方案概览
方案介绍:
OpenSearch召回引擎版:OpenSearch-召回引擎版是阿里巴巴自主研发的大规模分布式搜索引擎,支持了淘宝、天猫、菜鸟、优酷乃至海外电商在内整个集团的搜索业务,同时也支撑了阿里云上的开放搜索业务。OpenSearch-召回引擎版经过多年的发展,在满足业务高可用、高时效性、低成本等需求的同时,也沉淀出一套自动化运维系统,使用它的用户可以根据自己的业务特点构建自己的搜索服务。
数据集成 Data Integration:数据集成 Data Integration是阿里云对外提供的安全、低成本、稳定高效、弹性伸缩的数据同步平台,属于DataWorks的核心能力之一,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动及同步能力。
如果您想将现有的数据传输到召回引擎版中,可以借助数据集成Data Integration进行数据的传输,完成数据的传输只需3步:
创建实例并完成初始化配置:创建OpenSearch-召回引擎版实例(完成表的配置),购买数据集成Data Integration(资源组绑定到工作空间)。
配置数据同步任务:新增OpenSearch数据源,并确认网络可连通,然后在数据集成控制台配置数据同步任务,将数据源数据同步到OpenSearch。
问答测试:返回到OpenSearch-召回引擎版控制台对传输的数据进行查询测试。
配置说明:
使用限制:由于OpenSearch网络架构的限制,一个资源组只能同时同步到一个OpenSearch实例,因此请将召回引擎版实例和数据集成Data Integration配置为同一地域。
数据源支持情况:数据集成目前支持40种以上的数据源类型(包括关系型数据库、非结构化存储、大数据存储、消息队列等),通过定义来源与去向数据源,并使用数据集成提供的数据抽取插件(Reader)、数据写入插件(Writer),实现任意结构化、半结构化数据源之间的数据传输。
步骤一:购买和配置召回引擎版
1.购买召回引擎版实例
创建OpenSearch召回引擎版实例,可参考购买OpenSearch召回引擎版实例。
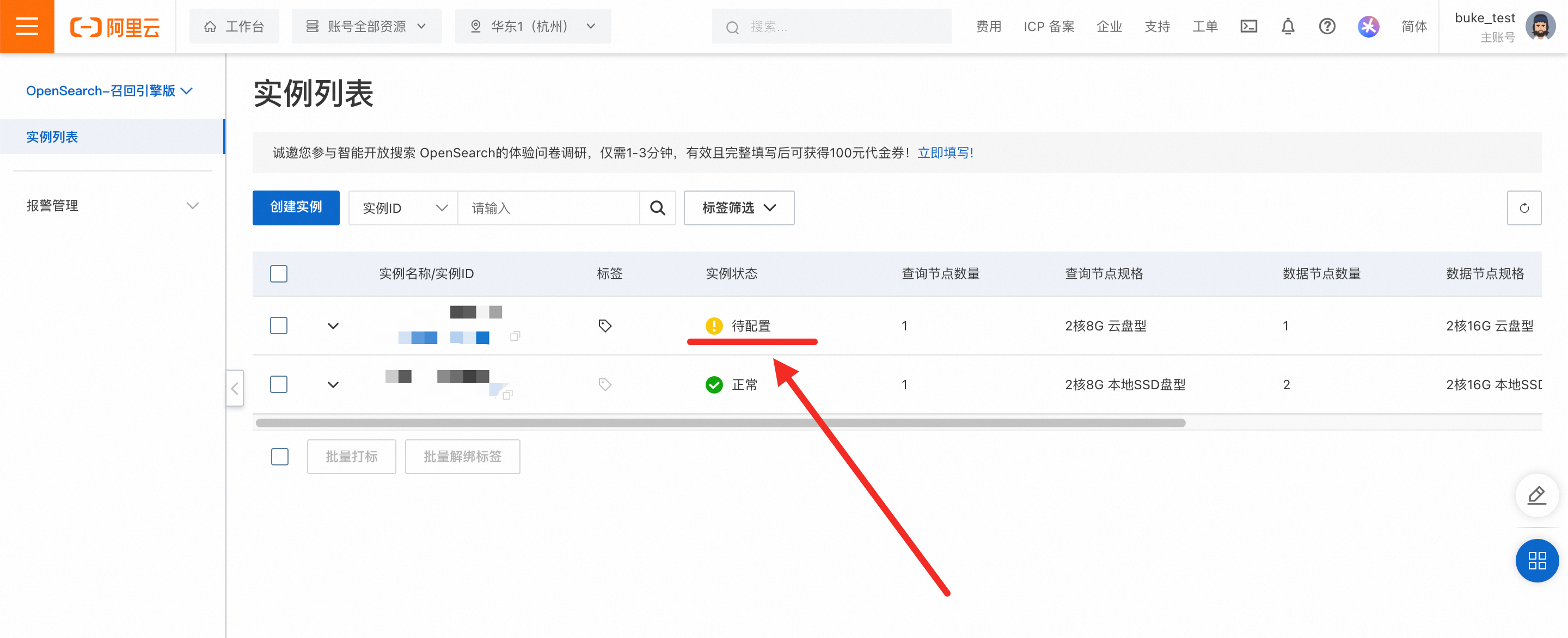
2.配置召回引擎版实例
新购的实例其状态为“待配置”,我们需要为新创建的召回引擎版实例配置一张表,在操作栏中点击配置,就可以进行表配置的流程。
表基础信息:填写表基础信息,完成后点击下一步。
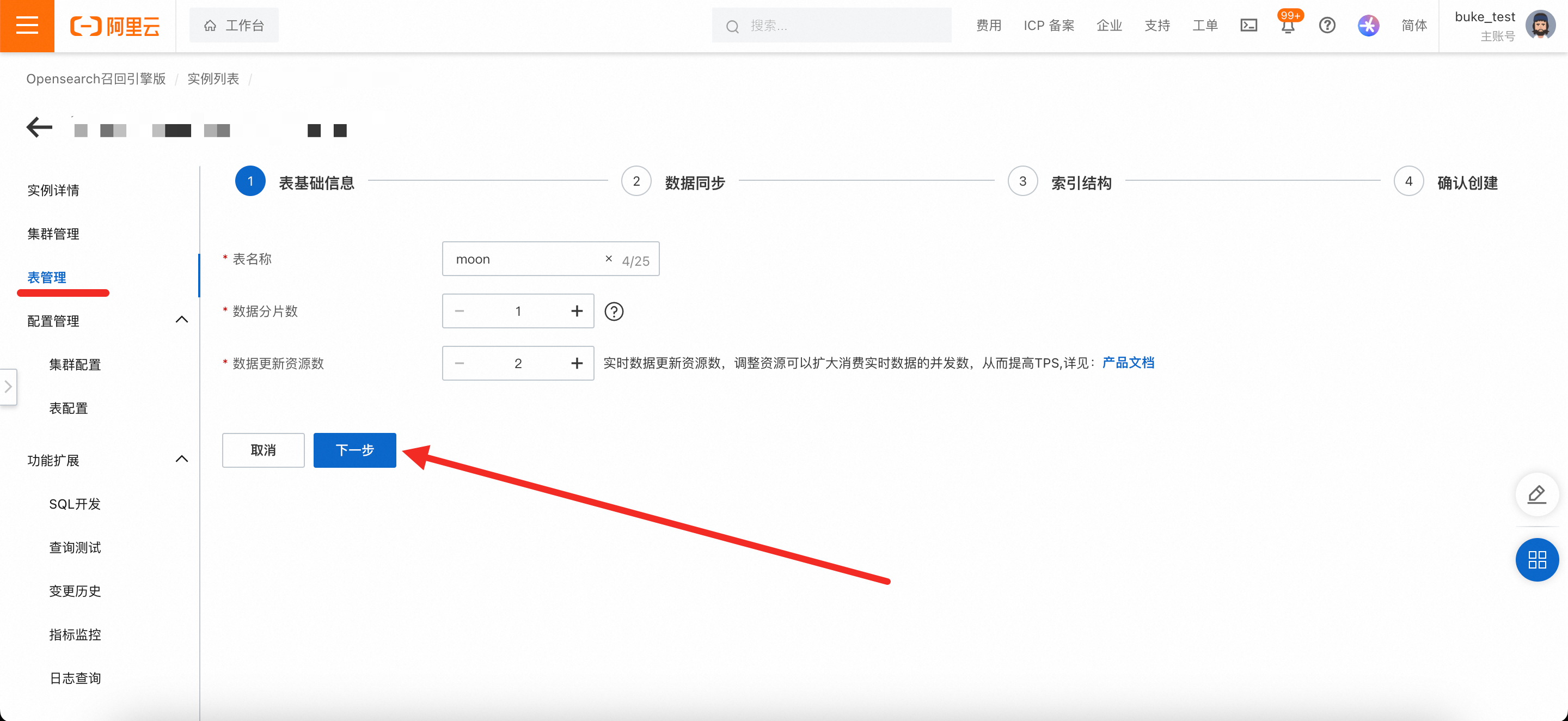
表名称:可自定义
数据分片数:分片数设置时,各索引表分片数需保持一致;或至少一个索引表分片数为1,其余索引表分片数一致,表分片数不超过256的正整数即可(建议不超过实例数据节点数的3倍)。
