
CTR模型介绍
点击率(click-through rate, CTR)预估是搜索平台的核心任务之一。它所解决的问题是:给定一个user和一个query,以及与该query所匹配的doc,预测这些doc曝光之后获得点击的概率。这个概率值可以用于排序脚本中,用来提升搜索效果,提升ctr等业务指标。
优势/场景
为了更好的满足用户多场景、多样化的搜索排序业务需求,开放搜索推出了CTR模型功能,可以实现个性化、千人千面的搜索排序效果。
创建并训练模型
创建行业模板,之后进入开放搜索控制台页面,左侧导航栏选择:搜索算法中心>排序配置>CTR预估模型,然后点击创建按钮:
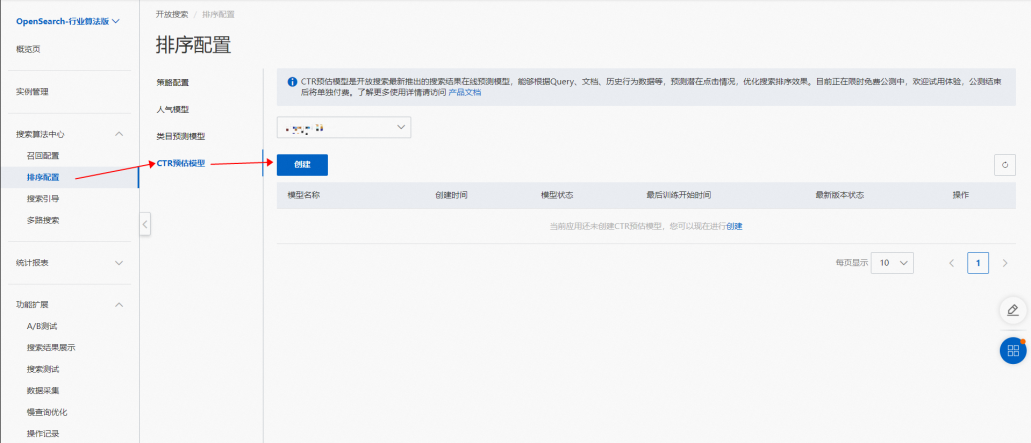
创建CTR预估模型,填写模型名称,设置训练字段:
