阿里云百炼提供了与OpenAI兼容的Batch接口。您可以通过文件方式提交批量任务,任务将异步执行,系统将在任务执行完成或设置的最长等待时间到达后返回任务执行结果,费用仅为实时调用的50%。
前提条件
已开通阿里云百炼服务,并已获取API-KEY:获取API Key。
建议您配置API Key到环境变量中以降低API-KEY的泄露风险。
如果您使用OpenAI Python SDK调用Batch接口,请通过以下命令安装最新版OpenAI SDK。
pip3 install -U openai
支持的模型
qwen-max
qwen-plus
qwen-turbo
qwen-long
qwen-vl-max
qwen-vl-plus
qwq-32b-preview
计费
快速开始
您可以通过以下步骤来执行完整的Batch任务。此Python示例代码将上传符合输入文件格式的 test.jsonl 文件,启动并监控Batch任务,待任务完成后获取结果。
准备文件:将包含请求信息的示例文件test.jsonl下载到本地,并确保其与下方的Python脚本置于同一目录下。
运行脚本:执行此Python脚本。
如果需要调整文件路径或其他参数,请根据实际情况修改代码。
import os from pathlib import Path from openai import OpenAI import time # 初始化客户端 client = OpenAI( # 若没有配置环境变量,可用百炼API Key将下行替换为:api_key="sk-xxx"。但不建议在生产环境中直接将API Key硬编码到代码中,以减少API Key泄露风险。 api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url ) def upload_file(file_path): print(f"正在上传包含请求信息的JSONL文件...") file_object = client.files.create(file=Path(file_path), purpose="batch") print(f"文件上传成功。得到文件ID: {file_object.id}\n") return file_object.id def create_batch_job(input_file_id): print(f"正在基于文件ID,创建Batch任务...") batch = client.batches.create(input_file_id=input_file_id, endpoint="/v1/chat/completions", completion_window="24h") print(f"Batch任务创建完成。 得到Batch任务ID: {batch.id}\n") return batch.id def check_job_status(batch_id): print(f"正在检查Batch任务状态...") batch = client.batches.retrieve(batch_id=batch_id) print(f"Batch任务状态: {batch.status}\n") return batch.status def get_output_id(batch_id): print(f"正在获取Batch任务中执行成功请求的输出文件ID...") batch = client.batches.retrieve(batch_id=batch_id) print(f"输出文件ID: {batch.output_file_id}\n") return batch.output_file_id def get_error_id(batch_id): print(f"正在获取Batch任务中执行错误请求的输出文件ID...") batch = client.batches.retrieve(batch_id=batch_id) print(f"错误文件ID: {batch.error_file_id}\n") return batch.error_file_id def download_results(output_file_id, output_file_path): print(f"正在打印并下载Batch任务的请求成功结果...") content = client.files.content(output_file_id) # 打印部分内容以供测试 print(f"打印请求成功结果的前1000个字符内容: {content.text[:1000]}...\n") # 保存结果文件至本地 content.write_to_file(output_file_path) print(f"完整的输出结果已保存至本地输出文件result.jsonl\n") def download_errors(error_file_id, error_file_path): print(f"正在打印并下载Batch任务的请求失败信息...") content = client.files.content(error_file_id) # 打印部分内容以供测试 print(f"打印请求失败信息的前1000个字符内容: {content.text[:1000]}...