通过应用观测,您可以查看百炼应用内部的全链路处理流程,并获取延时、Token量等指标,从而更有效地分析和优化您的百炼应用。
为什么做应用观测
尽管百炼应用具备强大的推理和文本生成能力,但由于其内部通常包含多个节点(如知识库),其高度复杂的架构为后续开发带来了诸多挑战,例如:
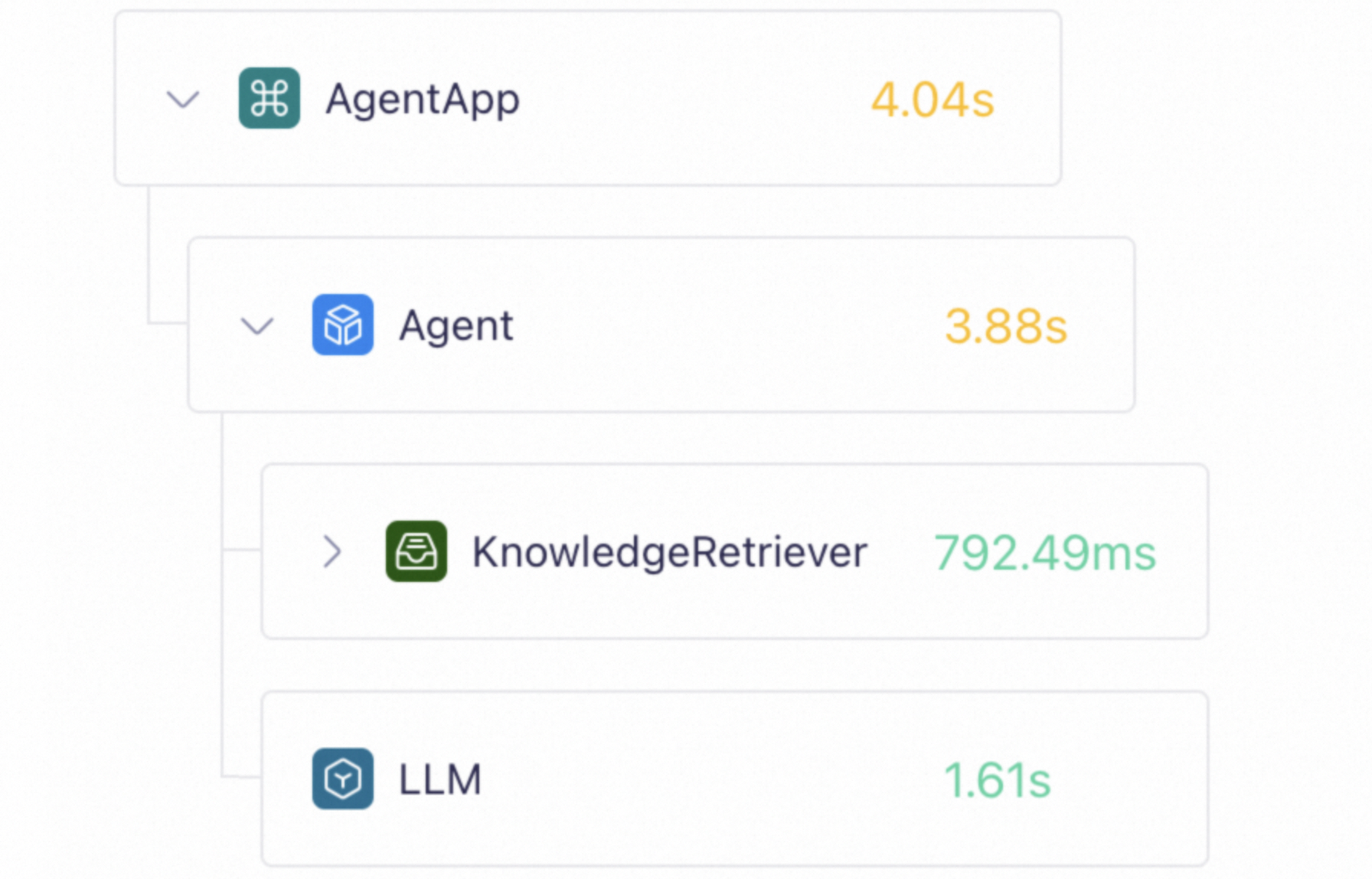
追踪应用内部的调用过程。
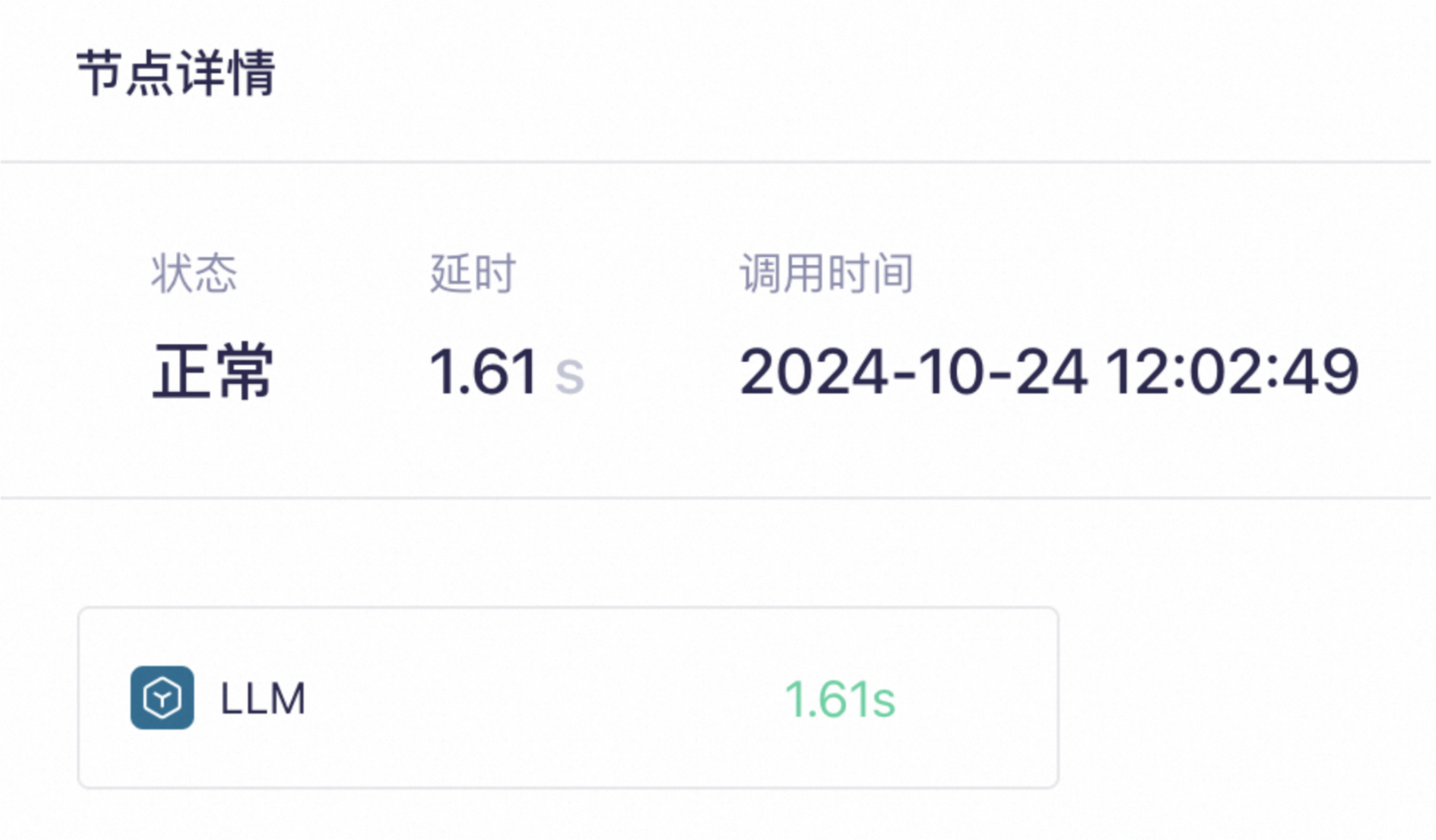
查看模型的响应延时。
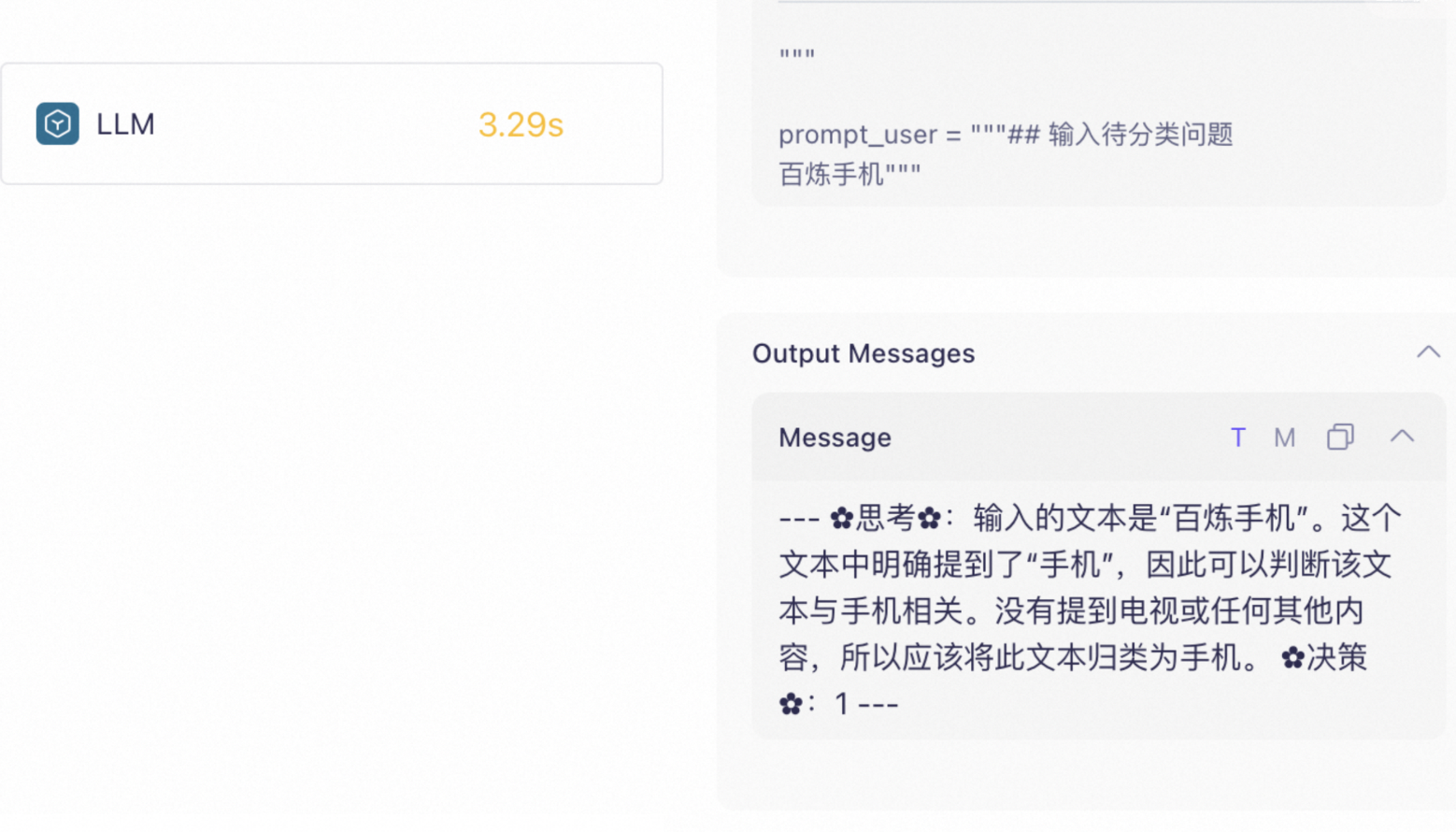
查看模型的思考过程。
为此,百炼提供了应用观测功能。只需简单配置,您即可端到端地查看业务空间内百炼应用的处理流程(例如向量生成、向量检索以及大模型调用等)并获取延时、Token量等指标(更新频率为分钟级)。
效果示例
追踪应用内部的调用过程 | 查看模型的响应延时 | 查看模型的思考过程 |
|
|
|
支持的应用
应用观测目前暂不支持通过Assistant API创建的智能体应用。
快速开始
百炼目前暂未提供可用的API进行应用观测。