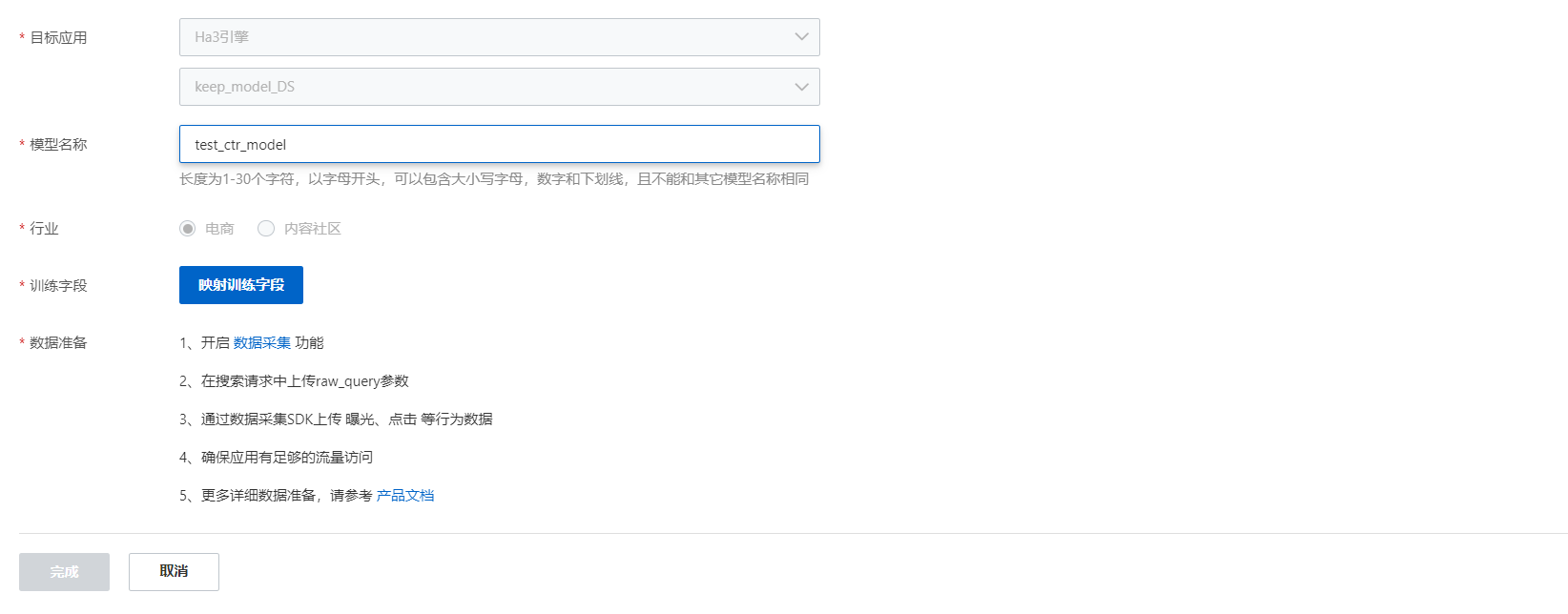
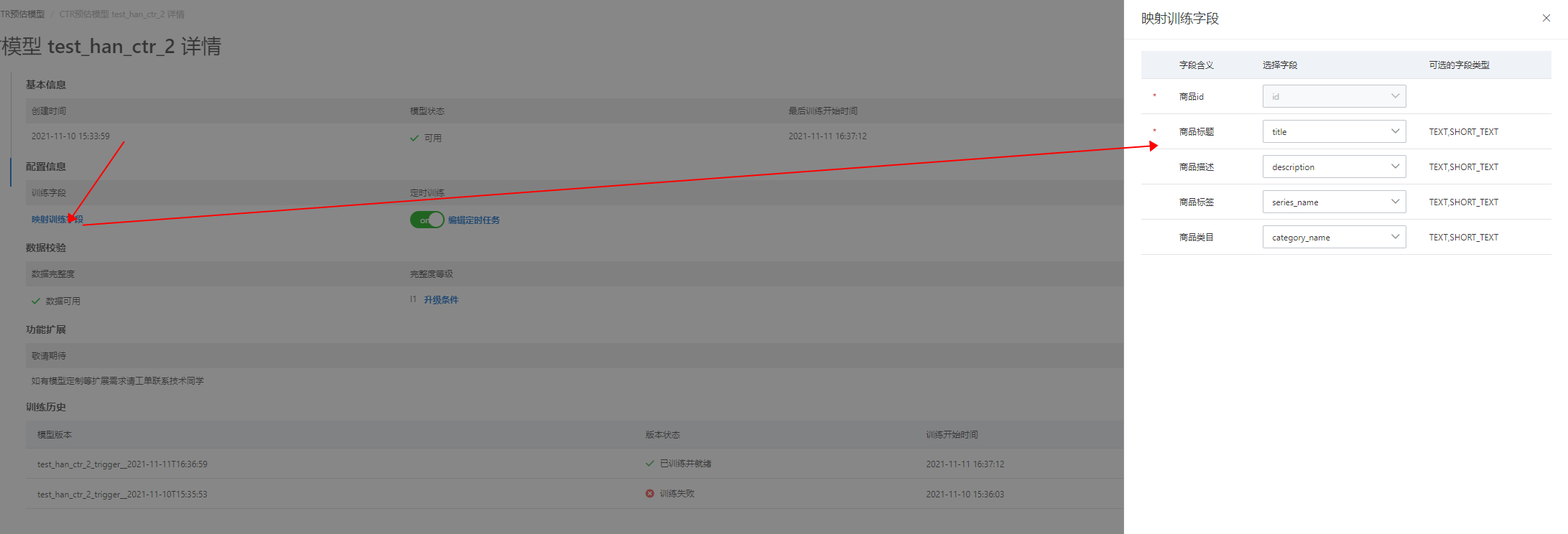
映射训练字段:(目前商品ID,和商品标题是必选项,其他字段设置的越多,模型效果越好)
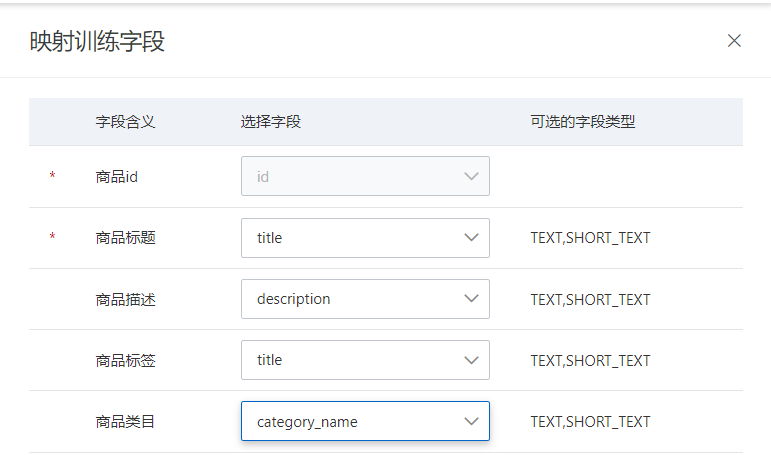
模型创建完成后,在CTR预估模型列表页,找到刚创建的模型,在右侧操作栏中点击“训练模型”:
开始训练后,可在CTR预估模型详情页,可查看模型训练进度:
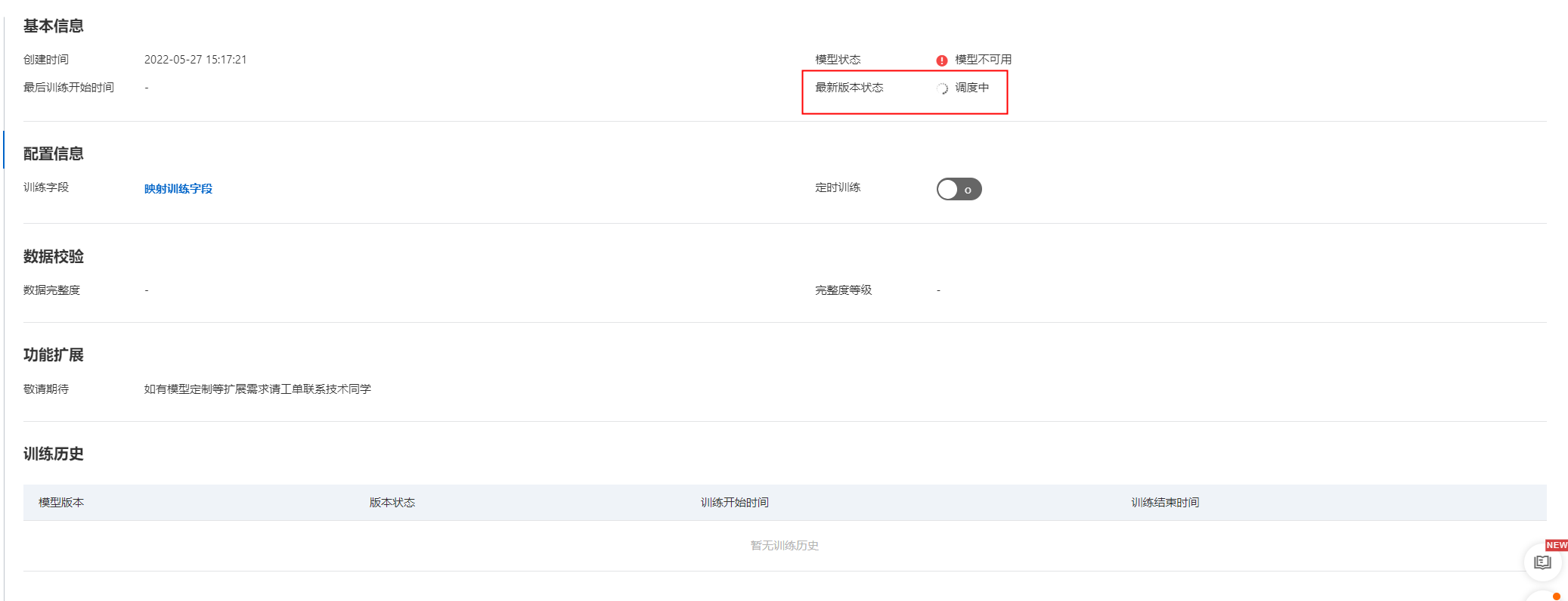
训练完成后,若模型状态会变为可用状态,即可进行使用(若模型状态为不可用,请根据数据校验的完整度等级的升级条件进行调整,满足要求后,第二天再训练即可,若还有问题,可以提工单联系技术同学):
