
本文将介绍以MaxCompute为数据源时如何添加表。
前置条件
了解MaxCompute ,如果您对MaxCompute 没有过多的了解,可什么是MaxCompute进行参考;
表权限,在配置MaxCompute 数据表时需要登录OpenSearch的账号对该表有相应的权限(describe,select,download,字段的label权限),赋权语句如下:
-- 添加账号
add user ****@aliyun.com;
-- 给该账号赋相应的表权限
GRANT describe,select,download ON TABLE table_xxx TO USER ****@aliyun.com
-- 由于ODPS开启了字段权限校验,导致拉取数据的时候无法访问高权限的字段,表索引build不出来,碰到这种情况需要授权给账号字段级别的访问权限。
-- 给整个Project统一授权
SET LABEL 3 to USER bs*******@aliyun.com
-- 给单表授权
GRANT LABEL 3 ON TABLE table_xxx(col1, col2) TO ****@aliyun.com召回引擎版支持的MaxCompute 表字段类型有:STRING 、BOOLEAN、DOUBLE、BIGINT、DATETIME;
配置MaxCompute 数据源
1、进入OpenSearch控制台,在左上角切换到OpenSearch-召回引擎版,在实例管理页面对应的列表中找到所属实例,点击操作栏中的管理:

点击‘去配置’按钮,开始实例配置。
2、表管理界面开始配置表基础信息,填写表名称,分片数和数据更新资源数:
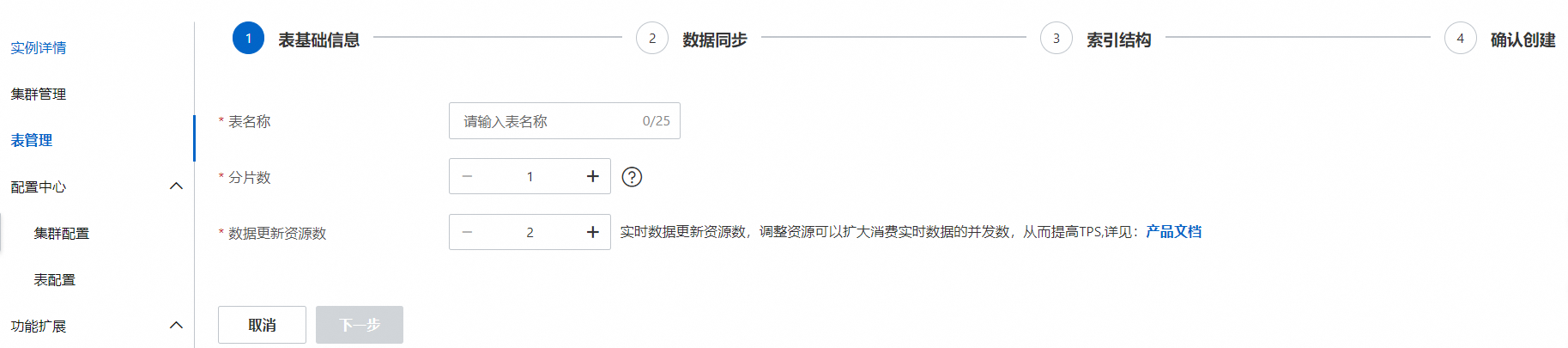
配置说明:
表名称:可自定义,不支持使用project.tablename。
