
本文提供一个项目示例代码,旨在演示如何集成 ASR(自动语音识别)、LLM(大语言模型)和 TTS(语音合成)三大核心能力,构建智能语音对话系统。
准备环境和代码
请先在本地或开发服务器上完成环境准备和项目示例代码获取。
本项目要求 Python 3.10 或更高版本。
下载项目示例代码ALTDemo.zip解压后使用。文件结构如下:
ALTDemo/ ├── asset/ # 资源文件目录 │ ├── test.crt # [可选] 用于本地 HTTPS 的自签名 SSL 证书 │ ├── test.key # [可选] 用于本地 HTTPS 的自签名 SSL 密钥 │ └── test.wav # 测试音频文件 ├── api_server.py # API 服务 (基于 FastAPI) ├── config.py # 配置文件 ├── engine.py # 核心引擎 (封装 ASR/LLM/TTS 调用) ├── http_stream.py # API 调用示例脚本 ├── utils.py # 工具函数 ├── webui.py # Web UI 界面 (基于 Gradio) ├── requirements.txt # Python 依赖包列表 └── README.md # 项目说明文档安装 Python 依赖。在项目根目录下执行以下命令:
pip install -r requirements.txt
一、部署云端依赖服务 (PAI-EAS)
本系统依赖的三个核心模型服务均通过模型在线服务 (PAI-EAS) 进行部署。
1.1 部署 ASR 服务 (Paraformer)
此服务用于将用户的语音输入转换为文本。
登录PAI控制台,在左侧导航栏单击Model Gallery。
在模型广场搜索
speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch,单击模型卡片右下角的部署,使用默认配置进行部署。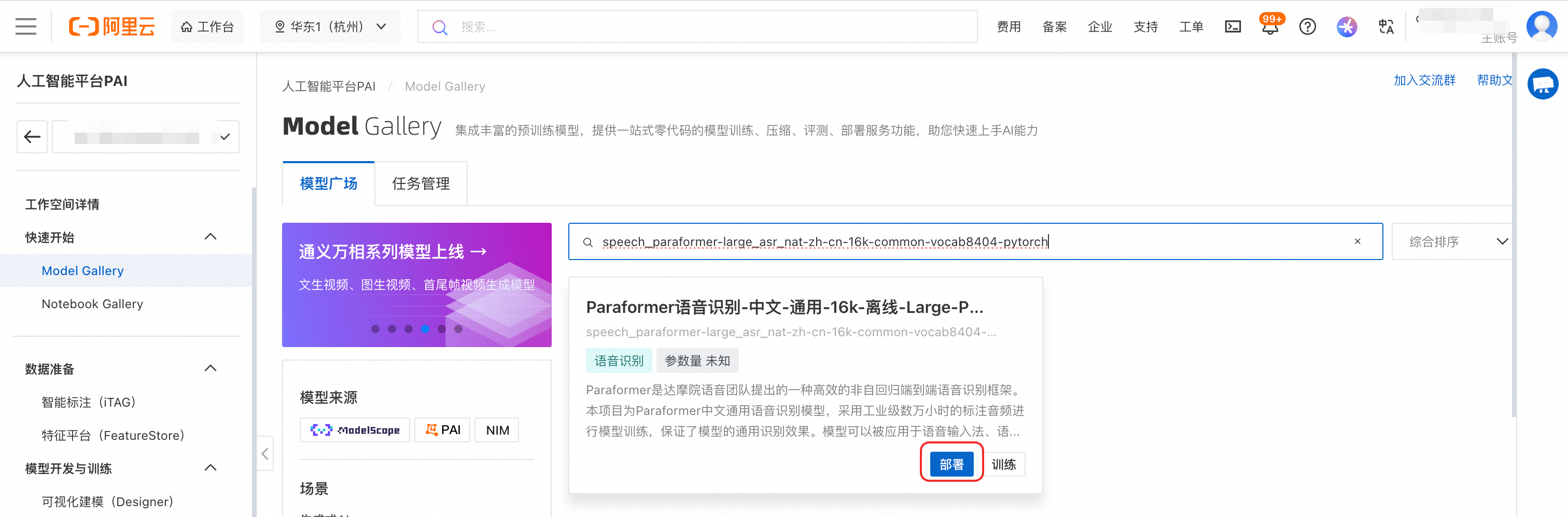
等待约10分钟,服务状态变为运行中,即部署成功。
1.2 部署 LLM 服务 (Qwen3-14B-FP8)
此服务用于理解文本并生成智能回复。
返回模型广场,搜索
