数据导出至OSS。命令示例如下:
示例1:将sale_detail表中的数据导出为PARQUET格式并压缩为SNAPPY。命令示例如下。
--控制导出文件个数:设置单个Worker读取MaxCompute表数据的大小,单位为MB。由于MaxCompute表有压缩,导出到OSS的数据一般会膨胀4倍左右。 SET odps.stage.mapper.split.size=256; --导出数据。 UNLOAD FROM (SELECT * FROM sale_detail) INTO LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location' ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole') STORED AS PARQUET PROPERTIES('mcfed.parquet.compression'='SNAPPY');示例2:将sale_detail表中分区为sale_date='2013',region='china'的数据导出为PARQUET格式并压缩为SNAPPY。命令示例如下。
--控制导出文件个数:设置单个Worker读取MaxCompute表数据的大小,单位为MB。由于MaxCompute表有压缩,导出到OSS的数据一般会膨胀4倍左右。 SET odps.stage.mapper.split.size=256; --导出数据。 UNLOAD FROM sale_detail PARTITION (sale_date='2013',region='china') INTO LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location' ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole') STORED AS PARQUET PROPERTIES('mcfed.parquet.compression'='SNAPPY');
登录OSS管理控制台,查看目标OSS路径的导入结果。
示例1结果如下。

示例2结果如下。

说明以SNAPPY或LZO压缩格式导出数据时,导出文件不支持显示.snappy或.lzo后缀名。
Unload函数导出设置前后缀
使用unload命令将MaxCompute的表导出为文件时,有的业务场景需要指定文件的前缀与后缀,按照下列的操作可以自定义文件的前缀,以及默认生成对应文件格式的后缀。
语法说明。
内置解析器导出csv、tsv等格式文件。
--内置解析器,导出csv,tsv等格式 UNLOAD FROM {<select_statement>|<table_name> [PARTITION (<pt_spec>)]} INTO LOCATION <external_location> [STORED BY <StorageHandler>] [WITH SERDEPROPERTIES ('<property_name>'='<property_value>',...)];设置前缀的property_name为:odps.external.data.prefix,值可以自定义,长度不超过10个字符。
设置后缀的property_name为:odps.external.data.enable.extension,值为
true即后缀显示文件格式。其他参数请参见通过内置Extractor导出(StorageHandler)。
导出orc、parquet等开源格式文件。
UNLOAD FROM {<select_statement>|<table_name> [PARTITION (<pt_spec>)]} INTO LOCATION <external_location> [ROW FORMAT SERDE '<serde_class>' [WITH SERDEPROPERTIES ('<property_name>'='<property_value>',...)] ] STORED AS <file_format> [PROPERTIES('<tbproperty_name>'='<tbproperty_value>')];设置前缀的tbproperty_name为:odps.external.data.prefix,值可以自定义,长度不超过10个字符。
