在百炼平台,调用大模型实现文本生成、图片生成、语音合成等任务时,会产生模型推理(调用)费用。此外,如果训练(调优)新模型或将模型部署到独占实例也会产生费用。
计费项
计费项 | 计费说明 | 计费方式 | 计费公式 |
大模型推理(调用) | 所有模型的调用单价和免费额度,请参考模型列表。 调用场景包括:模型调用、应用调用、模型评测、Prompt 自动优化(内置为 Qwen-Plus)。 适合按使用量购买大模型推理服务的需求。 | 后付费(按量) | 模型推理(调用)费用 = 模型调用消耗 x 模型推理(调用)单价 在免费额度内,不会产生费用。查看免费额度请参考新人免费额度。 |
将模型部署到独占实例的费用。 对部署后的模型进行调用和评测将不再额外收取“大模型推理(调用)”费用。 适合按时间买断大模型推理服务的需求。如果只想要增加并发量,请前往扩容申请。 | 后付费(按量) | 模型部署按量费用 = 使用时长(小时)× 实例数量 x 实例单价(不满1小时按1小时计费) 轻量版实例20元/小时 | |
预付费(包月) | 模型部署包月费用 = 购买时长(月)× 实例数量 x 实例单价(不满1天按1天计费) 轻量版实例10,000元/月 | ||
调优或微调 | 模型训练完成后获得的新模型必须进行大模型部署(额外收费)后才能评测和调用。 | 后付费(按量) | 模型训练费用 = (训练数据 Token 总数 + 混合训练数据 Token 总数)× 循环次数 × 训练单价(最低为 0.006元/千Token) 您可以查看模型训练控制台底部的预估训练费用,并单击计算详情,查看训练 Token 总数、循环次数和训练单价。 |
模型推理(调用)计费
完整的模型调用价格和免费额度,请参考模型列表。
计费公式:
文本
文本生成费用 = 模型输入 Token 数 x 模型输入单价 + 模型输出 Token 数 x 模型输出单价(最低为 0.0003元/千Token)
图像转成Token:每28x28像素对应一个Token;一张图最少4个Token。
文本向量、多模态向量、文本分类、文本抽取、文本排序费用 = 模型输出 Token 数 x 模型单价(最低为 0.0007元/千Token)
图像
图像生成费用 = 模型输出图片张数 x 单价(最低为 0.06元/张)
语音
语音合成费用 = 输入字符数 x 单价(最低为 1元/万字符)
根据待合成字符数计费(其中1个汉字算2个字符,英文、标点符号、空格均按照1个字符计费)。
语音识别(实时)费用 = 语音时间 x 单价(最低为 0.00008元/秒)
视频
视频合成大模型调用需要进行模型部署,部署后调用不收费,仅收取部署费用。详情请参考模型部署计费(最低为20元/实例/小时)
模型推理(调用)的免费额度
如何获取免费额度以及如何查看剩余免费额度请参考新人免费额度。
模型推理(调用)的预付费
您可以购买节省计划(预付费),用于抵扣模型推理超出免费额度后产生的推理费用。节省计划用完后,系统会按照后付费的方式结算,您也可以购买多个节省计划进行抵扣。
模型推理(调用):预付费折扣信息请根据下图信息前往价格折扣详情表获取,您也可以直接单击此处购买大语言模型推理节省计划。
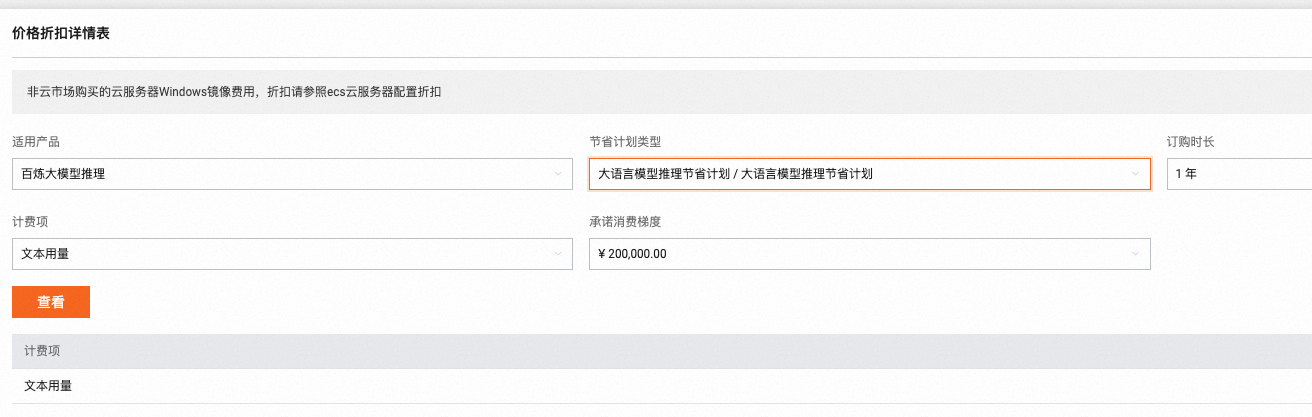
适用范围:通义千问、通义法睿、百川-开源版、ChatGLM以及OpenNLU模型。请前往模型列表获取完整的模型的调用价格和免费额度。
使用说明:如果购买了多个节省计划,抵扣时将按节省计划到期时间的先后顺序抵扣。如果到期时间相同,先购买的节省计划先抵扣。
退订规则:退订规则请提交工单进行咨询。
