
本文为您介绍如何使用DataWorks的PyODPS节点处理PyODPS的空值。
前提条件
您需要完成以下操作:
在DataWorks上完成业务流程创建,本例使用DataWorks简单模式。详情请参见创建业务流程。
操作步骤
准备测试数据。
登录DataWorks控制台。
创建表并上传数据。操作方法请参见建表并上传数据。
表pytable2的建表语句如下。
CREATE TABLE `pytable2` ( `id` string, `name` string, `f1` double, `f2` double, `f3` double, `f4` double ) ;示例数据文件pytable2.txt的内容如下。
0, name1, 1.0, NaN, 3.0, 4.0 1, name1, 2.0, NaN, NaN, 1.0 2, name1, 3.0, 4.0, 1.0, NaN 3, name1, NaN, 1.0, 2.0, 3.0 4, name1, 1.0, NaN, 3.0, 4.0 5, name1, 1.0, 2.0, 3.0, 4.0 6, name1, NaN, NaN, NaN, NaN
在左侧导航栏上单击工作空间。
选择操作列中的。
在数据开发页面,右键单击已经创建的业务流程,选择。
在新建节点对话框,输入节点名称,并单击确认。
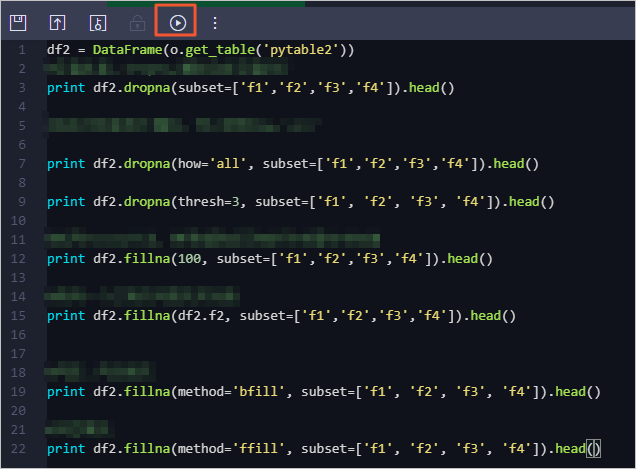
在PyODPS 2节点中输入空值处理代码。
示例代码如下。
df2 = DataFrame(o.get_table('pytable2')) #dropna方法,删除包含空值的行。 print df2.dropna(subset=['f1','f2','f3','f4']).head() #包含非空值则不删除,可以使用how='all'。 print df2.dropna(how='all', subset=['f1','f2','f3','f4']).head() print df2.dropna(thresh=3, subset=['f1', 'f2', 'f3', 'f4']).head() #fillna方法,使用常数或已有的列填充未知值。 print df2.fillna(100, subset=['f1','f2','f3','f4']).head() #使用一个已有的列填充未知值。 print df2.fillna(df2.f2, subset=['f1','f2','f3','f4']).head() #向前填充。 print df2.fillna(method='bfill', subset=['f1', 'f2', 'f3', 'f4']).head() #向后填充。 print df2.fillna(method='ffill', subset=['f1', 'f2', 'f3', 'f4']).head()单击运行。
在运行日志中查看运行结果。
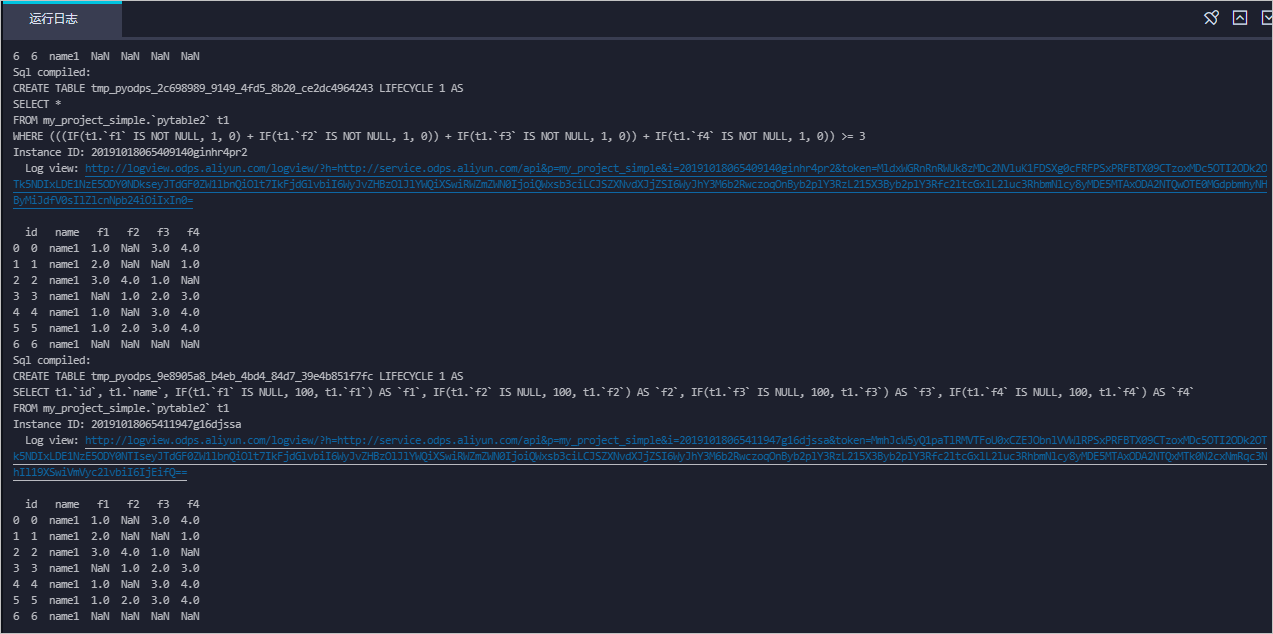
完整的运行结果如下。
Sql compiled: CREATE TABLE tmp_pyodps_d0c7d8c2_be38_4d48_b0eb_e89bae5bde01 LIFECYCLE 1 AS SELECT * FROM WB_BestPractice_dev.`pytable2` t1 WHERE (((IF(t1.`f1` IS NOT NULL, 1, 0) + IF(t1.`f2` IS NOT NULL, 1, 0)) + IF(t1.`f3` IS NOT NULL, 1, 0)) + IF(t1.