
DeepSeek-R1系列模型是一款专注于复杂推理任务的大语言模型,在复杂指令理解、推理结果准确性、性能稳定性等方面相比其他大语言模型,有一定优势。OpenSearch LLM智能问答版已集成DeepSeek-R1系列模型,进一步提升企业级RAG效果,本文向您介绍使用步骤。
实例购买与配置
创建OpenSearch LLM智能问答版实例,当前仅上海地域的实例(包括标准版与专业版)支持DeepSeek-R1系列模型,如何创建实例请参见创建LLM智能问答版实例,计费规则请参见产品计费。
说明标准版实例不支持定制训练LLM大语言模型,而专业版实例支持部分LLM的训练,但目前DeepSeek-R1模型尚不支持训练。

导入知识库数据
实例创建成功后,系统自动生成知识库数据表,支持通过文件导入结构化和非结构化数据,也支持批量从URL地址中导入数据。
在实例列表页面,单击目标实例操作列的管理,选择,根据需要选择通过文件导入或者网页链接导入,详情请参见数据配置。

数据状态为完成时,表示当前数据已完成向量化存储,通过查看content查看解析后的文档。|

实例配置视频演示:
效果测试
进入问答测试页,模型选择DeepSeek-R1系列,通过调整Prompt模板、文档召回过滤字段(filter )、文档召回数(top_n)、重排模型等参数,测试不同参数下的问答效果。
以下表格列出关键参数,详细参数使用请参见参数说明。
参数 | 说明 |
Prompt | Prompt(提示词)是您输入大模型的指令,用于明确需求并引导其生成精准、相关的回答或内容,详情请参见Prompt管理。 |
多轮对话 | 设置是否开启多轮对话,如果开启,需要设置用户请求ID,通过ID判断提问者是否为同一个用户,基于同一用户提问进行多轮对话。
|
流式输出 | 建议开启流式输出,实时输出中间结果,减少等待时间。 |
filter | 召回文档时根据filter指定的字段进行过滤,如设置timestamp>1356969600,表示仅从时间戳大于2013年1月1日的文档中获取数据。 |
top_n | 设置召回的文档数,默认为5。 |




通过SDK进行RAG问答
完成效果测试后,在应用系统中通过SDK进行RAG问答。如需更新知识库,可通过控制台快速导入文档,也可以通过SDK导入结构化文档和非结构化文档。
获取访问凭证
在安装和使用SDK前,请确保您已获取访问密钥(AccessKey,简称AK)。通过SDK调用阿里云服务时,发起的请求会携带AccessKey ID和AccessKey Secret加密请求内容生成的签名,进行身份验证及请求合法性校验。
将鼠标悬浮在控制台右上方的账号图标上,单击AccessKey管理。
在AccessKey页面,查看AccessKey信息。