设置后缀的tbproperty_name为:odps.external.data.enable.extension,值为
true即后缀显示文件格式。其他参数请参见导出其他开源格式数据。
后缀参考。
文件格式
SerDe
后缀
SEQUENCEFILE
org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
.sequencefile
TEXTFILE
org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
.txt
RCFILE
org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe
.rcfile
ORC
org.apache.hadoop.hive.ql.io.orc.OrcSerde
.orc
PARQUET
org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
.parquet
AVRO
org.apache.hadoop.hive.serde2.avro.AvroSerDe
.avro
JSON
org.apache.hive.hcatalog.data.JsonSerDe
.json
CSV
org.apache.hadoop.hive.serde2.OpenCSVSerde
.csv
使用示例。
导出text格式文件,并添加
mf_前缀和后缀。SET odps.sql.hive.compatible=true; SET odps.sql.split.hive.bridge=true; UNLOAD FROM (SELECT col_tinyint,col_binary FROM mf_fun_datatype LIMIT 1) INTO LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/mfosscostfee/demo6/' STORED AS textfile PROPERTIES ('odps.external.data.prefix'='mf_', 'odps.external.data.enable.extension'='true');在指定导出数据存储的目标OSS路径查看导出结果。
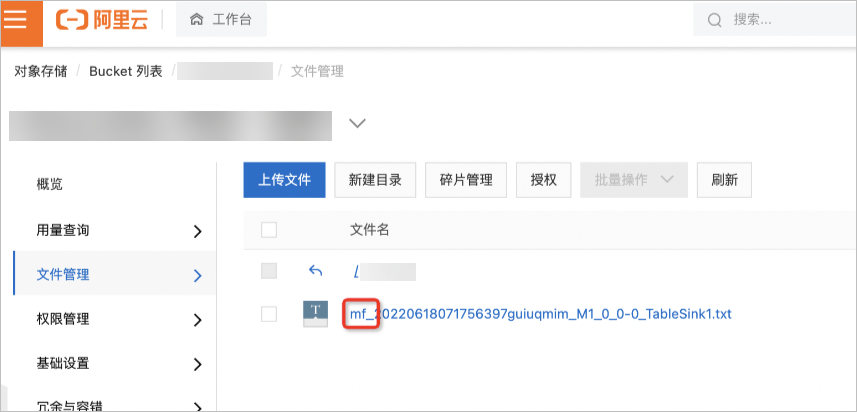
导出csv格式文件,并添加
mf_前缀和后缀。SET odps.sql.hive.compatible=true; SET odps.sql.split.hive.bridge=true; UNLOAD FROM (SELECT col_tinyint,col_binary FROM mf_fun_datatype LIMIT 2) INTO LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/mfosscostfee/demo6/' STORED BY 'com.aliyun.odps.CsvStorageHandler' PROPERTIES ('odps.external.data.prefix'='mf_', 'odps.external.data.enable.extension'='true');在指定导出数据存储的目标OSS路径查看导出结果。
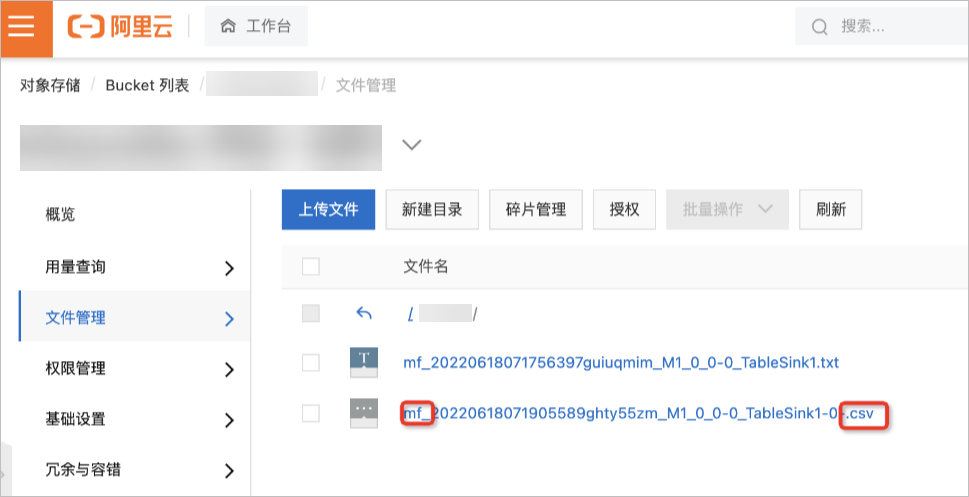
后续操作:通过OSS将数据导出至下游系统
MaxCompute 可以借助 OSS 作为中间过渡格式,将数据导出到多种不被直接支持的数据库中(例如,时序数据库InfluxDB)。具体实现步骤包括:
使用
UNLOAD命令将数据导出到 OSS。下载 OSS 数据到本地环境。
使用目标数据库的导入工具或命令完成数据加载。
相关文档
若您希望将外部存储上的CSV格式或其他开源格式数据导入至MaxCompute,请参见LOAD。