
EAS可将模型快速部署为在线推理服务。本文以vLLM框架部署Qwen3-0.6B模型为例,演示从部署到调用的完整流程。
本文仅以LLM模型自定义部署为例帮助您快速熟悉EAS使用。实际部署LLM模型推荐使用场景化部署的LLM大语言模型部署或者通过Model Gallery一键部署,更方便快捷。
一. 前提条件
使用主账号开通PAI并创建工作空间。登录PAI控制台,左上角选择开通区域,然后一键授权和开通产品。
二. 计费说明
本文将使用公共资源创建模型服务,计费方式为按量付费,计费规则参见EAS计费说明。
三. 准备工作
部署模型服务需要准备模型文件和代码文件(如Web接口)。如果官方镜像不满足要求,还需自行构建镜像。
3.1 模型文件准备
本文示例所需Qwen3-0.6B的模型文件,可以通过执行以下Python代码,从ModelScope下载到默认路径~/.cache/modelscope/hub。
# 模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-0.6B')3.2 代码文件准备
借助vLLM框架,我们可以非常简便地构建一个与OpenAI API兼容的API服务,故这里不需要特别准备代码文件。
如果您有复杂的业务逻辑或者特殊API需求,可以自行准备相关代码处理文件,如使用Flask创建一个简单的API接口代码如下。
3.3 上传文件到OSS
通过ossutil工具可将模型文件和代码文件上传到OSS,后续通过给服务挂载OSS来读取模型文件。
除了OSS,也可以使用其他方式存储,参见存储挂载。
也可以将部署所需文件全部打包到镜像中部署,但通常不建议这么做,原因如下:
模型的更新或迭代需要重新构建和上传镜像,增加维护成本。
大模型文件会显著增加镜像的大小,导致拉取镜像的时间变长,影响服务启动效率。
3.4 镜像准备
Qwen3-0.6B模型可以使用vllm>=0.8.5 来创建一个与 OpenAI 兼容的 API 端点。当前EAS提供的官方镜像vllm:0.11.2-mows0.5.1满足要求,故本文将直接使用官方镜像。
如不存在符合要求的官方镜像,则需要自定义镜像。如果您是在DSW开发训练模型,可以通过制作DSW实例镜像,来保障模型开发训练环境与部署运行环境的一致性。
四. 服务部署
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
在推理服务页签,单击部署服务,然后在自定义模型部署区域,单击自定义部署。
部署参数配置。关键参数如下配置,其他保持默认即可。
部署方式:镜像部署。
镜像配置:在官方镜像列表中选择
vllm:0.11.2-mows0.5.1。存储挂载:本文将模型文件存储在 OSS中,路径为
oss://examplebucket/models/Qwen/Qwen3-0___6B,故选择 OSS,配置如下。Uri:模型所在的OSS路径,配置为
oss://examplebucket/models/。挂载路径:挂载到服务实例中的目标路径,如
/mnt/data/。
运行命令:根据官方镜像关联了一个默认的运行命令,需根据实际情况进行修改。如本例中需要修改为
vllm serve /mnt/data/Qwen/Qwen3-0___6B。资源类型:选择公共资源,资源规格选择
ecs.gn7i-c16g1.4xlarge。如您想使用其他类型资源,请参见资源配置。
单击部署。服务部署时间约为5分钟,当服务状态为运行中时,表明服务已成功部署。
五. 在线调试
