
本文介绍了如何使用阿里云百炼大模型服务提供的实时多模交互 Linux C++ SDK,包括SDK下载安装、关键接口及代码示例。
前提条件
开通阿里云百炼实时多模交互应用,获取Workspace ID、APP ID和API Key。
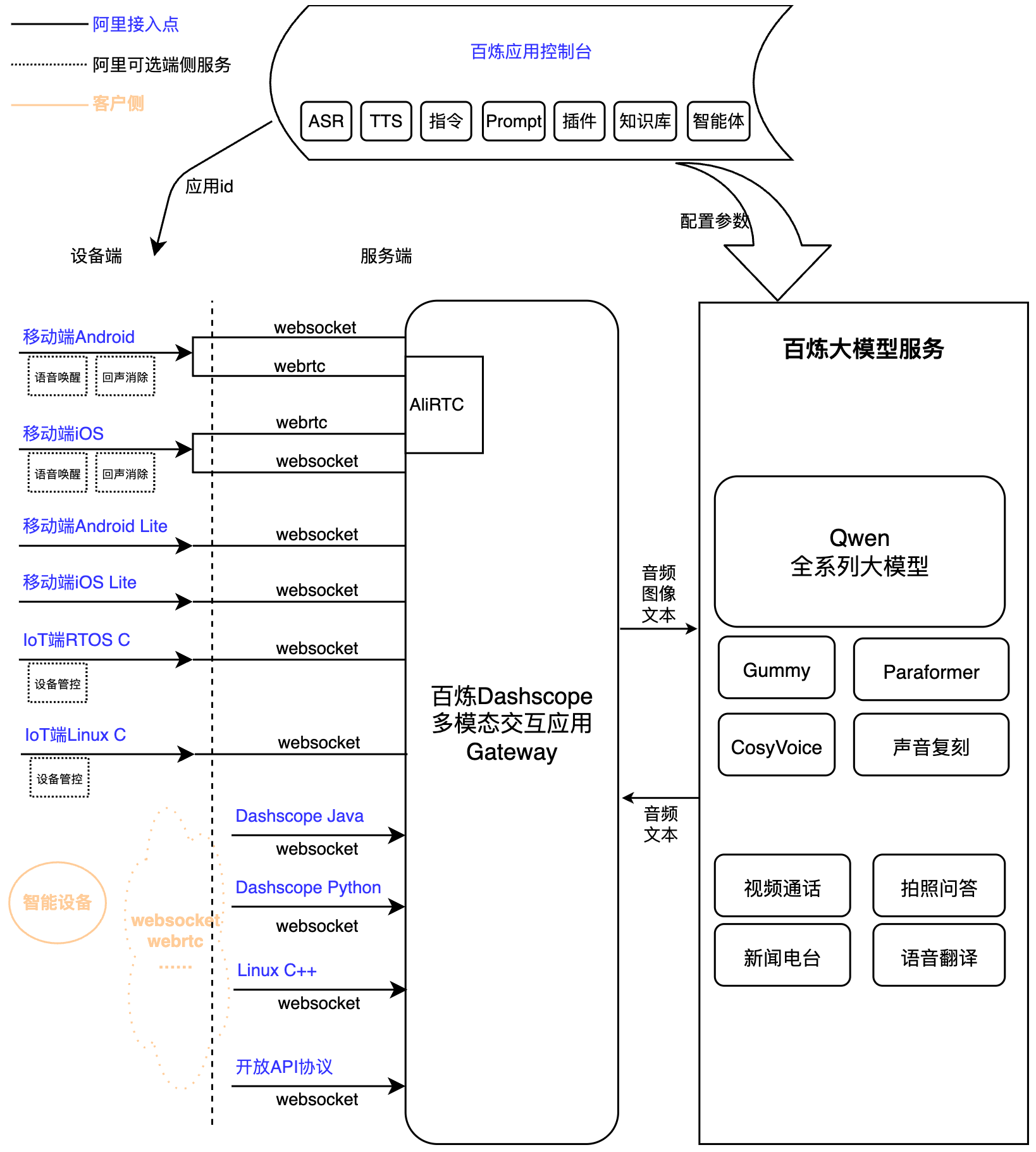
多模态实时交互服务接入架构
下载安装
最新SDK包 | 平台 | MD5 |
Linux x86_64 | a2f1935e29d7db70021e2c5c7e5c3db8 | |
Linux aarch64 (gcc-arm-10.2) | efeb135230fc36f2aa51afa64ab97e6b | |
Linux aarch64 (gcc-arm-11.2) | fd01741ce3c285e3a8bd602dc30bed67 |
音频格式说明
Websocket 链路音频格式说明:
上行:支持 pcm 和 opus 格式音频进行语音识别。仅支持用户送入pcm格式音频(16K采样率,16bit,单通道),opus格式音频由SDK内部自动完成编码。
下行:支持单通道 pcm、mp3和opus 音频流。其中opus音频流将会在SDK内部进行解码,用户收到的将是对应格式的pcm数据。
接口说明
CreateConversation
创建交互,设置回调。对应销毁接口为DestroyConversation。
/**
* @brief 创建交互,设置回调。对应销毁接口为DestroyConversation
* @param onMessage : 各事件监听回调,参见下文具体回调
* @param onEventTrackMessage : 用于SDK内部日志(info以上)通过回调送给上层
* @param user_data : 回调返回
* @return Conversation* : Conversation单例指针
*/
static Conversation* CreateConversation(
const ConversationCallbackMethod onMessage,
const EventTrackCallbackMethod onEventTrackMessage,
void* user_data = NULL);其中ConversationCallbackMethod类型如下:
ConversationCallbackMethod
SDK事件回调
/**
* @brief SDK各事件回调
* @param ConvEvent*
* :回调事件,可通过调用其中具体方法获得事件及相关信息。具体方法见下方ConvEvent
* @param void* :用户设置的user_data
*/
typedef void (*ConversationCallbackMethod)(ConvEvent*, void*);ConvEvent
方法列表
方法名 | 说明 |
int GetStatusCode(); | 获取状态码,正常情况为0或者20000000,失败时对应的错误码。错误码参考SDK文档说明。 |
ConvEventType GetMsgType(); | 获取当前所发生Event的类型,详见ConvEventType。 |
ConvEventType GetSubMsgType(); | 获取当前所发生Event的子类型,当ConvEvent::kRTCMessage时使用。 |
const char* GetAllResponse(); | 获得此ConvEvent的完整JSON格式response。 |
const char* GetErrorMessage(); | 获得错误信息。 |
const char* GetTaskId(); | 获取本次连接唯一ID,定位问题建议用dialog_id和round_id。 |
const char* GetDialogId(); | 获取对话ID。 |
const char* GetRoundId(); | 获取本轮交互的ID。 |
std::vector<unsigned char> GetBinaryData(); | 获取云端返回的二进制数据。当ConvEvent::kBinary时使用。 |
unsigned char* GetBinaryDataInChar(); | 同GetBinaryData()。当ConvEvent::kBinary时使用。 |
int GetBinaryDataSize(); | 同GetBinaryData(), 获得这一次二进制数据的字节数,与GetBinaryDataInChar()搭配。当ConvEvent::kBinary时使用。 |
int GetDialogStateChanged(); | 获得对话当前状态,当ConvEvent::kDialogStateChanged时使用。
|
float GetSoundDb(); | 返回最近一次输入音频的音量db值, 范围-160~0db,当ConvEvent::kSoundLevel时使用。 |
int GetSoundLevel(); | 返回最近一次输入音频的音量db值的分级, 范围0~100,当ConvEvent::kSoundLevel时使用。 |
int GetSampleRate(); | 返回此数据的采样率。当ConvEvent::kUserBinary时使用。 |
int GetChannelSelect(); | 返回音频数据的通道选择。
当ConvEvent::kUserBinary时使用。 |
NetworkEventType GetNetworkEvent(); | 网络事件,详见NetworkEventType。当ConvEvent::kNetworkStatus时使用。 |
int GetNetworkLatency(); | 返回网络延迟信息, 单位为毫秒。当ConvEvent::kNetworkStatus时使用。 |
ConvEventType
事件名称 | 事件说明 |
kConversationFailed | 会话任务发生错误,需要查看错误码及错误信息。收到此事件后需要根据错误信息判断如何处理,也可以使用此dialog_id重新连接,继续会话。 |
kConversationConnected | 与AI服务建连成功。 |
kConversationInitialized | AI(服务端)初始化完成, 返回初始化信息。 |
kConversationStarted | AI(服务端)登场, 会话任务成功启动, 建连成功。 |
kConversationCompleted | AI(服务端)退场。任务成功完成,执行断连操作。 |
kSentenceBegin | HUMAN开始说话。PushToTalk模式按键则触发此事件,TapToTalk和Duplex模式是用户开始说话触发此事件。 |
kSentenceEnd | HUMAN说话结束。PushToTalk模式按键松开则触发此事件,TapToTalk和Duplex模式是用户说话结束触发此事件。 |
kDataOutputStarted | AI(服务端)开始传送TTS数据。 |
kDataOutputCompleted | AI(服务端)TTS数据合成完成且发送完成。 |
kBinary | 表示此ConvEvent中包含AI(服务端)传回的TTS数据包。 |
kSoundLevel | 最近一次传入的HUMAN说话声音数据的音量值。 |
kDialogStateChanged | 对话状态发生变化。 |
kInterruptAccepted | AI(服务端)接收指令打断(如按键打断)请求。 |
kInterruptDenied | AI(服务端)拒绝指令打断(如按键打断)请求。 |
kVoiceInterruptAccepted | AI(服务端)接收语音打断请求。 |
kVoiceInterruptDenied | AI(服务端)拒绝语音打断请求。 |
kConnectionDisconnected | SDK与服务端断开链接。 |
kConnectionConnected | SDK与服务端链接。 |
