
RAG(Retrieval-Augmented Generation,检索增强生成)技术通过从外部知识库检索相关信息,并将其与用户输入合并后传入大语言模型(LLM),从而增强模型在私有领域知识问答方面的能力。EAS提供场景化部署方式,能快速构建与部署RAG对话系统,并支持灵活选择大语言模型和向量检索库。本文为您介绍如何部署RAG对话系统服务以及如何进行模型推理验证。
本文适用于RAG版本0.3.4和0.3.5,推荐使用最新版本。
步骤一:部署RAG服务
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
在推理服务页签,单击部署服务,然后在场景化模型部署区域,单击大模型RAG对话系统部署。
在部署大模型RAG对话系统页面,配置如下关键参数:
版本选择:RAG服务支持两种部署模式,根据应用场景和资源规划进行选择。
LLM一体化部署:将RAG服务与大语言模型(如Qwen)部署在同一个EAS服务实例中。此模式配置简单,适合快速验证和原型开发。
LLM分离式部署:仅部署RAG服务,大语言模型作为独立的服务存在。此模式允许RAG服务连接到不同的LLM服务(如其他EAS部署的LLM或阿里云百炼模型服务),便于资源复用和独立扩展。适合生产环境或已有LLM服务的场景。
部署资源:为服务分配合适的计算资源。
LLM一体化部署:系统会根据所选的模型类别自动推荐资源规格。更改为更低的规格可能导致服务启动失败。
LLM分离式部署:RAG服务本身资源消耗较低。建议选择至少8核CPU和16 GB内存的规格,例如
ecs.g6.2xlarge或ecs.g6.4xlarge。
向量检索库设置:
版本类型:选择FAISS(构建本地向量库以便快速实践)。生产环境建议使用其他成熟的向量检索库,配置方式请参见使用阿里云向量数据库。
OSS地址:选择当前地域下已创建的OSS存储目录,用来存储上传的知识库文件。如果没有可选的存储路径,您可以参考控制台快速入门进行创建。
说明如果您选择使用自持微调模型部署服务,请确保所选的OSS存储路径不与自持微调模型所在的路径重复,以避免造成冲突。
专有网络:如下进行EAS访问公网或内网资源,确保RAG服务能与LLM服务、向量检索库及其他云服务正常通信。
访问公网服务:通过公网访问向量数据库、LLM服务(如阿里云百炼模型服务)以及使用联网搜索,必须为EAS服务配置公网访问能力。
访问私网服务:
通过内网地址访问向量数据库,需RAG服务与向量数据库处于同一VPC内。
通过内网地址访问LLM服务,需RAG服务与LLM服务处于同一VPC内。
说明Hologres、ElasticSearch、Milvus、RDS PostgreSQL支持通过内网或公网访问,推荐使用内网访问。
Faiss向量检索库,无需通过网络访问。OpenSearch只支持通过公网访问。
参数配置完成后,单击部署。当服务状态变为运行中时,表示服务部署成功(服务部署时长通常约为5分钟,具体时长可能因模型参数量或其他因素略有差异,请耐心等待)。
步骤二:在WebUI配置和调试服务
RAG服务部署成功后,通过WebUI界面进行功能配置和效果调试。在推理服务页签找到已部署的RAG服务,进入服务详情页,单击右上角的Web应用,进入WebUI页面。
不同镜像版本的WebUI页面不同,可在服务概览页签的环境信息区域,查看RAG服务版本号。以下步骤以pai-rag:0.3.4版本为例。
2.1 配置大语言模型
在系统设置页签的模型及存储配置页签,进行参数配置。
以模型ID的值区分不同模型配置,选择NEW即可新增模型配置。
