本篇文档主要介绍定制排序模型的特征类型配置属性,不同特征配置有相应限制,以下是对应规范和限制。
介绍
本篇文档主要介绍定制排序模型的特征类型配置属性,不同特征配置有相应限制,以下是对应规范和限制。
公共属性
字段名 | 是否必选 | 含义 |
feature_name | 是 | feature_name会被当作最终输出的feature的前缀 |
feature_type | 是 | 即下文中的类型 |
id_feature(离散ID特征)
id feature是一个sparse feature,是一种最简单的离散特征,只是简单的将某个字段的值与用户配置的feature名字拼接。适用字符串和整型数据
raw_feature(原始数值特征)
-raw feature是一种dense的feature,是直接引用原始feature的字段值作为feature的value。适用于浮点型和整型。
-embedding等输入可以设置value_dimension,数值用不可见字符ascii(29)分割拼接成字符串。
参数名 | 是否必须 | 类型 | 示例值 | 描述 |
value_dimension | 否 | int | 128 | 输出的字段的维度,默认为1 |
combo_feature(组合交叉特征)
适用于字符串和整型特征的组合,不要尝试对浮点值特征作为输入。
combo feature是多个字段(或表达式)的组合(即笛卡尔积),id feature可以看成是一种特殊的combo feature,即参与交叉字段只有一个的combo feature。一般来讲,参与交叉的各个字段来自不同的表(比如user特征和item特征进行交叉)。
lookup_feature(匹配查找特征)
lookup feature 依赖 map 和 key 两个字段,map是一个多值string(MultiString)类型的字段,其中每一个string的样子如"k1:v2"。;key可以是一个任意类型的字段。生成特征时,先是取出key的值,将其转换成string类型,然后在map字段所持有的kv对中进行匹配,获取最终的特征。item的多值用多值分隔符ascii(29)分隔。
参数名 | 是否必须 | 类型 | 示例值 | 取值范围 | 描述 |
map | 是 | string | 如系统内置基础特征:"system_query_ctr_decay" | 多值string类型的字段,其中每一个string形如"k1:v2" | |
key | 是 | string | 如系统内置基础特征:"system_raw_q_ultra" | 任意类型的字段,生成特征时转换为string,从map中匹配 | |
combiner | 否 | string |
| 存在多个相同key时,通过combiner组合多个查到的值,默认为sum |
overlap_feature(匹配重叠特征)
用来输出一些字符串字词匹配信息的feature
参数名 | 是否必须 | 类型 | 示例值 | 取值范围 | 描述 |
query | 是 | string | "user:attr1" | 多值string类型的字段,分隔符使用'\u001d'(ascii(29)) | |
title | 是 | string | "item:attr2" | 多值string类型的字段,分隔符使用'\u001d'(ascii(29)) | |
method | 是 | string |
|
|
示例
query为high,high2,fiberglass,abc
title为high,quality,fiberglass,tube,for,golf,bag
method | separator | feature |
common_word | high_fiberglass | |
diff_word | " " | high2 abc |
query_common_ratio | 5 | |
title_common_ratio | 28 | |
is_contain | 0 | |
is_equal | 0 |
特征生成
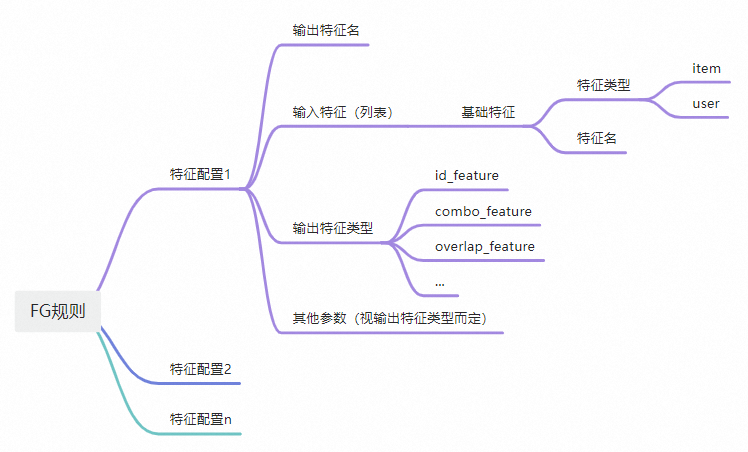
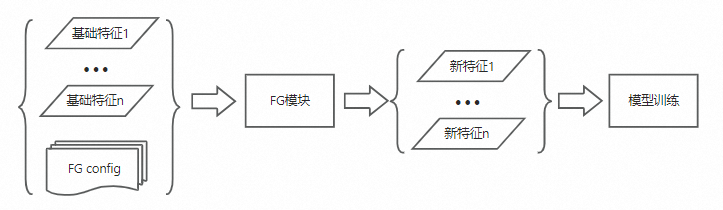
除了基础特征,模型训练实际用的特征会更加复杂,比如交叉多个基础特征生成新的训练特征,即特征生成过程。目前对排序模型而言,按照特征生成(FeatureGenerate)规则进行配置,即可得到需要的训练特征,如图所示:
FG规则: