
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
当您的MongoDB实例中存在过多的库表时,可能会遇到数据库性能退化以及其他问题。
数据库中常说的库和表分别对应MongoDB中的数据库(Database)和集合(Collection)。
在MongoDB中,WiredTiger存储引擎会为每一张表都建立对应的磁盘文件,每一个单独的索引也会成为一个新的磁盘文件。WiredTiger引擎中每一个打开的资源(比如文件系统对象)都会有一个对应的dhandle数据结构,存储了包括checkpoint信息、会话的引用计数、指向内存B+树结构的指针、统计数据信息等等。
因此,MongoDB中库表数量越多,WiredTiger引擎层打开操作系统文件对象的数量越多,相对应的内存dhandle数据结构也就越多。当大量的dhandle结构都存在内存中时,会出现相关锁的争抢,进而导致数据库实例的性能退化。
可能遇到的问题
锁(handleLock或者schemaLock)导致的慢查询,请求延迟变大。
库表数多导致的慢日志可能如下:
2024-03-07T15:59:16.856+0800 I COMMAND [conn4175155] command db.collections command: count { count: "xxxxxx", query: { A: 1, B: 1 }, $readPreference: { mode: "secondaryPreferred" }, $db: "db" } planSummary: COLLSCAN keysExamined:0 keysExaminedBySizeInBytes:0 docsExamined:1 docsExaminedBySizeInBytes:208 numYields:1 queryHash:916BD9E3 planCacheKey:916BD9E3 reslen:185 locks:{ ReplicationStateTransition: { acquireCount: { w: 2 } }, Global: { acquireCount: { r: 2 } }, Database: { acquireCount: { r: 2 } }, Collection: { acquireCount: { r: 2 } }, Mutex: { acquireCount: { r: 1 } } } storage:{ data: { bytesRead: 304, timeReadingMicros: 4 }, timeWaitingMicros: { handleLock: 40, schemaLock: 134101710 } } protocol:op_query 134268ms上述慢日志表示用户对只有1条文档的集合进行了简单的Count操作,但是花费了很长时间。日志的
timeWaitingMicros: { handleLock: 40, schemaLock: 134101710 } } protocol:op_query 134268ms部分表示读请求受到库表数量太多的影响,在等待获取底层存储的handleLock和schemaLock上花费了过多时间。添加新节点时在初始化同步阶段OOM。
实例的启动时间变长。
数据同步时间变长。
备份恢复时间变长。
物理备份失败率提升。
故障恢复时间变长。
库表数量多不一定会出现问题,是否出现问题与业务模型和负载等因素也有关系。例如以下两种业务场景,数据库规格相同且都有1万的库表数和10万的总文件数,但面临的问题完全不一样:
会计软件系统:访问具备明显的聚集性特征,大多数库表只作为冷数据存储,经常访问的库表只有近期的一小部分。
多租户管理系统:租户之间用表隔离,几乎所有的表都会被访问或使用。
优化方法
移除不需要的集合
查询数据库中哪些集合是可以删除的(例如已过期或业务不再使用的集合),通过dropCollection命令直接删除这些无用表。关于删除命令的介绍,请参见dropCollection()。
在执行删除操作前,请确保您有一个可用的全量备份。
查看数据库和集合信息的命令如下:
执行以下命令查看数据库中集合的数量。
db.getSiblingDB(<dbName>).getCollectionNames().length执行以下命令查看关于数据库的具体信息,包括集合的数量,索引的数量,文档条数,总数据量大小等信息。
//查看某个库的统计信息 db.getSiblingDB(<dbName>).stats()执行以下命令查看某个集合的具体信息。
//查看某个表的统计信息 db.getSiblingDB(<dbName>).<collectionName>.stats()
移除不需要的索引
降低索引的数量也可以减少WiredTiger存储引擎层维护的磁盘文件以及相应的dhandle结构,同样有助于缓解本问题。
索引优化的一些基本原则如下:
避免无用索引
查询根本不会访问到的字段,索引也自然不会命中,属于无用索引,可以删除。
索引的前缀匹配规则
例如
{a:1}和{a:1,b:1}两个索引,前者就属于前缀匹配的冗余索引,可以删除。等值查询时的索引字段顺序
例如
{a:1,b:1}和{b:1,a:1}两个索引,在等值匹配中,顺序并不会有影响,可以删除其中命中次数更少的一个。范围查询时参考ESR规则
根据实际的业务范围查询,按照
quality, Sort, Range的顺序来构造最优的复合索引。更多信息,请参见The ESR Rule。review命中次数低的索引
命中次数低的索引基本上都和另外一个高效索引存在一定的重复,需要结合业务的所有查询模式来判断是否可以删除。
您可以通过MongoDB的$indexStats聚合阶段来查看某个表中所有索引的统计信息。请在确保有相关权限的前提下,执行下面的命令。
//查看某个表的索引统计信息
db.getSiblingDB(<dbName>).<collectionName>.aggregate({"$indexStats":{}})返回示例如下。
{
"name" : "item_1_quantity_1",
"key" : { "item" : 1, "quantity" : 1 },
"host" : "examplehost.local:27018",
"accesses" : {
"ops" : NumberLong(1),
"since" : ISODate("2020-02-10T21:11:23.059Z")
}
}返回信息参数说明如下。
字段 | 描述 |
name | 索引名称。 |
key | 索引键详细信息。 |
accesses.ops | 使用了该索引的操作数,相当于索引命中的次数。 |
accesses.since | 开始收集统计信息的时间(实例重启或者索引重建会导致该字段以及ops字段重置)。 |
如果观察到索引命中次数很少(例如示例中的accesses.ops为1),则很大概率该索引是冗余索引或无用索引,可以考虑删除。如果您的MongoDB实例版本为4.4及以上,为了进一步降低删除索引的风险,您可以在dropIndex之前通过hiddenIndex命令先隐藏对应索引,确认一段时间内业务无异常后再进行索引删除的操作。
示例
假设一个游戏玩家集合,规则为“每当玩家收集了20个coins,则转换成1个stars”,集合中的文档如下:
// players collection
{
"_id": "ObjectId(123)",
"first_name": "John",
"last_name": "Doe",
"coins": 11,
"stars": 2
}目前表里的索引包括下面5个,覆盖了所有字段:
_id(默认索引){ last_name: 1 }{ last_name: 1, first_name: 1 }{ coins: -1 }{ stars: -1 }
索引优化逻辑如下:
业务查询不会访问
coins字段,因此{ coins: -1 }是无用索引。根据前面提到的索引前缀匹配规则,
{ last_name: 1, first_name: 1 }包含了{ last_name: 1 },因此可以删除{ last_name: 1 }索引。通过
$indexStats命令观察到{ stars: -1 }的命中次数很低,但考虑到业务上一整轮游戏结束时需要按照玩家的stars数量进行逆序排序来展示结算排行榜,因此尽管并不常用,{ stars: -1 }也需要保留来避免扫描所有文档。
优化后,集合中还剩下3个索引:
_id{ last_name: 1, first_name: 1 }{ stars: -1 }
优化后的收益如下:
存储空间下降。
写入性能提升。
如果您还有关于索引优化的更多问题,请提交工单联系阿里云技术支持协助解决。
整合多表数据
将多个集合中的数据整合到单个集合中以减少集合数量。
例如,数据库中有一个temperatures库,用来存储从传感器获得的所有温度数据。传感器从上午10点工作到晚上10点,每半小时读取一次当时的温度数据并存储在数据库中。每一天的温度数据存放在一个单独的以日期为命名的集合中。
以下展示了2个集合(分别是temperatures.march-09-2020和temperatures.march-10-2020)的部分数据的内容。
集合
temperatures.march-09-2020{ "_id": 1, "timestamp": "2020-03-09T010:00:00Z", "temperature": 29 } { "_id": 2, "timestamp": "2020-03-09T010:30:00Z", "temperature": 30 } ... { "_id": 25, "timestamp": "2020-03-09T022:00:00Z", "temperature": 26 }集合
temperatures.march-10-2020{ "_id": 1, "timestamp": "2020-03-10T010:00:00Z", "temperature": 30 } { "_id": 2, "timestamp": "2020-03-10T010:30:00Z", "temperature": 32 } ... { "_id": 25, "timestamp": "2020-03-10T022:00:00Z", "temperature": 28 }
随着时间的推移,数据库中的集合数量也在增加,由于MongoDB并没有明确的集合数量上限,而且示例中也并没有明确的数据生命周期关系,因此数据库所维护的集合数量及其相应索引数量不断增长。
除了库表数不断上涨的问题,这种建模还不便于执行跨天查询。若要查询多天的数据以获得较长时间内的温度趋势,您需要执行基于$lookup的查询,其性能不如针对同一集合内的查询。
更优的数据建模是将所有温度读数存储在单个集合中,并将每天的温度数据存储在单个文档中。优化后的示例如下。
// temperatures.readings
{
"_id": ISODate("2020-03-09"),
"readings": [
{
"timestamp": "2020-03-09T010:00:00Z",
"temperature": 29
},
{
"timestamp": "2020-03-09T010:30:00Z",
"temperature": 30
},
...