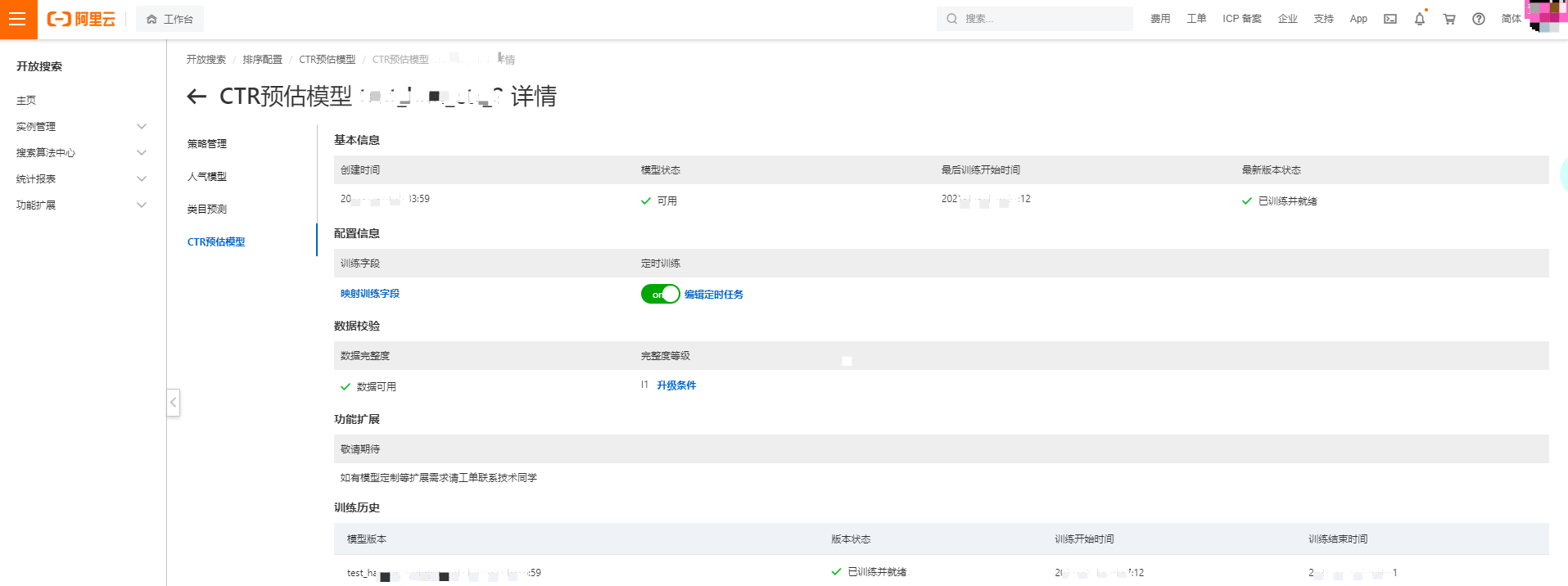
定时训练周期建议设置为每天。
搜索测试
创建一个cava类型的业务排序策略:
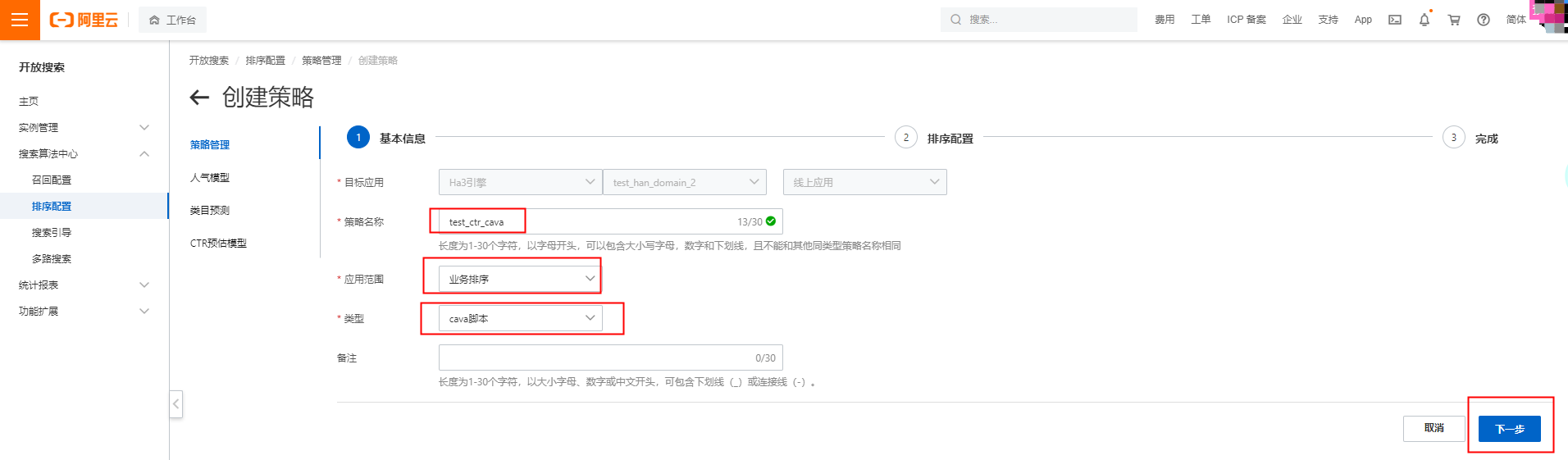
填写策略名称,应用范围选择业务排序,类型选择cava脚本:
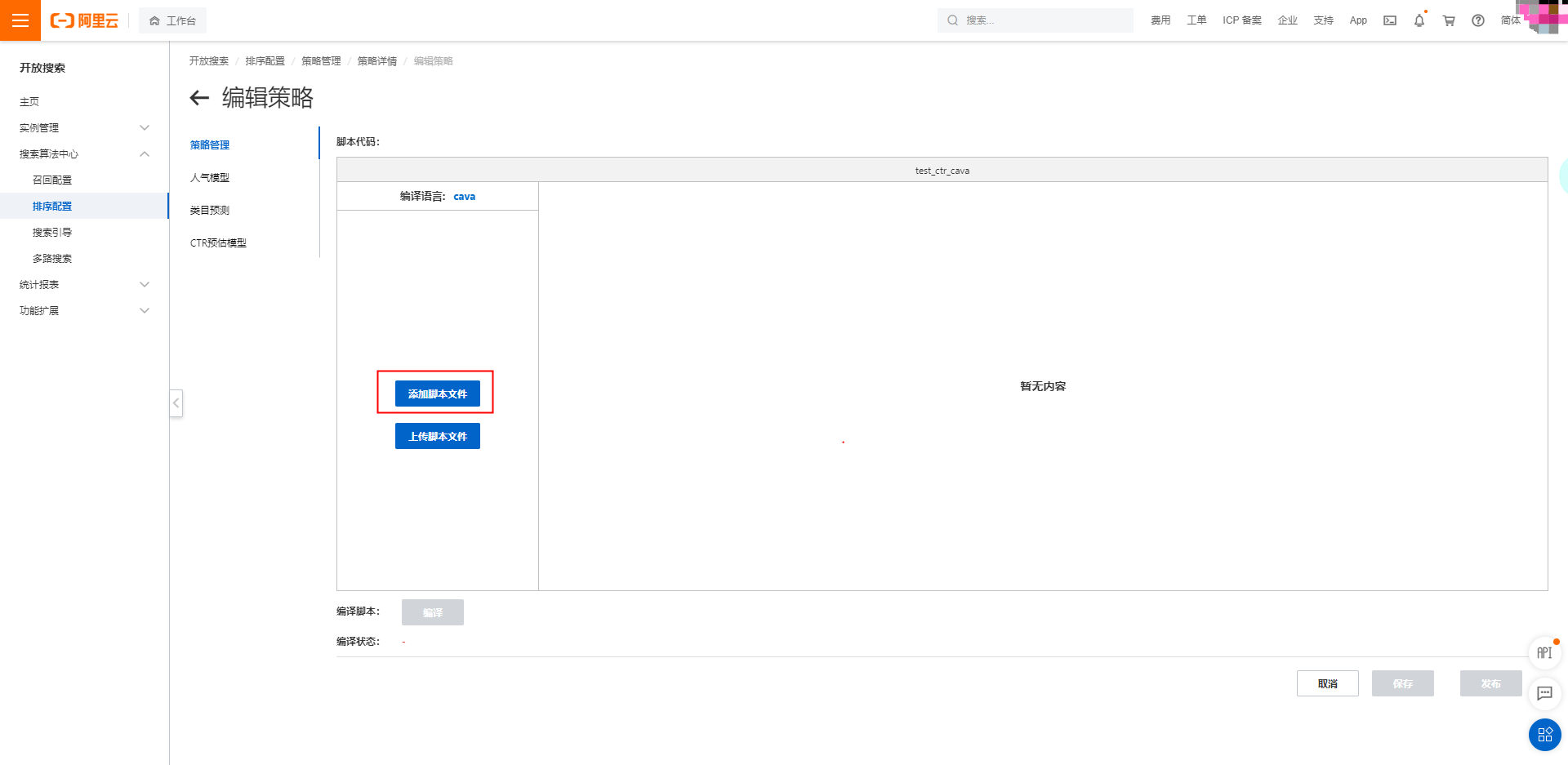
点击添加文件,将cava脚本示例贴到脚本代码中,点击编译,如提示编译成功,点击保存、发布后即可进行
搜索测试:
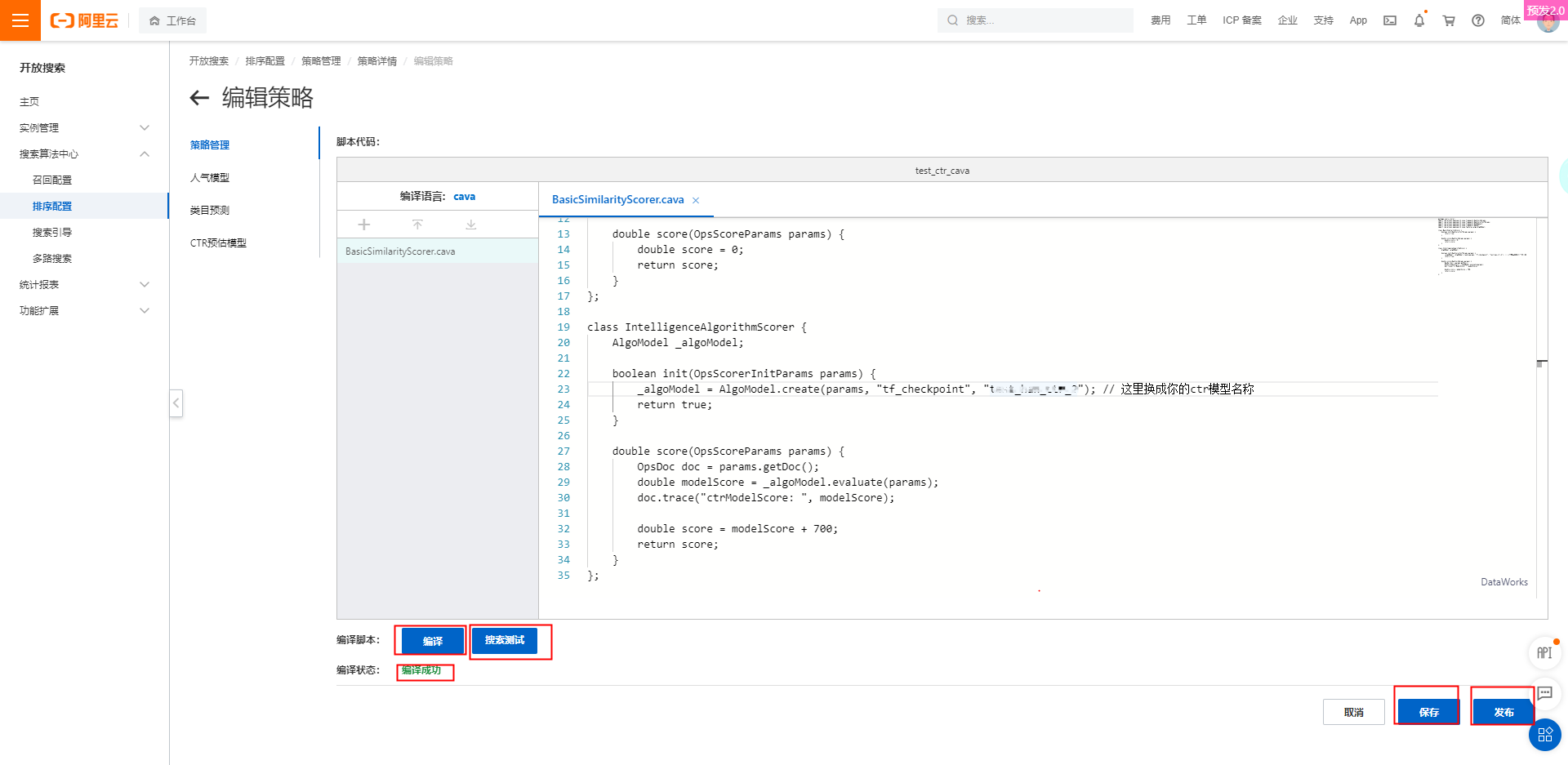