kHumanSpeakingDetail | 用户语音识别出的详细信息,比如文本。 |
kRespondingDetail | 系统对外输出的详细信息,比如LLM大模型返回的结果。 |
kNetworkStatus | 网络状态信息, 比如网络延迟。 |
kKeywordSpotted | 触发唤醒。 |
kKeywordTrusted | 触发唤醒并确认确实唤醒。 |
kVoiceTimeout | 触发唤醒后长时间无人说话退出唤醒态。 |
kOtherMessage | 未定义消息。 |
kUserBinary | RTC模式使用,表示此ConvEvent中包含HUMAN(用户)传回的MIC数据包。 |
kRTCMessage | 表示将事件整理成RTC消息,具体事件查看GetSubMsgType()。 |
kConversationStart | RTC模式使用,"StartedReceived"事件。 |
kConversationStop | RTC模式使用,"Stop"事件。 |
kSendSpeech | RTC模式使用,"SendSpeech"事件。 |
kStopSpeech | RTC模式使用,"StopSpeech"事件。 |
kRequestToSpeak | RTC模式使用,"RequestToSpeak"事件。 |
kRequestToRespond | RTC模式使用,"RequestToRespond"事件。 |
kLocalRespondingStarted | RTC模式使用,"LocalRespondingStarted"事件。 |
kLocalRespondingEnded | RTC模式使用,"LocalRespondingEnded"事件。 |
kAvatarStateChanged | RTC模式使用,"AvatarStateChanged"事件。 |
NetworkEventType
事件名称 | 事件说明 |
kNetworkEventUnknown | 无。 |
kNetworkEventLatency | 网络延迟事件。 |
其中EventTrackCallbackMethod类型如下:
EventTrackCallbackMethod
获得关键埋点信息日志
/**
* @brief SDK内部日志通过回调送给用户处理
* @param ConvLogLevel :返回日志的日志级别
* @param const char* :具体日志字符串
* @param void* :用户设置的user_data
*/
typedef void (*EventTrackCallbackMethod)(ConvLogLevel, const char*, void*);
enum ConvLogLevel {
kConvLogLevelVerbose,
kConvLogLevelDebug,
kConvLogLevelInfo,
kConvLogLevelWarning,
kConvLogLevelError,
kConvLogLevelNone,
};DestroyConversation
销毁交互。对应创建接口为CreateConversation。
/**
* @brief 销毁交互,若交互进行中,则内部完成Disconnect()
* @return ConvRetCode : 状态码
*/
ConvRetCode DestroyConversation();Connect
组装一个start请求,用于发起对服务端的链接。返回成功并不代表与VoiceChat Server链接成功,仅代表发起start请求构建成功,是否链接成功以返回的Response为准。
/**
* @brief 与服务端建立链接
* @param params :json string形式的初始化参数
* @return ConvRetCode : 状态码
*/
ConvRetCode Connect(const char* params);百炼参数设置说明
一级参数 | 二级参数 | 三级参数 | 类型 | 必须 | 说明 |
apikey | String | 是 | 临时凭证,具体请查看获取API Key。 | ||
workspace | String | 是 | 资源文件所在目录,即资源文件所在目录。 若为02C版本(纯云端RTC),可不设置。 若为02A/02E版本(带本地AEC&VAD),必须设置。 | ||
url | String | 是 | 请求的网关域名,百炼请求域名:"wss://dashscope.aliyuncs.com/api-ws/v1/inference",设置百炼请求域名时则ws_version自动切换到百炼交互协议。 | ||
chain_mode | String / int | 是 | 默认“ws”或0。可选“ws”或0、“rtc”或1,前者启用Websocket交互方式,后者启用RTC交互方式。 | ||
ws_version | int | 否 | 交互协议版本,默认情况无需设置。 若url设置为百炼域名,此参数自动设置为3,即选择百炼协议。 | ||
rtc_version | int | 否 | 交互协议版本,默认情况无需设置。 若使用百炼交互协议,此参数设置为3。 | ||
app_id | String | 是 | url选用百炼域名时即ws_version为3时,必填app_id,否则无需设置。 | ||
workspace_id | String | 是 | 用户业务空间id。 | ||
dialog_id | String | 否 | 对话id,空代表新的对话,传入则代表继续通话。格式为32位随机字符串。 | ||
mode | String | 否 | 运行模式,默认"duplex"或"mix_duplex"。
注意:SDK中的AEC为软件AEC, 需使用回声硬参考,保障mic和ref时延严格稳定对齐。推荐使用硬件AEC。 | ||
debug_path | String | 否 | 日志和音频文件存储目录,不设置则会在workspace下创建debug目录。 | ||
save_log | boolean | 否 | 是否存储日志,默认false。 | ||
save_wav | boolean | 否 | 是否存储音频,默认false。 | ||
log_level | String | 否 | 日志级别,默认"info"或2,可选择"verbose/debug/info/warn(warning)/error"或0/1/2/3/4。 | ||
ping_interval_ms | int | 否 | 统计网络延迟的操作间隔,即每次上报网络延迟回调的间隔时间,单位毫秒。不小于1000ms。 | ||
channel_select | int | 否 |
若为02C版本(纯云端RTC),则默认1,即返回MIC的音频数据。 | ||
voice_activity_detection_attributes | JSONObject | 否 | 人声检测VAD相关参数。 | ||
enable_external_vad_module | boolean / String | 否 | 启用外部VAD模块,启用后即设置true/"true"时,将关闭内部VAD模块,使用外部VAD。 | ||
enable_vad_module | boolean / String | 否 | 启用VAD模块,默认为false/"false"。此参数与enable_external_vad_module联合设置,两者均为false/"false"时,表示关闭VAD模块,只使用云端VAD功能。 | ||
acoustic_echo_cancelling_attributes | JSONObject | 否 | 回声消除AEC相关参数。 | ||
enable_external_aec_module | boolean / String | 否 | 启用外部AEC模块,启用后即设置true/"true"时,将关闭内部AEC模块,且会忽略送入的Ref音频(也可不送入),只使用送入的Mic音频。默认false/"false",即使用内部AEC模块。 | ||