`f4` IS NOT NULL, 1, 0)) >= 4 Instance ID: 20191010071154980g2hic292 id name f1 f2 f3 f4 0 0 name1 1.0 NaN 3.0 4.0 1 1 name1 2.0 NaN NaN 1.0 2 2 name1 3.0 4.0 1.0 NaN 3 3 name1 NaN 1.0 2.0 3.0 4 4 name1 1.0 NaN 3.0 4.0 5 5 name1 1.0 2.0 3.0 4.0 6 6 name1 NaN NaN NaN NaN Sql compiled: CREATE TABLE tmp_pyodps_49b46768_f589_48f6_be8a_b7139f31f6f2 LIFECYCLE 1 AS SELECT * FROM WB_BestPractice_dev.`pytable2` t1 WHERE (((IF(t1.`f1` IS NOT NULL, 1, 0) + IF(t1.`f2` IS NOT NULL, 1, 0)) + IF(t1.`f3` IS NOT NULL, 1, 0)) + IF(t1.`f4` IS NOT NULL, 1, 0)) >= 1 Instance ID: 20191010071159759g0dk9592 id name f1 f2 f3 f4 0 0 name1 1.0 NaN 3.0 4.0 1 1 name1 2.0 NaN NaN 1.0 2 2 name1 3.0 4.0 1.0 NaN 3 3 name1 NaN 1.0 2.0 3.0 4 4 name1 1.0 NaN 3.0 4.0 5 5 name1 1.0 2.0 3.0 4.0 6 6 name1 NaN NaN NaN NaN Sql compiled: CREATE TABLE tmp_pyodps_7f941800_1539_415b_9257_283ebeb893a6 LIFECYCLE 1 AS SELECT * FROM WB_BestPractice_dev.`pytable2` t1 WHERE (((IF(t1.`f1` IS NOT NULL, 1, 0) + IF(t1.`f2` IS NOT NULL, 1, 0)) + IF(t1.`f3` IS NOT NULL, 1, 0)) + IF(t1.`f4` IS NOT NULL, 1, 0)) >= 3 Instance ID: 20191010071204544giyswx7 0 0 name1 1.0 NaN 3.0 4.0 1 1 name1 2.0 NaN NaN 1.0 2 2 name1 3.0 4.0 1.0 NaN 3 3 name1 NaN 1.0 2.0 3.0 4 4 name1 1.0 NaN 3.0 4.0 5 5 name1 1.0 2.0 3.0 4.0 6 6 name1 NaN NaN NaN NaN Sql compiled: CREATE TABLE tmp_pyodps_16d6ea6d_5195_4e4c_8346_644a395852f7 LIFECYCLE 1 AS SELECT t1.`id`, t1.`name`, IF(t1.`f1` IS NULL, 100, t1.`f1`) AS `f1`, IF(t1.`f2` IS NULL, 100, t1.`f2`) AS `f2`, IF(t1.`f3` IS NULL, 100, t1.`f3`) AS `f3`, IF(t1.`f4` IS NULL, 100, t1.`f4`) AS `f4` FROM WB_BestPractice_dev.`pytable2` t1 Instance ID: 20191010071209190gyl56292 id name f1 f2 f3 f4 0 0 name1 1.0 NaN 3.0 4.0 1 1 name1 2.0 NaN NaN 1.0 2 2 name1 3.0 4.0 1.0 NaN 3 3 name1 NaN 1.0 2.0 3.0 4 4 name1 1.0 NaN 3.0 4.0 5 5 name1 1.0 2.0 3.0 4.0 6 6 name1 NaN NaN NaN NaN Sql compiled: CREATE TABLE tmp_pyodps_40755ebd_2d2a_482e_b360_3f3da0d5422c LIFECYCLE 1 AS SELECT t1.