查询节省计划账单:请参考如何查询节省计划账单。
旗舰模型推理(调用)计费细则
其他模型的调用价格和免费额度,请参考模型列表。
旗舰模型 |
适合复杂任务,推理能力最强 |
效果、速度、成本均衡 |
适合简单任务,速度快、成本低 |
支持长达千万字文档,成本低 |
API调用模型名 (稳定版本) | qwen-max | qwen-plus | qwen-turbo | qwen-long |
最大上下文长度 (Token数) | 32,768 | 131,072 | 131,072 | 10,000,000 |
最低输入价格 (每千Token) | 0.02元 | 0.0008元 | 0.0003元 | 0.0005元 |
最低输出价格 (每千Token) | 0.06元 | 0.002元 | 0.0006元 | 0.002元 |
Batch 调用的计费减免
百炼旗舰模型通义千问-Max、 通义千问-Plus、通义千问-Turbo 支持 Batch调用,调用费用为实时调用的 50%。
您可以通过文件方式提交批量任务,任务将异步执行,在24小时内返回结果。在任务运行结束前,您可以通过API进行任务状态查询,当任务结束后,可以通过API获取结果。使用详情请参考OpenAI Batch 接口调用。
模型评测计费
模型评测是否产生费用取决于评测的对象:
对独立部署的模型进行评测:只收取模型部署费用,评测不额外收费。
对普通模型(未独立部署)进行评测:产生模型推理(调用)费用。
模型部署计费
模型部署的费用取决于模型需要多少实例,以及运行的时长。独占实例的单价最低为20元/小时,预付费(包月)费用 7折。
按量付费:后付费模式,按量付费按实际使用时长计费,无需提前购买资源。您可以根据需求灵活使用,模型上线即开始计费,模型下线即停止计费。此外还支持弹性扩缩容,灵活调整独占实例资源量。此模式适用于即购即用的短期服务模型。
包月预付费:预付费模式,您需要提前购买需要的实例规格。在模型部署时选择包月资源,使用已购买的实例。此模式适合长期服务的稳定模型。您可以前往模型部署控制台模型部署(点击右上角的“资源池管理”)购买包月实例或查看已购买的实例信息。
计费方式 | 计费公式 |
后付费(按量) | 模型部署按量费用 = 使用时长(小时)× 实例数量 x 实例单价(不满1小时按1小时计费) 部署前可以在模型部署控制台查看不同模型的预估每小时费用。 |
预付费(包月) | 模型部署包月费用 = 购买时长(月)× 实例数量 x 实例单价 轻量版实例10,000元/月、基础版20,000元/月、标准版80,000元/月、高级版160,000元/月 购买实例:请前往模型部署控制台(点击右上角的资源池管理)购买。 退订实例:请前往退订管理退订。退订后,将根据剩余时间退回未使用金额。(不满1天按1天计费) |
当模型完成部署,即状态为“运行中”时,开始收取模型部署的费用。模型状态为“部署中”、“欠费”、“部署失败”时,均不会计费。
如果是包月预付费,模型状态为“运行中”后,开始消耗包月时间。
模型服务 | 独占实例资源规格 | 实例单价(后付费,按量) | 实例单价(预付费,包月) |
悦动人像EMO-detect | 轻量版 | 20元/实例/小时 | 10,000元/月 |
悦动人像EMO | |||
舞动人像AnimateAnyone-detect | |||
舞动人像AnimateAnyone | |||
通义万相-文本生成图像-0521 | |||
通义千问-turbo | 基础版 | 40元/实例/小时 | 20,000元/月 |
通义千问1.5-开源版-7B | |||