key_words_spotting_attributes | JSONObject | 否 | 唤醒相关参数。 | ||
enable_external_kws_module | boolean / String | 否 | 启用外部KWS模块,启用后即设置true/"true"时,将关闭内部KWS模块,由外部SetAction(kKeywordTrusted)来通知触发唤醒,SDK可继续后续交互流程。 "kws_duplex"模式有效。 | ||
independent_kws_mode | bool | 否 | 启用内部KWS模块的独立运行模式,默认为false。当启用时,KWS模块触发唤醒词时,SDK内部不会继续进行下一步流程,而是等待用户调用SetAction(kContinue)后SDK才继续进行下一步交互。即这段期间用户可以做其他业务相关的工作。 "kws_duplex"模式有效。 | ||
vad_asleep_tail_timeout | int | 否 | 说话人说话后多久时间未触发唤醒,则返回最初状态,默认为2000ms,单位为ms。 "kws_duplex"模式有效。 | ||
vad_awake_front_timeout | int | 否 | 唤醒后和唤醒识别后,说话人多久未说话,则退出唤醒态返回最初状态,默认为5000ms,单位ms。 "kws_duplex"模式有效。 | ||
word_list | JSONArray | 否 | 自定义唤醒词的设置,默认无需设置。 | ||
upstream | JSONObject | 是 | |||
type | String | 是 | 上行类型: AudioOnly 仅语音通话。 AudioAndVideo 上传视频。 | ||
mode | String | 否 | 运行模式,默认“duplex”,可选“tap2talk/push2talk”。 "kws_duplex"模式在这里设置为"duplex"。 | ||
sample_rate | int | 否 | 上行语音的采样率,支持范围:
默认为16000。 | ||
audio_format | String | 否 | 上行音频格式,默认为pcm,可选opus。 pcm:用户送入pcm音频数据。 opus:用户送入pcm音频数据,SDK内部编码成opus进行传送。注意,full_duplex和cloud_duplex模式不支持此格式。 raw-opus:用户送入pcm音频数据,SDK内部编码成raw-opus进行传送。 | ||
downstream | JSONObject | 否 | |||
type | String | 否 | 下行媒体类型: Text:不需要下发语音。 Audio:输出语音,默认值。 | ||
voice | String | 否 | 合成语音的音色,支持范围取决于用户在管控台的应用配置中选择的TTS模型和可选音色。具体选择范围可参考Python SDK。 | ||
sample_rate | int | 否 | 合成语音的采样率,默认由服务端指定。支持范围:
默认为24000。 | ||
audio_format | String | 否 | 下行音频格式,默认为pcm,可设置pcm、mp3和opus。用户接收到的音频参数为单通道、16bit。 注意:若用户设置opus,则由SDK内部将opus解码成pcm数据送还给用户。若用户设置mp3和pcm,则直接透传给用户。 | ||
volume | int | 否 | 合成音频的音量,取值范围0-100,默认50。 | ||
speech_rate | int | 否 | 合成音频的语速,取值范围50-200,表示默认语速的50%-200%,默认100。 | ||
pitch_rate | int | 否 | 合成音频的声调,取值范围50-200,默认100。 | ||
frame_size | int | 否 | 合成音频的帧大小,单位为毫秒。仅在downstream.audio_format为opus时生效。 取值范围:10、20、40、60、100、120。默认为60。 | ||
transmit_rate_limit | int | 否 | 合成音频发送速率限制,单位:字节每秒。默认无限制。 | ||
intermediate_text | String | 否 | 控制返回给用户中间文本: transcript 返回用户语音识别结果。 dialog 返回对话系统回答中间结果。 可以设置多种,以逗号分割,默认为transcript。 | ||
client_info | JSONObject | 是 | |||
user_id | String | 是 | 终端用户id,用来做用户相关的处理。 | ||
device | JSONObject | 否 | 终端用户id,用来做用户相关的处理。 | ||
uuid | String | 否 | 客户端全局唯一的id,需要用户自己生成,传入SDK。 | ||
network | JSONObject | 否 | 终端用户id,用来做用户相关的处理。 | ||
ip | String | 否 | 调用方公网ip。 | ||
location | JSONObject | 否 | 终端用户id,用来做用户相关的处理。 | ||
latitude | String | 否 | 调用方维度信息。 | ||
longitude | String | 否 | 调用方经度信息。 | ||
city_name | String | 否 | 调用方所在城市。 | ||
biz_params | JSONObject | 否 | |||
user_defined_params | JSONObject | 否 | 其他需要透传给agent的参数。 | ||
user_defined_tokens | JSONObject | 否 | 透传agent所需鉴权信息。 | ||
user_prompt_params | JSONObject | 否 | 用于设置并传入用户自定义的提示词中的变量。设置方法详见示例:自定义提示词变量和传值。 | ||
user_query_params | JSONObject | 否 | 用于设置并传入用户自定义的结构化后的对话变量,是给到大模型的额外信息。搭配提示词设置,增加大模型的环境感知能力。设置方法详见示例:自定义对话变量和传值。 | ||
nls_rule | JSONObject | 否 | 万能协议参数规则制定,可直接修改Websocket协议中发送的指令。 例如: 将修改Start发送的指令中的header.custom1,和payload.task_group,payload.task。 具体修改为何值,见nls_params。 | ||
nls_params | JSONObject | 否 | 万能协议参数设置,可直接修改Websocket协议中发送的指令。 例如: 将修改Start发送的指令中的: header.custom1的值改为{"test":1}, payload.task_group的值改为"aigc", payload.task的值改为"aigc", payload.function的值改为"generation", payload.model的值改为"multimodal-dialog"。 |
Disconnect
组装一个stop请求,用于发送指令告诉服务端中止链接。返回成功并不代表与VoiceChat Server断链成功,仅代表发起stop请求构建成功,是否断链成功以返回的Response为准。
/**
* @brief 断开链接
* @return ConvRetCode : 状态码
*/
ConvRetCode Disconnect();Interrupt
打断交互,使AI进入听状态。
/**
* @brief 按键(Tap)打断。正在播放时,调用此接口请求打断播放。
* @return ConvRetCode : 状态码
*/
ConvRetCode Interrupt();SendAudioData
推送实时采集的音频数据。
/**
* @brief 推送音频数据
* @param data : 音频数据,PCM格式
* @param data_size : 音频数据字节数
* @param type : 音频数据编码设置,暂未启用,设置无效。
* @param timestamp : 此数据包的时间戳(ms)。
* @return ConvRetCode : 状态码
*/
ConvRetCode SendAudioData(const uint8_t* data, size_t data_size,
EncoderType type = kEncoderNone,
uint64_t timestamp = 0);SendRefData
推送参考音频数据,在音频数据送给播放器时推送。
/**
* @brief 推送参考音频数据,在音频数据送给播放器时推送
* @param data : 音频数据,PCM格式
* @param data_size : 音频数据字节数
* @param timestamp : 此数据包的时间戳(ms)。
* @return ConvRetCode : 状态码
*/
ConvRetCode SendRefData(const uint8_t* data, size_t data_size,
uint64_t timestamp = 0);SendResponseData
Listening/Idle状态下,通知服务端与用户主动交互,可以直接把上传的文本转换为语音下发,也可以上传文本调用大模型,返回的结果再转换为语音下发。
/**
* @brief
* 通知服务端与用户主动交互,可以直接把上传的文本转换为语音下发,也可以上传文本调用大模型,返回的结果再转换为语音下发
* @param params :json string形式的初始化参数
* @return ConvRetCode : 状态码
*/
ConvRetCode SendResponseData(const char* params);parameters参数设置
参数 | 类型 | 必须 | 说明 |
type | String | 是 | 服务应该采取的交互类型: transcript 表示直接把文本转语音。 prompt 表示把文本送大模型回答。 |
text | String | 是 | 要处理的文本,可以是""空字符串,非null即可。 |
parameters | JSONObject | 否 | |
| JSONArray | 否 | 需要分析的图片信息。 |
| JSONArray | 否 | 与Start消息中biz_params相同,传递对话系统自定义参数。RequestToRespond的biz_params参数只在本次请求中生效。 |
任意 | Any | 否 | 将会透传给协议的payload中。 |
parameters示例
切换到视频模式
{
"type": "prompt",
"parameters": {
"biz_params": {
"videos": [{
"action": "connect",
"type": "voicechat_video_channel"
}]
}
}
}退出视频模式
{
"type": "prompt",
"parameters": {
"biz_params": {
"videos": [{
"action": "exit",
"type": "voicechat_video_channel"
}]
}
}
}发送图片进行问答
# 发送图片base64数据(支持小于180KB图片)
{
"type": "prompt",
"parameters": {
"images": [{
"type": "base64",
"value": "base64String"
}]
}
}
# 发送图片链接
{
"type": "prompt",
"parameters": {
"images": [{
"type": "url",
"value": "https://xxxxxxx"
}]
}
}UpdateMessage
更新参数,如p2t参数,或者发送参数,如UpdateInfo。
/**
* @brief 发送如P2T相关的参数
* @param params : 参数
* @return ConvRetCode : 状态码
*/
ConvRetCode UpdateMessage(const char* params);更新自定义唤醒词(仅kws_duplex有效)
{
"type": "update_local_modules",
"work": "update_keywords_list",
"wuw": {
"word_list": [{
"name": "小云",
"type": "main"
}]
}
}更新其他参数
{"type":"update_nls_parameters", "avatar":{}}
{"type":"update_nls_parameters", "client_info":{}}
{"type":"update_nls_parameters", "agent_chat":{}}
//【SDK V1.2.4 新增】
{"type":"update_nls_parameters", "extra_info":{}, "context":{}}更新参数万能方法
用户自定义服务端交互参数,"type": "update_custom_nls_parameters" 表示使用用户自定义参数功能。
nls_rule 中规定参数在协议中添加的位置,如"payload": ["Start_custom2", "SendSpeech_custom3"] 表示在向服务端发送"Start"协议时,payload中添加参数"custom2":{"test":2};"header": ["Start_custom1"] 表示在向服务端发送"Start"协议时,header中添加参数"custom1":{"test":1}。
{
"type": "update_custom_nls_parameters",
"nls_rule": {
"header": ["Start_custom1"],
"payload": ["Start_custom2", "SendHumanSpeech_custom3"],
"context": ["Stop_custom4"]
},
"nls_params": {
"Start_custom1": {
"test": 1
},
"Start_custom2": {
"test": 2
},
"SendHumanSpeech_custom3": {
"test": 3
},
"Stop_custom4": {
"test": 4
}
}
}发送参数(UpdateInfo)
客户端更新事件,例如发送图片数据。
百炼协议参数
参数 | 类型 | 必须 | 说明 |
type | String | 是 | update_info。 |
parameters | JSONObject | 是 | |
| JSONArray | 否 | 图片数据。 |
| JSONObject | 否 | |
| JSONObject | 否 | 客户端当前状态。 |
| JSONObject | 否 | 与Start消息中biz_params相同,传递对话系统自定义参数。 |
百炼协议示例
{
"type": "update_info",
"parameters": {
"biz_params": {},
"client_info": {
"status": {
"bluetooth_announcement": {
"status": "stopped"
}
}
},
"images": [{
"type": "base64",
"value": "base64String"
}]
}
}发送万能参数
{
"type": "update_custom_message",
"header": {
"TEST1": "XXX"
},
"payload": {
"TEST2": "YYY"
}