服务部署完成后,可以使用在线调试功能来测试服务是否正常运行。请根据具体的模型服务来配置请求方式、请求路径、请求body等。
本文部署服务的在线调试方式如下:
在推理服务页签,单击目标服务,进入服务概览页面,切换到在线调试页签。
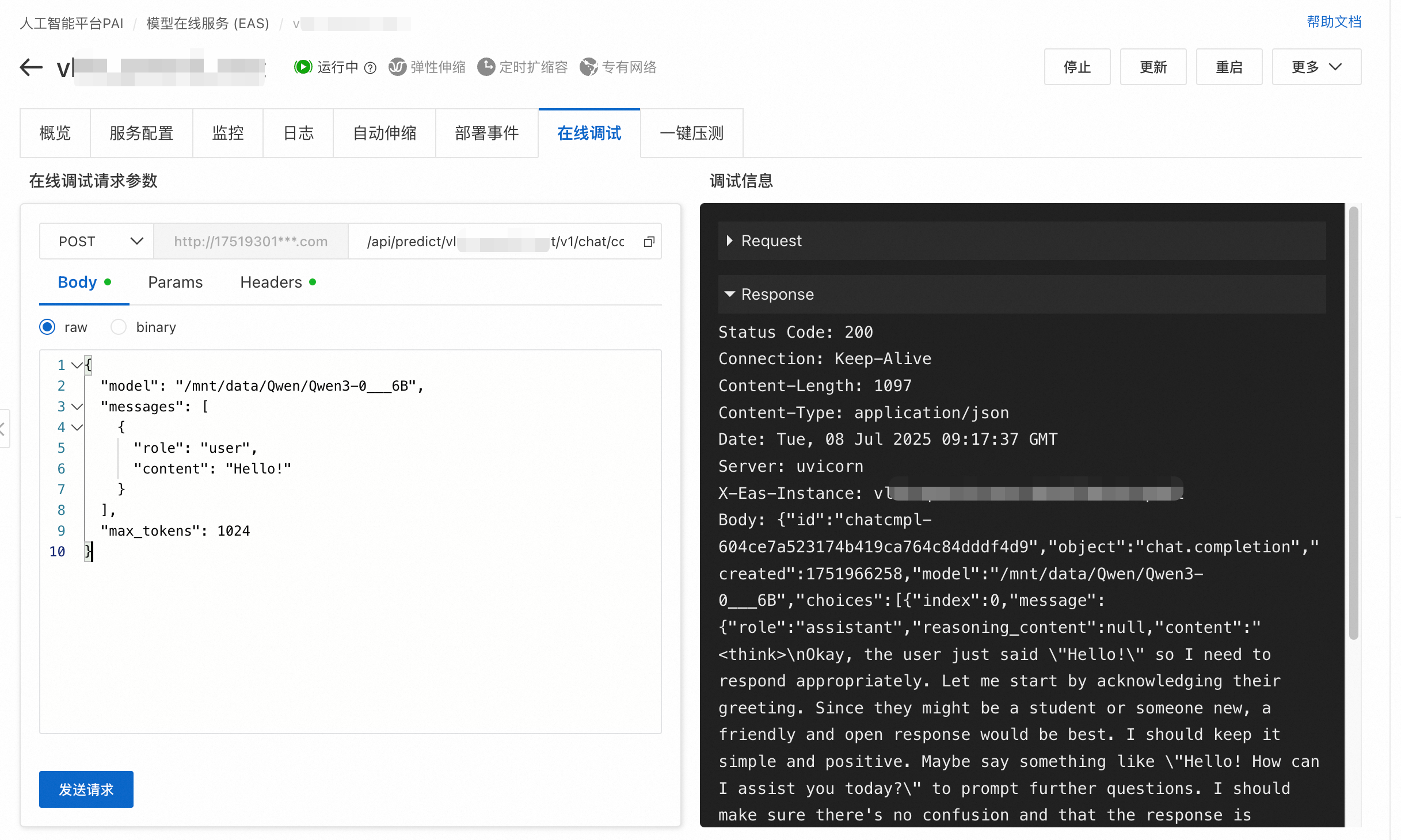
在调试页面的在线调试请求参数区域,设置请求参数,然后单击发送请求。请求参数如下:
对话接口:需在已有URL后添加
/v1/chat/completionsHeaders:添加请求头,key为
Content-Type,value为application/json。
Body:
{ "model": "/mnt/data/Qwen/Qwen3-0___6B", "messages": [ { "role": "user", "content": "Hello!" } ], "max_tokens": 1024 }
返回结果如下图所示。
六. 服务调用
6.1 获取访问地址和Token
本文部署时默认使用了共享网关。部署完成后,可以在服务概览信息中获取调用所需的访问地址和Token。
在推理服务页签,单击目标服务名称进入概览页面。
在基本信息区域,单击查看调用信息。
在调用信息面板,复制访问地址和 Token:
根据需要选择公网地址或VPC 地址。
后续示例中使用 <EAS_ENDPOINT> 表示访问地址,<EAS_TOKEN> 表示 Token。
6.2 使用curl或Python进行调用
示例代码如下:
curl http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/****/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: *********5ZTM1ZDczg5OT**********" \
-X POST \
-d '{
"model": "/mnt/data/Qwen/Qwen3-0___6B",
"messages": [
{
"role": "user",
"content": "Hello!"
}
],
"max_tokens": 1024
}' import requests
# 替换为实际访问地址
url = 'http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/***/v1/chat/completions'
# header信息 Authorization的值为实际的Token
headers = {
"Content-Type": "application/json",
"Authorization": "*********5ZTM1ZDczg5OT**********",
}
# 根据具体模型要求的数据格式构造服务请求。
data = {
"model": "/mnt/data/Qwen/Qwen3-0___6B",
"messages": [
{
"role": "user",
"content": "Hello!"
}
],
"max_tokens": 1024
}
# 发送请求
resp = requests.post(url, json=data, headers=headers)
print(resp)
print(resp.content)七. 停止或删除服务
本文使用了公共资源创建EAS服务,计费方式为按量付费。当您不需要使用服务时请停止或删除服务,以免继续扣费。