通义千问1.5-开源版-14B | |||
基于通义千问2-开源版-7B训练出来的模型 | 基础版v2-Qwen2 | - | 20,000元/月 |
通义千问-Plus | 标准版 | 160元/实例/小时 | 80,000元/月 |
通义千问1.5-开源版-72B | |||
通义千问1.5-开源版-110B | |||
基于通义千问2-开源版-72B训练出来的模型 | 标准版v2-Qwen2 | - | 80,000元/月 |
通义千问-max | 高级版 | 320元/实例/小时 | 160,000元/月 |
模型训练计费(模型调优、模型微调)
计费方式 | 计费公式 |
后付费(按量) | 模型训练费用 = (训练数据 Token 总数 + 混合训练数据 Token 总数)× 循环次数 × 训练单价 您可以查看模型训练控制台底部的预估训练费用,并单击计算详情,查看训练 Token 总数、循环次数和训练单价。 |
模型服务 | 模型规格 | 价格 |
通义千问-开源版-72B | qwen-72b-chat | 0.15元/千Token |
通义千问2-开源版-72B | qwen2-72b-instruct | |
通义千问1.5-开源版-72B | qwen1.5-72b-chat | |
通义千问-Plus-0723 | qwen-plus-0723 | |
通义千问-Turbo-0624 | qwen-turbo-0624 | 0.03元/千Token |
通义千问Turbo | qwen-turbo | |
通义千问-开源版-14B | qwen-14b-chat | |
通义千问-Plus | qwen-plus | |
通义千问VL-Plus | qwen-vl-plus | |
通义千问1.5-开源版-14B | qwen1.5-14b-chat | |
通义千问-开源版-7B | qwen-7b-chat | 0.006元/千Token |
通义千问2-开源版-7B | qwen2-7b-instruct | |
通义千问1.5-开源版-7B | qwen1.5-7b-chat |
计费常见问题
在哪里为百炼平台的使用付费?
使用时发生余额不足、欠费等情况请直接前往费用与成本页面充值需要的金额。
预付费方法:
模型推理(调用):预付费折扣信息请根据下图信息前往价格折扣详情表获取,您也可以直接单击此处购买大语言模型推理节省计划。
模型部署:请前往模型部署控制台模型部署(点击右上角“资源池管理”)购买实例或查看已购买的实例信息。
模型训练:不支持预付费。
Token和字符串之间怎么换算?
Token是模型用来表示自然语言文本的基本单位,可以直观地理解为“字”或“词”。
对于中文文本,1个Token通常对应一个汉字或词语。例如,“你好,我是通义千问”会被转换成['你好', ',', '我是', '通', '义', '千', '问']。
对于英文文本,1个Token通常对应3至4个字母或1个单词。例如,"Nice to meet you."会被转换成['Nice', ' to', ' meet', ' you', '.']。
不同的大模型切分Token的方法可能不同。您可以使用SDK在本地查看经过通义千问模型切分后的Token数据。
本地运行的tokenizer可以用来估计文本的Token量,但是得到的结果不保证与模型服务端完全一致,仅供参考。如果您对通义千问的tokenizer细节感兴趣,请参考: tokenizer参考。
多轮对话怎么计费?
在多轮对话中,历史对话的输入输出都会作为新一轮的模型输入 token 进行计费。
怎么增加并发量?