}
返回的对应消息
{
"header": {
"TEST1": "XXX",
"dialog_id": "2b9bea3d2b2749a0808bae06a9da493c",
"namespace": "VoiceChat",
"request_id": "c48cfe7bbadd485db2e387136ce6608c",
"task_id": "fffffff707fe4c288869931b0eeeeeee"
},
"payload": {
"TEST2": "YYY"
}
}SetAction
需要有一个音频(播放)开始/结束事件告知到SDK。
/**
* @brief 触发SDK动作,比如音频(播放)开始/结束事件告知到SDK
* @param action : 触发的动作类型
* @param data : 此次SDK动作附带的数据, 比如音频数据比如json字符串
* @param data_size : 此次SDK动作附带的数据的字节数
* @return ConvRetCode : 状态码
*/
ConvRetCode SetAction(ConvAction action, const uint8_t* data = NULL,
size_t data_size = 0);ConvAction
枚举名 | 说明 |
kMicStarted | MIC开始工作。 |
kMicStopped | MIC停止录音。 |
kPlayerStarted | 开始播放。 |
kPlayerStopped | 播放完毕。注意:需确保播放器中缓存数据全部播放完毕后给出,否则会导致自打断或播放数据进入 ASR。 |
kEnableVoiceInterruption | 开启语音打断功能。 |
kDisableVoiceInterruption | 关闭语音打断功能。 |
kVoiceMute | 语音静音。若正在AI听阶段,则主动告知AI,用户已经说完话。 |
kVoiceUnmute | 语音静音关闭。 |
kStartHumanSpeech | 仅在push2talk模式有效, 表示用户开始说话。 注意:Connect()成功后请在收到DialogStateChanged为kDialogIdle后再调用。 |
kStopHumanSpeech | 仅在push2talk模式有效, 表示用户说话完毕。 |
kCancelHumanSpeech | 仅在push2talk模式有效, 表示用户说话取消。 |
kPullOutHeadphones | 拔耳机时调用,用于优化耳机切换的回声消除效果。 |
kContinue | 交互流程暂停时,继续下一步,比如唤醒后调用此接口继续下一步流程。 |
kVoiceDetectedBegin | 外置VAD时使用,表示检测到人开始说话。 |
kVoiceDetectedEnd | 外置VAD时使用,表示检测到人说话完毕。 |
kVoiceTimeout | 外置KWS时使用,表示人长时间未说话。 |
kKeywordTrusted | 外置KWS时使用,触发唤醒并确认确实唤醒。 |
GetState
获得当前各种状态。
/**
* @brief 获得当前状态
* @param type : 状态类型
* @return ConvRetCode : 状态码
*/
int GetState(StateType type);StateType
枚举名 | 说明 |
kTypeDialogState | 对话(AI)当前状态,枚举值为ConvConstants.DialogState。 |
kTypeConnectionState | 链接状态。 |
kTypeMicState | MIC当前状态,枚举值为ConvConstants.ConvAppAction。 |
kTypePlayerState | PLAYER当前状态,枚举值为ConvConstants.ConvAppAction。 |
DialogState
枚举名 | 说明 |
kDialogIdle | 当前处于空闲未工作状态。 |
kDialogListening | AI(服务端)处于听状态,接收用户输入数据(如MIC音频数据)。 |
kDialogResponding | AI(服务端)处于反馈状态,送出AI的数据(如TTS音频数据)。 |
kDialogThinking | AI(服务端)处于思考阶段。 |
GetResponse
向SDK送入通过RTC获得的VoiceChat相关response。response将在VideoChat Native SDK内部进行解析,转成交互状态和相关事件给APP。
/**
* @brief
* 向SDK送入通过RTC获得的VoiceChat相关response。response将在VideoChat Native
* SDK内部进行解析,转成交互状态和相关事件给APP。
* @param params :json string形式的初始化参数
* @return ConvRetCode : 状态码
*/
ConvRetCode GetResponse(const char* params);另外,如AvatarStateChanged请求的组装,处理通过updateMessage(),用此getResponse()也可,传入的格式如下:
{"type":"rtc","from_state":"2","seq_id":"1","to_state":"0"}
或
{"from_state":"2","seq_id":"1","to_state":"0"}
或
{"from_state":2,"seq_id":1,"to_state":0}
或
{"header":{"name":"AvatarStateChanged","namespace":"Conversation"},"payload":{"from_state":2,"seq_id":2,"to_state":0}}
或
{"header":{"name":"AvatarStateChanged","namespace":"Conversation"},"payload":{"from_state":"2","seq_id":"2","to_state":"0"}}代码示例
语音对话初始化
这一步通过设置回调函数来接收交互过程中的所有事件,包括对话状态、对话结果等。
void onMessage(ConvEvent* event, void* param) {
ConvEvent::ConvEventType event_type = event->GetMsgType();
int dialog_state = event->GetDialogStateChanged();
if (event_type != ConvEvent::kSoundLevel &&
event_type != ConvEvent::kBinary) {
std::cout << "trigger onMessage -->>\n"
<< " session id: " << event->GetSessionId() << "\n"
<< " messge type: " << event->GetMsgTypeString() << "\n"
<< " dialog state: " << dialog_state << "\n"
<< " response: " << event->GetAllResponse() << std::endl;
}
switch (event_type) {
case ConvEvent::kConversationFailed:
// 对话发生错误
break;
case ConvEvent::kConversationStarted:
// 对话建连成功
break;
case ConvEvent::kConversationCompleted:
break;
case ConvEvent::kSentenceBegin:
break;
case ConvEvent::kSentenceEnd:
break;
case ConvEvent::kDataOutputStarted:
// 后续将接收语音合成数据, 这里可启动播放器。
// 播放器启动后需要通知SDK
break;
case ConvEvent::kDataOutputCompleted:
// 接收语音合成数据完成, 这里需要通知播放器已经送完数据。
// 注意, 这里只是接收完语音合成数据, 而非播放完成, 缓存或播放器中还有大量数据待播放。
// 完全播放完后必须通知SDK
break;
case ConvEvent::kBinary:
break;
case ConvEvent::kSoundLevel:
break;
case ConvEvent::kDialogStateChanged:
// 可通过对话状态进行相关业务逻辑操作
break;
case ConvEvent::kInterruptAccepted:
// 允许打断, 这里可以关闭正在播放的音频
break;
case ConvEvent::kInterruptDenied:
break;
case ConvEvent::kVoiceInterruptAccepted:
// 允许打断, 这里可以关闭正在播放的音频
break;
case ConvEvent::kVoiceInterruptDenied:
break;
case ConvEvent::kHumanSpeakingDetail:
break;
case ConvEvent::kRespondingDetail:
break;
}
}
void onEtMessage(ConvLogLevel level, const char* log, void* user_data) {
std::cout << " ==>> [" << level << "] " << log << std::endl;
}
ConversationCallbackMethod on_message_callback = onMessage;
EventTrackCallbackMethod on_et_callback = onEtMessage;
Conversation* conversation = Conversation::CreateConversation(on_message_callback,
on_et_callback, NULL);语音对话发起建连
建连参数把包括账号信息以json的形式构建,具体参考接口文档。PushToTalk模式下,建连成功后对话状态处于Idle状态。
std::string gen_init_params() {
Json::FastWriter writer;
Json::Value root;
Json::Value agent_chat;
root["mode"] = g_mode;
root["chain_mode"] = "ws";
root["ws_version"] = 3;
root["debug_mode"] = "xxxxxxx";
root["workspace"] = "xxxxxxx";
root["save_log"] = true;
root["save_wav"] = true;
root["log_level"] = g_log_level;
root["url"] = "";
root["apikey"] = "";
root["app_id"] = "";
root["workspace_id"] = "";
Json::Value upstream;
upstream["type"] = "AudioOnly";
upstream["audio_format"] = "opus"; // asr格式,支持pcm,opus
root["upstream"] = upstream;
Json::Value downstream;
downstream["type"] = "Audio";
downstream["voice"] = "longxiaoxia_v2";
downstream["sample_rate"] = 24000; // default tts sample_rate is 24000
downstream["audio_format"] = "pcm"; // 下发的音频编码格式,支持opu,pcm
downstream["intermediate_text"] = "transcript,dialog";
downstream["debug"] = true;
root["downstream"] = downstream;
Json::Value client_info; /* 额外扩充的用户信息 */
client_info["user_id"] = "bin23439207";
root["client_info"] = client_info;
Json::Value dialog_attributes;
dialog_attributes["prompt"] = "你是个有用的助手。";
root["dialog_attributes"] = dialog_attributes;
Json::Value acoustic_echo_cancelling_attributes;
acoustic_echo_cancelling_attributes["enable_external_aec_module"] = false;
root["acoustic_echo_cancelling_attributes"] =
acoustic_echo_cancelling_attributes;
Json::Value voice_activity_detection_attributes;
voice_activity_detection_attributes["enable_external_vad_module"] = false;
root["voice_activity_detection_attributes"] =
voice_activity_detection_attributes;
Json::Value key_words_spotting_attributes;
key_words_spotting_attributes["enable_external_kws_module"] = false;
key_words_spotting_attributes["independent_kws_mode"] = false;
root["key_words_spotting_attributes"] = key_words_spotting_attributes;
std::string result = writer.write(root);
std::cout << "init params: " << result.c_str() << std::endl;
return result;
}
// 发起建连, 可通过返回值判断是否建连成功。
// 若建连失败可通过返回值和回调信息进行判断。
ConvRetCode ret = conversation->Connect(gen_init_params().c_str());
语音对话结束
ConvRetCode ret = conversation->Disconnect();语音对话释放
conversation->DestroyConversation();
conversation = NULL;打断当前语音对话
对话正处于Responding状态可调用此接口打断,并进入Listening状态。
ConvRetCode ret = conversation->Interrupt();PushToTalk模式用户开始说话
对话状态处于Idle状态时调用此接口,对话状态进入Listening。若对话状态处于Responding和Thinking,则打断当前状态重新进入Listening。调用接口成功后,用户所说的话持续送给服务端进行交互,直到停止。
ConvRetCode ret = conversation->SetAction(kStartHumanSpeech);PushToTalk模式用户结束说话