首次使用应用观测时,请先根据界面指引开通模型调用服务、可观测链路OpenTelemetry和相关策略(开通后通常秒级生效,但高峰期可能会稍有延迟)。
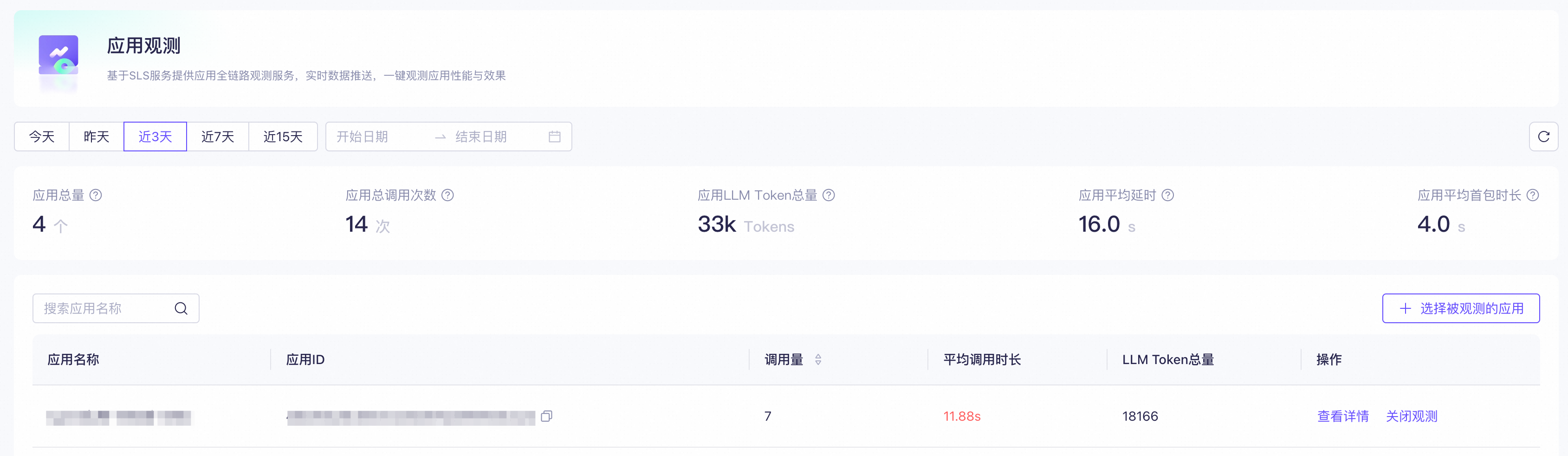
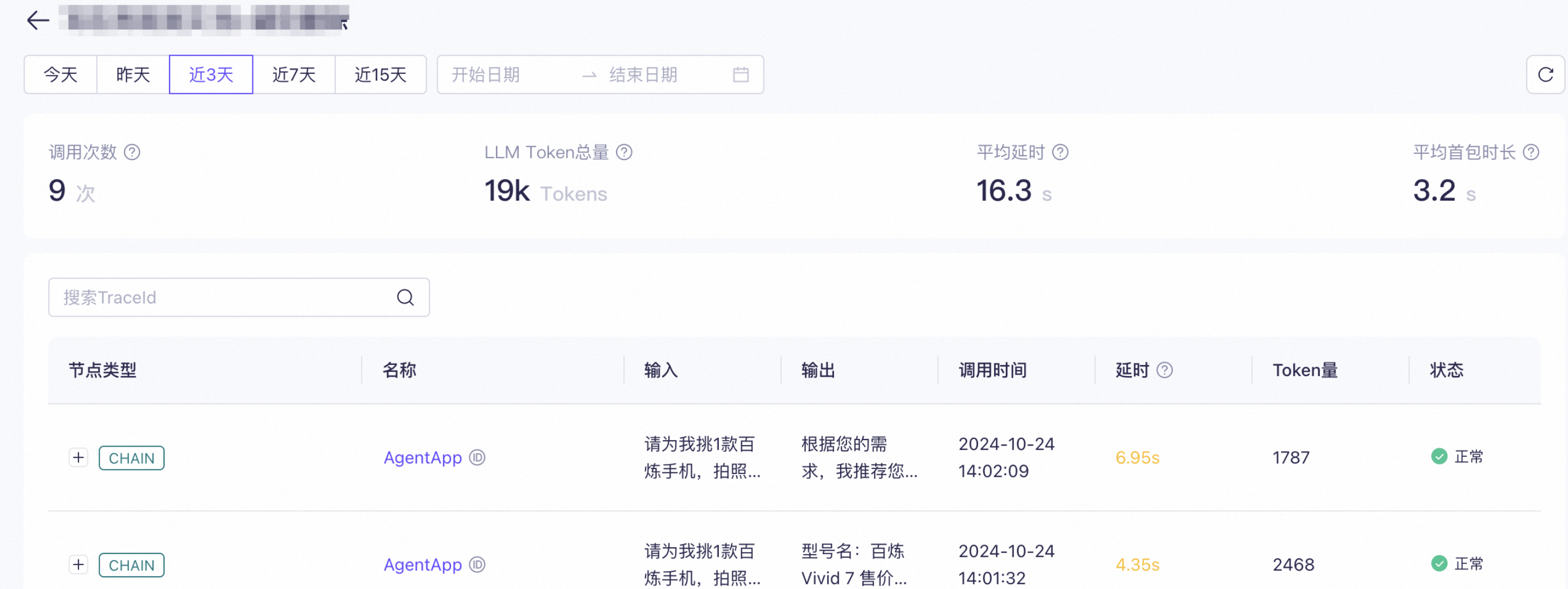
1. 选择被观测的应用访问应用观测,单击。如果列表中没有您已创建的应用,可能是因为:
|
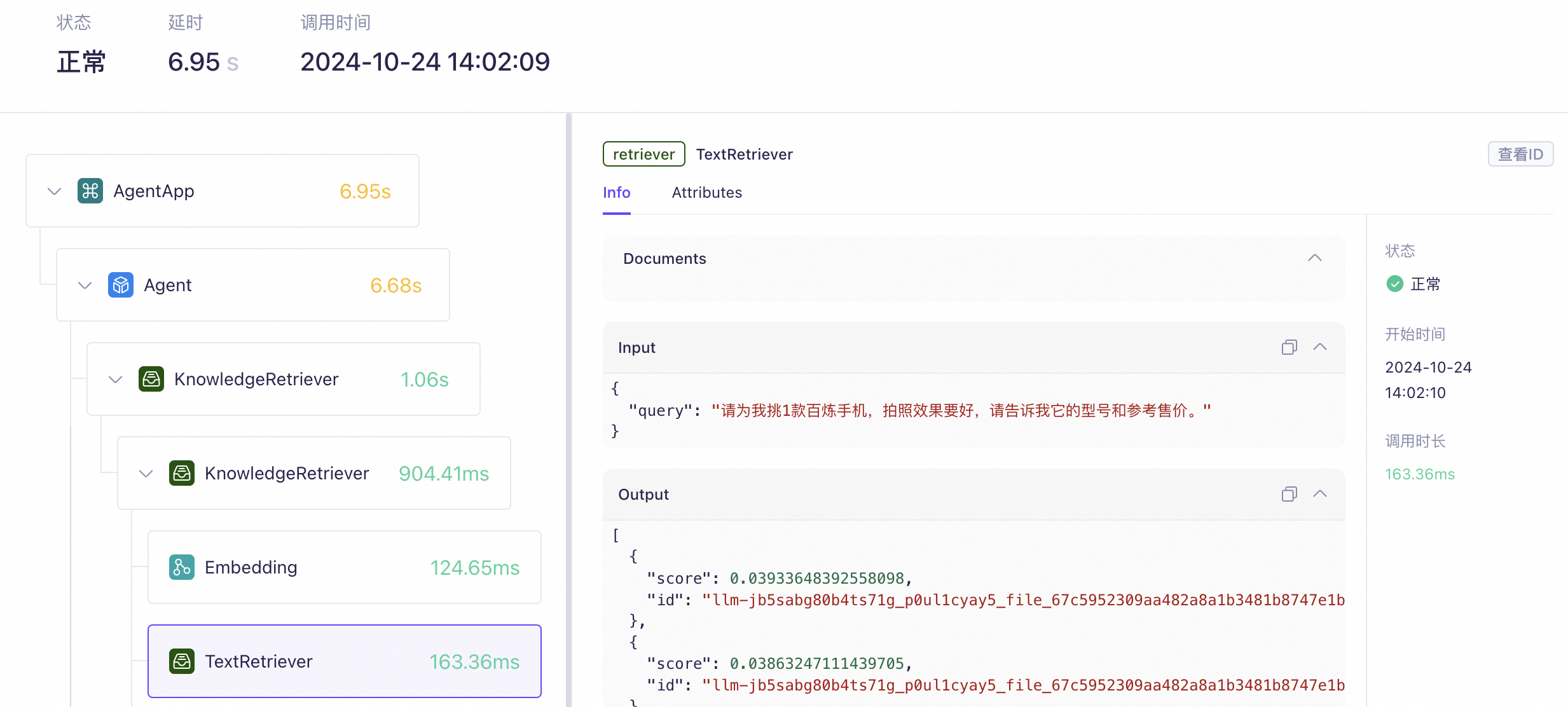
2. 开始观测
|
|
|
计费说明
应用观测功能本身不收费。
应用观测产生的数据需要存储在可观测链路OpenTelemetry服务中,您需要支付相关的费用。关于OpenTelemetry服务的费用详情,请参见计费说明。
附录
名词解释
名词 | 解释 |
节点 | 在应用观测中,节点是指被追踪的一个操作单元。每个节点具有名称和类型等属性,并详细记录了操作的具体信息和起止时间。另外,节点之间还可以形成嵌套关系。 |
支持的节点类型
注意:以下节点仅在被触发或调用时展示。
智能体应用
节点类型 | 说明 |
CHAIN | Chain节点将大模型节点与其他类型的节点相连接,以实现复杂任务的处理。 Chain节点可以包含其它类型节点,例如Retriever、LLM等。 当Chain作为根节点时,名称可能值为:AgentApp(智能体应用)、WorkflowApp(工作流应用)以及AgentflowApp(智能体编排应用)。 |
AGENT | Agent节点表示对智能体的调用。 |
RETRIEVER | Retriever节点用于执行检索操作。KnowledgeRetriever表示在知识库中进行检索。 目前暂不支持观测在长期记忆中的检索过程。 作为KnowledgeRetriever的子节点时,Retriever有两种名称:
|
REWRITER | Rewriter节点会基于会话上下文自动调整原始输入Prompt以提升知识检索效果。 |
EMBEDDING | Embedding节点用于将输入Prompt转化为数值化向量。 Token量指Embedding模型本次向量化了多少Token。 |
RERANKER | Reranker节点会计算每个输入文本切片的相似度分数并按此降序排列。 |
LLM | LLM节点表示对大模型(如通义千问Plus)的调用。例如使用SDK或OpenAPI请求大模型进行推理或者文本生成。 Token量指模型输入Token数 + 模型输出Token数。 LLM节点的延时(调用时长)包括输出回复的过程。 |
TOOL | 例如调用计算器或者夸克搜索。 |
GUARDRAIL | Guardrail节点表示对阿里绿网的调用,用于实时监控、检测和拦截多种违规内容,例如赌博、色情等。 ManualIntervention指触发了您为智能体应用设定的干预规则;SystemIntervention指触发了系统干预规则。 |
工作流应用
节点类型 | 说明 |
CHAIN | Chain节点将大模型节点与其他类型的节点相连接,以实现复杂任务的处理。 Chain节点可以包含其它类型节点,例如Retriever、LLM等。 当Chain作为根节点时,名称可能值为:AgentApp(智能体应用)、WorkflowApp(工作流应用)以及AgentflowApp(智能体编排应用)。 |
START | 表示开始节点。 |
RETRIEVER | Retriever节点用于执行检索操作。KnowledgeRetriever表示在知识库中进行检索。 目前暂不支持观测在长期记忆中的检索过程。 作为KnowledgeRetriever的子节点时,Retriever有两种名称:
|
REWRITER | Rewriter节点会基于会话上下文自动调整原始输入Prompt以提升知识检索效果。 |
EMBEDDING | Embedding节点用于将输入Prompt转化为数值化向量。 Token量指Embedding模型本次向量化了多少Token。 |
RERANKER | Reranker节点会计算每个输入文本切片的相似度分数并按此降序排列。 |
LLM | 表示大模型节点。 Token量指模型输入Token数 + 模型输出Token数。 LLM节点的延时(调用时长)包括输出回复的过程。 |
API | 表示API节点。 |
CLASSIFIER | 表示意图分类节点。 |
TEXT_CONVERTER | 表示文本转换节点。 |
SCRIPT | 表示脚本转换节点。 |
CONDITION | 表示条件判断节点。 |
FUNCTION_COMPUTE | 表示函数计算节点。 |
APP_FLOW | 表示AppFlow节点。 |
GUARDRAIL | Guardrail节点表示对阿里绿网的调用,用于实时监控、检测和拦截多种违规内容,例如赌博、色情等。 ManualIntervention指触发了您为智能体应用设定的干预规则;SystemIntervention指触发了系统干预规则。 |
END | 表示结束节点。 |
智能体编排应用
节点类型 | 说明 |
CHAIN | Chain节点将大模型节点与其他类型的节点相连接,以实现复杂任务的处理。 Chain节点可以包含其它类型节点,例如Retriever、LLM等。 当Chain作为根节点时,名称可能值为:AgentApp(智能体应用)、WorkflowApp(工作流应用)以及AgentflowApp(智能体编排应用)。 此外,智能体编排应用的Chain节点支持嵌套其它Chain节点。 |
START | 表示开始节点。 |
RETRIEVER | Retriever节点用于执行检索操作。KnowledgeRetriever表示在知识库中进行检索。 目前暂不支持观测在长期记忆中的检索过程。 作为KnowledgeRetriever的子节点时,Retriever有两种名称:
|
REWRITER | Rewriter节点会基于会话上下文自动调整原始输入Prompt以提升知识检索效果。 |
EMBEDDING | Embedding节点用于将输入Prompt转化为数值化向量。 Token量指Embedding模型本次向量化了多少Token。 |
RERANKER | Reranker节点会计算每个输入文本切片的相似度分数并按此降序排列。 |
LLM | 表示大模型节点。 Token量指模型输入Token数 + 模型输出Token数。 LLM节点的延时(调用时长)包括输出回复的过程。 |
AGENT_GROUP | 表示智能体群组节点。 |
PLANNER | Planner节点将输入智能体群组节点的内容提供给决策大模型,并根据模型的推理结果来确定后续执行任务的智能体。 |
DECIDER | 表示决策分类节点。 |
TEXT_CONVERTER | 表示文本转换节点。 |
SCRIPT | 表示脚本转换节点。 |
GUARDRAIL | Guardrail节点表示对阿里绿网的调用,用于实时监控、检测和拦截多种违规内容,例如赌博、色情等。 ManualIntervention指触发了您为智能体应用设定的干预规则;SystemIntervention指触发了系统干预规则。 |
END | 表示结束节点。 |