{
"timestamp": "2020-03-09T022:00:00Z",
"temperature": 26
}
]
}
{
"_id": ISODate("2020-03-10"),
"readings": [
{
"timestamp": "2020-03-10T010:00:00Z",
"temperature": 30
},
{
"timestamp": "2020-03-10T010:30:00Z",
"temperature": 32
},
...
{
"timestamp": "2020-03-10T022:00:00Z",
"temperature": 28
}
]
}优化后的模式需要消耗的资源比原始模式少得多。现在,您不再需要根据每天读取温度的时间创建索引,集合上的默认索引_id有助于按日期进行查询。同时也解决了库表数不断增长的问题。
时序数据您也可以考虑使用时序集合(Time Series Collections)功能来解决上述问题。
时序集合功能仅MongoDB 5.0及以上版本支持。
实例拆分
在MongoDB单实例下总库表数无法降低的情况下,可以考虑对该数据库实例进行逻辑拆分并进行配套的业务整改。
可以分成以下两种场景处理:
场景 | 拆分方案 | 注意事项 |
集合(collections)分布在多个库(databases)中 | 如果库之间的业务相互关联性并不大(例如多个应用或服务共享使用同一个数据库实例),可以通过云数据库MongoDB版(副本集架构)迁移至云数据库MongoDB版(副本集架构或分片集群架构)将部分库迁移到一个新的MongoDB实例。在迁移完成前,业务逻辑和访问方式也需要配套进行拆分。 如果库之间的业务关联性比较大,请参考单库场景的拆分方案。 |
|
集合(collections)集中在1个库(database)中 | 需要业务侧先判断是否可以按某个维度对所有的表进行拆分,比如地域、城市、优先级或其他任何业务上有意义的维度。 然后通过DTS将部分表迁移到一个或者多个新的MongoDB实例,完成1拆N的目的。在迁移完成前业务逻辑和访问方式需要配套进行拆分。 |
|
示例
某个多租户管理平台系统使用了MongoDB数据库,初期建模时以每一个租户为一个单独的集合。随着业务不断发展,租户的数量已达到了十万以上的量级,数据库整体的数据量也达到了TB级,实例经常出现数据库访问慢以及延迟高的问题。
业务侧在拆分时选择按照地域的维度,将国内的租户分为了华北、东北、华东、华中、华南、西南、西北几个地域。在对应的地域可用区分别创建全新的MongoDB实例并进行了多轮DTS迁移。同时,为了满足业务侧聚合分析的需求,建立了MongoDB实例到数仓的同步。
拆分完成后,单个MongoDB的库表数大幅下降,实例规格也相应降低。同时,业务侧按地域基于就近访问原则,使得请求访问延时缩短到ms级别,大幅提升了业务的产品使用体验,后续的实例运维也变得更加简单。
迁移到分片集群实例并使用分片标签(Shard Tag)来管理
如果所有的集合都集中在一个库中,而且还希望通过一个逻辑上的数据库实例来管理的话,您可以考虑将数据迁移到分片集群架构并使用分片标签(Shard Tag)来进行管理。shard tag管理方式稍微复杂一些,需要一些额外的运维操作(sh.addShardTag和sh.addTagRange),但所有的表依然由同一个MongoDB实例管理,业务上基本不需要改造,只需要将连接串替换为新的分片集群实例的连接串即可。
假如您的实例中有10万个活跃集合,可以新购一个10个Shard节点的分片集群实例,通过以下流程完成设置并迁移数据,可实现每个Shard节点上各1万个活跃集合。操作步骤如下:
新购一个分片集群实例,本文以2个分片的实例为例。如何创建分片集群,请参见创建分片集群实例。
连接分片集群实例的mongos节点,如何连接数据库,请参见通过Mongo Shell连接MongoDB分片集群实例。
执行如下命令为所有分片添加标签(Shard Tag)。
sh.addShardTag("d-xxxxxxxxx1", "shard_tag1") sh.addShardTag("d-xxxxxxxxx2", "shard_tag2")说明执行相关命令前请确保您使用的账户具备相应的权限。
DMS暂不支持
sh.addShardTag,建议您使用mongo shell或者mongosh连接实例执行相关命令。
为所有的分片表提前设置范围的标签分布规则。
use <dbName> sh.enableSharding("<dbName>") sh.addTagRange("<dbName>.test", {"_id":MinKey}, {"_id":MaxKey}, "shard_tag1") sh.addTagRange("<dbName>.test1", {"_id":MinKey}, {"_id":MaxKey}, "shard_tag2")示例中选择
_id作为分片键,实际使用时请按需选择,确保所有的查询操作都包含分片键字段。分片键需要与下一个操作里的字段保持一致。同时需要使用[MinKey,MaxKey]的上下边界,使得一个表的所有数据仅存在于单个分片上。对于所有的待迁移表都执行shardCollection操作。
sh.shardCollection("<dbName>.test", {"_id":1}) sh.shardCollection("<dbName>.test1", {"_id":1})通过
sh.status()命令来确认相关规则已生效。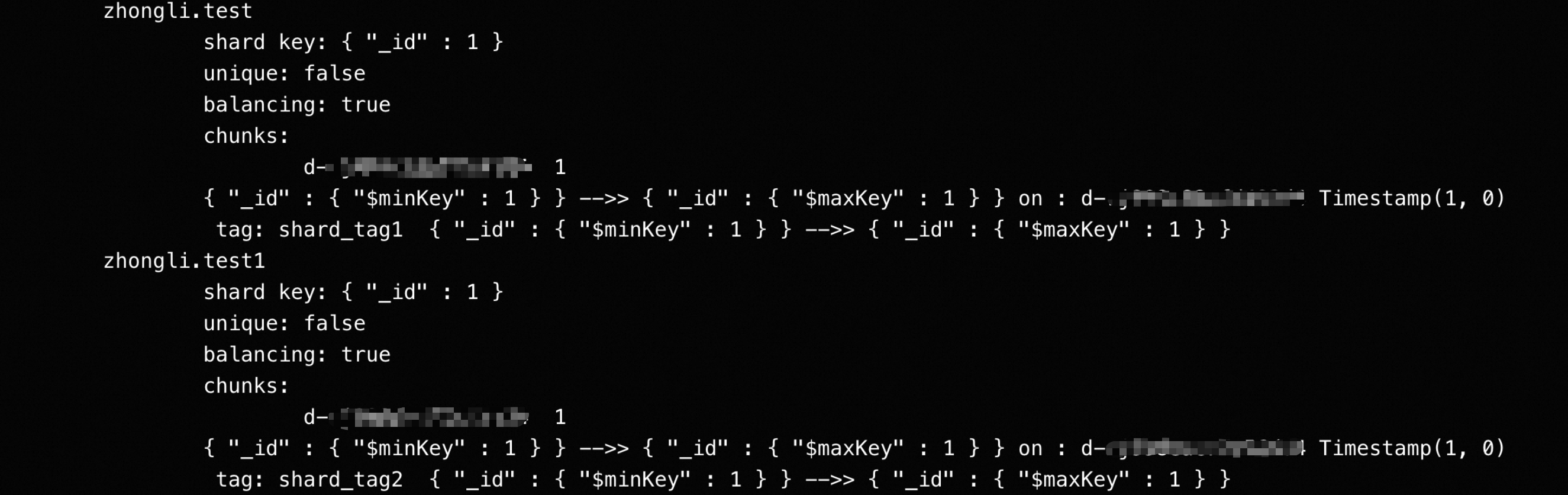
将数据从副本集实例迁移到分片集群实例中。
说明由于已经在目标实例上进行了分片操作,所有库表信息已存在,因此需要配置目标已存在表的处理模式为忽略报错并继续执行。
数据校验一致后将业务切换到访问新的分片集群实例。
如果需要为实例增加分片,需要执行上述操作中的步骤3,为所有新增的分片添加标签。
如果数据库后续会持续新增集合,需要执行上述操作中的步骤4和步骤5。如果不执行这两个步骤,库表将只会存在主分片上,导致主分片上库表数越来越多,然后再次遇到实例卡顿或异常的问题。
迁移到分片集群实例并使用分区(Zones)来管理
本方法与使用分片标签管理方法类似,不过使用的是MongoDB的分区(Zones)功能,需要额外的运维操作(分别为sh.addShardToZone()以及sh.updateZoneKeyRange())。
操作步骤如下:
新购一个分片集群实例,本文以2个分片的实例为例。如何创建分片集群,请参见创建分片集群实例。
连接分片集群实例的mongos节点,如何连接数据库,请参见通过Mongo Shell连接MongoDB分片集群实例。
执行如下命令为所有分片指定分区(Zones)。