用户所说的话持续送给服务端进行交互,直到调用此接口,AI将根据用户所说的话进行对应的反馈。
ConvRetCode ret = conversation->SetAction(kStopHumanSpeech);文本合成TTS
SDK支持通过文本直接请求服务端合成音频。
您需要在客户端处于Listening状态下发送SendResponseData()请求。
若当前状态非Listening,需要先调用Interrupt()接口打断当前播报。
Json::Value root;
root["text"] = "幸福是一种技能,是你摒弃了外在多余欲望后的内心平和。";
root["type"] = "transcript";
Json::StreamWriterBuilder writer;
writer["indentation"] = "";
ConvRetCode ret = conversation->SendResponseData(Json::writeString(writer, root).c_str());VQA交互发送图片实现多模交互
VQA 是在对话过程中通过发送图片实现图片+语音的多模交互的功能。
核心过程是语音或者文本通过SendResponseData()接口发送多模交互指令。
Json::Value root;
root["text"] = "看看图片里是什么?";
root["type"] = "prompt";
Json::Value parameters;
Json::Value biz_params;
biz_params["user_defined_params"] = Json::Value(Json::objectValue);
Json::Value videos(Json::arrayValue);
{
Json::Value video1;
video1["action"] = "connect";//进入视频模式
video1["type"] = "voicechat_video_channel";
videos.append(video1);
Json::Value video2;
video2["action"] = "exit";//退出视频模式
video2["type"] = "voicechat_video_channel";
videos.append(video2);
}
biz_params["videos"] = videos;
parameters["biz_params"] = biz_params;
Json::Value images(Json::arrayValue);
{
Json::Value image;
// 发送图片base64数据的示例
// 这里base64encode可借用SDK的辅助接口也可自行实现
ConversationUtils utils;
image["type"] = "base64";
image["value"] = utils.Base64EncodeFromFilePath(path/*图片路径*/);
// 发送图片链接的示例
image["type"] = "url";
image["value"] = "https://xxxx";
images.append(image);
}
parameters["images"] = images;
root["parameters"] = parameters;
Json::StreamWriterBuilder writer;
writer["indentation"] = "";
ConvRetCode ret = conversation->SendResponseData(Json::writeString(writer, root).c_str());LiveAI交互发送图片实现多模交互
若使用此功能,需要Connect()入参中upstream.type设置为AudioAndVideo,即通过UpdateInfo接口持续发送图片数据来实现图片+语音的多模交互。图片大小只支持720p、480p。视频模式每500ms传一次。
// 发送图片base64数据的示例
// 这里base64encode可借用SDK的辅助接口也可自行实现
ConversationUtils utils;
std::string base64_content = utils.Base64EncodeFromFilePath(path/*图片路径*/);
if (!base64_content.empty()) {
Json::Value root;
root["type"] = "update_info";
Json::Value parameters;
parameters["biz_params"] = Json::objectValue;
Json::Value client_info;
Json::Value status;
Json::Value bluetooth_announcement;
bluetooth_announcement["status"] = "stopped";
status["bluetooth_announcement"] = bluetooth_announcement;
client_info["status"] = status;
parameters["client_info"] = client_info;
Json::Value image;
image["type"] = "base64";
image["value"] = base64_content;
image["width"] = 480;
image["height"] = 720;
Json::Value images(Json::arrayValue);
images.append(image);
parameters["images"] = images;
root["parameters"] = parameters;
Json::StreamWriterBuilder writer;
writer["indentation"] = "";
conversation->UpdateMessage(Json::writeString(writer, root).c_str());
}自定义提示词变量和传值
在管控台项目【提示词】配置自定义变量。
定义了一个user_name字段代表用户昵称。并将变量user_name以占位符形式${user_name} 插入到Prompt 中。
在控制台提示词编辑区顶部可通过自定义变量入口添加变量字段,并在Prompt正文中以${变量名}占位符形式引用。
在代码中设置变量。
如下示例,设置"user_name" = "大米"。
/* 以下示例在<语音对话发起建连>的示例上, 新增传入参数biz_params */
std::string gen_init_params() {
/* 其他初始化参数不再赘述, 请看<语音对话发起建连> */
Json::Value biz_params;
Json::Value user_prompt_params;
user_prompt_params["user_name"] = "大米";
biz_params["user_prompt_params"] = user_prompt_params;
root["biz_params"] = biz_params;
std::string result = writer.write(root);
std::cout << "init params: " << result.c_str() << std::endl;
return result;
}
// 发起建连, 可通过返回值判断是否建连成功。
// 若建连失败可通过返回值和回调信息进行判断。
ConvRetCode ret = conversation->Connect(gen_init_params().c_str());
自定义对话变量和传值
在管控台项目【对话变量】配置自定义变量。