如果您有增加并发量的需求,请前往扩容申请,如果该链接的列表中不包含您需要的模型,则说明暂不支持增加并发量。
如果是独立部署的模型,请扩充实例数量。
创建了大模型应用会收费吗?
只创建应用不会收费。但如果调用应用进行了问答,则会根据调用的模型类型收取模型调用费用。
主动取消模型训练会收费么?
会,如果您主动取消训练,之前已产生的费用仍会被计算。其他原因导致的训练中断,百炼平台不会向您收取训练费用。
模型部署什么时候开始计费?
当模型完成部署,即状态为运行中时,开始收取模型部署的费用。模型状态为部署中、欠费、部署失败时,均不会计费。
如果是包月预付费,模型状态为运行中后,开始消耗包月时间。
模型部署是否可以暂停计费?
如果是包月预付费的独占实例,您只能在退订管理页面,退订独占实例。退订时,将从实付金额中扣除已消费金额,退回剩余金额。具体说明请参考退订说明。
如果是按量后付费的独占实例,您可以下线模型服务。模型服务下线后,将不再产生模型部署费用。
账单常见问题
查看上个月百炼的成本支出
在成本分析页面,成本类型选择应付金额,时间粒度选择月,时间范围选择上个月(假设为2024年08月),产品选择大模型服务平台百炼,即可查看上个月百炼的成本支出。
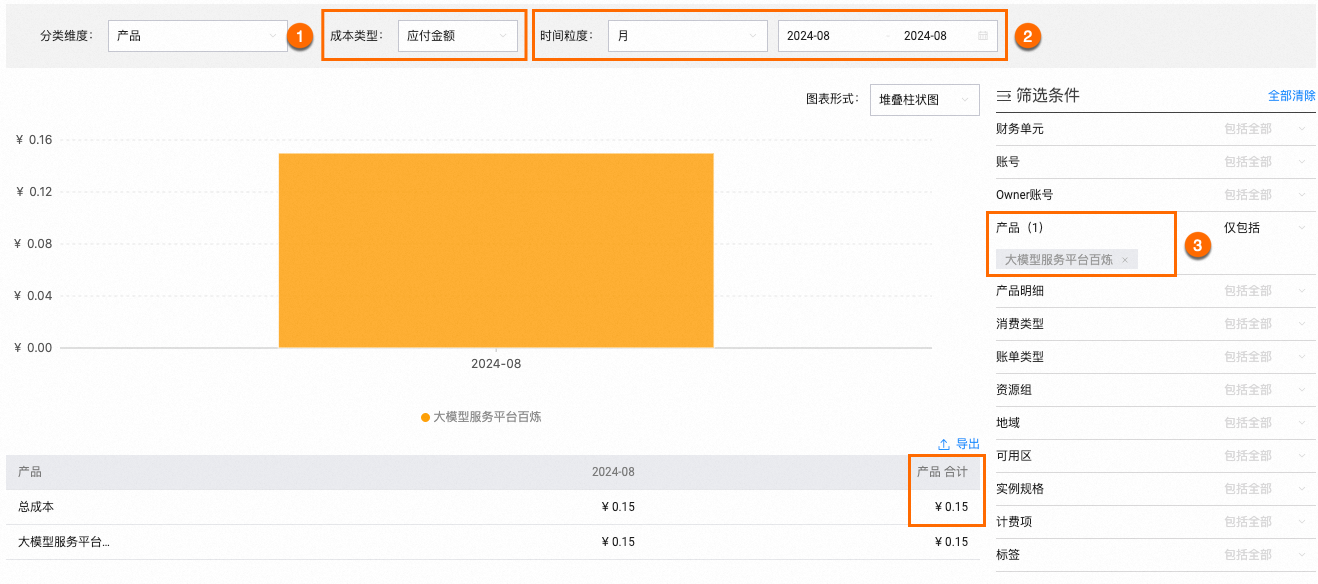
查看模型推理(调用)总花费
在成本分析页面,成本类型选择应付金额,选择时间粒度和范围(假设为2024年03月~08月),产品明细选择大模型推理。
