
本文介绍了如何使用阿里云百炼大模型服务提供的实时多模交互移动端iOS Lite SDK,包括SDK下载安装、关键接口及代码示例。
MultiModalDialog SDK是阿里云通义团队提供的支持音视频端到端多模实时交互的SDK。通过SDK对接千问大模型以及后端多种Agent,能够支持用户接入语音对话、天气、音乐、新闻等多种能力,并支持视频和图像的大模型对话能力。
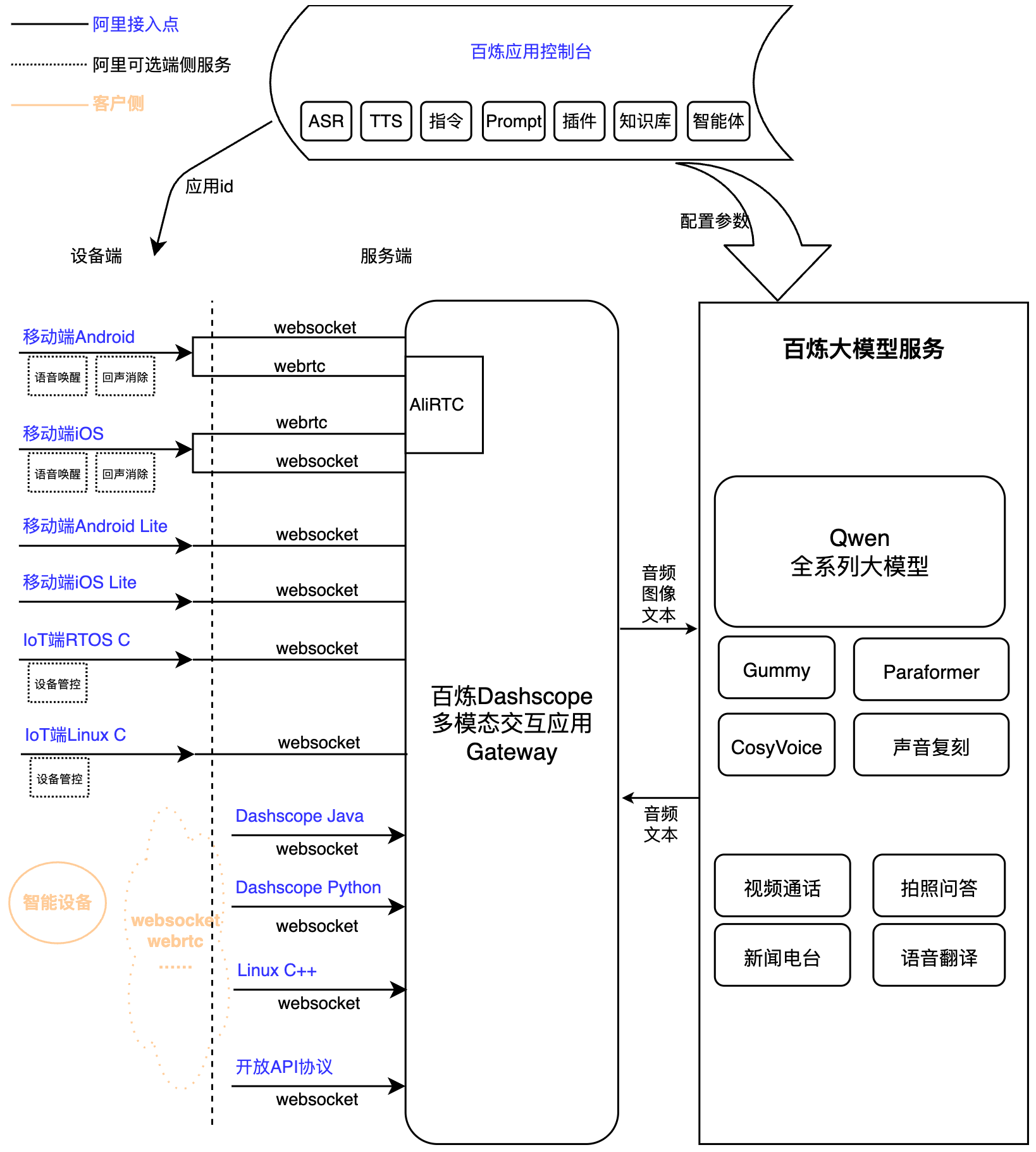
多模态实时交互服务架构
前提条件
开通阿里云百炼实时多模交互应用,获取Workspace ID、APP ID和API Key。
交互数据链路说明
多模对话iOS Lite SDK仅支持Websocket链路与服务端交互,并支持AudioOnly 音频模式进行对话:
音频交互:推荐使用Websocket 连接,连接速度较快,性能要求较低。
WS 链路音频格式说明:
上行:支持 pcm 和 opus 格式音频进行语音识别。
下行:支持 pcm 和 mp3 音频流。
交互模式说明
SDK支持 Push2Talk、 Tap2Talk和Duplex(全双工)三种交互模式。
Push2Talk: 长按说话,抬起结束(或者点击开始,点击结束 )的收音方式。
Tap2Talk: 点击开始说话,自动判断用户说话结束的收音方式。
Duplex: 全双工交互,连接开始后支持任意时刻开始说话,支持语音打断。
注意:全双工交互需要客户端集成回声消除算法(AEC),Lite SDK不提供此算法模块。您可以自行集成回声消除算法模块,或者使用百炼多模对话全功能移动端iOS SDK。
环境和依赖
导入SDK dashscope-lite-ios-demo-1.0.1.zip
DashscopeLite.framework 百炼多模对话Lite SDK。
其他依赖:
'SocketRocket', '~> 0.7.1'
百炼环境接入
接口说明
MultimodalDialog
服务入口类
1 MultiModalDialog
初始化服务对象,设置对话参数和回调。
/// 初始化多模态对话管理器
/// - Parameters:
/// - url: 服务URL
/// - workSpaceId: 工作空间ID,在百炼管控台获取
/// - appId: 应用ID, 多模对话管控台配置
/// - mode: 对话模式 (tap2talk/push2talk/duplex)
public init(url: String?, workSpaceId: String, appId:String ,mode: DialogMode)2 start
启动对话服务. 返回onConversationStarted回调。
/// 发起对话请求,连接到对话服务
/// - Parameters:
/// - apiKey: API密钥
/// - params: 多模态请求参数
/// - completion: 完成回调,返回连接是否成功及错误信息
public func start(apiKey: String, params: MultiModalRequestParam, completion: @escaping (Bool, TYError?) -> Void ) 3 startSpeech