数据更新资源数:数据更新所用资源数,每个索引默认免费提供2个4核8G的更新资源,超出免费额度的资源将产生费用,详情可参考召回引擎版计费概述。
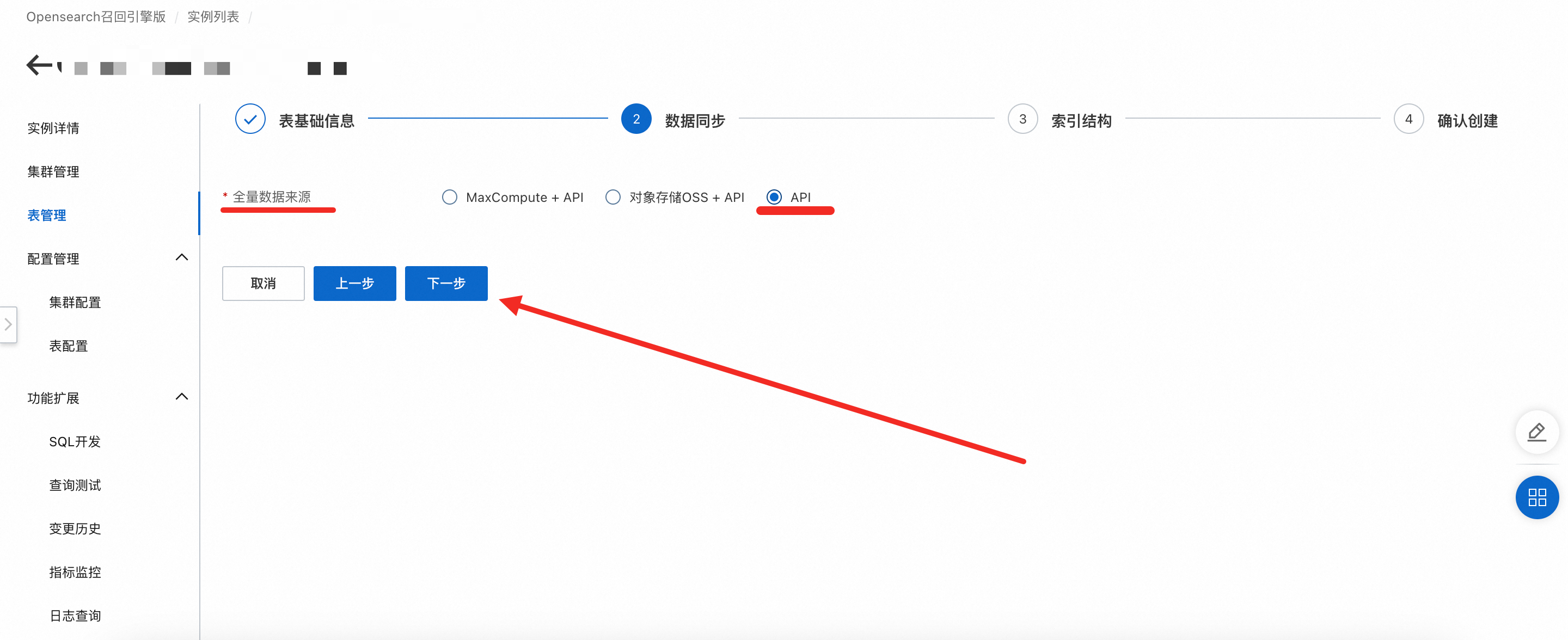
数据同步:全量数据来源选择API的方式,表示用户的数据通过API的方式推送至实例中,完成后点击下一步。
索引结构:对字段、索引进行设置,建议字段名称与原始数据表中名称一致,便于后续在DataWorks中配置字段映射关系。
主键设置:
属性字段:可以选择是否压缩,默认为不压缩,选择file_compressor表示开启压缩。
数据压缩:字段内容的压缩,通过去重等方式实现数据压缩,字段内容可以选择是否压缩,默认为不压缩,默认多值和STRING类型选择uniq,单值数值类型选择equal。
设置说明:
如果开启了属性压缩,建议前往「集群管理-节点状态-表加载策略」编辑索引加载方式,以此降低对性能的影响。
配置分析方式的字段类型必须为TEXT类型。
支持复制字段操作,复制出的新字段(DUP字段)与原字段内容保持一致(推送不一致内容时,将采用原字段内容覆盖),如期望字段内容不一致,请手动删除DUP字段高级配置中的copy from配置。
当数据中缺少字段或字段为空时,系统将自动补充默认值,数字类型默认补0,STRING类型默认补空字符串,支持自定义默认值。