数据分片数:分片数设置时,各索引表分片数需保持一致;或至少一个索引表分片数为1,其余索引表分片数一致,表分片不超过256的正整数即可(建议不超过实例数据节点数的3倍)。
数据更新资源数:数据更新所用资源数,每个索引默认免费提供2个4核8G的更新资源,超出免费额度的资源将产生费用,详情可参考召回引擎版计费概述。
3、数据同步,配置数据源,校验通过后,点击下一步:

配置参数说明:
全量数据来源:选择MaxCompute+API
Project:访问的目标MaxCompute项目名称
accesskeyId:阿里云账号或RAM用户的AccessKey ID
accesskeySecret:AccessKey ID对应的AccessKey Secret
Table:访问的目标MaxCompute表名
分组键partition:MaxCompute数据源必须设置分区键; 示例:ds=20170626
自动索引重建:是否开启自动索引重建任务,如果开启,则将在识别到当前数据源的变更时,自动对引用该数据源的索引表进行索引重建
开启自动索引重建,则必须创建done表,创建方式,可参考下方自动索引重建;
4、字段配置,配置完成后,点击下一步:
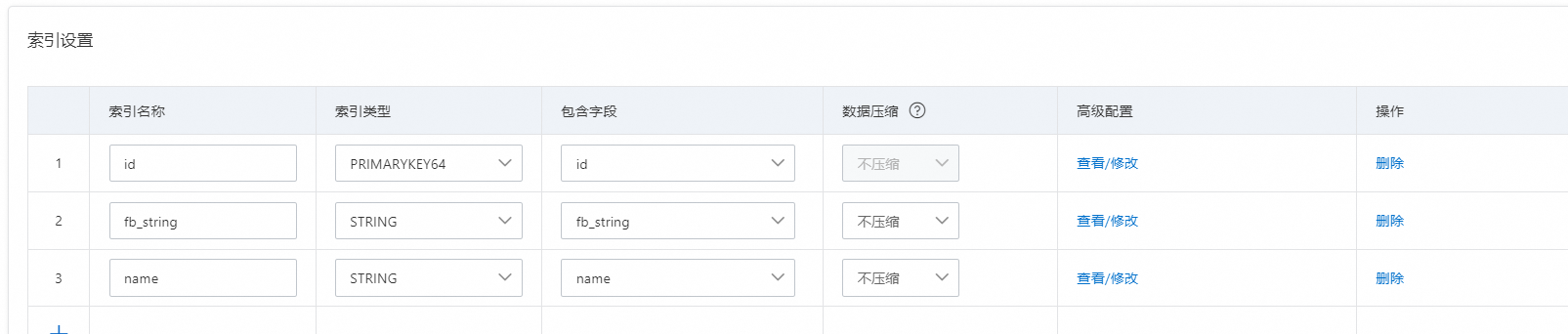
 5、索引配置,配置完成后,点击下一步:
5、索引配置,配置完成后,点击下一步:
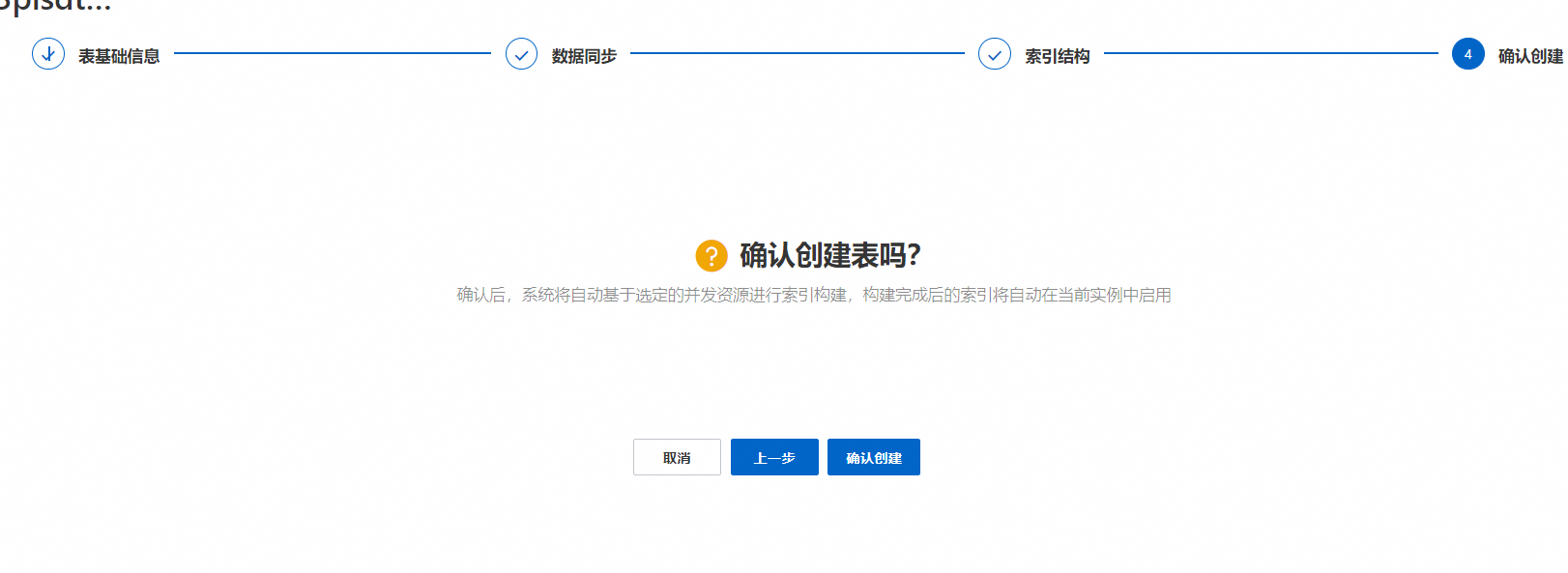
 6、确认创建,点击确认创建后,系统将自动创建配置好的表:
6、确认创建,点击确认创建后,系统将自动创建配置好的表:
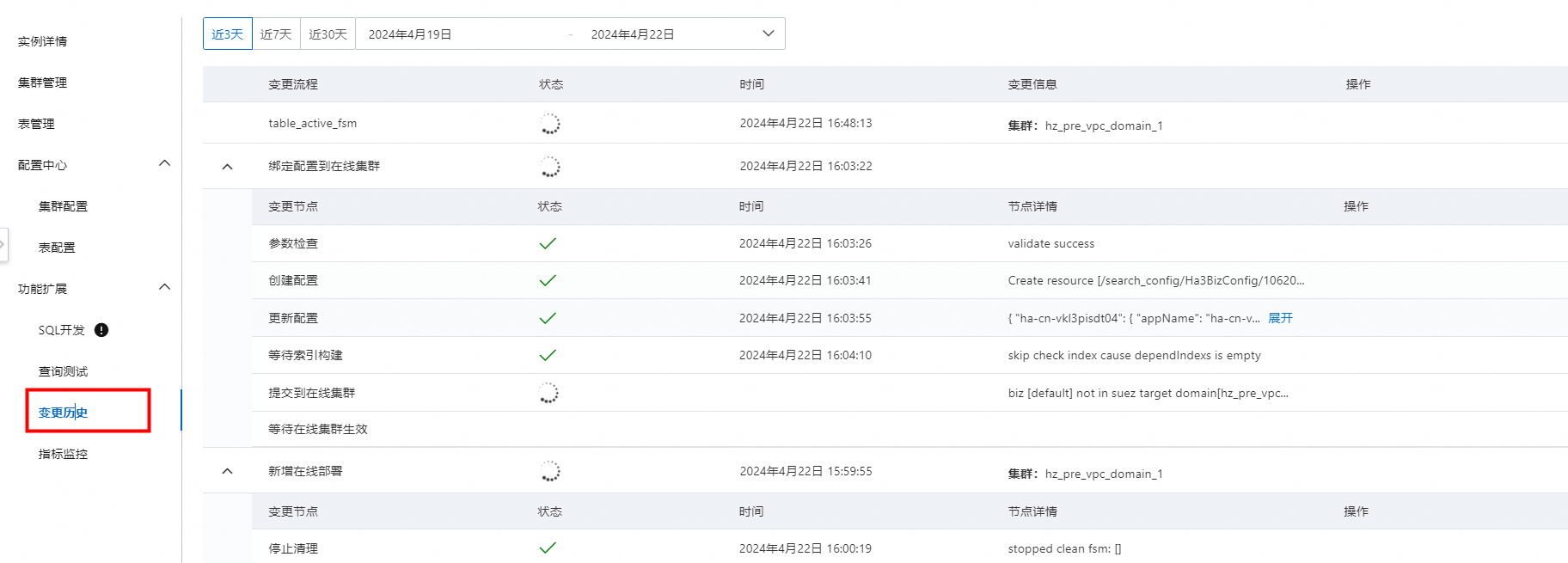
7、可在变更历史中查看创建表的进度:
注意:
全量数据来源:用户的数据来源,命名规则为实例名称_用户自定义名称;