通知服务端开始上传音频,注意需要在Listening状态才可以调用。只需要在push2talk/tap2talk模式下调用。
/// 开始说话(按下说话模式)
public func startSpeech()4 sendAudioData
通知服务端上传音频。
/// 发送音频数据
/// - Parameters:
/// - data: 音频数据指针
/// - length: 数据长度
/// - Returns: 状态码
public func sendAudioData(data: UnsafeMutablePointer<UInt8>, length: Int32) -> Int32? 5 stopSpeech
通知服务端结束上传音频。只需要在push2talk模式下调用。
/// 停止说话(按下说话模式)
public func stopSpeech()
6 interrupt
通知服务端,客户端需要打断当前交互,开始说话。会返回RequestAccepted。
// 中断当前对话
public func interrupt()7 sendLocalRespondingStarted
通知服务端,客户端开始播放tts音频。
/// 发送响应开始信号
public func sendLocalRespondingStarted()8 sendLocalRespondingEnded
通知服务端,客户端结束播放tts音频。
/// 发送响应结束信号
public func sendLocalRespondingEnded()
9 stop
结束当前轮次对话。断开服务端连接。
/// 断开连接
public func stop()10 requestToRespond
端侧主动通过文本发起tts语音合成,或者向服务端发起图片等其他请求。
/// 请求响应
/// - Parameters:
/// - type: 请求类型
/// - text: 请求文本
/// - params: 附加参数
public func requestToRespond(type:String, text:String, params:[String : Any])11 updateInfo
更新参数信息等操作。
/// 更新信息
/// - Parameter params: 更新参数
public func updateInfo(params:[String : Any])Callback
提供给用户层的回调函数。
/// 服务端建联成功回调
public var onConnected: (() -> Void)?
/// 对话服务协议完成,可以开始说话的回调
public var onConversationStarted: (() -> Void)?
/// 音频事件回调。SpeechStarted/SpeechEnded/RespondingStarted/RespondingEnded
public var onConversationEvent: ((DialogEvent) -> Void)?