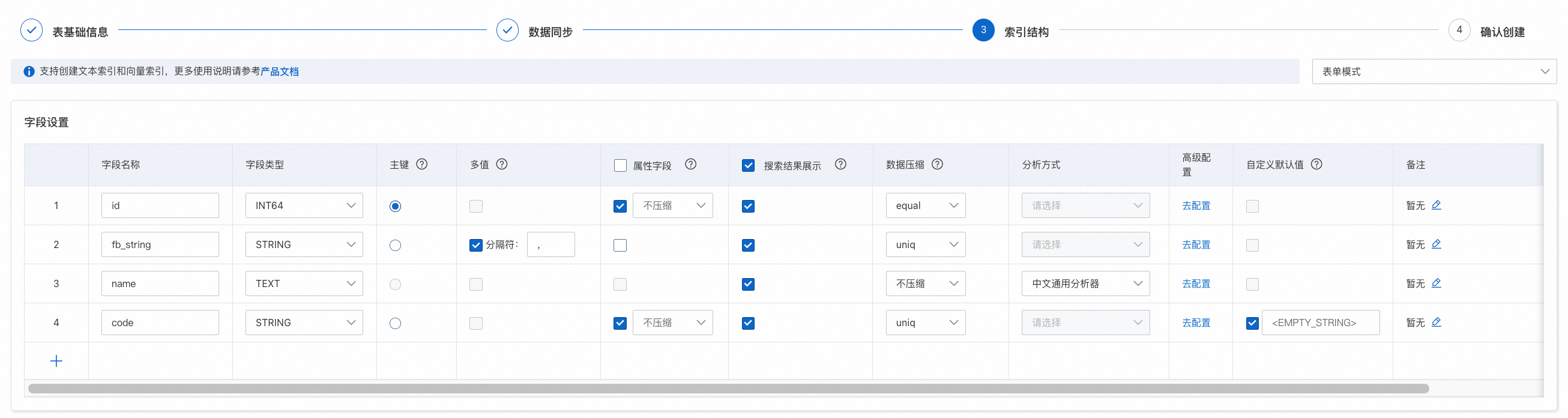
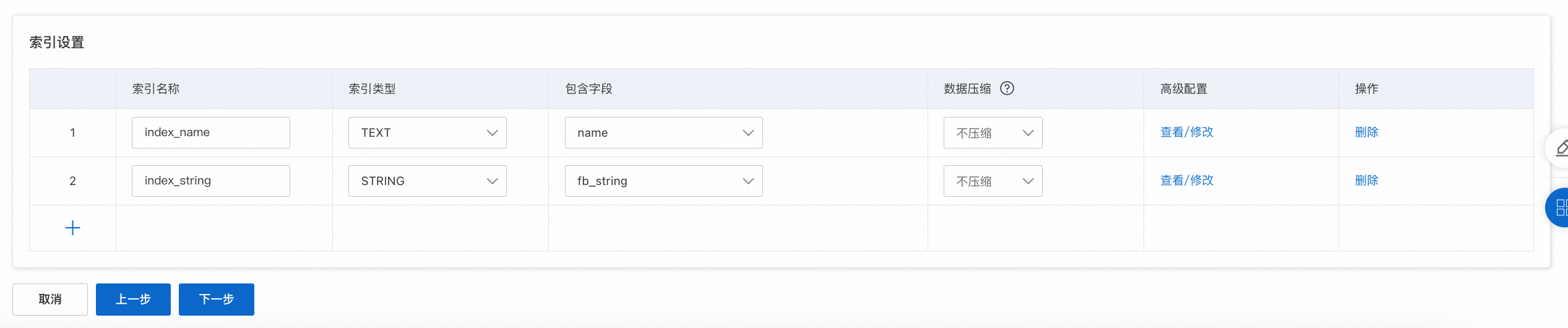
索引设置:给需要进行索引检索的字段配置对应的索引。
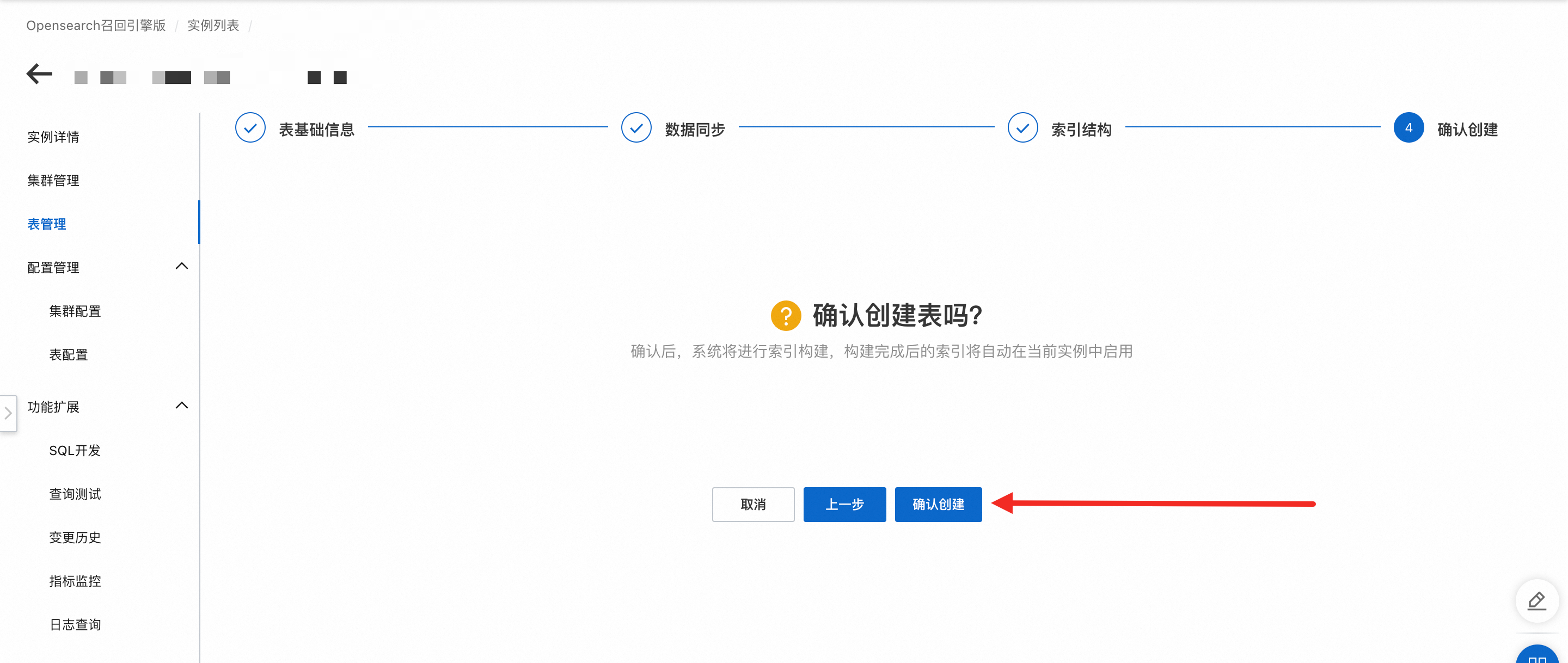
确认创建:点击确认创建后,系统将自动创建配置好表。
步骤二:购买和配置Data Integration
1.购买Data Integration
进入数据集成Data Integration售卖页,可以按需求创建实例,但需要注意地域的选择需与召回引擎版实例一致,可选择独享资源或通用资源任意一种。
2.资源组绑定到工作空间
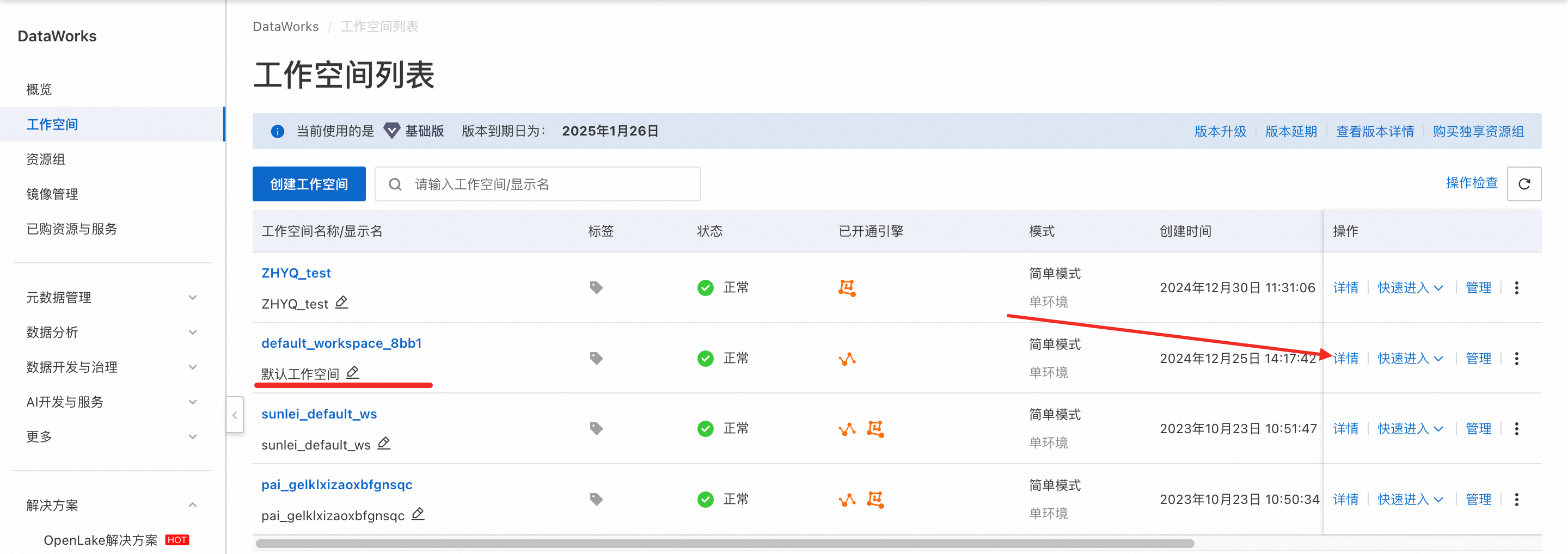
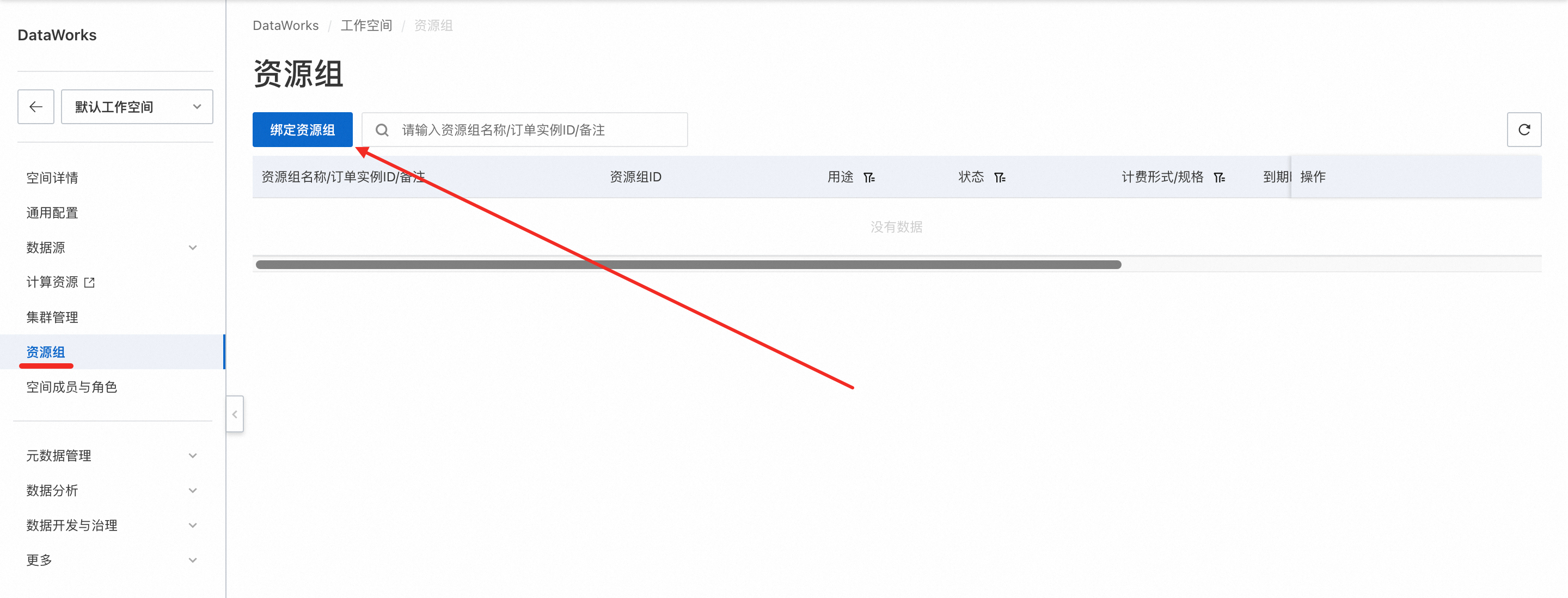
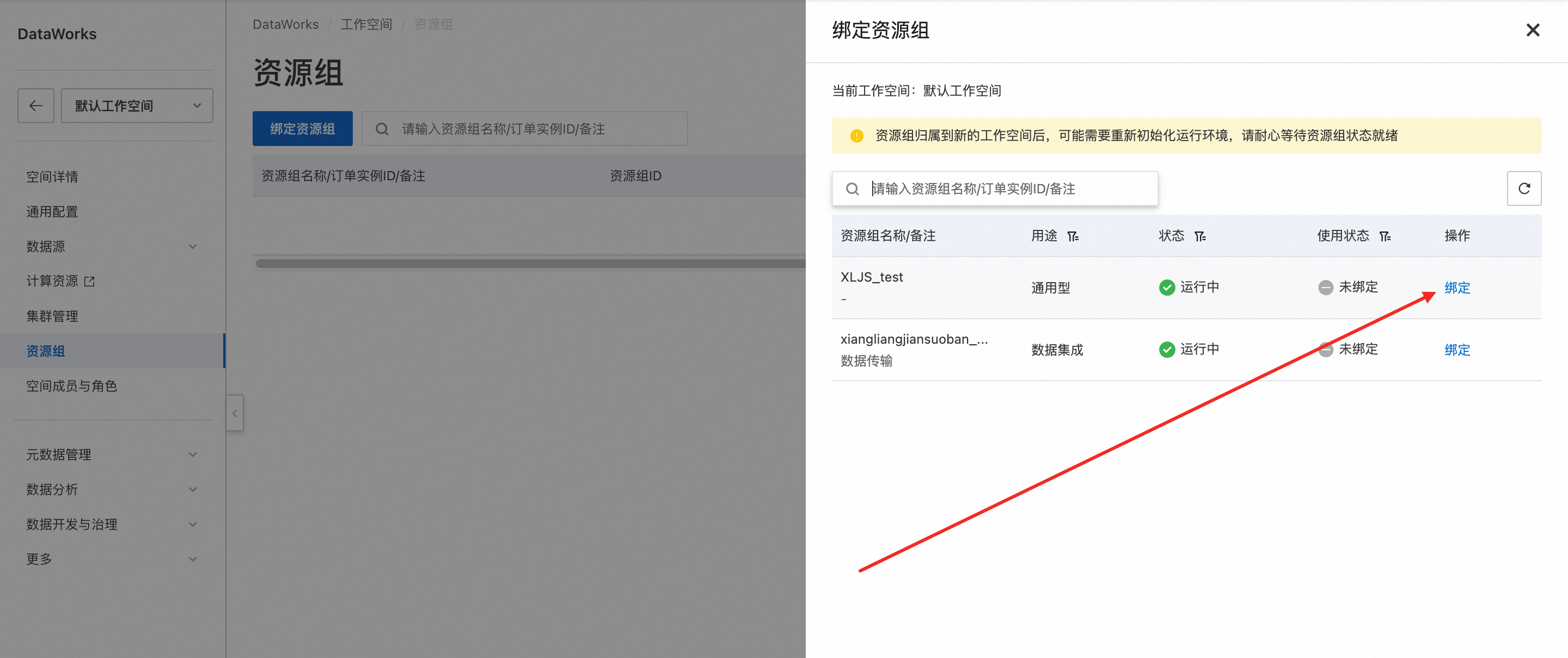
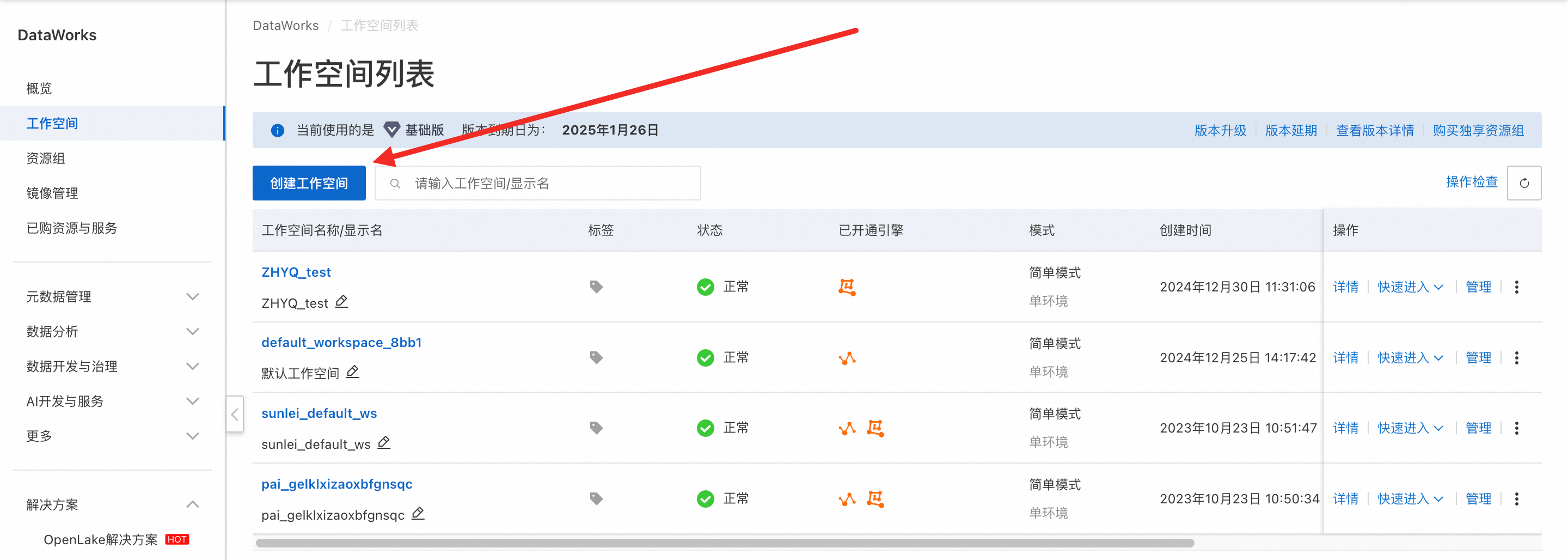
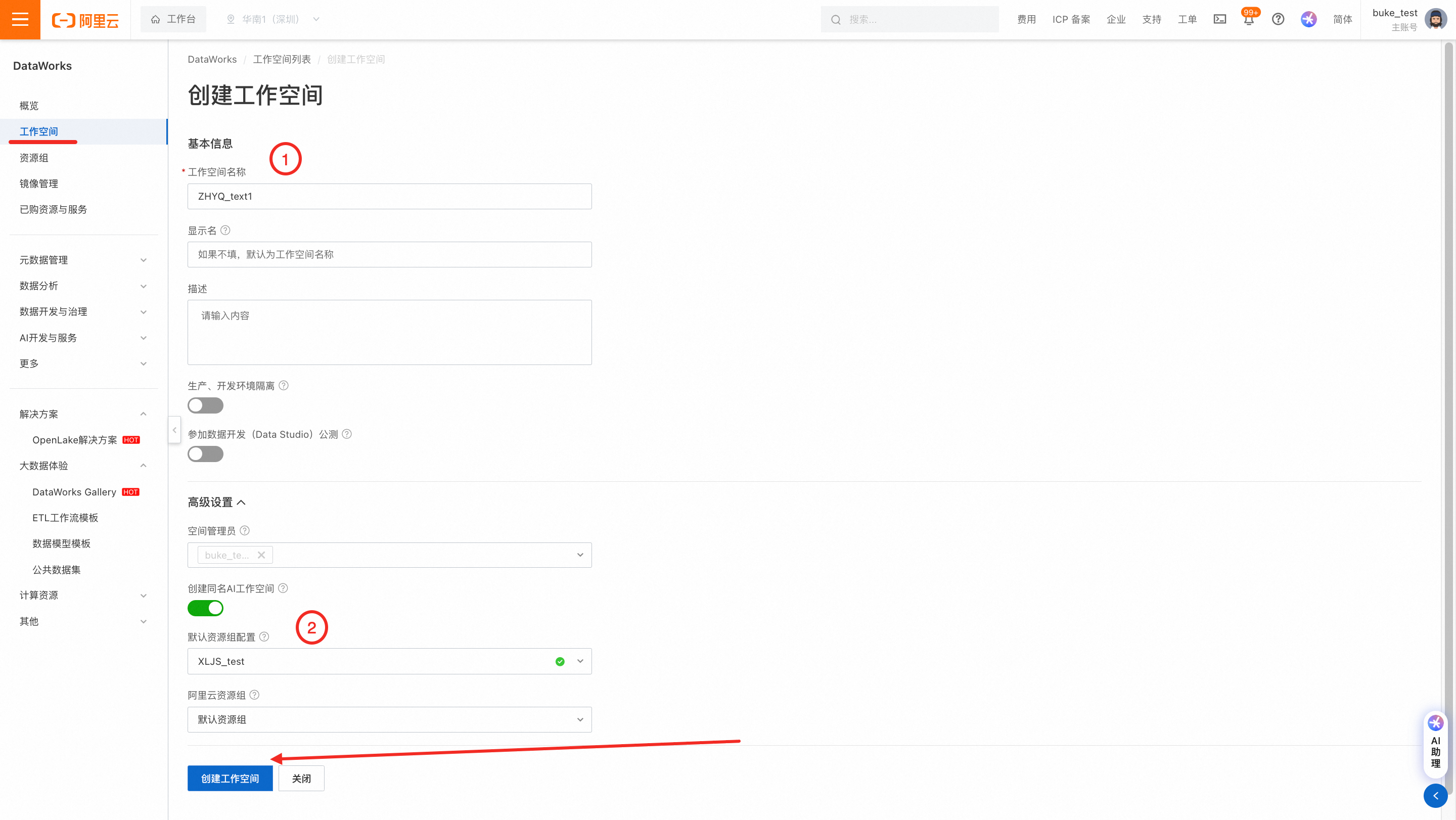
进入DataWorks控制台→工作空间,需要将已购买的DataWorks资源组绑定到工作空间中,可以选择绑定到默认工作空间,或者创建一个新的工作空间。