\n") # 保存错误信息文件至本地 content.write_to_file(error_file_path) print(f"完整的请求失败信息已保存至本地错误文件error.jsonl\n") def main(): # 文件路径 input_file_path = "test.jsonl" # 可替换为您的输入文件路径 output_file_path = "result.jsonl" # 可替换为您的输出文件路径 error_file_path = "error.jsonl" # 可替换为您的错误文件路径 try: # Step 1: 上传包含请求信息的JSONL文件,得到输入文件ID input_file_id = upload_file(input_file_path) # Step 2: 基于输入文件ID,创建Batch任务 batch_id = create_batch_job(input_file_id) # Step 3: 检查Batch任务状态直到结束 status = "" while status not in ["completed", "failed", "expired", "cancelled"]: status = check_job_status(batch_id) if status == "validating" or status == "in_progress": print(f"等待任务完成...") time.sleep(10) # 等待10秒后再次查询状态 else: break # 如果任务失败,则打印错误信息并退出 if status == "failed": batch = client.batches.retrieve(batch_id) print(f"Batch任务失败。错误信息为:{batch.errors}\n") print(f"参见错误码文档: https://help.aliyun.com/zh/model-studio/developer-reference/error-code") return # Step 4: 下载结果:如果输出文件ID不为空,则打印请求成功结果的前1000个字符内容,并下载完整的请求成功结果到本地输出文件; # 如果错误文件ID不为空,则打印请求失败信息的前1000个字符内容,并下载完整的请求失败信息到本地错误文件。 output_file_id = get_output_id(batch_id) if output_file_id: download_results(output_file_id, output_file_path) error_file_id = get_error_id(batch_id) if error_file_id: download_errors(error_file_id, error_file_path) print(f"参见错误码文档: https://help.aliyun.com/zh/model-studio/developer-reference/error-code") except Exception as e: print(f"An error occurred: {e}") print(f"参见错误码文档: https://help.aliyun.com/zh/model-studio/developer-reference/error-code") if __name__ == "__main__": main()获取结果:任务完成时,若任务成功,将在同一目录下生成输出结果文件
result.jsonl。若任务失败,则程序退出并打印错误信息。
如果存在错误文件ID,将在同一目录下生成错误文件
error.jsonl以供检查。在过程中发生的异常会被捕获,并打印错误信息。
数据文件格式说明
输入文件格式
Batch任务的输入文件为 JSONL 文件,格式要求如下:
每行一个 JSON 格式的请求。
单个 Batch 任务最多包含 50,000 个请求。
Batch 文件最大500 MB。
文件中单行最大 1 MB。
单行的请求内容需遵循各模型上下文长度的限制。
示例
一个单行内容示例:
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "qwen-turbo", "messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What is 2+2?"}]}}参数
字段 | 类型 | 必选 | 描述 |
custom_id | String | 是 | 用户自定义的请求ID,每一行表示一条请求,每一条请求有一个唯一的 |
method | String | 是 | 请求方法,当前只支持POST |
url | String | 是 | API关联的URL,当前支持:/v1/chat/completions |
body | Object | 是 | 模型调用的请求体,其中model为选择的模型,messages 的构建需要符合ChatML格式,如: |
CSV文件转换为JSONL文件
如果您有一份第一列为请求id(custom_id)第二列为内容(content)的 CSV 文件,您可以通过下方Python代码快速创建一份符合Batch任务格式的JSONL文件。此特定格式的 CSV 文件应与下方的Python脚本放置在同一目录中。
也可以使用本文提供的模板文件,具体步骤如下:
将模板文件下载到本地,并与下方的Python脚本置于同一目录下;
这里的CSV模板文件格式是第一列为请求id(custom_id),第二列为内容(content),您可以将您的业务问题粘贴到这个文件中。
运行下方 Python 脚本代码后,将在同一目录下生成一个符合Batch任务文件格式的名为input_demo.jsonl的JSONL文件。
import csv
import json
def messages_builder_example(content):
messages = [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": content}]
return messages
with open("input_demo.csv", "r") as fin:
with open("input_demo.jsonl", 'w', encoding='utf-8') as fout:
csvreader = csv.reader(fin)
for row in csvreader:
body = {"model": "qwen-turbo", "messages": messages_builder_example(row[1])}
request = {"custom_id": row[0], "method": "POST", "url": "/v1/chat/completions", "body": body}