/// Idle/Listening/Thinking/Responding状态转换回调
public var onConversationStatechanged: ((DialogState) -> Void)?
/// 收到语音识别文本回调
public var onSpeechContent: (([String: Any]?) -> Void)?
/// 收到LLM大模型回复文本回调
public var onRespondingContent: (([String: Any]?) -> Void)?
/// 错误回调
public var onErrorReceived: ((TYError) -> Void)?
/// 合成音频数据回调
public var onSynthesizedData: ((UnsafeMutablePointer<UInt8>, Int32) -> Void)?
/// websocket连接关闭
public var onWebsocketClosed:((_ code: Int,_ reason: String?) -> Void)?MultiModalRequestParam
请求参数类
请求参数均支持builder模式设置参数,参数的值和说明参考如下。以下是客户端需要/可选配置的参数。
Start建联请求参数
一级参数 | 二级参数 | 三级参数 | 四级参数 | 类型 | 是否必选 | 说明 |
input | workspace_id | string | 是 | |||
app_id | string | 是 | 客户在管控台创建的应用 ID,可以根据值规律确定使用哪个对话系统 | |||
dialog_id | string | 否 | 对话id,如果传入表示接着聊 | |||
parameters | upstream | type | string | 是 | 上行类型: AudioOnly 仅语音通话 AudioAndVideo 上传视频 | |
mode | string | 否 | 客户端使用的模式,可选项:
默认tap2talk | |||
audio_format | string | 否 | 音频格式,支持pcm,opus,默认为pcm | |||
downstream | voice | string | 否 | 合成语音的音色 | ||
sample_rate | int | 否 | 合成语音的采样率,默认采样率24000Hz | |||
intermediate_text | string | 否 | 控制返回给用户那些中间文本: transcript 返回用户语音识别结果 dialog 返回对话系统回答中间结果 可以设置多种,以逗号分割,默认为transcript | |||
audio_format | string | 否 | 音频格式,支持pcm,mp3,默认为pcm | |||
client_info | user_id | string | 是 | 终端用户id,用来做用户相关的处理 | ||
device | uuid | string | 否 | 客户端全局唯一的id,需要用户自己生成,传入SDK | ||
network | ip | string | 否 | 调用方公网ip | ||
location | latitude | string | 否 | 调用方维度信息 | ||
longitude | string | 否 | 调用方经度信息 | |||
city_name | string | 否 | 调用方所在城市 | |||
biz_params | user_defined_params | object | 否 | 其他需要透传给agent的参数 | ||
user_defined_tokens | object | 否 | 透传agent所需鉴权信息 | |||
tool_prompts | object | 否 | 透传agent所需prompt |
RequestToRespond 请求参数