如果AccessKey列表为空或者没有已启用的AccessKey,前往创建AccessKey。
若您使用RAM用户调用,请确保您的RAM用户账号被授予AliyunOpenSearchFullAccess权限。
将AccessKey配置到环境变量
建议您将AccessKey写入环境变量,避免在代码里显式地配置AccessKey,降低AccessKey泄漏风险。
Windows系统
在Windows系统中,您可以使用CMD、PowerShell配置环境变量,或者通过系统属性编辑环境变量。
CMD
添加永久性环境变量
如果您希望环境变量在当前用户的所有新会话中生效,可以按如下操作。
在CMD中运行以下命令。
# <access_key_id>需替换为您的AccessKey ID,<access_key_secret>替换为您的AccessKey Secret。 setx ALIBABA_CLOUD_ACCESS_KEY_ID <access_key_id> setx ALIBABA_CLOUD_ACCESS_KEY_SECRET <access_key_secret>打开一个新的CMD窗口。
在新的CMD窗口运行以下命令,检查环境变量是否生效。
echo %ALIBABA_CLOUD_ACCESS_KEY_ID% echo %ALIBABA_CLOUD_ACCESS_KEY_SECRET%
添加临时性环境变量
如果您仅希望在当前会话中使用该环境变量,可以在CMD中运行以下命令。
# <access_key_id>需替换为您的AccessKey ID,<ACCESS_KEY_SECRET>替换为您的AccessKey Secret。
set ALIBABA_CLOUD_ACCESS_KEY_ID=<access_key_id>
set ALIBABA_CLOUD_ACCESS_KEY_SECRET=<access_key_secret>您可以在当前会话运行以下命令检查环境变量是否生效。
echo %ALIBABA_CLOUD_ACCESS_KEY_ID%
echo %ALIBABA_CLOUD_ACCESS_KEY_SECRET%PowerShell
添加永久性环境变量
如果您希望环境变量在当前用户的所有新会话中生效,可以按如下操作。
在PowerShell中运行以下命令。
# <access_key_id>需替换为您的AccessKey ID,<access_key_secret>替换为您的AccessKey Secret。 [Environment]::SetEnvironmentVariable("ALIBABA_CLOUD_ACCESS_KEY_ID", "<access_key_id>", [EnvironmentVariableTarget]::User) [Environment]::SetEnvironmentVariable("ALIBABA_CLOUD_ACCESS_KEY_SECRET", "<access_key_secret>", [EnvironmentVariableTarget]::User)打开一个新的PowerShell窗口。
在新的PowerShell窗口运行以下命令,检查环境变量是否生效。
echo $env:ALIBABA_CLOUD_ACCESS_KEY_ID echo $env:ALIBABA_CLOUD_ACCESS_KEY_SECRET
添加临时性环境变量
如果您仅希望在当前会话中使用该环境变量,可以在PowerShell中运行以下命令。
# <access_key_id>需替换为您的AccessKey ID,<access_key_secret>替换为您的AccessKey Secret。
$env:ALIBABA_CLOUD_ACCESS_KEY_ID = "<access_key_id>"
$env:ALIBABA_CLOUD_ACCESS_KEY_SECRET = "<access_key_secret>"您可以在当前会话运行以下命令检查环境变量是否生效。
echo $env:ALIBABA_CLOUD_ACCESS_KEY_ID
echo $env:ALIBABA_CLOUD_ACCESS_KEY_SECRET通过系统属性编辑环境变量
我的电脑 右键,单击属性;打开设置界面,单击高级系统设置,打开系统属性界面。
在系统属性界面,单击环境变量,打开环境变量界面。
在界面下方系统变量中,单击新建,打开新建系统变量。
变量名填入:分别新建您的ALIBABA_CLOUD_ACCESS_KEY_ID、ALIBABA_CLOUD_ACCESS_KEY_SECRET,变量值填入您的
<access_key_id>与<access_key_secret>。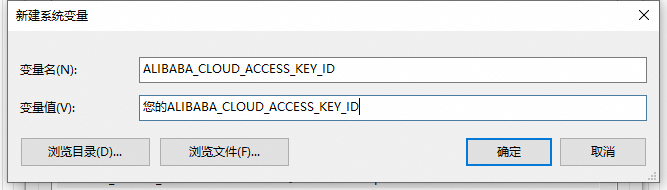
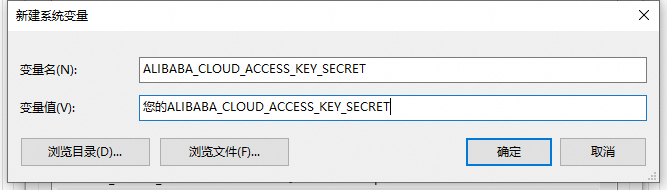
填入后,分别点击三个界面的确定后关闭。至此,环境变量已配置成功。
您可以在终端运行以下命令检查环境变量是否生效。
echo %ALIBABA_CLOUD_ACCESS_KEY_ID%