fout.write(json.dumps(request, separators=(',', ':'), ensure_ascii=False) + "\n", )输出文件格式
JSONL文件,每行一个JSON。
示例
一个单行内容示例:
{"id": "batch_req_wnaDys", "custom_id": "request-2", "response": {"status_code": 200, "request_id": "req_c187b3", "body": {"id": "chatcmpl-9758Iw", "object": "chat.completion", "created": 1711475054, "model": "qwen-max", "choices": [{"index": 0, "message": {"role": "assistant", "content": "2 + 2 equals 4."}, "finish_reason": "stop"}], "usage": {"prompt_tokens": 24, "completion_tokens": 15, "total_tokens": 39}, "system_fingerprint": null}}, "error": null}参数
字段 | 类型 | 必选 | 描述 |
id | String | 是 | 请求id |
custom_id | String | 是 | 用户自定义的请求id |
response | Object | 否 | 请求结果 |
error | Object | 否 | 异常响应结果 |
error.code | String | 否 | 错误码 |
error.message | String | 否 | 错误信息 |
JSONL文件转换为CSV文件
相比于JSONL文件,CSV文件通常只包含必要的数据值,没有额外的键名或其他元数据,非常适合用于自动化脚本和Batch任务。如果您需要将Batch输出的 JSONL 文件转换成 CSV 文件,可以使用以下Python代码实现。
请确保将 result.jsonl 文件与下方的 Python 脚本放在同一目录下,运行下方脚本代码后会生成一个名为 result.csv 的 CSV 文件。
import json
import csv
columns = ["custom_id",
"model",
"request_id",
"status_code",
"error_code",
"error_message",
"created",
"content",
"usage"]
def dict_get_string(dict_obj, path):
obj = dict_obj
try:
for element in path:
obj = obj[element]
return obj
except:
return None
with open("result.jsonl", "r") as fin:
with open("result.csv", 'w', encoding='utf-8') as fout:
rows = [columns]
for line in fin:
request_result = json.loads(line)
row = [dict_get_string(request_result, ["custom_id"]),
dict_get_string(request_result, ["response", "body", "model"]),
dict_get_string(request_result, ["response", "request_id"]),
dict_get_string(request_result, ["response", "status_code"]),
dict_get_string(request_result, ["error", "error_code"]),
dict_get_string(request_result, ["error", "error_message"]),
dict_get_string(request_result, ["response", "body", "created"]),
dict_get_string(request_result, ["response", "body", "choices", 0, "message", "content"]),
dict_get_string(request_result, ["response", "body", "usage"])]
rows.append(row)
writer = csv.writer(fout)
writer.writerows(rows)当CSV文件中包含中文字符,并且使用Excel打开时遇到乱码问题时,可以使用文本编辑器(如Sublime)将CSV文件的编码转换为GBK,然后再用Excel打开。另一种方法是在Excel中新建一个Excel文件,并在导入数据时指定正确的编码格式UTF-8。
具体流程
1. 准备与上传文件
创建Batch任务前,需要您将准备好的符合输入文件格式的JSONL文件,通过以下的文件上传接口上传后,获取file_id,通过purpose参数指定上传文件的用途为batch。
您可以上传Batch任务的单个文件最大为500 MB;当前阿里云账号下可以上传的最大文件数为10000个,上传文件的总量不超过100 GB,文件暂时没有有效期。当您的文件空间达到限制后,可以通过删除文件接口删除不需要的文件以释放空间。
OpenAI Python SDK
请求示例
import os
from pathlib import Path
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,可用百炼API Key将下行替换为:api_key="sk-xxx"。但不建议在生产环境中直接将API Key硬编码到代码中,以减少API Key泄露风险。