添加一个name变量代表面前的人,添加一个emotion变量代表用户的心情。
在控制台提示词编辑区下方的对话变量面板中,单击右上角+ 添加按钮,依次录入变量名(如name、emotion)和对应描述(如面前的人、用户的心情)。
在代码中设置变量。
如下示例,设置"name" = "张三"和"emotion" = "难过"。
/* 以下示例在<语音对话发起建连>的示例上, 新增传入参数biz_params */
std::string gen_init_params() {
/* 其他初始化参数不再赘述, 请看<语音对话发起建连> */
Json::Value biz_params;
Json::Value user_query_params;
user_query_params["name"] = "张三";
user_query_params["emotion"] = "难过";
biz_params["user_query_params"] = user_query_params;
root["biz_params"] = biz_params;
std::string result = writer.write(root);
std::cout << "init params: " << result.c_str() << std::endl;
return result;
}
// 发起建连, 可通过返回值判断是否建连成功。
// 若建连失败可通过返回值和回调信息进行判断。
ConvRetCode ret = conversation->Connect(gen_init_params().c_str());
SDK错误码
枚举值 | 枚举 | 说明 |
0 | kSuccess | |
10 | kDefaultError | |
11 | kMemAllocError | 内存分配失败 |
50 | kInitFailed | 初始化为不支持的模式 |
51 | kNotConnected | 链接失败,如联网超时等 |
52 | kEngineNull | 交互引擎未创建,不可使用 |
53 | kIllegalParam | 设置参数非法 |
54 | kIllegalInitParam | 初始化参数非法 |
55 | kInvalidState | 当前交互状态无法调用此接口 |
56 | kHasInvoked | 已经调用了此接口 |
57 | kNotCreateConversation | 还未创建会话即未调用createConversation就开始操作 |
58 | kSkipSendData | 当前交互状态忽略此次音频 |
59 | kSendDataFailed | 发送音频失败 |
60 | kInvalidAudioData | 无效音频 |
61 | kStopFailed | stop()失败,如超时 |
62 | kCancelFailed | cancel()失败,如超时 |
63 | kInvokeTimeout | 接口调用超时 |
64 | kRequestDenied | 打断请求拒绝 |
65 | kRequestAccepted | 允许打断请求 |
66 | kSkipDestroyConversation | 当前SDK未创建,跳过释放操作 |
67 | kInvokeInvalidAction | SetAction()调用错误事件 |
100 | kCeiInitFailed | 内部引擎初始化失败,常发生于connect()时 |
101 | kCeiSetParamFailed | 内部引擎配置参数失败 |
111 | kVadSdkFileNotFound | 内部引擎因为找不到资源文件而初始化失败,请检查资源文件是否完备,且是最新版本 |
112 | kVadSdkInvalidParam | 内部vad引擎的初始化参数非法 |
113 | kVadSdkInvalidState | 内部vad引擎运行处于异常状态,比如vad已经释放 |
114 | kVadSdkProcessFailed | 内部vad引擎在异常状态送入数据 |
115 | kVadSdkCreateFailed | 内部vad引擎初始化失败,一般是由于资源文件缺失或者不兼容的旧版本 |
200 | kEmptyConvEvent | 非法ConvEvent |
201 | kInvalidConvEventMsgType | 非法的ConvEvent事件类型 |
301 | kServerNotAccess | 链接服务端失败,比如服务端不可链接,dns不可解析等 |
310 | kNoSupportMode | 不支持的服务端交互协议 |
311 | kJsonFormatError | 接收到服务端返回的消息不符合JSON格式 |
312 | kSslError | SSL失败,比如握手失败 |
313 | kSslConnectFailed | SSL链接失败 |
350 | kNlsIsNullptr | |
351 | kNlsInvokeTimeout | 向服务端发送请求操作超时 |
352 | kNlsStartFailed | 向服务端发送建立会话请求失败,常为网络问题 |
353 | kNlsStopFailed | 向服务端发送停止会话请求失败,常为网络问题 |
354 | kNlsCancelFailed | 向服务端发送停止会话请求失败,常为网络问题 |
355 | kNlsStartInboundFailed | 向服务端发送启动对话任务请求失败,常为网络问题 |
358 | kNlsCancelBoundFailed | 向服务端发送停止对话任务请求失败,常为网络问题 |
359 | kNlsSetParamsFailed | 设置请求参数错误,比如设置token无效 |
360 | kNlsSendAudioFailed | 向服务端发送音频数据失败,常为网络问题 |
361 | kNlsControlFailed | UpdateInfo等向服务端发送指令失败 |
400 | kEncoderExistent | |
401 | kDecoderExistent | |
402 | kEncoderInexistent | 编码器不存在 |
403 | kDecoderInexistent | |
404 | kOpusEncoderCreateFailed | Opus编码器创建失败 |
405 | kOpusDecoderCreateFailed | |
406 | kOggOpusEncoderCreateFailed | OggOpus编码器创建失败 |
407 | kInvalidEncoderType | encoder类型无效 |
500 | kInvalidAkId | 阿里云账号ak id无效 |
501 | kInvalidAkSecret | 阿里云账号ak secret无效 |
502 | kInvalidAppKey | 项目appKey无效 |
503 | kInvalidDomain | domain无效 |
504 | kInvalidAction | action无效 |
505 | kInvalidServerVersion | ServerVersion无效 |
506 | kInvalidServerResource | ServerResource无效 |
507 | kInvalidRegionId | RegionId无效 |
508 | kClientRequestFaild | 账号客户端请求失败 |
509 | kInvalidUrlCmd | 无效的url |
510 | kInvalidTokenCmd | 无效的token指令 |
511 | kTokenConnectFailed | 链接token服务器失败 |
512 | kTokenResponseError | token返回失败 |
时序图说明
duplex

push2talk
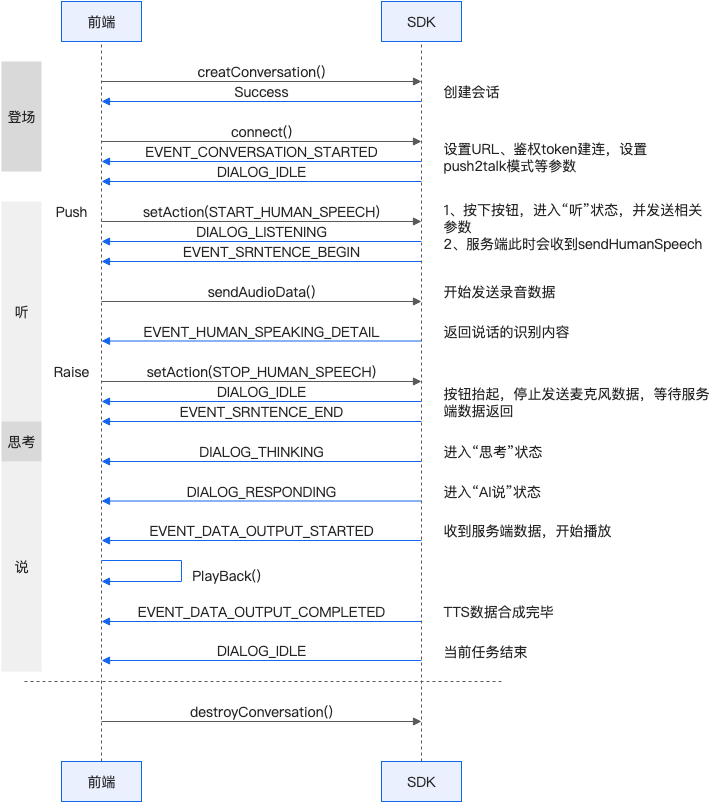
tap2talk
