什么是倒排索引
倒排索引也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。 通过倒排索引,可以快速定位单词所在的文档列表以及该词在文档中的位置,词频等信息。供信息分析使用。
倒排索引存储信息
信息名称 | 描述 |
ttf | 全称:total term frequency, 表示检索词在所有文档中出现的总次数 |
df | 全称:document frequency, 表示包含检索词的文档总数 |
tf | 全称:term frequency, 表示检索词在文档中出现的次数 |
docid | 全称:document id, 是文档在引擎中的唯一标识,可以通过docid获取到原文档的其他信息。 |
fieldmap | 全称:field map, 用于记录包含检索词的field信息(TODO: Link 什么是field??) |
section 信息 | 用户可以为某些文档分段,然后为每一段添加附属信息。该信息可以在检索时取出,供后续处理使用 |
position | 用于记录检索词在文档中的位置信息 |
positionpayload | 全称:position payload, 用户可以为文档不同位置设置payload信息,并可以在检索时取出,供后续处理用 |
docpayload | 全称:document payload, 用户可以为某些文档添加附属信息,并可以在检索时取出,供后续处理使用 |
termpayload | 全称:term payload, 用户可以为某些词添加附属信息,并可以在检索时取出,供后续处理使用 |
倒排索引的基本结构
结构名称 | 描述 |
dictionary | 词典, 存储检索词和倒排链的映射信息。引擎可以通过词典查找检索词对应的倒排信息位置 |
doclist | 全称:document list,存储包含检索词的文档信息 |
positionlist | 全称:position list,存储每一篇文档中检索词所在的位置信息 |
truncatelist | 全称:truncate list(截断链),用于提高引擎性能,根据用户的配置,将一些优质文档单独建倒排索引,以提高检索性能 |
bitmap | 用于提高引擎性能,根据用户的配置,将一些倒排结构采用bitmap方式存储,以减少倒排所占空间,提高检索性能(TODO link 什么是bitmap?) |
倒排索引检索的基本流程
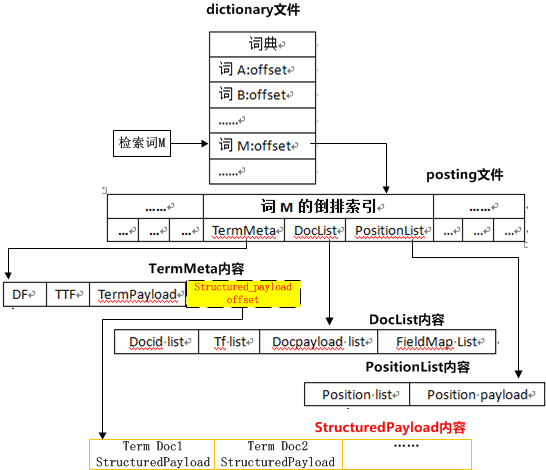
当用户查询单词M的倒排索引时,首先引擎会查询词典文件,找到索引词在倒排索引文件(posting文件)的起始位置。随后引擎通过解析倒排链,获取词M存储在倒排链的三部分信息:TermMeta,DocList, PositionList。TermMeta存储的是对索引词的基本描述,主要包括词的df、ttf、termpayload信息。DocList包含索引词的文档信息列表,文档信息包括:DocumentId,文档中的检索词频(tf), docpayload, 包含检索词的field信息(termfield)。PositionList是检索词在文档中的位置信息列表,主要包括检索词在文档中的具体位置(position)和positionpayload信息。