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 百炼服务的base_url
)
# test.jsonl 是一个本地示例文件,purpose必须是batch
file_object = client.files.create(file=Path("test.jsonl"), purpose="batch")
print(file_object.model_dump_json())测试文件test.jsonl内容:
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "qwen-turbo", "messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What is 2+2?"}]}}返回示例
{
"id": "file-batch-xxx",
"bytes": 231,
"created_at": 1729065815,
"filename": "test.jsonl",
"object": "file",
"purpose": "batch",
"status": "processed",
"status_details": null
}curl
请求示例
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/files \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
--form 'file=@"test.jsonl"' \
--form 'purpose="batch"'测试文件test.jsonl内容:
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "qwen-turbo", "messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What is 2+2?"}]}}返回示例
{
"id": "file-batch-xxx",
"bytes": 231,
"created_at": 1729065815,
"filename": "test.jsonl",
"object": "file",
"purpose": "batch",
"status": "processed",
"status_details": null
}2. 创建Batch任务
使用准备与上传文件返回的文件ID创建Batch任务。
接口限流:每个阿里云主账号每分钟100次,最大运行任务数100个(包括所有未结束的任务,超过最大任务数,需要等任务结束后才能再创建)。
OpenAI Python SDK
请求示例
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,可用百炼API Key将下行替换为:api_key="sk-xxx"。但不建议在生产环境中直接将API Key硬编码到代码中,以减少API Key泄露风险。
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 百炼服务的base_url
)
batch = client.batches.create(
input_file_id="file-batch-xxx", # 上传文件返回的 id
endpoint="/v1/chat/completions", # 大语言模型固定填写,/v1/chat/completions
completion_window="24h"
)
print(batch)curl
需要配置的endpoint
POST https://dashscope.aliyuncs.com/compatible-mode/v1/batches请求示例
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/batches \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input_file_id": "file-batch-xxx",
"endpoint": "/v1/chat/completions",
"completion_window": "24h"
}'将input_file_id的值替换为实际值。输入参数配置
字段 | 类型 | 传参方式 | 必选 | 描述 |
input_file_id | String | Body | 是 | 准备与上传文件返回的文件 ID作为输入参数,以file-batch开头 文件的 |
endpoint | String | Body | 是 | 访问路径,大语言模型固定填写 |
completion_window | String | Body | 是 | 等待时间,支持最短等待时间24h,最长等待时间336h,仅支持整数 |
metadata | Map | Body | 否 | 附加信息,键值对 |
返回示例
{
"id": "batch_cf957e2b-3295-4357-83af-5fb22ac17e81",
"object": "batch",
"endpoint": "/v1/chat/completions",
"errors": null,
"input_file_id": "file-batch-ADvrUmLWW8TFuKNjGDUUig1c",
"completion_window": "24h",
"status": "validating",
"output_file_id": null,
"error_file_id": null,
"created_at": 1722503223,
"in_progress_at": null,
"expires_at": null,
"finalizing_at": null,
"completed_at": null,
"failed_at": null,
"expired_at": null,
"cancelling_at": null,