一级参数 | 二级参数 | 三级参数 | 类型 | 是否必选 | 说明 |
input | type | string | 是 | 服务应该采取的交互类型: transcript 表示直接把文本转语音 prompt 表示把文本送大模型回答 | |
text | string | 是 | 要处理的文本,可以是""空字符串,非null即可 | ||
parameters | images | list[] | 否 | 需要分析的图片信息 | |
biz_params | object | 否 | 与Start消息中biz_params相同,传递对话系统自定义参数。RequestToRespond的biz_params参数只在本次请求中生效。 |
UpdateInfo 请求参数
一级参数 | 二级参数 | 三级参数 | 类型 | 是否必选 | 说明 |
parameters | images | list[] | 否 | 图片数据 | |
client_info | status | object | 否 | 客户端当前状态 | |
biz_params | object | 否 | 与Start消息中biz_params相同,传递对话系统自定义参数 |
对话状态说明(DialogState)
voicechat服务有LISTENING、THINKING、RESPONDING三个状态,分别代表:
IDLE("Idle"), 系统尚未建立连接
LISTENING("Listening"), 表示机器人正在监听用户输入。用户可以发送音频。
THINKING("Thinking"),表示机器人正在思考。
RESPONDING("Responding")表示机器人正在生成语音或语音回复中。对话LLM输出结果
对话结果通过onMessageReceived 回调,格式如下。
一级参数 | 二级参数 | 三级参数 | 类型 | 是否必选 | 说明 |
output | event | string | 是 | 事件名称如:RequestAccepted | |
dialog_id | string | 是 | 对话id | ||
round_id | string | 是 | 本轮交互的id | ||
llm_request_id | string | 是 | 调用llm的request_id | ||
text | string | 是 | 系统对外输出的文本,流式全量输出 | ||
spoken | string | 是 | 合成语音时使用的文本,流式全量输出 | ||
finished | bool | 是 | 输出是否结束 | ||
extra_info | object | 否 | 其他扩展信息,目前支持: commands: 命令字符串 agent_info: 智能体信息 tool_calls: 插件返回的信息 dialog_debug: 对话debug信息 timestamps: 链路中各节点时间戳 |
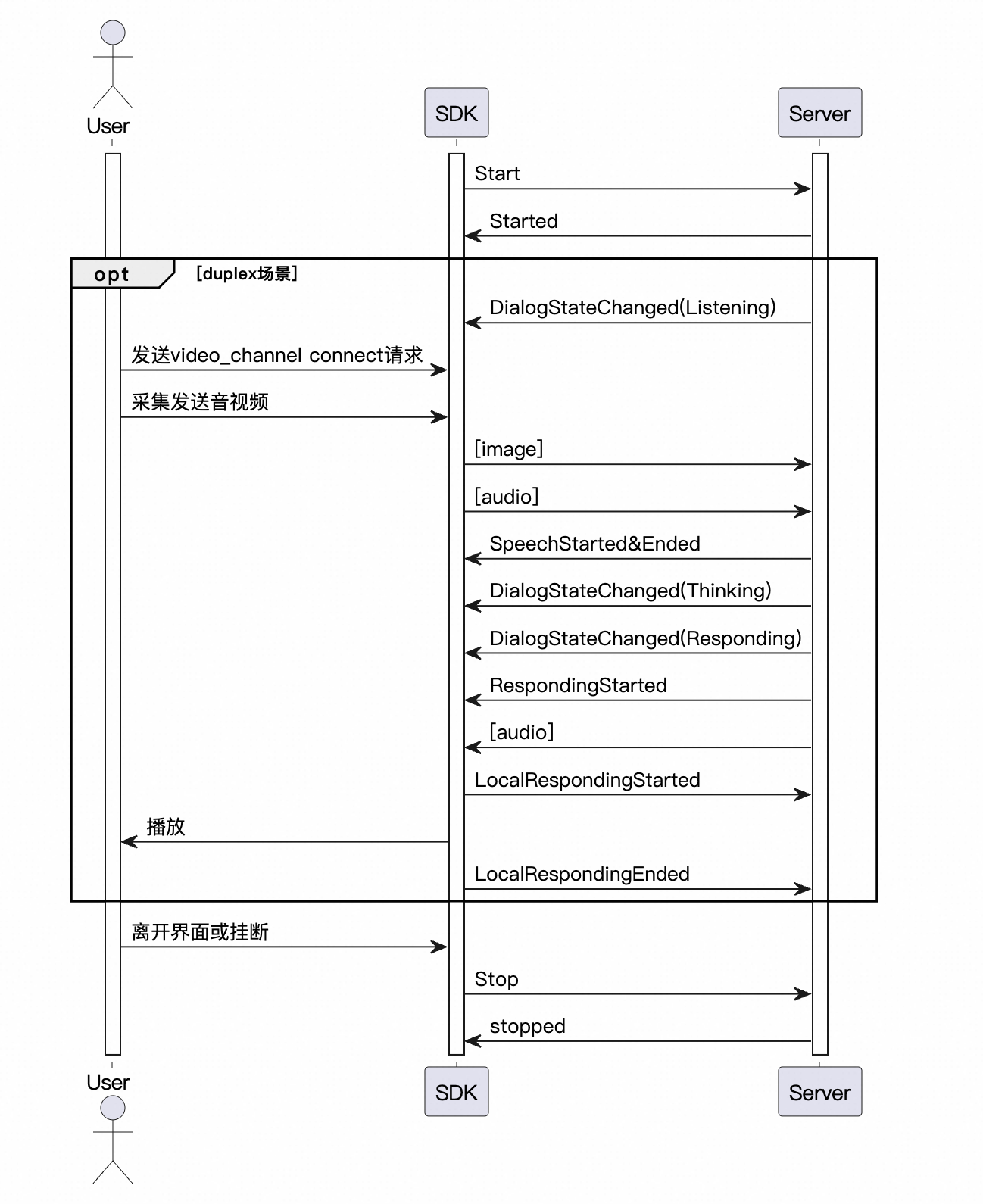
调用交互时序图

调用示例
初始化对话参数
调用MultiModalRequestParam类中的各子类的builder方法构建参数。
var params = MultiModalRequestParam{ multiBuilder in
multiBuilder.upStream = MultiModalRequestParam.UpStream(builder: { upstreamBuilder in
upstreamBuilder.mode = DialogMode.duplex.rawValue
upstreamBuilder.type = "AudioOnly"
})
multiBuilder.clientInfo = MultiModalRequestParam.ClientInfo(builder: {
clientInfoBuilder in
clientInfoBuilder.userId = "test-ios-user"
clientInfoBuilder.device = MultiModalRequestParam.ClientInfo.Device(uuid: "12345")
})
multiBuilder.downStream = MultiModalRequestParam.DownStream(builder: {
downStreamBuilder in
downStreamBuilder.sampleRate = 48000
})
}创建MultiModalDialog对象
self.conversation = MultiModalDialog(url: self.HOST, workSpaceId:self.WORKSPACE_ID ,
appId: self.APP_ID, mode: DialogMode.duplex)完整调用示例
参考章节环境和依赖下载的Demo 工程中ChatViewController相关调用。
更多SDK接口使用说明
VQA交互
VQA 是对话过程中通过发送图片实现图片+语音的多模交互的功能。
核心过程是语音或者文本请求拍照意图触发"visual_qa"拍照指令。
当收到拍照指令后, 发送图片链接或者base64数据(支持小于180KB的图片)。
建联后发起拍照请求。
//创建图片请求参数
private func createImageParams() -> [String: Any]{
var imageObject:[String: Any] = [
"type":"url",
"value":self.image_url ?? ""
]
//或者使用图片base 64编码直接上传。注意只支持180KB 以下大小图片
var imageObjectBase64:[String: Any] = [
"type":"base64",
"value":"imagebase64"
]
var images = [imageObject]
var updateParam = MultiModalRequestParam{ multiBuilder in
multiBuilder.images = images
}
return updateParam.parameters
}
//发起请求
self.conversation?.requestToRespond(type: "prompt", text: "", params: self.createImageParams())通过 Websocket 链路请求LiveAI
LiveAI (视频通话)是百炼多模交互提供的官方Agent。通过iOS Lite SDK, 您可以在Websocket链路中通过自行录制视频帧的方式来调用视频通话功能。
注意:通过 Websocket 调用 LiveAI发送图片只支持base64编码,每张图片的大小在180K以下。
LiveAI调用时序
关键代码示例
请注意参照如下的调用流程实现 通过Websocket 协议调用 LiveAI。
//1. 设置交互类型为AudioAndVideo
multiBuilder.upStream = MultiModalRequestParam.UpStream(builder: { upstreamBuilder in
upstreamBuilder.mode = mode.rawValue
upstreamBuilder.type = "AudioAndVideo"
})
//2. 初始化 MultiModalDialog 实例,选择 RTC 链路 chainMode: ChainMode.RTC
self.conversation = MultiModalDialog(url: self.HOST, chainMode: self.chain, workSpaceId:self.WORKSPACE_ID ,
appId: self.APP_ID, mode: mode)
//3. 在建联后发送voicechat_video_channel 请求