绑定默认工作空间:
创建工作空间:
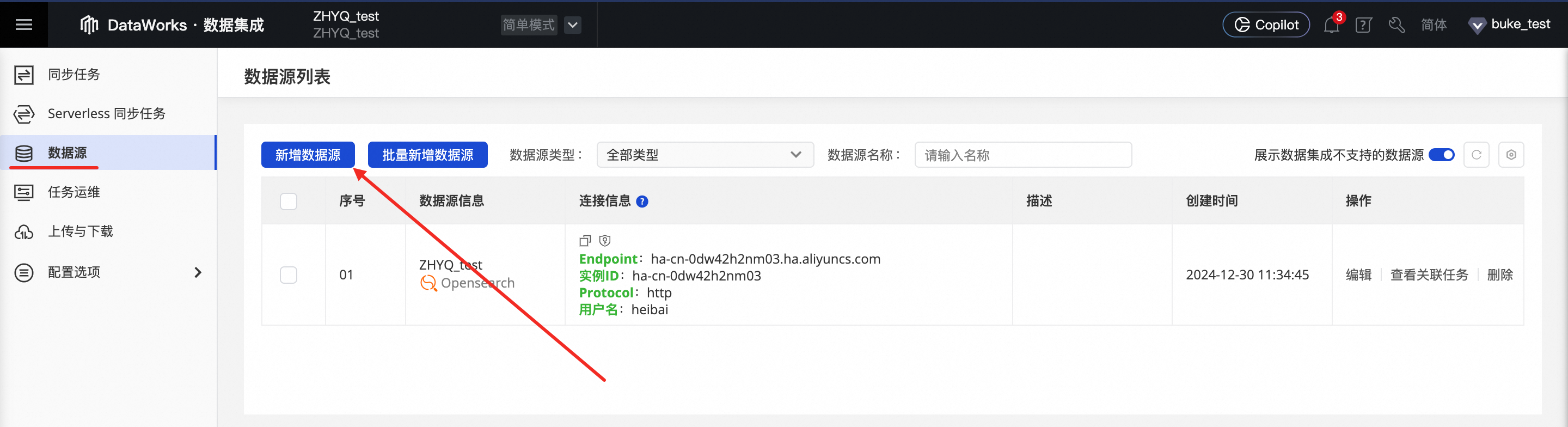
步骤三:新增数据源
DataWorks的数据源用于连接不同的数据存储服务,在配置数据集成同步任务之前,您需要首先定义好同步任务的来源端和去向端数据源信息,以便在配置同步任务时,能够通过选择数据源名称来确定数据的读取和写入数据库。
返回到DataWorks工作空间列表页面,找到绑定好资源组的工作空间,在操作栏中选择快速进入→数据集成进入DataWorks管理中心。
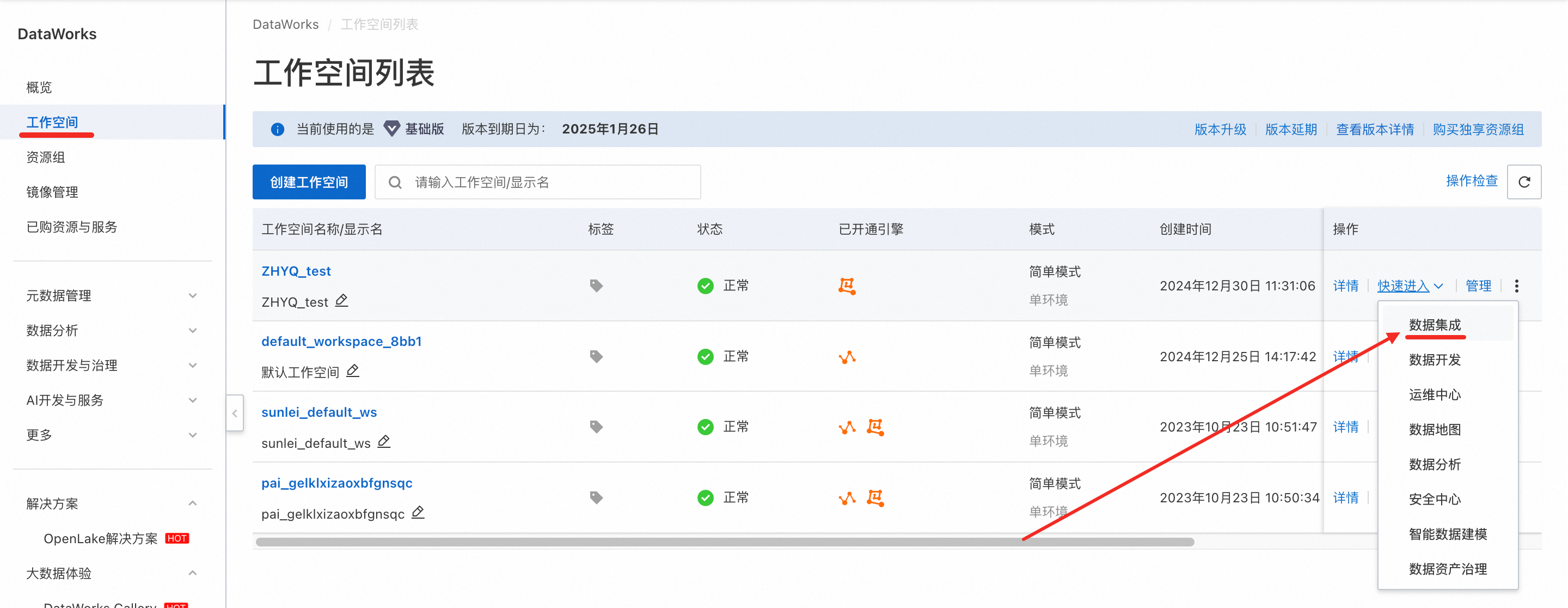
在左侧导航栏选择数据源→新增数据源,进行新增数据源的创建。
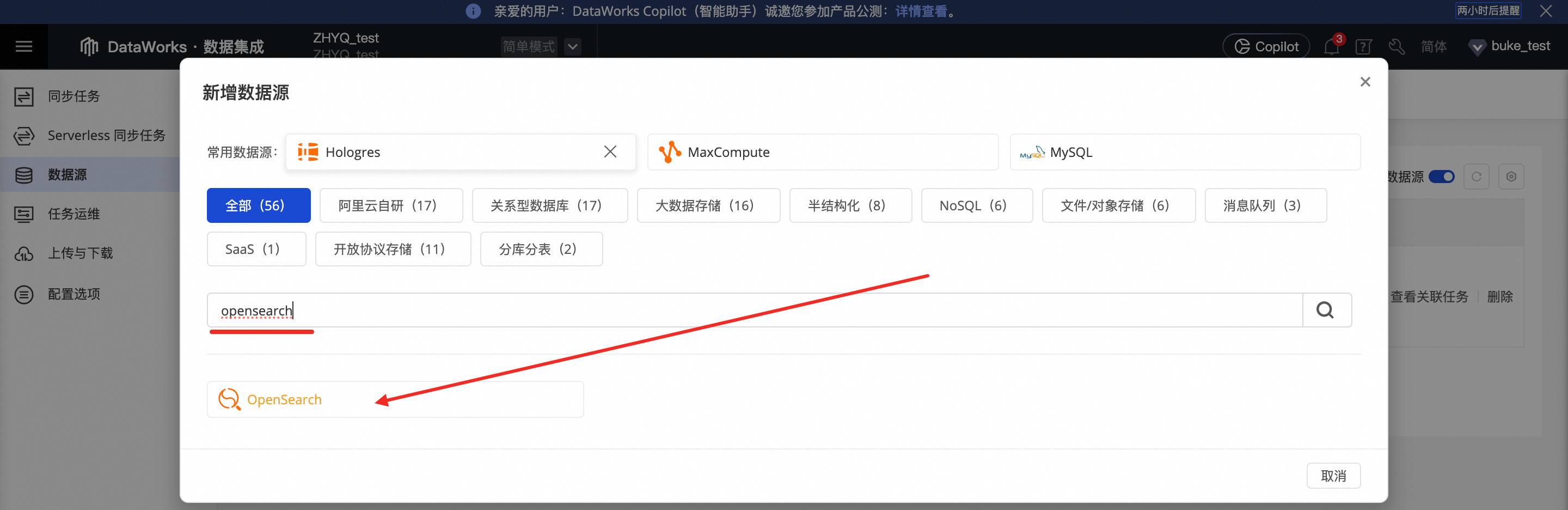
在新增数据源的搜索栏中找到OpenSearch的数据源,进入新增OpenSearch数据源页面。
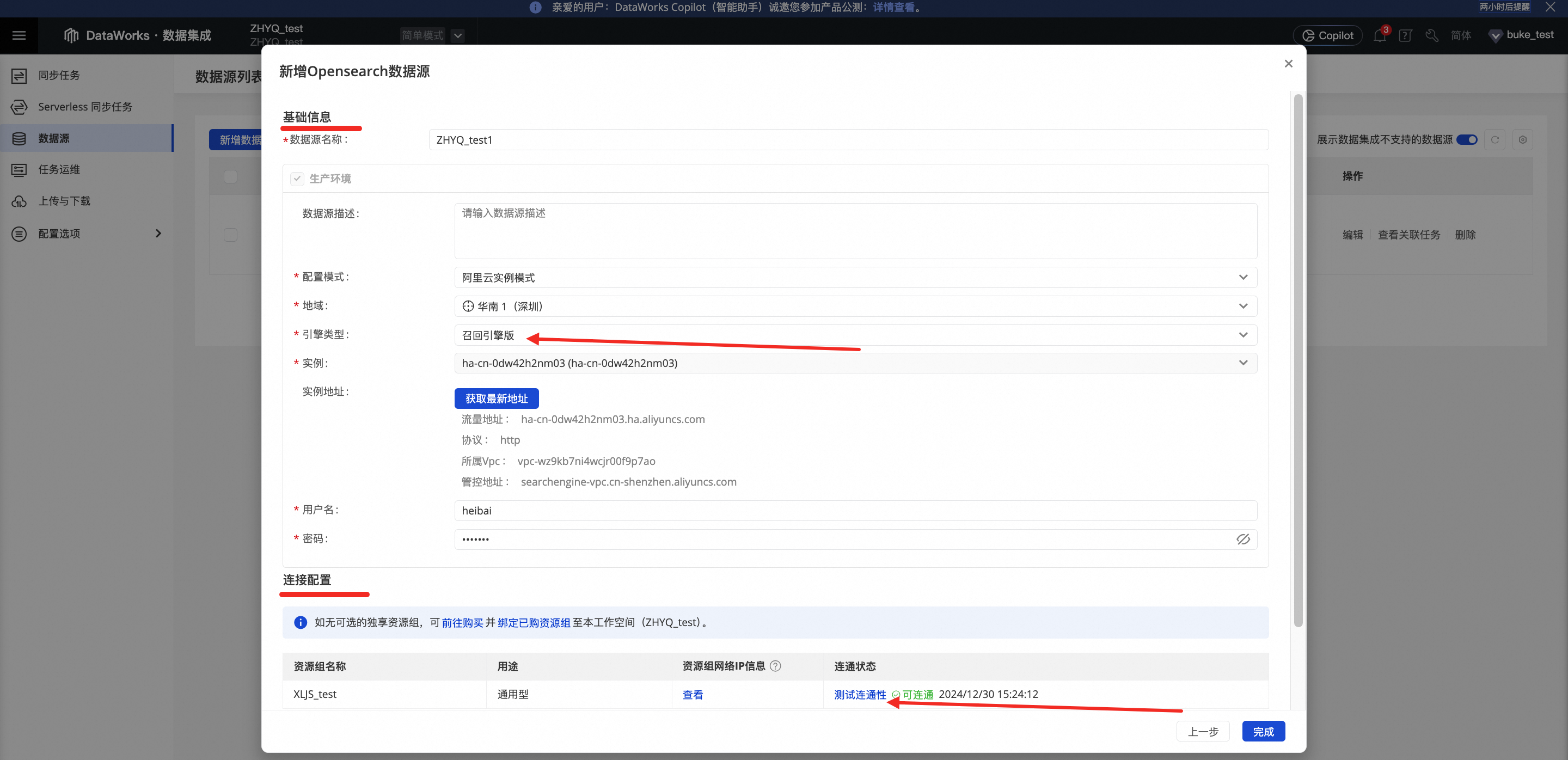
先对基础信息进行设置(引擎类型需要选择召回引擎版),完成后在连接配置中单击测试连通性,如测试资源组连通性状态为可连通,即完成新增数据源的创建。