"cancelled_at": null,
"request_counts": {
"total": 0,
"completed": 0,
"failed": 0
},
"metadata": {}
}返回参数
字段 | 类型 | 描述 |
id | String | Batch任务 ID |
object | String | 对象类型,固定值 |
endpoint | String | 访问路径 |
errors | Map | 错误信息 |
input_file_id | String | 上传的文件id |
completion_window | String | 等待时间,支持最短等待时间24h,最长等待时间336h,仅支持整数 |
status | String | 任务状态,包括validating、failed、in_progress、finalizing、completed、expired、cancelling、cancelled |
output_file_id | String | 执行成功请求的输出文件id |
error_file_id | String | 执行错误请求的输出文件id |
created_at | Integer | 任务创建的Unix 时间戳(秒) |
in_progress_at | Integer | 任务开始运行的Unix时间戳(秒) |
expires_at | Integer | 任务开始超时的时间戳(秒) |
finalizing_at | Integer | 任务最后开始时间戳(秒) |
completed_at | Integer | 任务完成的时间戳(秒) |
failed_at | Integer | 任务失败的时间戳(秒) |
expired_at | Integer | 任务超时的时间戳(秒) |
cancelling_at | Integer | 任务设置为取消中的时间戳(秒) |
cancelled_at | Integer | 任务取消的时间戳(秒) |
request_counts | Map | 不同状态的请求数量 |
metadata | Map | 附加信息,键值对 |
3. 查询与管理Batch任务
查询Batch任务详情
通过传入创建Batch任务返回的Batch任务ID,来查询指定Batch任务的信息。
接口限流:每个阿里云主账号每分钟300次(由于Batch任务执行需要一些时间,建议创建Batch任务之后,每分钟调用1次该查询接口获取任务信息)。
OpenAI Python SDK
请求示例
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,可用百炼API Key将下行替换为:api_key="sk-xxx"。但不建议在生产环境中直接将API Key硬编码到代码中,以减少API Key泄露风险。
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 百炼服务的base_url
)
batch = client.batches.retrieve("batch_id") # 将batch_id替换为Batch任务的id
print(batch)curl
需要配置的endpoint
GET https://dashscope.aliyuncs.com/compatible-mode/v1/batches/batch_id请求示例
curl --request GET 'https://dashscope.aliyuncs.com/compatible-mode/v1/batches/batch_id' \
-H "Authorization: Bearer $DASHSCOPE_API_KEY"将batch_id替换为实际值。输入参数配置
字段 | 类型 | 传参方式 | 必选 | 描述 |
batch_id | String | Path | 是 | 需要查询的Batch任务的ID(创建Batch任务返回的Batch任务ID),以batch开头,例如“batch_xxx” |
返回示例
请参见创建Batch任务的返回示例。
返回参数
请参见创建Batch任务的返回参数。
返回参数中output_file_id和error_file_id可以通过下载Batch结果文件获取内容。
查询Batch任务列表
您可以通过batches.list()方法来查询Batch任务列表,利用分页机制来逐步获取完整的任务列表。通过传递上次查询结果中的最后一个Batch任务ID作为after参数值,可以请求下一页的Batch任务数据,并通过limit参数来指定返回任务的数量。
接口限流:每个阿里云主账号每分钟100次。
OpenAI Python SDK
请求示例
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,可用百炼API Key将下行替换为:api_key="sk-xxx"。但不建议在生产环境中直接将API Key硬编码到代码中,以减少API Key泄露风险。
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 百炼服务的base_url
)
batches = client.batches.list(after="batch_id", limit=20) # 将batch_id替换为Batch任务的id
print(batches)curl
需要配置的endpoint
GET https://dashscope.aliyuncs.com/compatible-mode/v1/batches?limit=20&after=batch_id请求示例
curl --request GET 'https://dashscope.aliyuncs.com/compatible-mode/v1/batches?limit=20&after=batch_id' \
-H "Authorization: Bearer $DASHSCOPE_API_KEY"将after=batch_id中的batch_id替换为实际值,limit参数设置为返回任务的数量。