sh.addShardToZone("d-xxxxxxxxx1", "ZoneA") sh.addShardToZone("d-xxxxxxxxx2", "ZoneB")说明执行相关命令前请确保您使用的账户具备相应的权限。
DMS暂不支持
sh.addShardToZone,建议您使用mongo shell或者mongosh连接实例执行相关命令。
为所有的表提前设置范围的分区分布规则。
use <dbName> sh.enableSharding("<dbName>") sh.updateZoneKeyRange("<dbName>.test", { "_id": MinKey }, { "_id": MaxKey }, "ZoneA") sh.updateZoneKeyRange("<dbNmae>.test1", { "_id": MinKey }, { "_id": MaxKey }, "ZoneB")示例中选择
_id为分片键,实际使用时请按需选择,确保所有的查询操作都包含分片键字段。分片键需要跟下一个操作里的字段保持一致。同时需要使用[MinKey,MaxKey]的上下边界,使得一个表的所有数据仅存在于单个分片上。对于所有的待迁移表都执行shardCollection操作。
sh.shardCollection("<dbName>.test", { _id: "hashed" }) sh.shardCollection("<dbName>.test1", { _id: "hashed" })通过
sh.status()命令来确认相关规则已生效。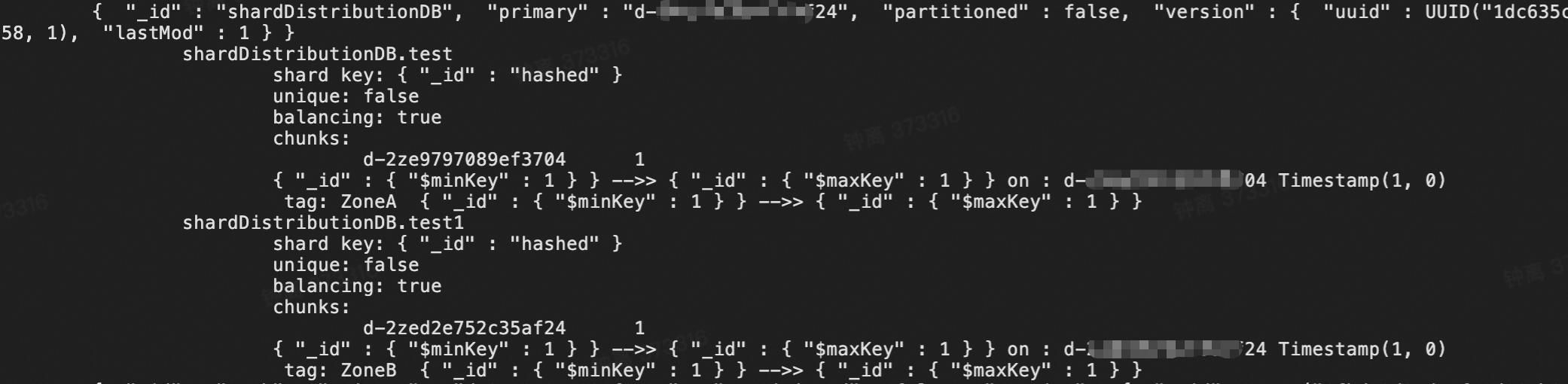
将数据从副本集实例迁移到分片集群实例中。
说明由于已经在目标实例上进行了分片操作,所有库表信息已存在,因此需要配置目标已存在表的处理模式为忽略报错并继续执行。
数据校验一致后将业务切换到访问新的分片集群实例。
如果需要为实例增加分片,需要执行上述操作中的步骤3,为所有新增的分片指定分区。
如果数据库后续会持续新增集合,需要执行上述操作中的步骤4和步骤5。如果不执行这两个步骤,库表将只会存在主分片上,导致主分片上库表数越来越多,然后再次遇到实例卡顿或异常的问题。
风险提示
不建议您直接通过dropDatabase命令删除拥有大量集合的库。
执行dropDatabase命令后,WT引擎会异步进行清理操作,逐个清理所有待删除表相关的元数据和物理文件。该操作可能会影响从节点的主从同步,导致复制延迟不断上涨;进而引起flowControl机制介入或者影响您所有{writeConcern:majority}的写入操作。
您可以考虑采取以下方式来规避:
设置合理的间隔分批删除库中的集合,并在所有集合删除完毕后最终执行
dropDatabase命令。使用DTS或者其他迁移工具将需保留的库表迁移到新实例中,并在迁移割接完成后删除旧实例。
无论如何,您都应该针对实例设置合理的主从延迟告警项。如果您的实例遇到了此问题,可以提交工单联系技术支持协助解决。
总结
尽量将一个副本集内的库表总数控制在1万以内。如果单个表里的索引数量过多(>15),则该数值应适当下调。
如果因业务特性(例如多租户系统按表隔离)需要存在很多的库表数,请考虑拆分业务逻辑并使用分片集群实例。
如果您的数据库已被库表数多的问题困扰,想要降低数据库中的库表数但不知道如何修改业务逻辑设计,您可以提交工单联系技术支持协助解决。