如果显示无法连通,表示资源组与数据源无法连通,后续相应数据源任务将无法正常执行,此时您需要根据右侧弹出的连通性诊断工具窗口,自助解决连通性问题,连通性诊断工具会提示目前连通失败的原因(例如检查您设置的账号、密码、连接地址、创建的实例状态是否异常等),请根据提示进行修改调整。
步骤四:配置同步任务
新建同步任务:在左侧导航栏中选择同步任务,对同步任务的来源和去向进行设置,然后单击新建同步任务。
DataWorks支持众多数据源作为数据集成的输入与输出数据源,可通过数据集成模块的数据源为数据集成任务创建数据源,本次演示的数据来源以Elasticsearch为例(数据源已提前创建完毕),去向选择OpenSearch。
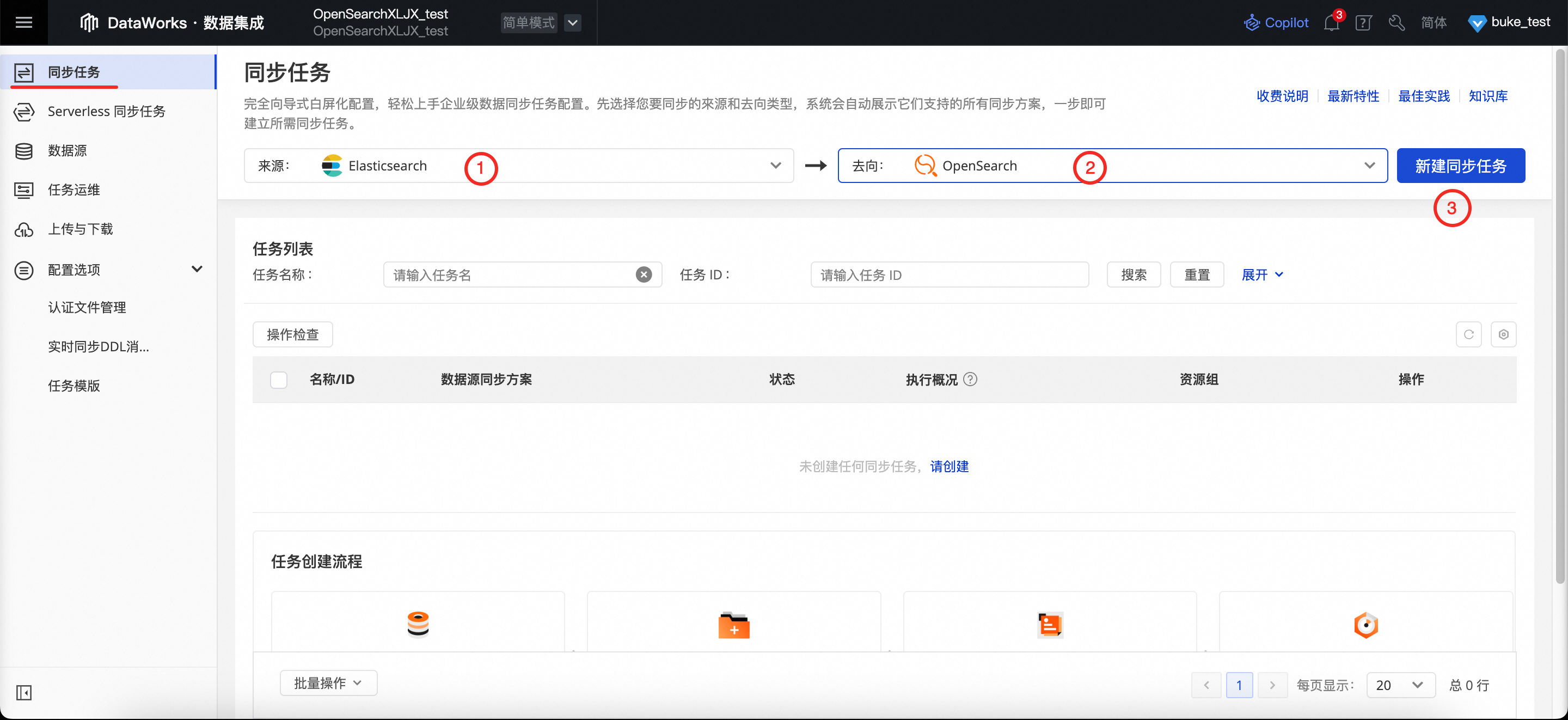
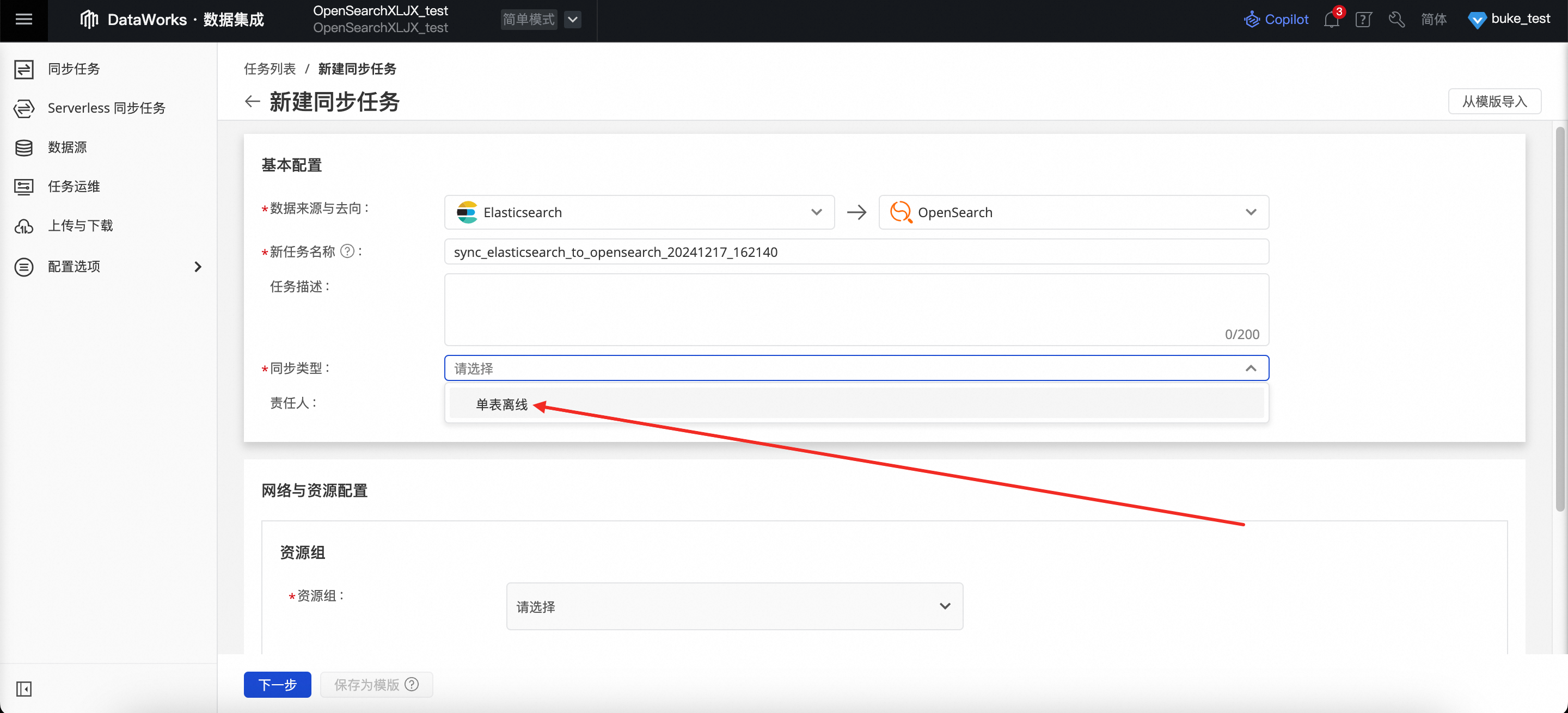
进入到新建同步任务页面,在同步类型项中选择单表离线后,就可以前往DataStudio页进行数据传输设置。
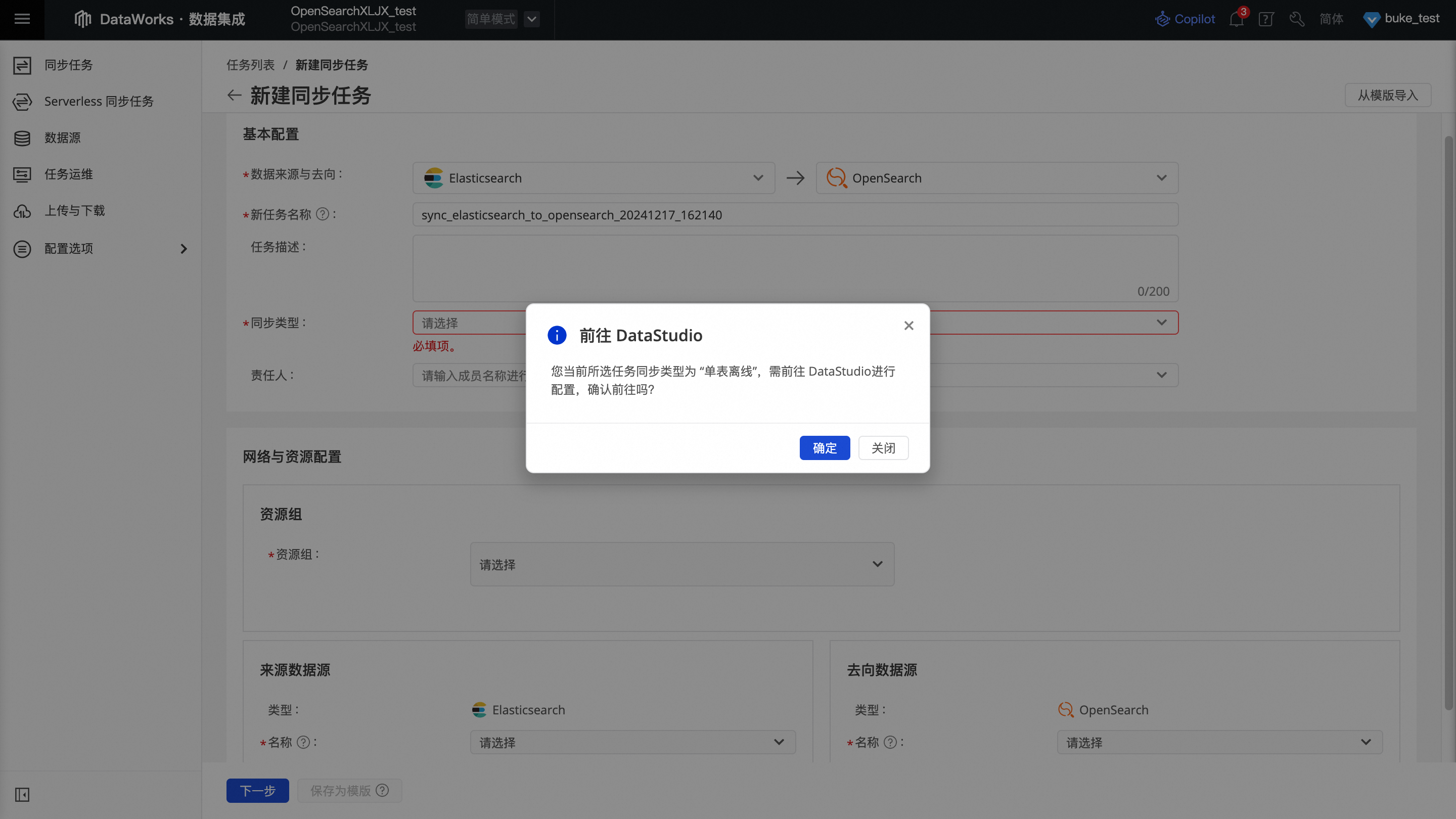
新建节点:进入到DataStudio页面后会出现新建节点的弹窗,节点类型选择离线同步,路径可以根据个人情况设置,配置完毕后点击确认。
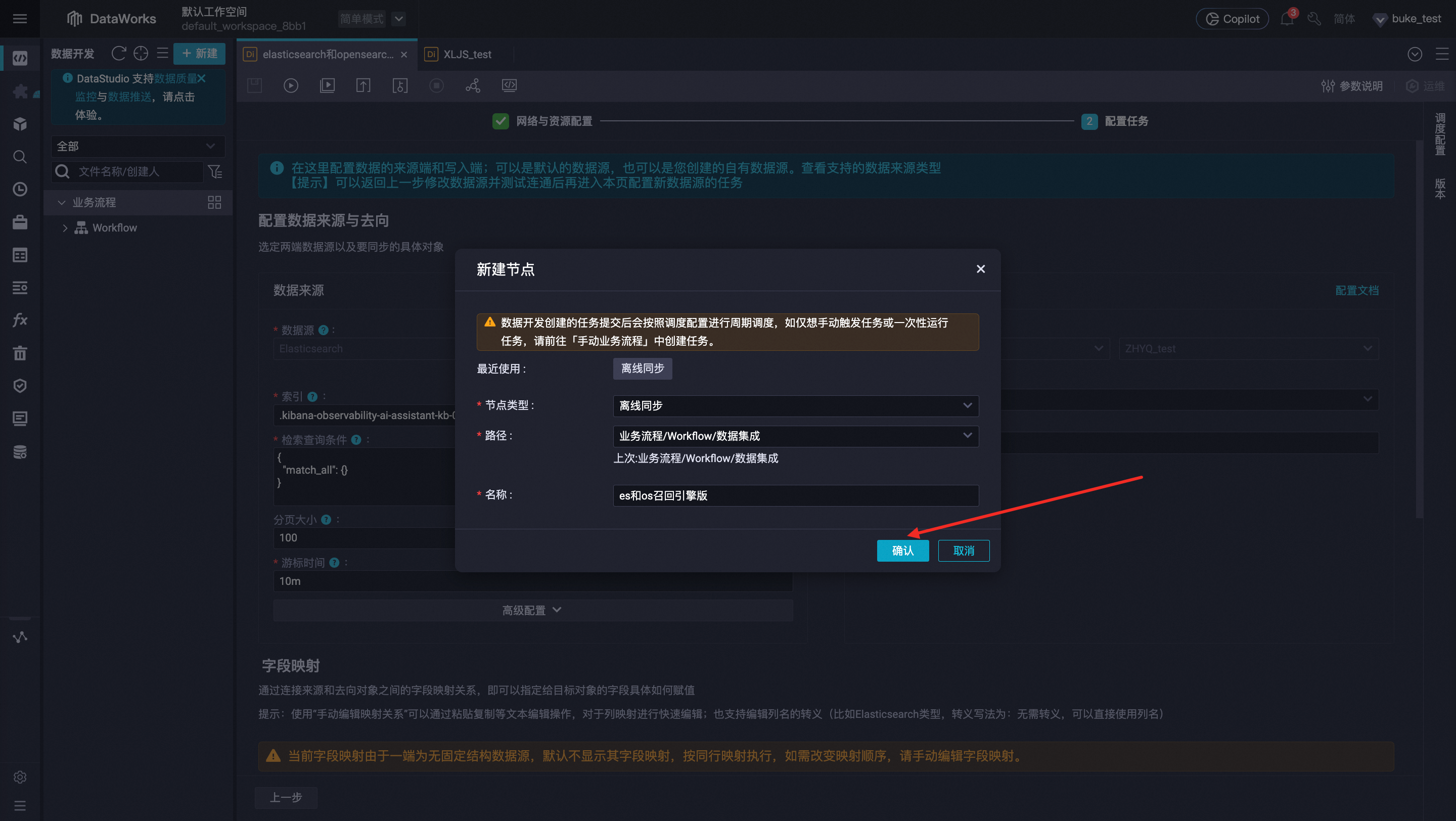
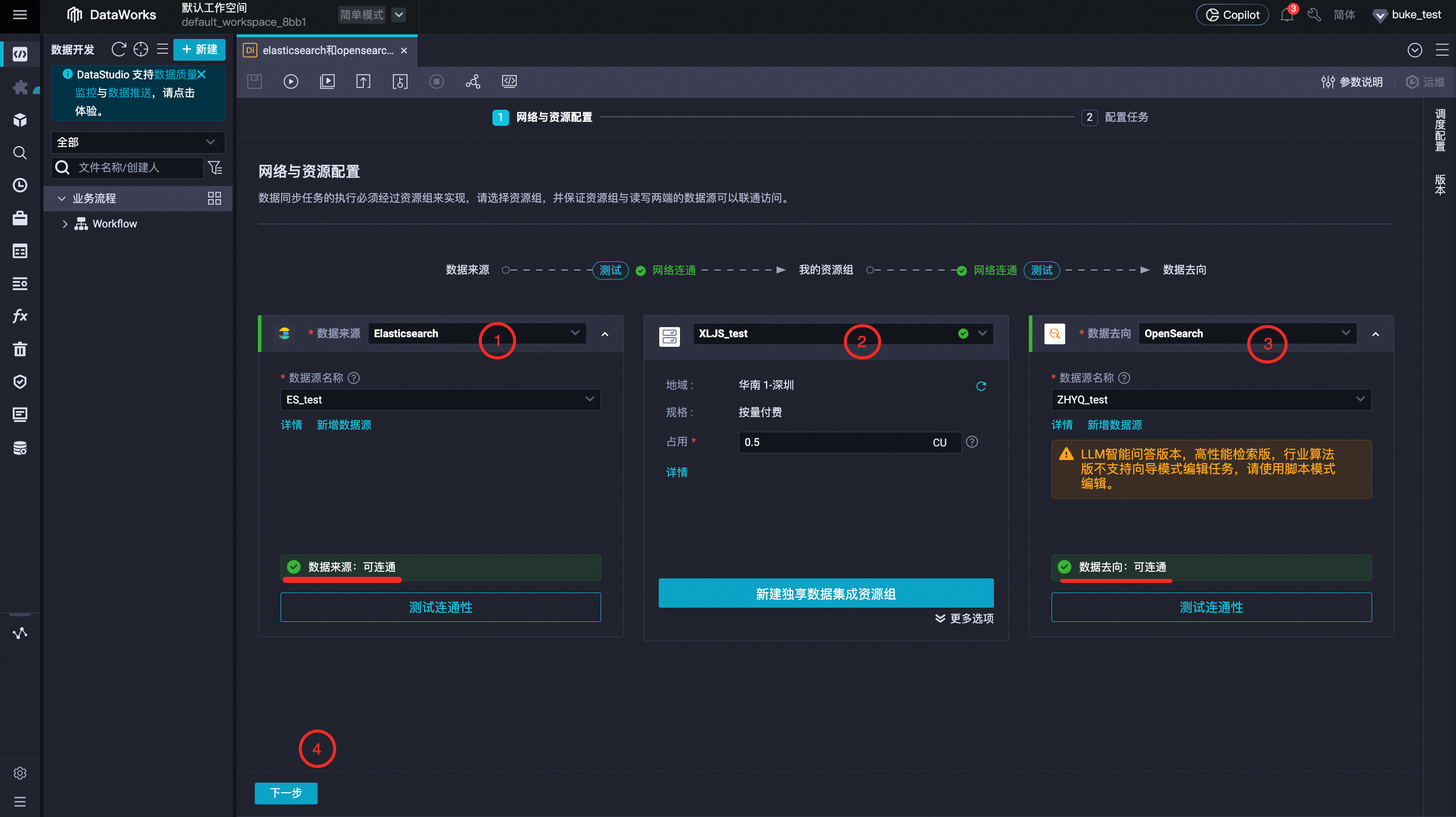