输入参数配置
字段 | 类型 | 传参方式 | 必选 | 描述 |
after | String | Query | 否 | 用于分页的游标,参数 例如,若本次查询返回了20行数据,且最后一个Batch任务 ID(即last_id)是batch_xxx,则后续查询时可以设置 |
limit | Integer | Query | 否 | 每次查询返回的Batch任务数量,范围[1,100],默认20。 |
返回示例
{
"object": "list",
"data": [
{
"id": "batch_b8b6a83e-00a3-4068-81d9-0a1705bf6b2c",
"object": "batch",
"endpoint": "/v1/chat/completions",
"errors": null,
"input_file_id": "file-batch-IvxTEDheD70YmyXfqrkE2t64",
"completion_window": "24h",
"status": "completed",
"output_file_id": "file-batch_output-fUy6gxJCyHzT0WHDg2SInyTp",
"error_file_id": null,
"created_at": 1722234109,
"in_progress_at": 1722234109,
"expires_at": null,
"finalizing_at": 1722234165,
"completed_at": 1722234165,
"failed_at": null,
"expired_at": null,
"cancelling_at": null,
"cancelled_at": null,
"request_counts": {
"total": 100,
"completed": 95,
"failed": 5
},
"metadata": {}
},
{ ... }
],
"first_id": "batch_b8b6a83e-00a3-4068-81d9-0a1705bf6b2c",
"last_id": "batch_ca912d83-e9e8-4cf2-89a4-d29743e334e4",
"has_more": true
}返回参数
字段 | 类型 | 描述 |
object | String | 类型,固定值list |
data | Array | Batch任务对象,参见创建Batch任务的返回参数 |
first_id | String | 当前页第一个 Batch任务 ID |
last_id | String | 当前页最后一个Batch任务 ID |
has_more | Boolean | 是否有下一页 |
取消Batch任务
通过传入创建Batch任务返回的Batch任务ID,来取消指定的Batch任务。
接口限流:每个阿里云主账号每分钟100次。
OpenAI Python SDK
请求示例
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,可用百炼API Key将下行替换为:api_key="sk-xxx"。但不建议在生产环境中直接将API Key硬编码到代码中,以减少API Key泄露风险。
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 百炼服务的base_url
)
batch = client.batches.cancel("batch_id") # 将batch_id替换为Batch任务的id
print(batch)curl
需要配置的endpoint
POST https://dashscope.aliyuncs.com/compatible-mode/v1/batches/batch_id/cancel请求示例
curl --request POST 'https://dashscope.aliyuncs.com/compatible-mode/v1/batches/batch_id/cancel' \
-H "Authorization: Bearer $DASHSCOPE_API_KEY"将batch_id替换为实际值。输入参数配置
字段 | 类型 | 传参方式 | 必选 | 描述 |
batch_id | String | Path | 是 | 需要取消的Batch任务的id,以batch开头,例如“batch_xxx” |
返回示例
请参见创建Batch任务的返回示例。
返回参数
请参见创建Batch任务的返回参数。
4. 下载Batch结果文件
在Batch推理任务结束后,您可以通过接口下载结果文件。
您可以通过查询Batch任务详情或通过查询Batch任务列表返回参数中的output_file_id获取下载文件的file_id。仅支持下载以file-batch_output开头的file_id对应的文件。
OpenAI Python SDK
您可以通过content方法获取Batch任务结果文件内容,并通过write_to_file方法将其保存至本地。
请求示例
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
content = client.files.content(file_id="file-batch_output-xxx")
# 打印结果文件内容
print(content.text)
# 保存结果文件至本地
content.write_to_file("result.jsonl")返回示例
{"id":"xxx","custom_id":"request-1","response":{"status_code":200,"request_id":"xxx","body":{"id":"xxx","object":"chat.completion","created":1729490866,"model":"qwen-turbo","choices":[{"finish_reason":"stop","index":0,"message":{"content":"2 + 2 equals 4."}}],"usage":{"completion_tokens":8,"prompt_tokens":36,"total_tokens":44},"system_fingerprint":null}},"error":null}