Qwen3-14B-FP8,使用默认配置进行部署。等待约5分钟,服务状态变为运行中,即部署成功。
1.3 部署 TTS 服务 (CosyVoice)
此服务用于将 LLM 生成的文本合成为语音。
推荐使用EAS的场景化部署,参见快速部署Frontend/Backend分离式高性能服务。
二、配置本地项目
查看上一步部署服务的调用信息,并配置到config.py中。
2.1 查看调用信息
在推理服务页签,单击目标服务名称进入概览页面,在基本信息区域单击查看调用信息。

2.2 配置config.py
编辑 config.py 文件,配置为步骤一部署的3个服务的调用地址和Token。
# 1. ASR 服务 (语音识别)
# 格式:从 PAI-EAS 服务详情页复制的“公网调用地址”,需要以 / 结尾
ASR_BASE_URL = "http://your-asr-service.cn-hangzhou.pai-eas.aliyuncs.com/"
ASR_API_KEY = "your_asr_api_key_here"
# 2. LLM 服务 (大语言模型)
# 格式:从 PAI-EAS 服务详情页复制的“公网调用地址”,并拼接上/v1
LLM_BASE_URL = "http://your-llm-service.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/your-service-name/v1"
LLM_API_KEY = "your_llm_api_key_here"
# LLM 系统提示词,用于设定机器人的角色和回复风格
LLM_GUIDE = "你是一个聊天机器人, 跟我聊天, 但是不能超过50字"
# 3. TTS 服务 (语音合成)
# 格式:从 PAI-EAS 服务详情页复制的“公网调用地址”
TTS_BASE_URL = "http://your-tts-service.cn-hangzhou.pai-eas.aliyuncs.com"
TTS_API_KEY = "your_tts_api_key_here"
# TTS 语音合成参数
TTS_REFERENCE_AUDIO_ID = "" # 音色克隆参考音频 ID三、体验与集成
通过 Web UI 进行语音对话