网络与资源配置:需要对数据来源、我的资源组、数据去向3部分内容进行配置,并确定数据来源和数据去向是可连通的,设置完成后点击下一步。
配置任务:需要对数据来源与去向、字段映射、通道控制3部分内容进行配置,完成后就可开启左上角的运行,进行离线数据同步。
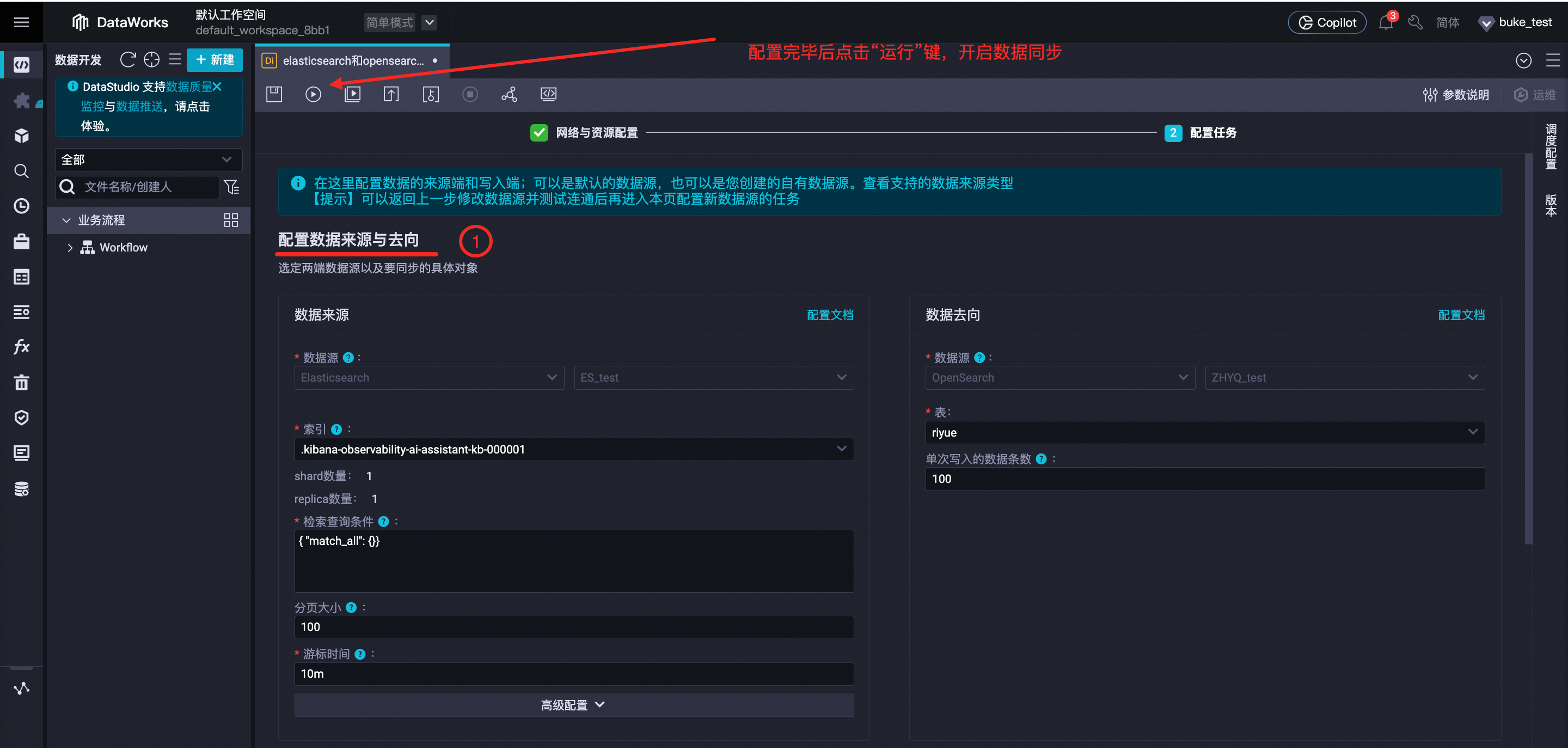
配置完数据来源和数据去向后,需要指定读取端和写入端列的映射关系,字段映射中的来源字段和目标字段需要一致,并且同行相对应,如需改变映射顺序,请手动编辑字段映射,如果字段本身在表中没有(或不支持)默认值填充,则同步会出错。配置字段映射关系后,任务将根据字段映射关系,将源端字段写入目标端对应类型的字段中。

opensearch数据同步规则:
源端数据example | OpenSearch可选类型 |
0.123 | FLOAT/DOUBLE |
123 | INT8/INT32等其他int类型 |
"0.1,0.2,0.3" | MULTI_FLOAT/MULTI_DOUBLE(多值类型,一般向量字段才这样设置) |
[0.1,0.2,0.3] | MULTI_FLOAT/MULTI_DOUBLE(多值类型,一般向量字段才这样设置) |
["abc","defg"] | STRING/MULTI_STRING(单值、多值都可以接受,具体看用户业务场景选择) |