{"id":"yyy","custom_id":"request-2","response":{"status_code":200,"request_id":"yyy","body":{"id":"yyy","object":"chat.completion","created":1729490866,"model":"qwen-turbo","choices":[{"finish_reason":"stop","index":0,"message":{"content":"你好!有什么我可以帮你的吗?"}}],"usage":{"completion_tokens":8,"prompt_tokens":31,"total_tokens":39},"system_fingerprint":null}},"error":null}curl
您可以通过GET方法,在URL中指定file_id来下载Batch任务结果文件。
需要配置的endpoint
GET https://dashscope.aliyuncs.com/compatible-mode/v1/files/{file_id}/content请求示例
curl -X GET https://dashscope.aliyuncs.com/compatible-mode/v1/files/file-batch_output-xxx/content \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" > result.jsonl输入参数配置
字段 | 类型 | 传参方式 | 必选 | 描述 |
file_id | string | Path | 是 | 需要下载的文件的id,查询Batch任务详情或通过查询Batch任务列表返回参数中的 |
返回结果
Batch任务结果的JSONL文件,格式请参考输出文件格式。
Batch支持任务完成通知
提交Batch任务之后,可以通过查询Batch任务接口获取状态和信息,Batch任务执行时间有时会比较长,持续查询Batch任务效率较低,Batch支持任务完成之后通知,减少不必要的任务查询,提高效率。Batch任务完成通知支持两种方式:Callback回调和EventBridge消息。
Callback回调通知
EventBridge消息
对于更复杂或集成度更高的系统,使用阿里云事件总线EventBridge是更好的选择。您可以在EventBridge控制台配置自定义事件规则,将Batch任务结束的信息转发给不同的目标,如函数计算、HTTP、消息队列RocketMQ等,从而更加高效地处理已完成的Batch任务。
如果您尚不清楚EventBridge阿里云事件总线的概念,请参见什么是事件总线EventBridge。
EventBridge的几个核心概念:
事件:事件状态变化的数据记录。
事件源:事件的来源,负责生产事件。
事件目标:事件的处理终端,负责消费事件。
事件总线:事件的中转站,负责事件的中间转储。
事件规则:用于监控特定类型的事件。当发生匹配事件时,事件会被路由到与事件规则关联的事件目标。
步骤一:开通EventBridge
步骤二:控制台查询事件
Batch任务结束后,在EventBridge中可以查找特定条件下的Batch任务结束事件。
进入EventBridge控制台,切换到北京地域,在左侧导航栏选择事件总线,单击default进入云服务专用总线页面。
Batch任务所属的事件总线为云服务专用总线,即default。
在云服务专用总线页面的左侧导航栏选择事件追踪,输入查询条件。
事件源:搜索选择
acs.dashscope(百炼云产品)。事件类型:搜索选择
dashscope:System:BatchTaskFinish(百炼异步任务结束)。规则名称:如果您想接收包含任务结果的通知,这里可以选择已创建的规则过滤事件。自定义创建规则请参见本文的创建事件转发规则(可选)。
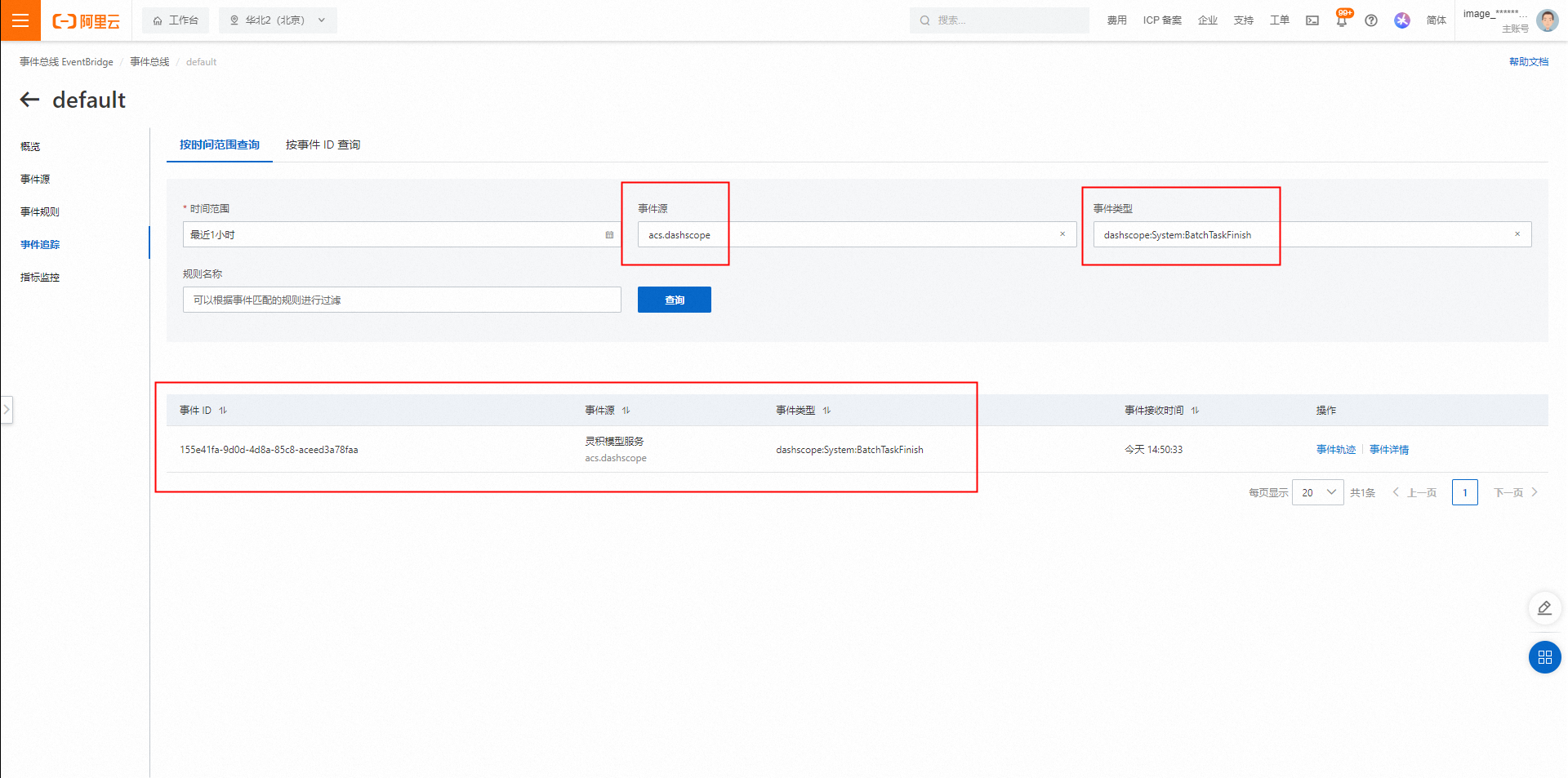
单击查询得到Batch任务结束事件,单击事件详情,可以查看到Batch任务结束的详细信息,如下:
{ "id": "2e44cbc8-xxxxx-f8d7a414d3db", "time": "2024-11-20T06:51:29.220Z", "aliyunpublishtime": "2024-11-20T06:51:29.258Z", "specversion": "1.0", "aliyuneventbusname": "default", "aliyunoriginalaccountid": "xxxxx", "datacontenttype": "application/json;charset=utf-8", "aliyunaccountid": "xxxxx", "source": "acs.dashscope", "aliyunregionid": "cn-beijing", "type": "dashscope:System:BatchTaskFinish", "data": { "id": "batch_cf957e2b-3295-4357-83af-5fb22ac17e81", "object": "batch", "endpoint": "/v1/chat/completions", "errors": null, "input_file_id": "file-batch-ADvrUmLWW8TFuKNjGDUUig1c", "completion_window": "24h", "status": "completed", "output_file_id": null, "error_file_id": null, "created_at": 1722503223, "in_progress_at": 1732085433, "expires_at": null, "finalizing_at": 1732085488, "completed_at": 1732085488, "failed_at": null, "expired_at": null, "cancelling_at": null, "cancelled_at": null, "request_counts": { "total": 3, "completed": 3, "failed": 0 }, "metadata": { "ds_batch_finish_callback": "https://xxxxx" }, } }参数描述