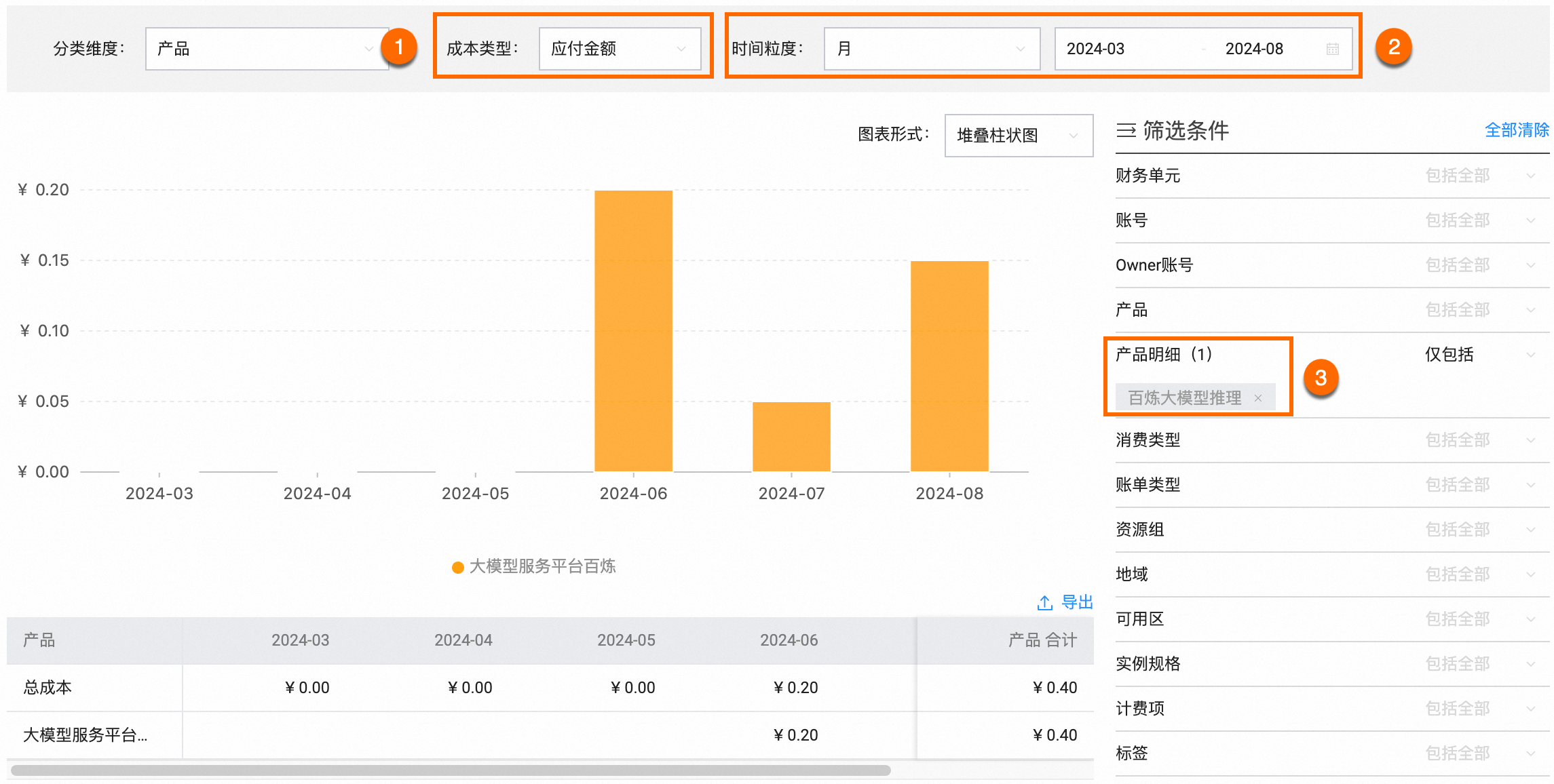
查看具体模型的推理(调用)花费
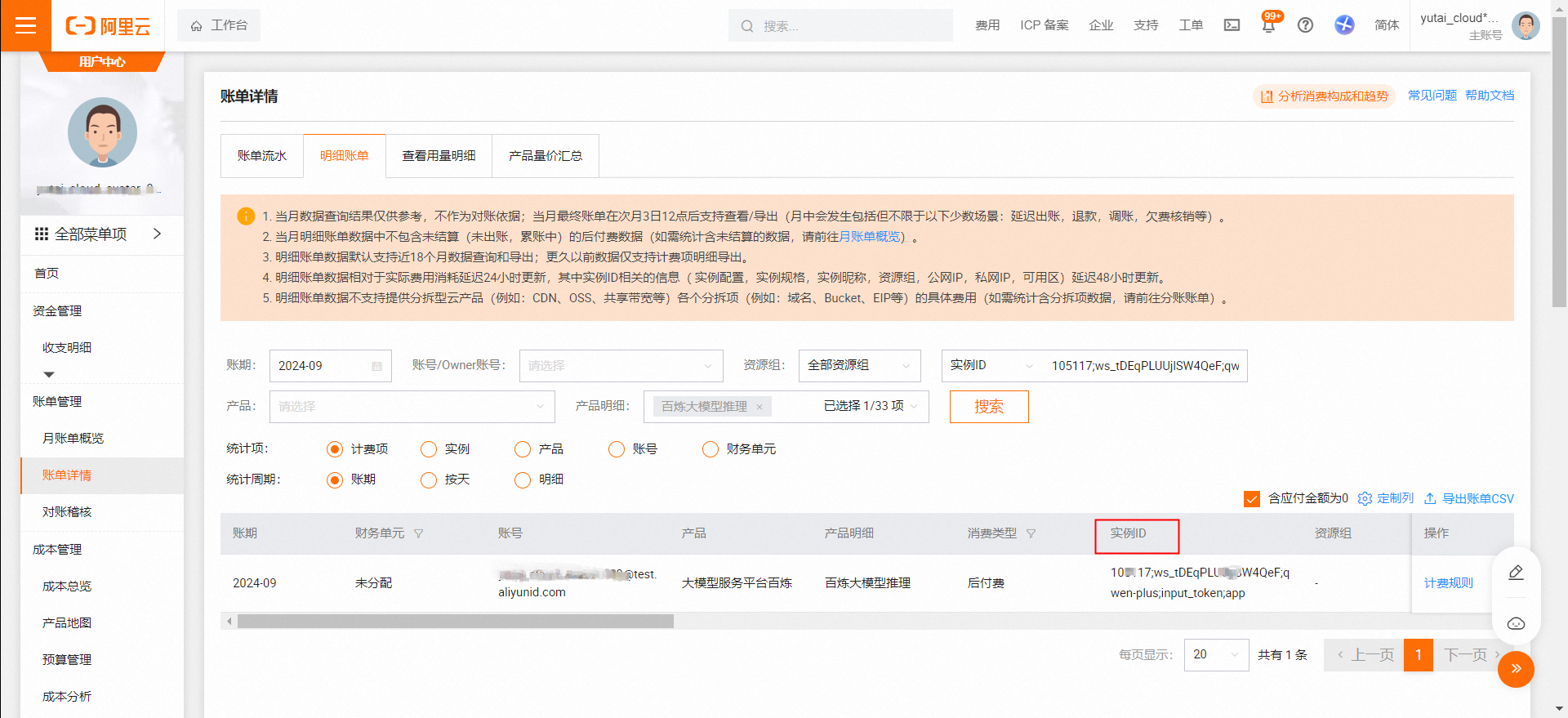
以模型 qwen-max 为例。在明细账单页面,选择账期,选择产品明细为大模型推理,然后单击搜索。在实例ID列可以找到qwen-max的input_tokens和output_tokens两个实例。将这两个实例对应的应付金额相加,即为所选账期内调用qwen-max模型所支付的费用。
实例ID字段内容依次为:ApiKeyId,WorkspaceId,ModelName,AmountType和Source。
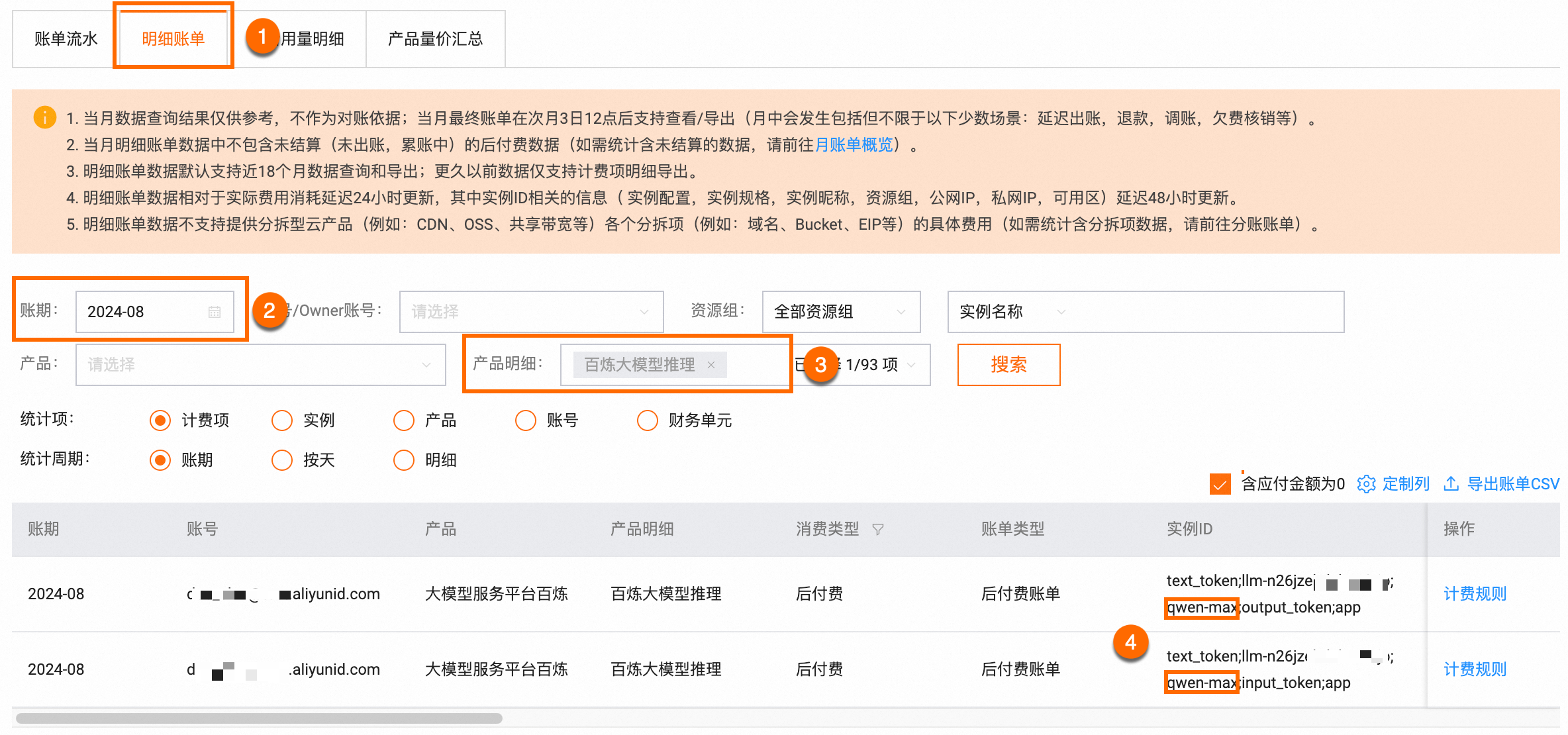
如何根据明细账单进行分账?
比如可以通过业务空间、apikeyid、模型名称等内容,进行分账。
您可以前往百炼API Key管理查看API Key与ApiKeyId的对应关系。
自2024年9月7日以后产生的账单,可通过实例ID信息进行分账,其中实例ID中包含的信息是:ApiKeyId、业务空间ID、模型名称、输入/输出类型、调用渠道。可以通过下载账单表格,按照类型分账进行数据分析和汇总。
如果您的实例ID中没有包含ApiKeyId,则表示该收费项是通过控制台调用产生的。
抵扣券或者优惠券相关
如果有抵扣券或者优惠券,产生的费用如何扣费?
阿里云扣费顺序请前往阿里云后付费账单扣款顺序查询。
相关文档
如何获取免费额度、如何查看免费额度用量,请参考新人免费额度。