
您可以在体验中心通过可视化方式体验文档解析、多模态向量、多模态排序、主体识别、文本向量、视频解析等各类服务,帮助您快速评估服务是否满足业务诉求。
功能介绍
体验中心提供以下服务:
服务类别 | 服务说明 |
文档内容解析 |
|
图片内容解析 | 图片内容理解服务:基于多模态大模型对图片内容进行解析理解以及文字识别,解析后的文本可用于图片检索、问答场景。 |
图片文本识别服务:OCR图片文本识别,识别后的文本可用于图片检索问答场景。 | |
文档切片 | 提供通用文本切片服务,支持基于文档段落、文本语义、指定规则,对HTML、Markdown、TXT格式的结构化数据进行拆分,同时支持以富文本形式提取文档中的代码、图片以及表格。 |
文本向量 |
|
多模态向量 |
|
多模态排序 | 提供图像的相关性排序服务,在RAG及多模态搜索场景中,可通过排序服务找到相关性更高的内容并依次返回,引入排序服务可有效提升检索及大模型生成的准确率。 |
主体识别 | 从图像或视频中自动定位并识别主要目标或对象,支持单个及多个主体的识别,适用于智能监控、自动驾驶、图像检索等应用。 |
文本稀疏向量 提供将文本数据转化为稀疏向量形式表达的服务,稀疏向量存储空间更小,常用于表达关键词和词频信息,可与稠密向量搭配进行混合检索,提升检索效果。 | OpenSearch文本稀疏向量化服务:提供多语言(100+)文本向量化服务,输入文本最大长度8192 token。 |