参数
类型
描述
示例值
id
String
事件ID,标识事件的唯一值。
45ef4dewdwe1-7c35-447a-bd93-fab****
datacontenttype
String
参数data的内容形式。datacontenttype只支持application/json格式。
application/json;charset=utf-8aliyunaccountid
String
阿里云账号ID。
123456789098****
aliyunpublishtime
String
接收事件的时间。
2020-11-19T21:04:42.179PRC
aliyunoriginalaccountid
String
阿里云原始账号ID。
123456789098****
specversion
String
CloudEvents协议版本。
1.0
aliyuneventbusname
String
接收事件的事件总线名称。
default
source
String
事件源。提供事件的服务。标识事件发生的内容。一般会包含事件源的类型,发布事件的机制或生产事件的过程。发送端必须确保每个事件的source+id是唯一的。
acs.dashscope
time
String
事件产生的时间。如果无法确定事件发生的时间,CloudEvents生产者可以把time设置为其他时间(例如当前时间),但是同一个source的所有生产者设置的值必须是一致的。
2020-11-19T21:04:41+08:00
aliyunregionid
String
接收事件的地域。
cn-beijing
type
String
事件类型。描述事件源相关的事件类型。该参数用于路由、事件查询和策略执行等。格式由生产者定义且包含版本等信息。
dashscope:System:BatchTaskFinish
data
Object
事件内容,Batch任务信息(参考2. 创建Batch任务返回结果)。
创建事件转发规则(可选)
如果您想接收包含任务结果的通知,如短信、电话、邮箱、钉钉等方式,您可以自定义规则,将Batch任务转发到不同的接收点,创建步骤如下:
在左侧导航栏选择事件规则,单击创建规则。
配置基本信息,自定义规则名称和描述。
单击下一步,配置事件模式。
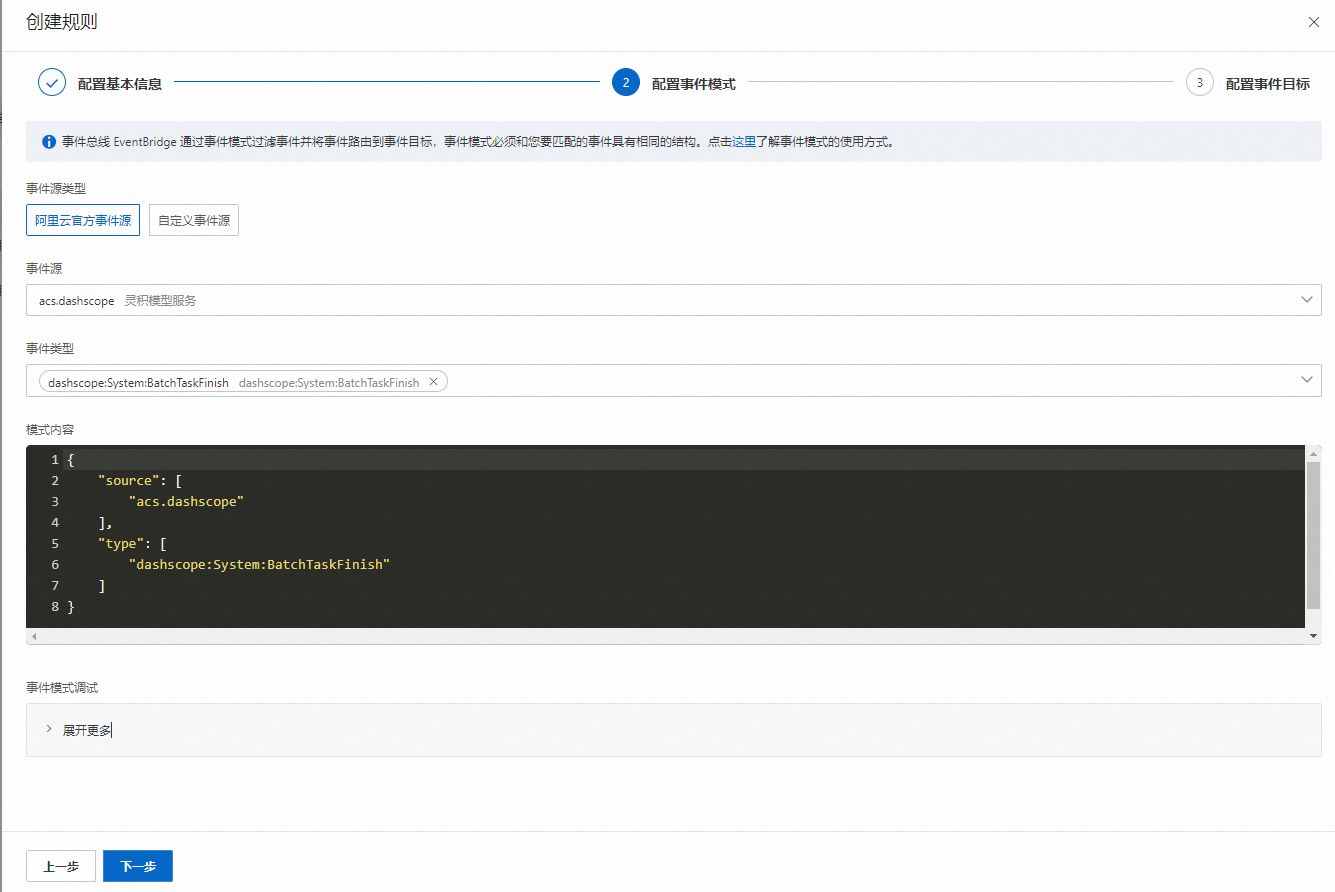
事件源:搜索选择
acs.dashscope(百炼云产品)。事件类型:搜索选择
dashscope:System:BatchTaskFinish(百炼异步任务结束)。模式内容:用来过滤相关事件的模式定义,可以根据指定字段的值进行过滤。具体模式定义参考事件模式。示例如下:
转发Batch任务所有事件:
{ "source": ["acs.dashscope"], "type": ["dashscope:System:BatchTaskFinish"] }只转发Batch任务状态为completed的事件:
{ "source": ["acs.dashscope"], "type": ["dashscope:System:BatchTaskFinish"], "data": { "status": [ "completed" ] } }
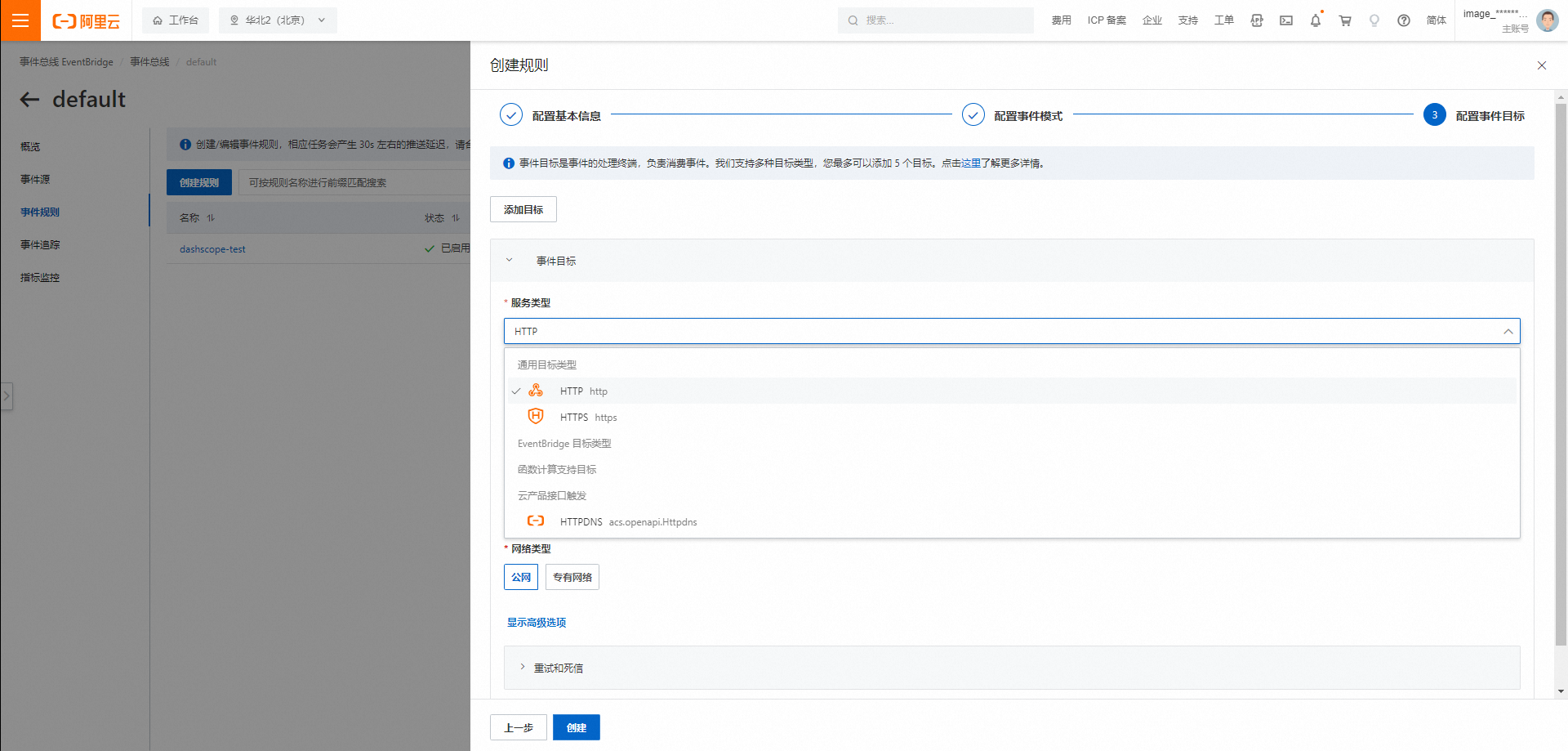
单击下一步,配置事件目标。
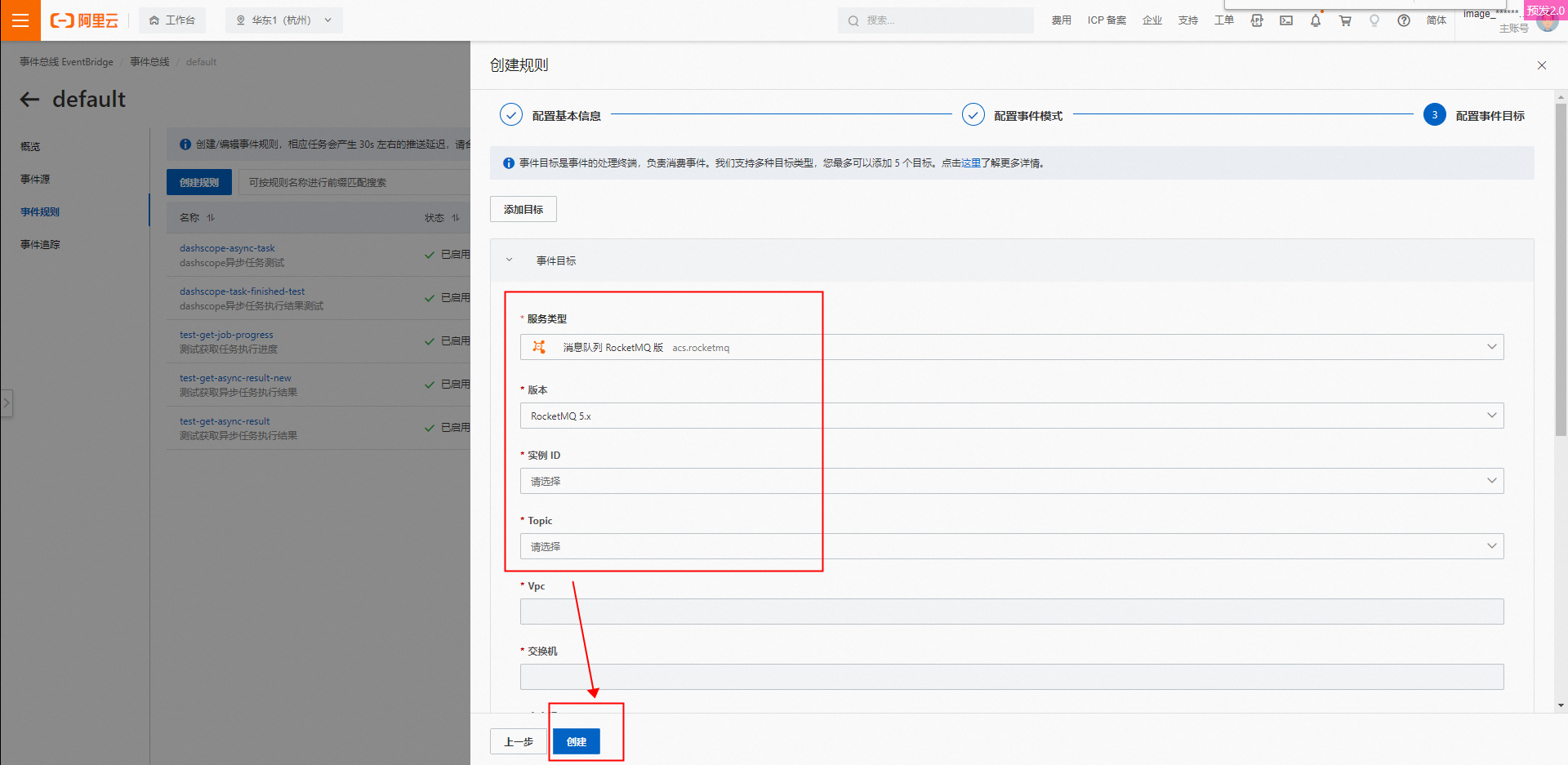
EventBridge支持多种类型的事件目标,包括HTTP、RocketMQ消息队列等,您可以根据需要选择服务类型,填写配置信息。
有关更多事件目标类型的信息,请参见事件目标概述。本文将以通过RocketMQ消息队列接收事件(可选)接收EventBridge事件为例。
单击创建,配置完成。
RocketMQ消息队列接收事件(可选)
如果已经有RocketMQ队列,可以跳过此步。
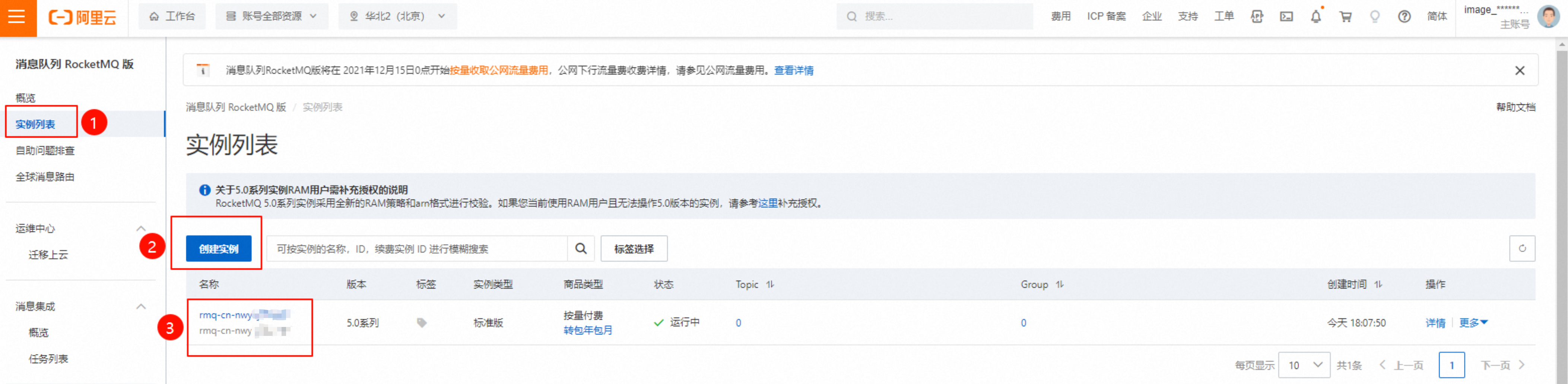
进入RocketMQ控制台,在左侧导航栏选择实例列表,单击创建实例。
下图中,rmq-cn-nwy*******为实例ID。
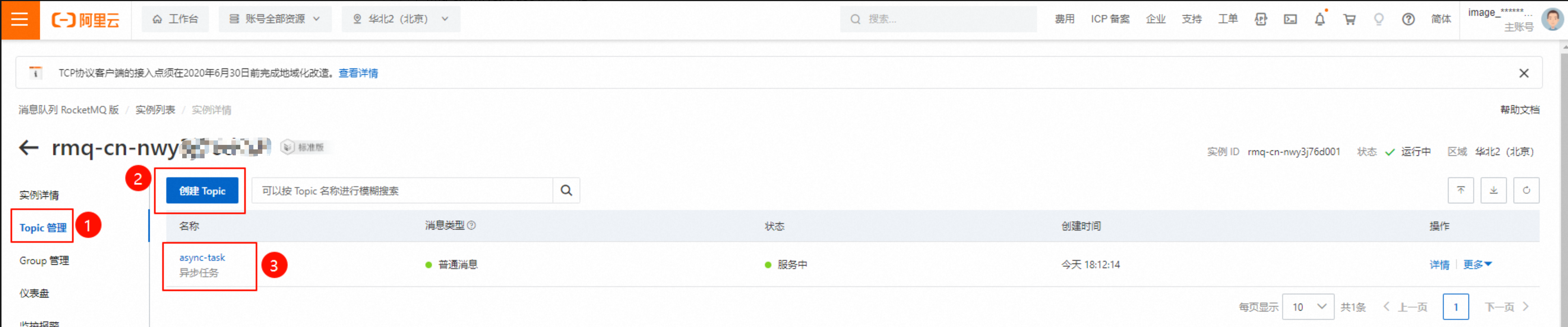
创建对应实例的Topic。
创建对应实例的Group。
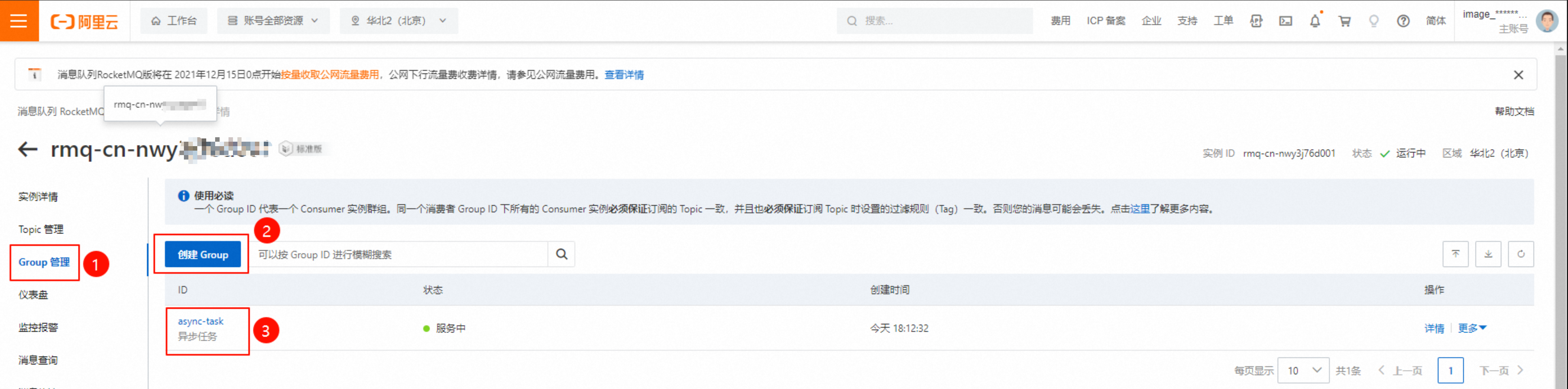
打开创建事件转发规则(可选)中的配置EventBridge的事件目标界面,选择已配置的RocketMQ实例,填写RocketMQ配置信息。
服务类型:消息队列RocketMQ版。
版本:创建完成的RocketMQ版本。
实例ID:创建完成的RocketMQ的实例ID。
Topic:创建完成的Topic。
常见问题
这几个模块的Batch定价,对应的模型也有基础限流吗?
答:实时调用才会有RPM(Requests Per Minute:每分钟处理请求数)限流,Batch调用没有 RPM 限流。
使用Batch调用,是否需要下单,在哪里下单?
答:Batch是一种调用方式,无需额外下单。该调用方式为后付费计价模式,按照Batch接口调用直接付费。
提交的Batch调用请求,后台如何处理? 是根据提交请求的先后顺序来执行吗?
答:不是排队机制,是调度机制,根据资源情况来调度和执行Batch请求任务。
报错如何处理?
答:请参见错误码。