LLM一体化部署
通常无需修改模型配置。但若选择了vLLM加速部署,模型名称需与运行命令中的设置一致。
在服务详情页的服务配置页签查看运行命令script,其中 --served-model-name 后面的值为模型名称。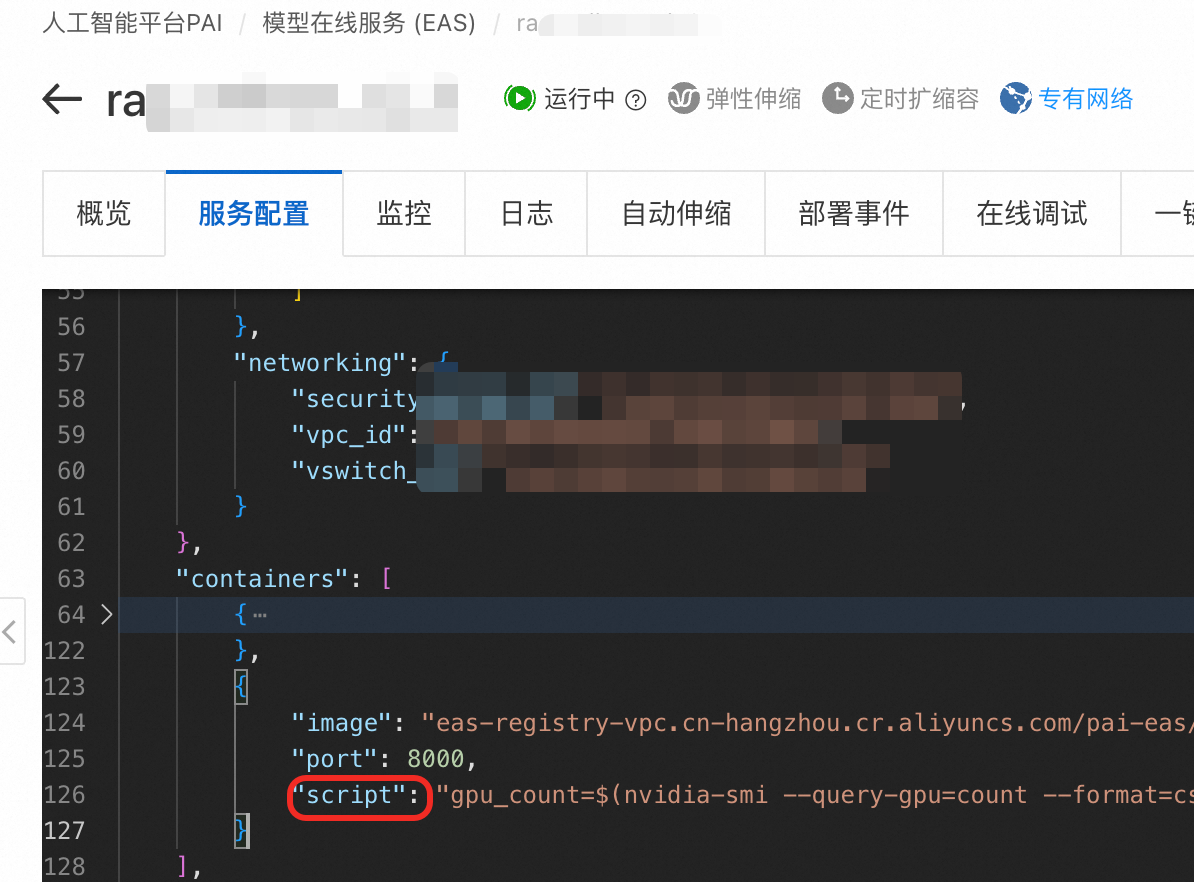
LLM分离式部署
URL、密钥:默认填充了阿里云百炼的模型服务URL,获取API Key填写即可。也可使用EAS部署的模型服务,配置为EAS服务的访问地址和Token。
说明阿里云百炼模型调用需单独计费,请参见阿里云百炼计费项说明。
公网地址连接LLM服务:需为RAG服务配置有公网访问能力的专有网络。
VPC地址连接LLM服务:RAG服务与LLM服务必须在同一个专有网络内。
模型名称:
如果是EAS部署的模型服务,且推理引擎为vLLM,请务必填写具体的模型名称(可通过
/v1/models接口获取)。推理引擎为SGLang或BladeLLM,则只需将模型名称设置为default。如果其他模型服务,请参考具体的服务调用参数说明。
2.2 管理知识库
在知识库页签下,可以创建/更新/删除知识库配置、上传文件、设置知识库问答提示词以及调试检索参数并应用到线上。
1. 知识库设置
在知识库设置Tab页,配置知识库向量模型、向量数据库等相关参数,建议直接使用默认配置。
知识库:选择NEW可新增独立的知识库。通过知识库名称实现数据的隔离使用。
说明知识库名称对应文件管理页签下的文件夹名称。文件上传到对应的文件夹下,并在对话时选择相应的知识库名称。
知识库-向量模型:仅支持huggingface来源,系统会根据选择的向量模型,自动配置向量维度等参数。
向量维度:输出向量维度。维度的设置对模型的性能有直接影响。在您选择向量模型后,系统将自动配置向量维度,无需手动操作。
向量Batch大小:批处理大小。
向量数据库配置:默认使用部署RAG服务时配置的向量数据库。也可以切换至其他向量数据库,在配置相关参数后,单击更新知识库。
重要如果部署时向量数据库参数配置错误,需在这里修改,无法通过更新服务来修改。
2. 文件管理
知识库设置完成后,可以在文件管理页签上传文件。上传知识库文件的具体操作方法,请参见RAG知识库管理。
上传后,系统会自动处理文件,将其内容向量化并存储到向量检索库。支持的文件类型为.html、.htm、.txt、.pdf、.pptx、.md、Excel(.xlsx或.xls)、.jsonl、.jpeg、.jpg、.png、.csv或Word(.docx),例如rag_chatbot_test_doc.txt。
对于除FAISS外的向量检索库,上传同名文件会覆盖旧文件。
通过API上传的文件并非永久存储,其存储期限取决于所选向量检索库(如对象存储OSS、Elasticsearch、Hologres等)的配置。建议查阅相关文档,了解存储策略以确保数据长期保存。
3. 检索测试
在检索测试页签,调整检索参数以优化问答效果。
检索模式:
向量检索:默认模式,基于语义相似性进行检索。适用于多数复杂场景。
关键字检索:基于BM25等关键词检索召回算法进行检索。在语料稀缺的垂直领域或需要精确匹配的场景中,更具优势。
混合检索:综合以上两种模式的优势,通过倒数排序融合(Reciprocal Rank Fusion, RRF)算法对文档在不同模式中的排名进行加权求和,提升整体检索的准确性和效率。
返回Top-K条文本结果:召回Top-K条最相关的文本片段。取值为0~100。