启动 Web UI 服务。在项目根目录下执行以下命令:
python3 webui.py --ssl --port 7860启动参数说明:
--ssl:启用 HTTPS(需要asset/test.crt和asset/test.key证书文件)--port:指定服务端口
启动成功后,在浏览器中访问
https://localhost:7860/(若在本地运行)或https://[您的服务器公网IP]:7860/(若部署在服务器上)。说明使用自签名证书,浏览器会提示安全警告,选择继续访问即可。
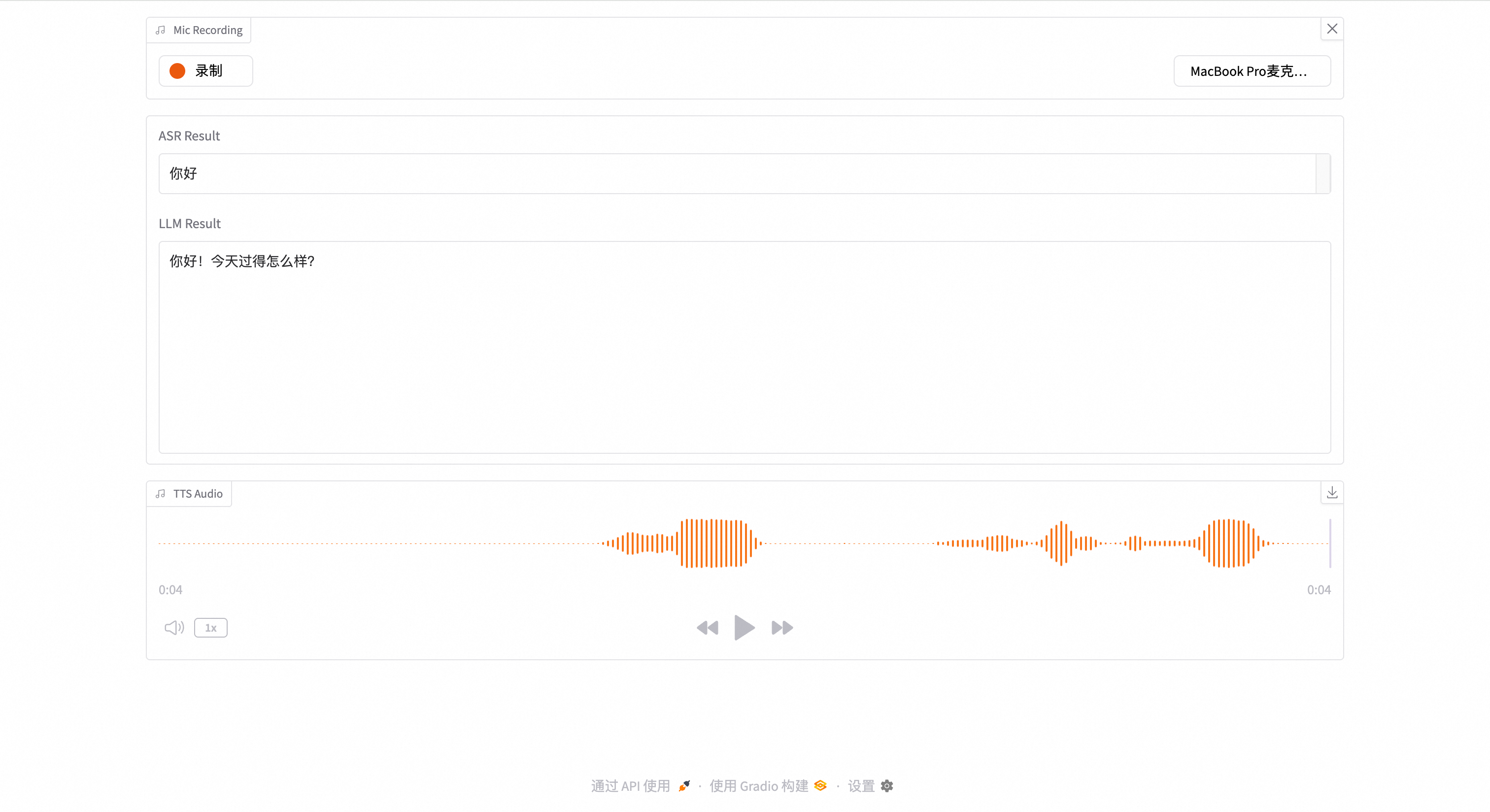
点击录制开始录音,说出您想对话的内容,然后点击停止。系统将自动完成后续流程:
语音输入文本会显示在 ASR Result 文本框中。
大模型的回复会以流式方式显示在 LLM Result 文本框中。
回复的语音将自动播放。
通过 API 集成语音能力
启动API服务。
uvicorn api_server:app --host 0.0.0.0 --port 10000调用示例:
curl
curl -XPOST http://127.0.0.1:10000/process_alt \ --form 'file=@"asset/test.wav"' \ --form "metadata={\"format\": \"mp3\", \"sample_rate\": 32000};type=application/json"Python
项目中提供了
http_stream.py示例脚本:python3 http_stream.py脚本执行后会:
将
asset/test.wav发送到 API 服务接收流式音频响应
保存为
http_stream.mp3文件
资源清理
为避免产生不必要的费用,实验结束后请务必清理所有云端服务。
登录 PAI-EAS 控制台。
找到您为本项目创建的三个服务(ASR, LLM, TTS)。
对每个服务分别执行停止或删除操作。
停止:服务将暂停,计算资源会释放,不再计费,但服务配置会保留,可以快速重启。
删除:服务将被彻底移除,无法恢复。
联系我们
如果您在使用过程中有任何问题,请通过搜索钉钉群号(161765003163)进群咨询。