非string数组元素如[{"a":b},{"c":d}] | STRING/TEXT/RAW等(多层object结构只支持单值推送) |
对于多值类型的数据,在DataWorks的页面上都展示为"MULTI_"前缀,例如MULTI_FLOAT。
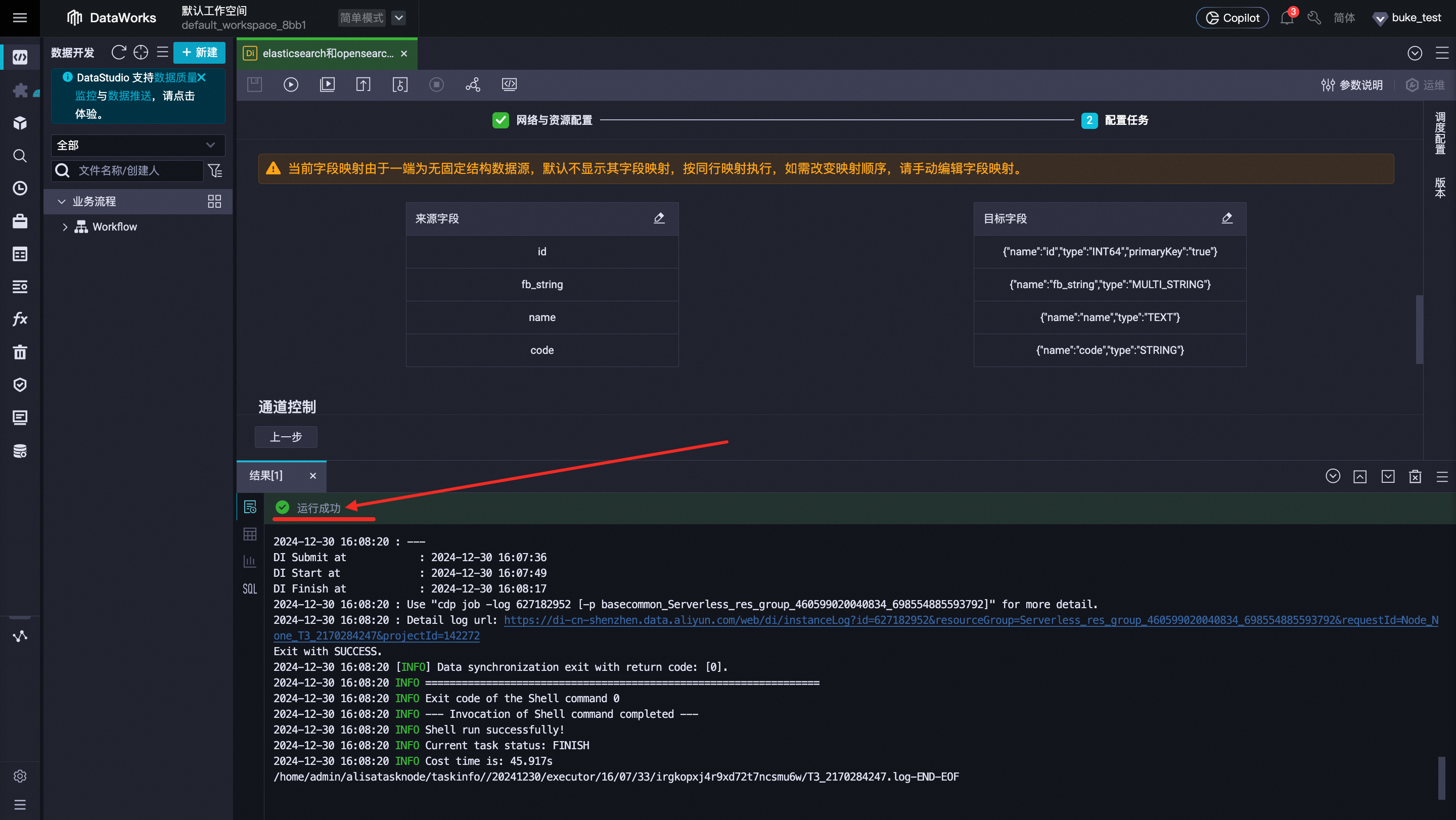
运行结果:在最下方的结果栏中可以看到运行结果是否成功。
步骤五:数据查询
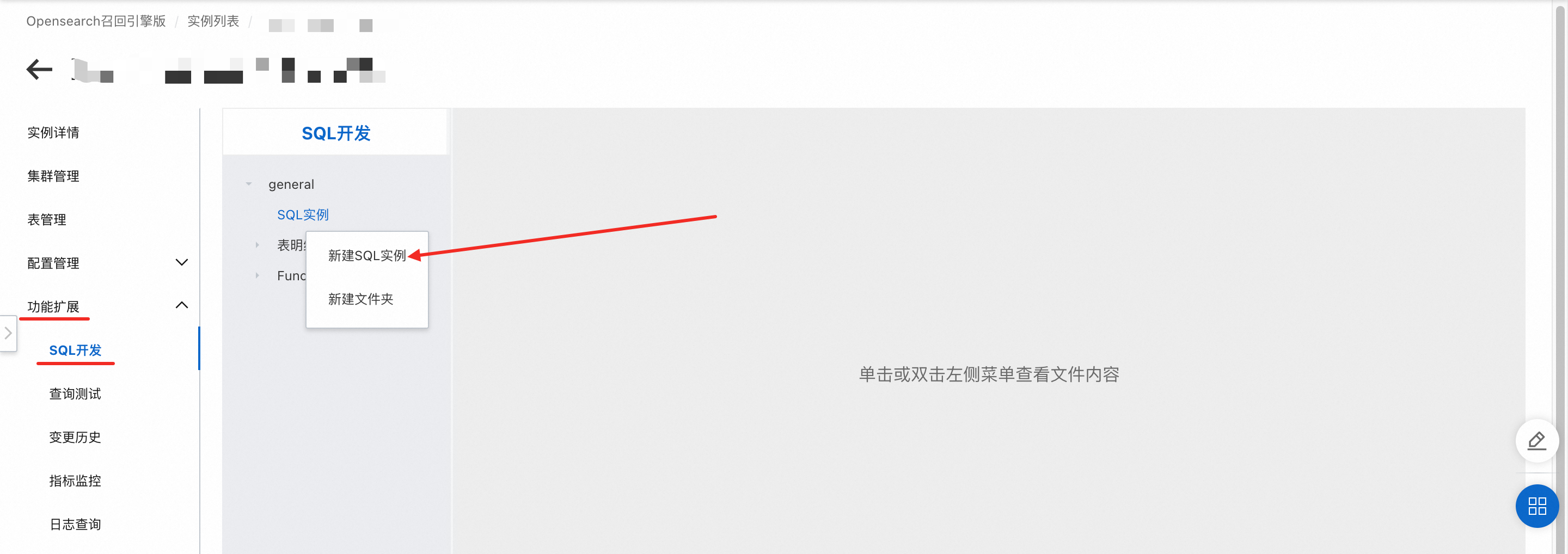
返回到OpenSearch-召回引擎版控制台,在操作栏中的管理进入实例管理界面。

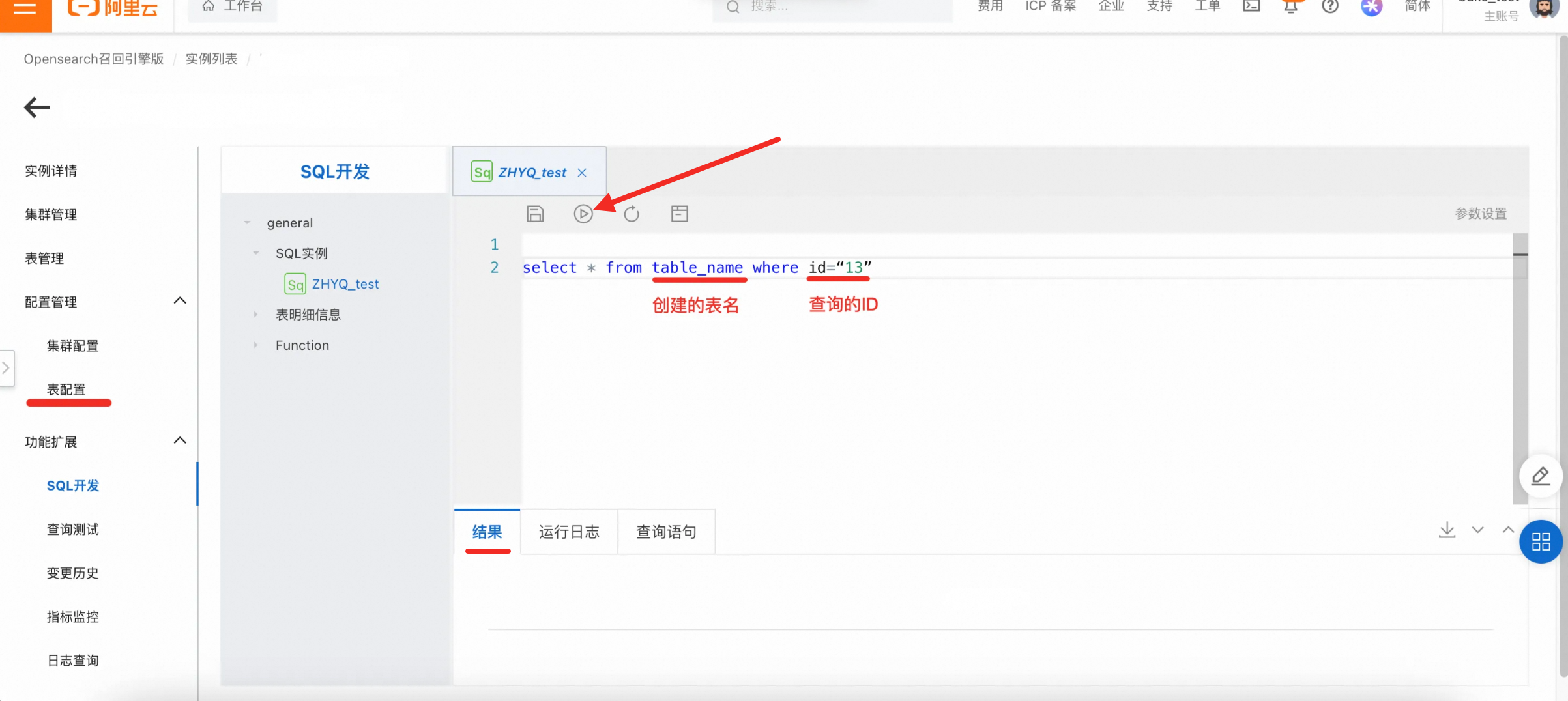
左侧导航栏找到功能扩展→SQL开发→新建SQL实例,创建SQL实例脚本。
查询数据总量:可以执行以下内容,再点击运行键,就能在结果栏里查看到统计表的所有数据条数。
select count(*) from table_name;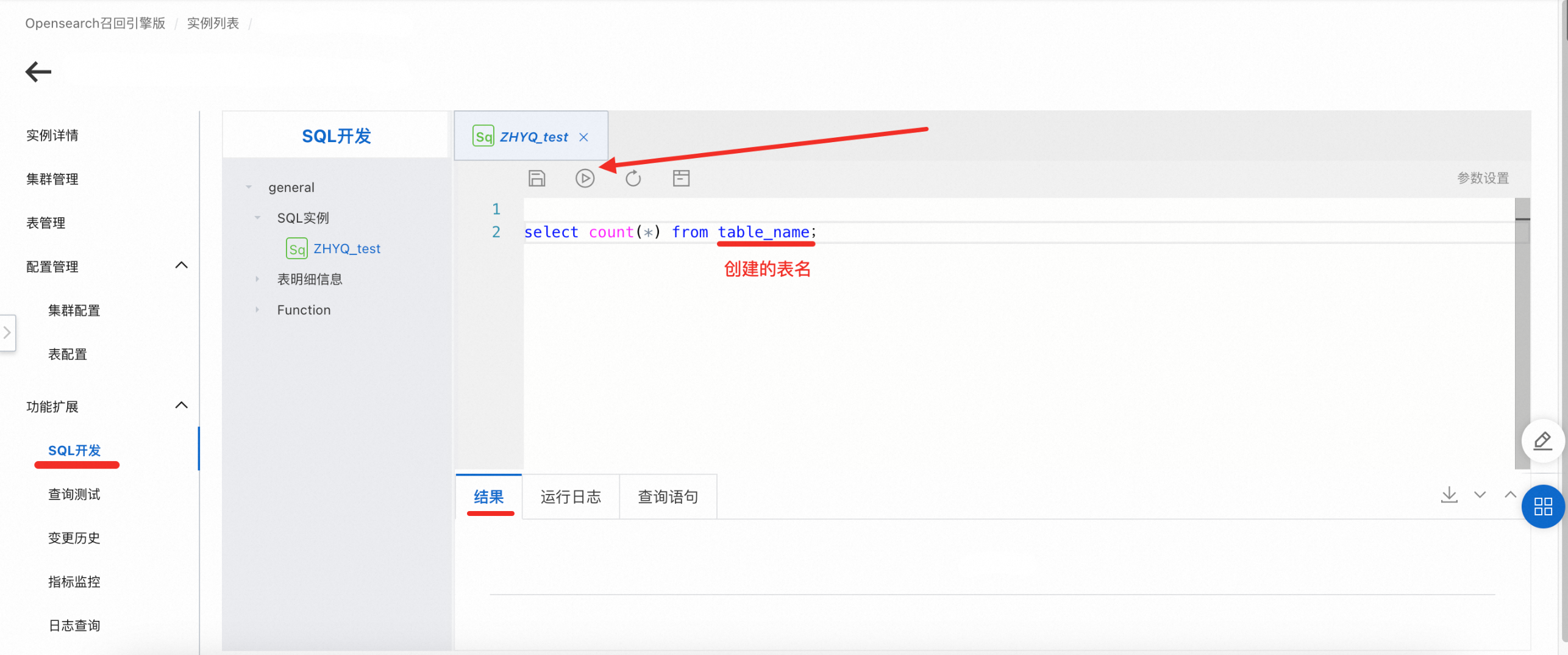
具体数据查询:可以执行以下内容,再点击运行键,就能在结果栏里查看到具体数据结果。
select * from table_name where id=“***”