Project、accesskeyId、accesskeySecret、Table、分组键partition:用户访问MaxCompute数据源所需要的参数;
自动索引重建:是否开启自动索引重建任务,如果开启,则将在识别到当前数据源的变更时,自动对引用该数据源的索引表进行索引重建;
开启自动索引重建,则必须创建done表,创建方式,可参考下方自动索引重建;
自动索引重建
当用户在配置数据源开启自动索引重建时,表示召回引擎版实例会根据用户的done表变动去自动索引重建。
举例:假设用户的MaxCompute 数据表mytable,分区为ds=20220113,第一次配置数据源索引重建之后,以后每天产出一个新分区(分区数据是表的全量数据),需要召回引擎版实例扫描到新分区然后自动进行索引重建拉取新分区数据,此时就需要:自动索引重建+done表 实现此功能,操作步骤如下:
添加数据源时候,开启自动索引重建:

在MaxCompute 设置done 表,假设源表名为mytable,分区键名称为ds,那么done表表名为mytable_done,分区键名称为ds,两张表在MaxCompute 显示为:

odps:sql:xxx> show tables;
InstanceId: xxx
SQL: .
ALIYUN$xxx@aliyun.com:mytable #全量数据源的表
ALIYUN$xxx@aliyun.com:mytable_done #控制自动全量的done表done 表的示意图:
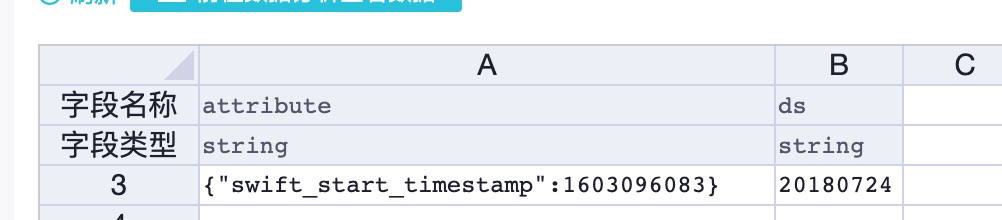
创建done表语句:
create table mytable_done (attribute string) partitioned by (ds string);当mytable表分区ds=20220114 数据完成产出后,需要设置done表,以触发召回引擎版实例的索引重建;
-- 添加分区
alter table mytable_done add if not exists partition (ds="20220114");
-- 插入自动全量信号数据
insert into table mytable_done partition (ds="20220114") select '{"swift_start_timestamp":1642003200}';最终done表内容如下所示:
odps:sql:xxx> select * from mytable_done where ds=20220114 limit 1;
InstanceId: xxx
SQL: .
+-----------+----+
| attribute | ds |
+-----------+----+
| {"swift_start_timestamp":1642003200} | 20220114 |
+-----------+----+最终当done表插入自动全量信号数据后,召回引擎版实例会扫描done的信号,然后自动触发索引重建。
注意:
要求done表至少有一个分区键,并且分区键名称必须与源表的分区键名称一致;
done表添加的分区必须是源表中存在的分区,若源表的分区有、ds="20220114"、ds="20220115"、ds="20220116",那么done表新加的分区也必须在源表分区范围内;
注意事项
创建表时,MaxCompute的table名称不可带有project名称,否则会导致build时识别不了表名报错。
编辑表时,不可修改表名称;
MaxCompute的数据源所配置的表需要是有分区的表;
用户在MaxCompute上产出的表作为全量输入,使用API数据源推送实时数据;