echo %ALIBABA_CLOUD_ACCESS_KEY_SECRET%macOS系统
添加永久性环境变量
如果您希望环境变量在当前用户的所有新会话中生效,可以添加永久性环境变量。
在终端中执行以下命令,查看默认Shell类型。
echo $SHELL根据默认Shell类型进行操作。
Zsh
执行以下命令来将环境变量设置追加到
~/.zshrc文件中。# <access_key_id>需替换为您的AccessKey ID,<access_key_secret>替换为您的AccessKey Secret。 echo "export ALIBABA_CLOUD_ACCESS_KEY_ID=<access_key_id>" >> ~/.zshrc echo "export ALIBABA_CLOUD_ACCESS_KEY_SECRET=<access_key_secret>" >> ~/.zshrc也可以手动修改
~/.zshrc文件。执行以下命令,使变更生效。
source ~/.zshrc重新打开一个终端窗口,运行以下命令检查环境变量是否生效。
echo $ALIBABA_CLOUD_ACCESS_KEY_ID echo $ALIBABA_CLOUD_ACCESS_KEY_SECRET
Bash
执行以下命令来将环境变量设置追加到
~/.bash_profile文件中。# <access_key_id>需替换为您的AccessKey ID,<access_key_secret>替换为您的AccessKey Secret。 echo "export ALIBABA_CLOUD_ACCESS_KEY_ID=<access_key_id>" >> ~/.bash_profile echo "export ALIBABA_CLOUD_ACCESS_KEY_SECRET=<access_key_secret>" >> ~/.bash_profile也可以手动修改
~/.bash_profile文件。执行以下命令,使变更生效。
source ~/.bash_profile重新打开一个终端窗口,运行以下命令检查环境变量是否生效。
echo $ALIBABA_CLOUD_ACCESS_KEY_ID echo $ALIBABA_CLOUD_ACCESS_KEY_SECRET
添加临时性环境变量
如果您仅希望在当前会话中使用该环境变量,可以添加临时性环境变量。
执行以下命令。
# <access_key_id>需替换为您的AccessKey ID,<access_key_secret>替换为您的AccessKey Secret。 export ALIBABA_CLOUD_ACCESS_KEY_ID=<access_key_id> export ALIBABA_CLOUD_ACCESS_KEY_SECRET=<access_key_secret>执行以下命令,验证该环境变量是否生效。
echo $ALIBABA_CLOUD_ACCESS_KEY_ID echo $ALIBABA_CLOUD_ACCESS_KEY_SECRET
Linux系统
添加永久性环境变量
如果您希望环境变量在当前用户的所有新会话中生效,可以添加永久性环境变量。
执行以下命令来将环境变量设置追加到
~/.bashrc文件中。# <access_key_id>需替换为您的AccessKey ID,<access_key_secret>替换为您的AccessKey Secret。 echo "export ALIBABA_CLOUD_ACCESS_KEY_ID=<access_key_id>" >> ~/.bashrc echo "export ALIBABA_CLOUD_ACCESS_KEY_SECRET=<access_key_secret>" >> ~/.bashrc也可以手动修改
~/.bashrc文件。执行以下命令,使变更生效。
source ~/.bashrc重新打开一个终端窗口,运行以下命令检查环境变量是否生效。
echo $ALIBABA_CLOUD_ACCESS_KEY_ID echo $ALIBABA_CLOUD_ACCESS_KEY_SECRET
添加临时性环境变量
如果您仅希望在当前会话中使用该环境变量,可以添加临时性环境变量。
执行以下命令。
# <access_key_id>需替换为您的AccessKey ID,<access_key_secret>替换为您的AccessKey Secret。 export ALIBABA_CLOUD_ACCESS_KEY_ID=<access_key_id> export ALIBABA_CLOUD_ACCESS_KEY_SECRET=<access_key_secret>执行以下命令,验证该环境变量是否生效。
echo $ALIBABA_CLOUD_ACCESS_KEY_ID echo $ALIBABA_CLOUD_ACCESS_KEY_SECRET
选择开发语言
Java
步骤 1:配置Java环境
步骤 2:获取调用参数
SDK调用依赖以下关键参数:
AppName:应用名称。