向量降维 | 向量降维embedding-dim-reduction:提供向量模型调优服务,可通过定制训练向量降维等模型,在不带来过多检索效果损失的情况下,辅助将高维度向量降低维度,以便提升性价比。 |
查询分析 提供Query内容分析服务,基于大语言模型及NLP能力,可对用户输入的查询内容进行意图识别、相似问题扩展、NL2SQL处理等,有效提升RAG场景中检索问答效果。 | 通用Query分析服务,基于大语言模型对用户输入Query进行意图理解以及相似问题扩展。 |
排序服务 |
|
语音识别 | 语音识别服务001:提供语音转文本能力,可将视频或音频中的语音内容快速转化为结构化文本。该服务支持多种语言。 |
视频截帧 | 视频截帧服务001:提供视频内容提取能力,可从视频中捕获关键帧画面。结合多模态向量服务或图片解析能力,实现跨模态检索。 |
大模型 |
|
联网搜索 | 搜索过程中,当私有知识库无法给出相应的答案时,可拓展联网搜索,获取更多互联网信息,补充私有知识库,结合大语言模型给出更丰富的回答。 |
功能体验
以文档解析和多模态向量为例,介绍如何在体验中心快速试用服务、查看结果并获取调用代码。
文档解析
登录AI搜索开放平台控制台。
在左侧导航栏选择体验中心。
服务类别选择文档解析/图片解析(document-analyze),选择具体的体验服务。
体验数据可以使用系统提供的示例数据,支持通过管理数据上传您自己的数据,文件类型支持Txt、Pdf、Html、Doc、Docx、Ppt、Pptx格式,大小不超过20M。
文件:上传本地文件,7天后自动清除, 平台不会长期存储您的数据。
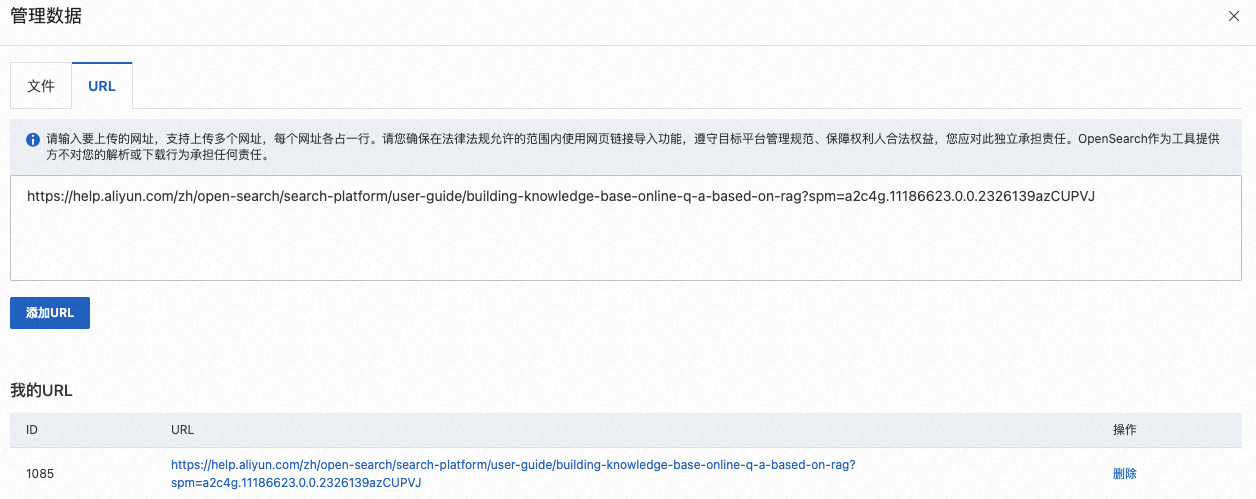