cava脚本示例如下:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.algo.AlgoModel;
class BasicSimilarityScorer {
boolean init(OpsScorerInitParams params) {
return true;
}
double score(OpsScoreParams params) {
double score = 0;
return score;
}
};
class IntelligenceAlgorithmScorer {
AlgoModel _algoModel;
boolean init(OpsScorerInitParams params) {
//注意tf_checkpoint 为固定参数
_algoModel = AlgoModel.create(params, "tf_checkpoint","ctr", "这里换成你的ctr模型名称");
return true;
}
double score(OpsScoreParams params) {
OpsDoc doc = params.getDoc();
double modelScore = _algoModel.evaluate(params);
doc.trace("ctrModelScore: ", modelScore);
double score = modelScore + 700;
return score;
}
};进行搜索测试:
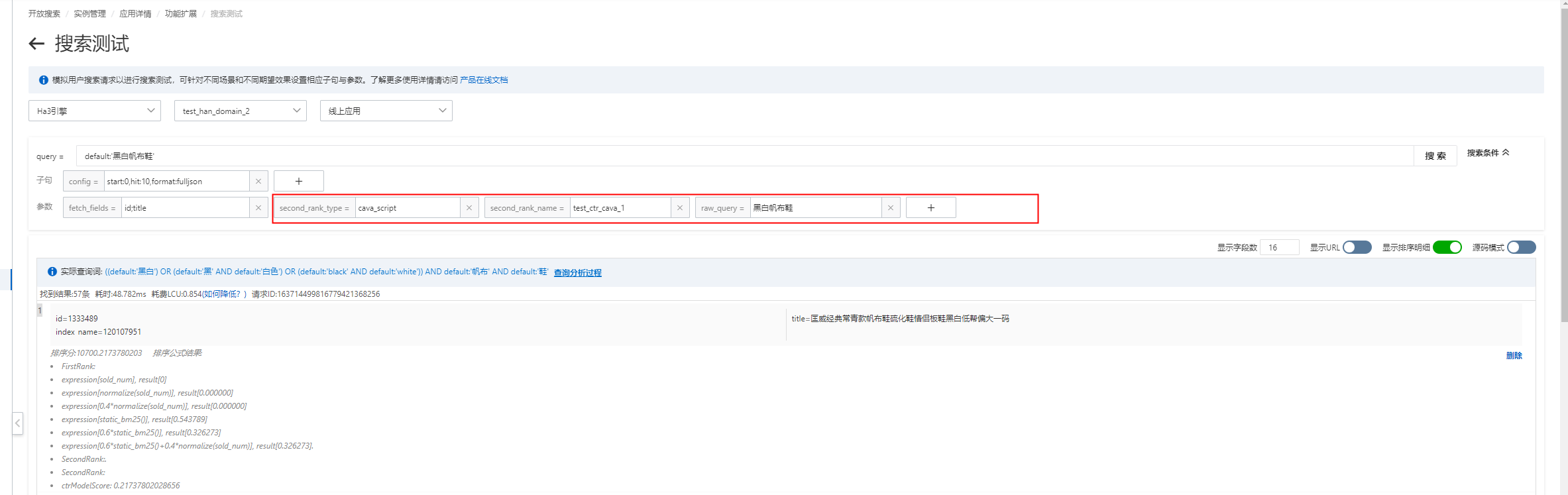