相似度分数阈值:过滤掉相似度低于此阈值的结果。
重排序类型:如选择基于模型的重排序,对第一次召回的结果进行二次排序,提升最终答案的精准度。
说明首次使用重排,模型加载可能需要较长时间。
2.3 联网搜索配置
如果使用联网搜索进行问答测试,需在应用页签的联网搜索Tab页进行联网搜索配置。参见RAG集成联网搜索搭建AI智能问答最佳实践。
2.4 对话测试
在对话页签,模拟真实用户的问答交互,验证RAG系统的效果。
对话模型ID:选择在系统设置中配置的LLM。
知识库名称:选择要查询的目标知识库。
选择工具:
大模型:直接使用LLM回答。
联网搜索:结合实时网络搜索结果进行回答(需预先配置搜索引擎)。
查询知识库:结合知识库内容回答。
查询数据库:直接从NL2SQL查询数据库中检索并返回Top K条相似结果。
输入问题,测试系统回答效果。
可开启流式输出和展示参考资料以获得更佳的调试体验。
可调整温度(0到1)控制生成内容的随机性。温度值越低,输出结果也相对固定;而温度越高,输出结果则更具多样性和创造性。
步骤三:API调用
RAG服务提供API接口(如知识库管理、对话等),便于集成到应用程序中。详情请参见RAG API接口说明。
成本与风险说明
成本构成
部署和使用本方案涉及的费用主要包括:
EAS资源的费用: RAG服务运行所占用的计算资源(vCPU、内存、GPU等)按时收费。服务停止后,此部分费用即停止。
向量检索库费用: 若使用Elasticsearch、Milvus、、Hologres、OpenSearch或RDS PostgreSQL,需支付相应产品的实例费用。
对象存储OSS费用: 用于存储原始知识库文件。
大语言模型调用费用: 若使用阿里云百炼等商业模型服务,会产生API调用费用。
公网NAT网关费用: 若EAS服务需要访问公网,会产生NAT网关的费用。
网络搜索服务费用: 若启用联网搜索功能(如Bing、阿里云通用搜索服务),会产生相应搜索服务的费用。
停止EAS服务后,仅能停止EAS资源的收费。若需停止其他产品的收费,请参考对应产品的文档指引,按照说明停止或删除相关实例。
关键风险与限制
对话长度限制: 受限于所选LLM服务的上下文窗口大小(Token限制),单次对话能处理的文本长度有限。
文件覆盖: 在使用除FAISS外的向量检索库时,上传同名文件将直接覆盖已有数据,操作前需谨慎。
API参数限制: 仅部分功能参数可通过API进行配置,其余高级配置(如多数检索调优参数)仍需通过WebUI完成。
注意事项
本实践受制于LLM服务的服务器资源大小以及默认Token数量限制,能支持的对话长度有限,旨在帮助您体验RAG对话系统的基本检索功能。
常见问题
如何使用RAG服务进行知识库数据隔离?
以部署pai-rag:0.3.4版本的RAG服务为例,当不同部门或个人使用各自独立的知识库时,可以通过以下方法实现数据的有效隔离:
在WebUI页面的知识库页签的知识库设置页签,配置以下参数,然后单击添加知识库。
知识库名称:选择NEW。
新知识库名称:自定义新的知识库名称。例如INDEX_1。
在知识库页签的文件管理Tab页上传知识库文件时,将文件上传到对应的知识库目录中即可。具体操作,请参见上传知识库文件。
在对话页签进行对话时,请选择相应的知识库名称。系统将使用目标知识库文件进行知识问答,从而实现不同知识库数据的隔离。
通过API设置的参数为什么没有生效?
目前,PAI-RAG服务仅支持通过API设置接口说明文档中列出的参数,其余参数需通过WebUI界面进行配置,详情请参见步骤二:在WebUI配置和调试服务。