URL:提供文件URL地址和对应的文件类型,支持上传多个网址,每个网址各占一行。
说明数据格式选择错误会导致文档解析失败,请根据文件数据选择正确的文件类型。
 重要
重要请您确保在法律法规允许的范围内使用网页链接导入功能,遵守目标平台管理规范、保障权利人合法权益,您应对此独立承担责任。AI搜索开放平台作为工具提供方不对您的解析或下载行为承担任何责任。
如您使用自己的数据,从下拉列表中选择提前上传的文件或者URL。
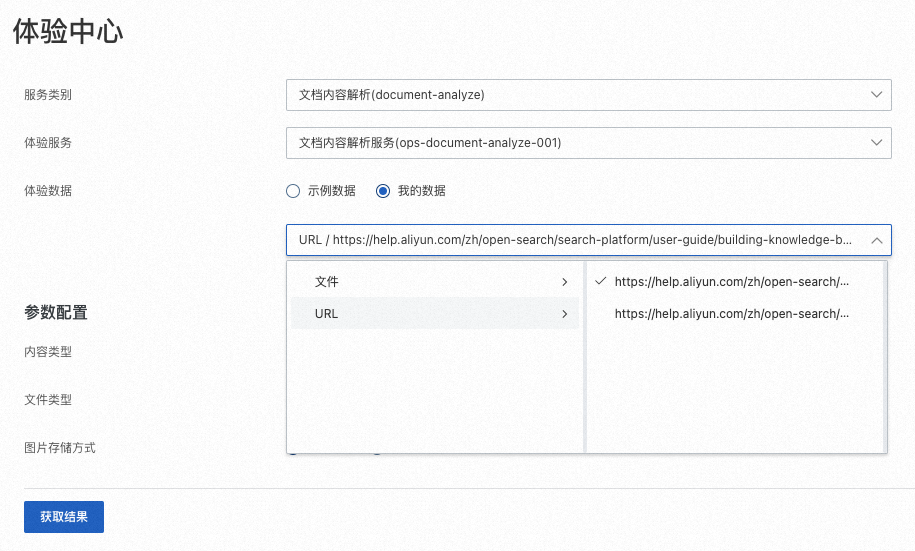
单击获取结果,系统调用服务解析文档。
结果:展示解析进度和解析结果
结果源码:查看结果响应代码、通过复制代码或者下载文件将代码下载到本地。
示例代码:查看和下载调用文本内容解析服务的示例代码。

多模态向量
登录AI搜索开放平台控制台。
在左侧导航栏选择体验中心。
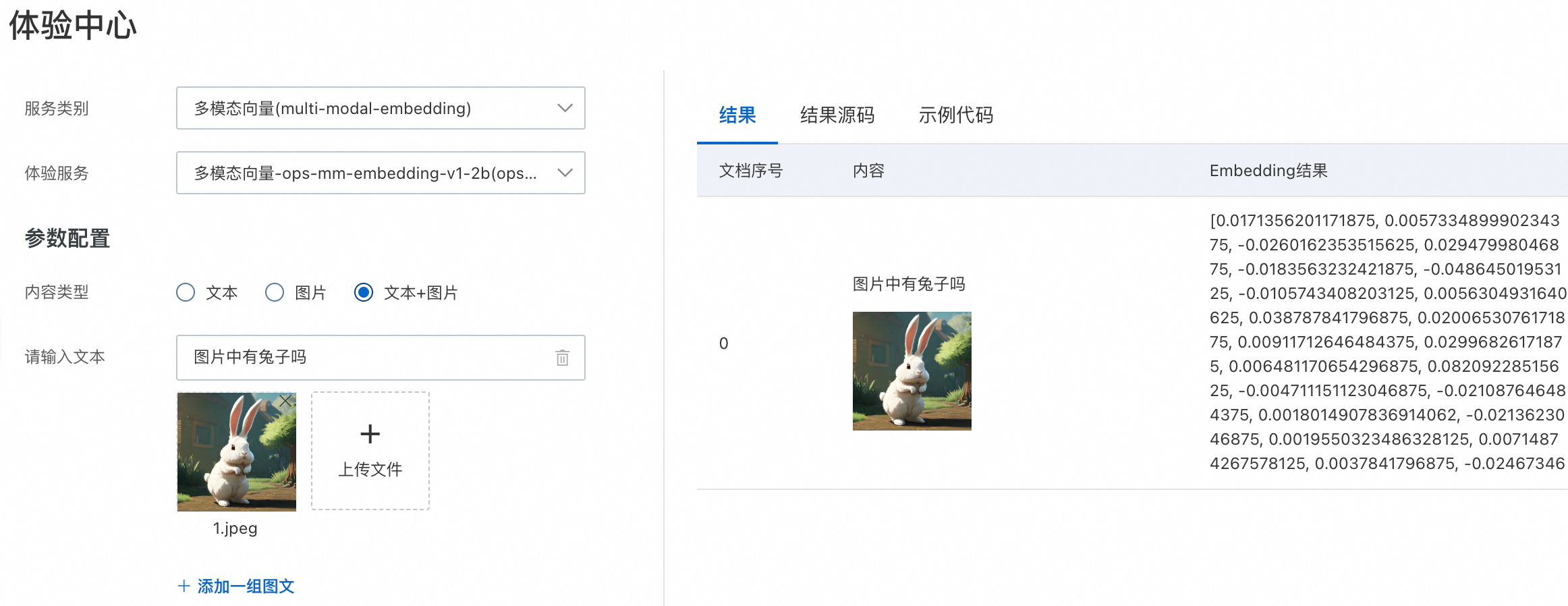
服务类别选择多模态向量(multi-modal-embedding),选择具体的体验服务,选择文本、图片或者文本+图片。
 说明
说明上传本地图片进行向量化时,图片将在7天后自动清除, 平台不会长期存储您的数据。
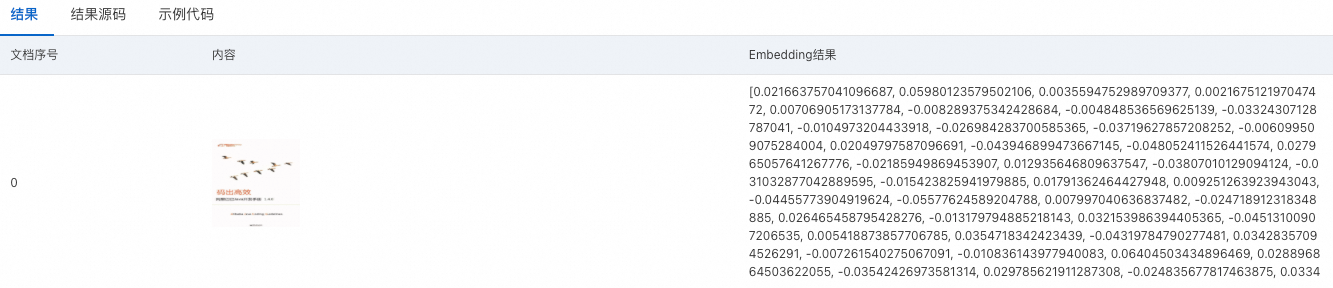
单击获取结果,获取多模态向量化结果。
结果:展示向量化结果
结果源码:查看结果响应代码、通过复制代码或者下载文件将代码下载到本地。
示例代码:查看和下载调用文本向量化服务的示例代码。