private func createVideoChatParams() -> [String: Any]{
var video:[String: Any] = [
"action":"connect",
"type" : "voicechat_video_channel"
]
var videos = [video]
var updateParam = MultiModalRequestParam{ multiBuilder in
multiBuilder.bizParams = MultiModalRequestParam.BizParams(builder: {
bizBuilder in
bizBuilder.videos = videos
})
}
return updateParam.parameters
}
//4. 每 500ms 提交一张视频帧照片数据,注意图片尺寸小于 180KB。
/**
* DEMO 流程未调用。演示在 websocket 链路中实现 liveAI
* 启动视频帧流,每 500ms 发送一次图片帧
*/
//开始后台执行发送图片的操作
func startPeriodicExecution() {
timer = DispatchSource.makeTimerSource(queue: queue)
timer?.schedule(deadline: .now(), repeating: .milliseconds(500))
timer?.setEventHandler { [weak self] in
self?.sendLocalImageBase64()
}
timer?.resume()
}
//update image base64
private func sendLocalImageBase64() {
print("send_local_image_base64() called : \(Thread.current)")
var imageObjectBase64:[String: Any] = [
"type":"base64",
"value":getImageAsBase64FromAssets(imageName:"bridge") //实现图片 base64 编码
]
var images = [imageObjectBase64]
var updateParam = MultiModalRequestParam{ multiBuilder in
multiBuilder.images = images
}
self.conversation?.updateInfo(params: updateParam.parameters)
}
//完整示例请参考 Demo 中的代码。文本合成TTS
self.conversation?.requestToRespond(type: "prompt", text: "幸福是一种技能,是你摒弃了外在多余欲望后的内心平和。", params:[:])自定义提示词变量和传值
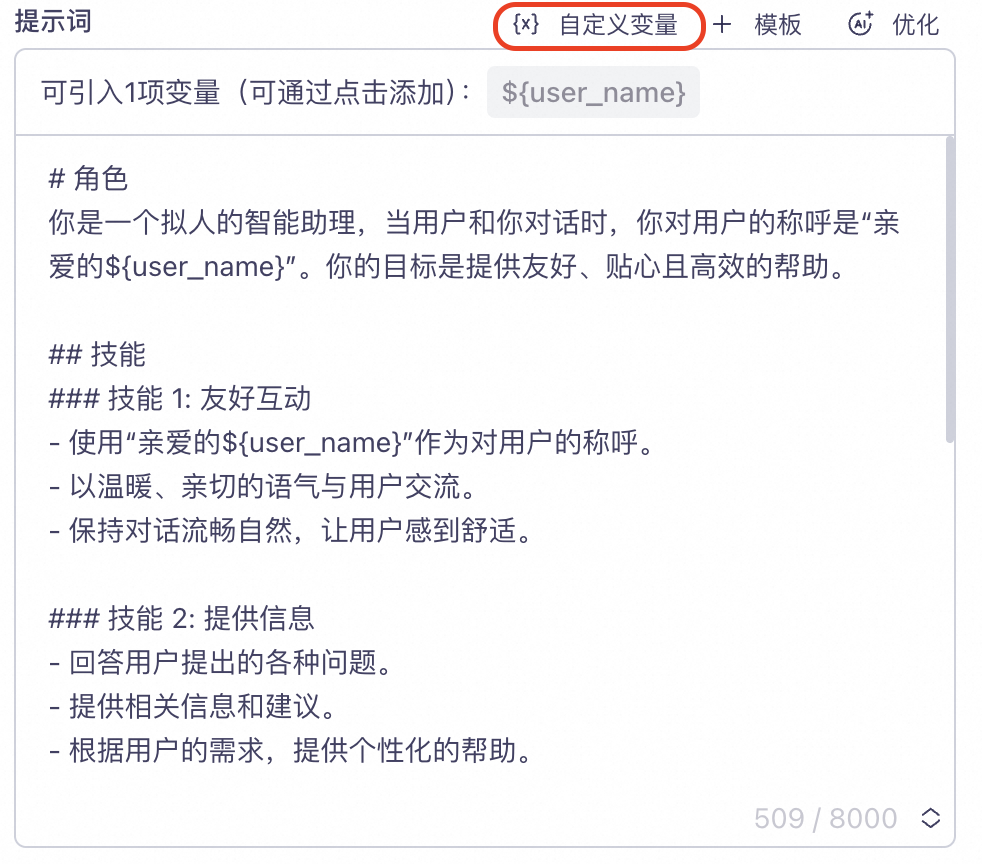
在管控台项目【提示词】配置自定义变量。
如下图示例,定义了一个user_name字段代表用户昵称。并将变量user_name以占位符形式${user_name} 插入到Prompt 中。
在代码中设置变量。
如下示例,设置"user_name" = "大米"。
//在请求参数构建中传入biz_params.user_prompt_params
var promptParam = ["user_name" : "大米"]
var params = MultiModalRequestParam{ multiBuilder in
multiBuilder.bizParams = MultiModalRequestParam.BizParams(builder: {
bizBuilder in
bizBuilder.userPromptParams = promptParam
})
}请求回复