注意:
second_rank_type 、second_rank_name 、raw_query 是必要参数,搜索请求时必须配置;
如果行为数据以及查询时都上传了user_id 参数,模型的打分效果会更好;
CTR模型详情页说明
基本信息
可查看模型的创建时间、状态、最后训练开始时间以及最新版本状态。

配置信息
训练字段:点击“映射训练字段”后,弹出映射训练字段选框,可以修改或删除模型训练字段,修改训练字段后需重新训练模型才会生效:
定时训练:默认开启并每天训练一次,也可以编辑定时任务,自定义训练周期。
数据校验
数据完整度状态包含可用、数据异常;
完整度报告显示当前应用的完整度等级,具体完整度等级可见:
数据完整度 | 介绍 | 晋升条件 |
l0 | 表示数据完全不可用,缺少必要的核心字段,数据量太少,后续的数据处理不能继续进行 | l0-->l1:
|
l1 | 表示数据的核心字段已经具备,满足最基本的入口条件,但行为数据仍存在字段缺失和数据量不足的问题,部分不依赖行为数据的优化可以进行,全面的优化还需要继续解决行为数据的问题 | l1-->l2:
|
l2 | 表示数据质量满足要求,后续的优化可以正常进行,但数据量较小,对优化的最终效果存在一定影响 | l2-->l3:
|
l3 | 表示数据质量和数据量达到合理的水平,具备了正常优化的前提条件 | l3-->l4:
|
l4 | 表示数据规模较大,数据量充足,达到千万级,数据完整度水平较高 | l4-->l5:
|
l5 | 表示数据规模很大,数据量很充足,达到亿级以上,具备深度优化的条件 |
ipv表示每次搜索的点击率,即bhv_type=click;
有上报曝光行为事件且数量大于ipv数量,表示bhv_type=expose的数量大于bhv_type=click的数量(补充:用户有点击某商品,说明该商品一定有曝光,此处该条行为数据需要上传2次,即bhv_type=click和bhv_type=expose都需要上传)
注意事项
现阶段仅支持CTR模型在Cava插件中使用;
现阶段仅支持独享集群规格的实例创建CTR模型;
每个实例最多支持3个CTR模型;
训练字段越多,模型训练效果越好;
训练晋升条件中的raw_query是搜索请求时需要携带的参数,并且要求是独立的、有召回结果的、非重复的查询词,具体用法可参考Java SDK 搜索Demo;
相关API/SDK参考:算法周边。