host:应用的API访问地址。

步骤 3:调用接口
运行以下代码调用示例:
package com.aliyun.opensearch;
import com.aliyun.opensearch.OpenSearchClient;
import com.aliyun.opensearch.sdk.generated.OpenSearch;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchClientException;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchException;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchResult;
import java.util.HashMap;
import java.util.Map;
public class LLMSearch {
private static String appName = "替换为应用名称";
private static String host = "替换应用的API访问地址";
private static String accesskey = "替换accesskey";
private static String secret = "替换secret";
private static String path = "/apps/%s/actions/knowledge-search";
public static void main(String[] args) {
String appPath = String.format(path, appName);
//ApiReadTimeOut
OpenSearch openSearch = new OpenSearch(accesskey, secret, host);
openSearch.setTimeout(90000);
OpenSearchClient openSearchClient = new OpenSearchClient(openSearch);
Map<String, String> params = new HashMap<String, String>() {{
put("format", "full_json");
put("_POST_BODY", "{\"question\":{\"text\":\"怎么充电\",\"type\":\"TEXT\",\"session\":\"\"},\"options\":{\"retrieve\":{\"doc\":{\"filter\":\"\",\"top_n\":5,\"sf\":\"\",\"dense_weight\":\"0.7\",\"formula\":\"\",\"operator\":\"AND\"},\"entry\":{\"sf\":\"\"},\"image\":{\"sf\":\"\",\"dense_weight\":\"0.7\"},\"qp\":{\"query_extend\":false,\"query_extend_num\":5},\"return_hits\":false,\"rerank\":{\"enable\":true,\"model\":\"ops-bge-reranker-larger\"}},\"chat\":{\"stream\":true,\"prompt_config\":{\"attitude\":\"normal\",\"rule\":\"detailed\",\"noanswer\":\"sorry\",\"language\":\"Chinese\",\"role\":false,\"role_name\":\"AI小助手\",\"out_format\":\"text\"},\"agent\":{\"tools\":[]},\"csi_level\":\"strict\",\"history_max\":\"\",\"link\":\"false\",\"model\":\"deepseek-r1\",\"model_generation\":\"\"}}}");
}};
try {
OpenSearchResult openSearchResult = openSearchClient
.callAndDecodeResult(appPath, params, "POST");
System.out.println("RequestID=" + openSearchResult.getTraceInfo().getRequestId());
System.out.println(openSearchResult.getResult());
} catch (
OpenSearchException e) {
System.out.println("RequestID=" + e.getRequestId());
System.out.println("ErrorCode=" + e.getCode());
System.out.println("ErrorMessage=" + e.getMessage());
} catch (
OpenSearchClientException e) {
System.out.println("ErrorMessage=" + e.getMessage());
}
}
}Python
步骤 1:配置 Python 环境
配置虚拟环境(可选)
步骤 2:获取参数
SDK调用依赖以下关键参数:
app_name:应用名称。
endpoint:应用的API访问地址。
步骤 3:调用接口
BaseRequest参考:Python client 示例。
# -*- coding: utf-8 -*-
import time, os
from typing import Dict, Any
from Tea.exceptions import TeaException
from Tea.request import TeaRequest
from alibabacloud_tea_util import models as util_models
from BaseRequest import Config, Client
class LLMSearch:
def __init__(self, config: Config):
self.Clients = Client(config=config)
self.runtime = util_models.RuntimeOptions(
connect_timeout=10000,
read_timeout=90000,
autoretry=False,
ignore_ssl=False,
max_idle_conns=50,
max_attempts=3
)
self.header = {}
def searchDoc(self, app_name: str,body:Dict, query_params: dict={}) -> Dict[str, Any]:
try:
response = self.Clients._request(method="POST", pathname=f'/v3/openapi/apps/{app_name}/actions/knowledge-search',
query=query_params, headers=self.header, body=body, runtime=self.runtime)
return response
except TeaException as e:
print(e)
if __name__ == "__main__":
# 配置统一的请求入口和 需要去掉http://
endpoint = "<endpoint>"
# 支持 protocol 配置 HTTPS/HTTP
endpoint_protocol = "HTTP"
# 用户识别信息
# 从环境变量读取配置的AccessKey ID和AccessKey Secret,
# 运行代码示例前必须先配置环境变量,参考文档上面“配置环境变量”步骤
access_key_id = os.environ.get("ALIBABA_CLOUD_ACCESS_KEY_ID")
access_key_secret = os.environ.get("ALIBABA_CLOUD_ACCESS_KEY_SECRET")
# 支持 type 配置 sts/access_key 鉴权. 其中 type 默认为 access_key 鉴权. 使用 sts 可配置 RAM-STS 鉴权.
# 备选参数为: sts 或者 access_key
auth_type = "access_key"
# 如果使用 RAM-STS 鉴权, 请配置 security_token, 可使用 阿里云 AssumeRole 获取 相关 STS 鉴权结构.
security_token = "<security_token>"
# 配置请求使用的通用信息.
# type和security_token 参数如果不是子账号,需要省略
Configs = Config(endpoint=endpoint, access_key_id=access_key_id, access_key_secret=access_key_secret,
security_token=security_token, type=auth_type, protocol=endpoint_protocol)
# 创建 opensearch 实例
# 请将<应用名称>替换为您创建的智能问答版实例名称
ops = LLMSearch(Configs)
app_name = "<应用名称>"
# --------------- 文档搜索 ---------------
docQuery = {"question": {"text": "搜索", "type": "TEXT"}, "options": {"chat": {"model": "deepseek-r1"}}}
res1 = ops.searchDoc(app_name=app_name, body=docQuery)
print(res1)