
在索引结构时可以对向量索引进行高级配置,以下将详细说明这些高级版配置的参数含义。
在配置索引结构时,索引设置中可以对向量索引进行高级配置:

详细的配置参数如下:
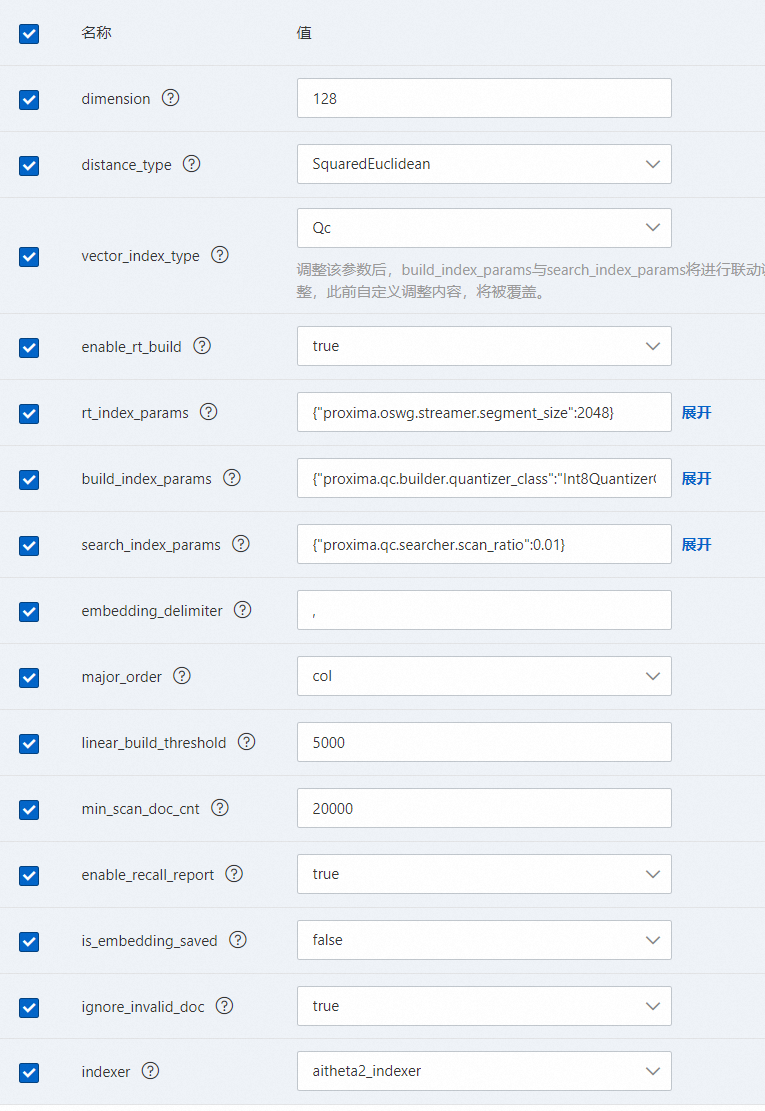
参数说明:
参数名称 | 可选值 | 参数描述 |
dimension | 大于1的整数 | 向量维度 |
distance_type |
| 向量距离 |
vector_index_type |
| 向量索引算法 |
enable_rt_build |
| 是否支持实时索引,true表示开启实时索引 |
rt_index_params | 默认值 | 实时索引参数 |
build_index_params | 默认值 | 索引构建参数,和builder_name参数对应 |
search_index_params | 默认值 | 索引检索参数,和searcher_name参数对应 |
embedding_delimiter | 默认为逗号,可自定义 | 向量分隔符 |
major_order |
| 数据存储方式 |
linear_build_threshold | 默认值为5000 | 线性构建的阈值,若文档数量低于该阈值,则会使用LinearBuilder构建, LinearSearcher检索。默认是10000,用线性构建的好处是可以节省内存,召回结果无损, 但是若数据规模较大时,性能极差。 |
min_scan_doc_cnt | 默认值为20000 | 召回候选集的个数最小值,默认10000,和proxima.qc.searcher.scan_ratio的概念类似。两者都配置的情况下,取两者的最大值 |
enable_recall_report | 默认为true,开启 | 是否开启召回率指标汇报 |
is_embedding_saved | 默认为false,不保存 | 是否保存原始向量。如果开启INT8/FP16量化且开启实时检索,务必开启该选项,否则会导致批次增量构建失败 |
ignore_invalid_doc | 默认为true,开启 | 是否忽略有问题的向量数据(补:向量维度不正确、或无向量数据,开启该配置后,错误的向量数据会直接丢弃) |
indexer |
| 构建向量索引的插件,目前仅支持aitheta2_indexer。 |