`id`, t1.`name`, IF(t1.`f1` IS NULL, t1.`f2`, t1.`f1`) AS `f1`, IF(t1.`f2` IS NULL, t1.`f2`, t1.`f2`) AS `f2`, IF(t1.`f3` IS NULL, t1.`f2`, t1.`f3`) AS `f3`, IF(t1.`f4` IS NULL, t1.`f2`, t1.`f4`) AS `f4` FROM WB_BestPractice_dev.`pytable2` t1 Instance ID: 20191010071213970gbp66792 id name f1 f2 f3 f4 0 0 name1 1.0 NaN 3.0 4.0 1 1 name1 2.0 NaN NaN 1.0 2 2 name1 3.0 4.0 1.0 NaN 3 3 name1 NaN 1.0 2.0 3.0 4 4 name1 1.0 NaN 3.0 4.0 5 5 name1 1.0 2.0 3.0 4.0 6 6 name1 NaN NaN NaN NaN Sql compiled: CREATE TABLE tmp_pyodps_d39fcce1_d8a9_4cc2_8aff_2ed1e9c6bb1b LIFECYCLE 1 AS SELECT pyodps_udf_1570691538_d9441c59_c666_4a5d_8154_67d8bc8c24ad(t1.`id`, t1.`name`, t1.`f1`, t1.`f2`, t1.`f3`, t1.`f4`) AS (`id`, `name`, `f1`, `f2`, `f3`, `f4`) FROM WB_BestPractice_dev.`pytable2` t1 Instance ID: 20191010071219627goqv9292 id name f1 f2 f3 f4 0 0 name1 1.0 3.0 3.0 4.0 1 1 name1 2.0 1.0 1.0 1.0 2 2 name1 3.0 4.0 1.0 NaN 3 3 name1 1.0 1.0 2.0 3.0 4 4 name1 1.0 3.0 3.0 4.0 5 5 name1 1.0 2.0 3.0 4.0 6 6 name1 NaN NaN NaN NaN Sql compiled: CREATE TABLE tmp_pyodps_3f190cf0_f9fb_4e06_a942_ab31c0241cd3 LIFECYCLE 1 AS SELECT pyodps_udf_1570691566_0330848b_82d3_411c_88e1_cbbcc6adb9c1(t1.`id`, t1.`name`, t1.`f1`, t1.`f2`, t1.`f3`, t1.`f4`) AS (`id`, `name`, `f1`, `f2`, `f3`, `f4`) FROM WB_BestPractice_dev.`pytable2` t1 Instance ID: 20191010071247729gt776792 id name f1 f2 f3 f4 0 0 name1 1.0 1.0 3.0 4.0 1 1 name1 2.0 2.0 2.0 1.0 2 2 name1 3.0 4.0 1.0 1.0 3 3 name1 NaN 1.0 2.0 3.0 4 4 name1 1.0 1.0 3.0 4.0 5 5 name1 1.0 2.0 3.0 4.0 6 6 name1 NaN NaN NaN NaN
该文章对您有帮助吗?