
心脏病严重影响人们的生命健康,如果可以通过人体相关体测指标,分析不同特征对心脏病的影响,则可以有效预防心脏病。本工作流基于真实的心脏病患者体测数据,为您介绍如何通过数据挖掘算法构建心脏病预测模型。
前提条件
数据挖掘流程

心脏病预测
进入Designer页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应的工作空间。
在工作空间页面的左侧导航栏选择,进入Designer页面。
-
构建工作流。
-
在Designer页面,单击预置模板页签。
-
在模板列表的心脏病预测案例区域,单击创建。
-
在新建工作流对话框,配置参数(可以全部使用默认参数)。
其中:工作流数据存储配置为OSS Bucket路径,用于存储工作流运行中产出的临时数据和模型。
-
单击确定。
等待大约十秒钟,工作流即可创建成功。
-
在工作流列表,选择心脏病预测案例工作流,单击进入工作流。
-
系统根据预置的模板,自动构建工作流,如下图所示。
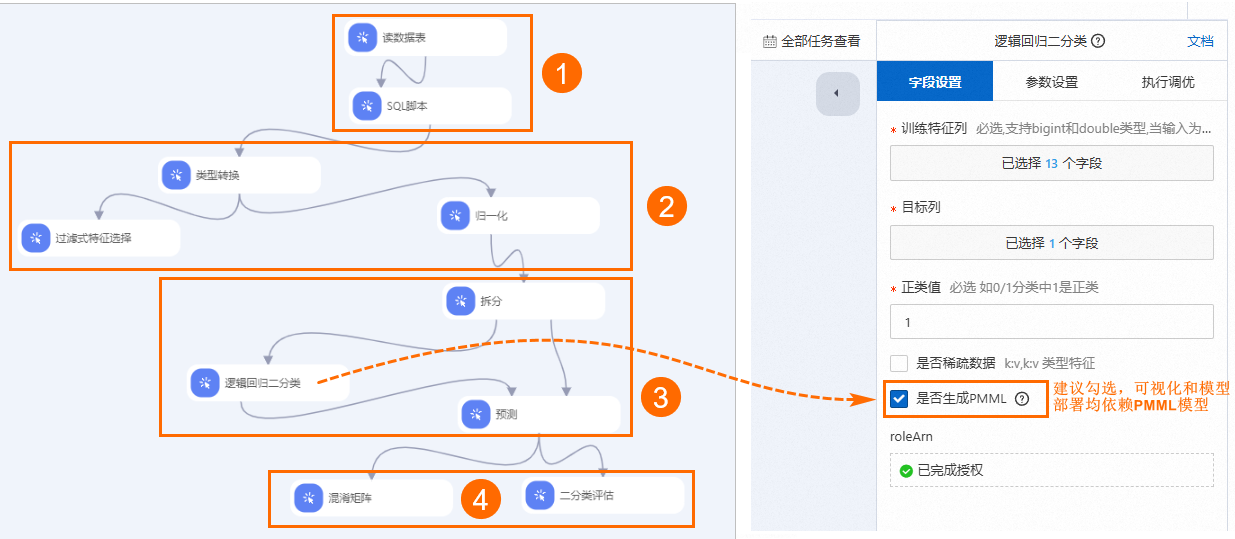
区域
描述
①
数据预处理,主要对数据进行去噪、缺失值填充及类型变换操作。因为每个样本只会患病或健康,所以心脏病预测可以归属于分类问题。本工作流的输入数据包括14个特征列和1个目标列(更多字段介绍请参见附录:心脏病数据集),在数据预处理过程中,需要根据每个字段的含义将字符类型转化为数值类型。其中:
-
二值类数据:以sex字段为例,其取值为female或male,可以使用0表示female,1表示male。
-
多值类数据:以cp字段为例,该参数表示胸部疼痛感,可以将疼痛感由轻到重依次映射为0~3的数值。
数据预处理的SQL脚本示例如下。
select age, (case sex when 'male' then 1 else 0 end) as sex, (case cp when 'angina' then 0 when 'notang' then 1 else 2 end) as cp, trestbps, chol, (case fbs when 'true' then 1 else 0 end) as fbs, (case restecg when 'norm' then 0 when 'abn' then 1 else 2 end) as restecg, thalach, (case exang when 'true' then 1 else 0 end) as exang, oldpeak, (case slop when 'up' then 0 when 'flat' then 1 else 2 end) as slop, ca, (case thal when 'norm' then 0 when 'fix' then 1 else 2 end) as thal, (case status when 'sick' then 1 else 0 end) as ifHealth from ${t1};②
特征工程主要包括特征的衍生及尺度变化等功能。本工作流首先通过类型转换组件将输入特征转换为DOUBLE类型(因为逻辑回归模型的输入数据必须为DOUBLE类型),然后使用过滤式特征选择组件判断每个特征对于结果的影响(通过信息熵和基尼系数反映其影响)。同时,使用归一化组件将每个特征的数值范围转换为0~1,从而去除量纲对结果的影响,其公式为
result=(val-min)/(max-min)。③
模型训练和预测:
-
使用拆分组件将数据集按照7:3分为训练数据集和预测数据集。
-
使用逻辑回归二分类组件训练模型。
说明如果您需要导出PMML模型文件,在该组件的字段设置页签,需要选中是否生成PMML复选框。然后单击空白画布,在该工作流页面的工作流属性页签,配置工作流数据存储路径。
-
将模型和预测数据集输入至预测组件,进行结果预测。
④
使用混淆矩阵和二分类评估组件进行模型评估。
-
-
-
运行工作流并查看输出结果。
-
单击画布上方的
 。
。 -
工作流运行结束后,右键单击画布中的逻辑回归二分类,在快捷菜单,单击,即可导出训练完成的心脏病预测模型。
-
右键单击画布中的预测,在快捷菜单,单击,即可查看模型预测结果。
-
-
查看模型效果。
-
右键单击画布中的二分类评估,在快捷菜单,单击可视化分析。
-
在二分类评估对话框,单击指标数据页签,即可查看模型评估指标数据。
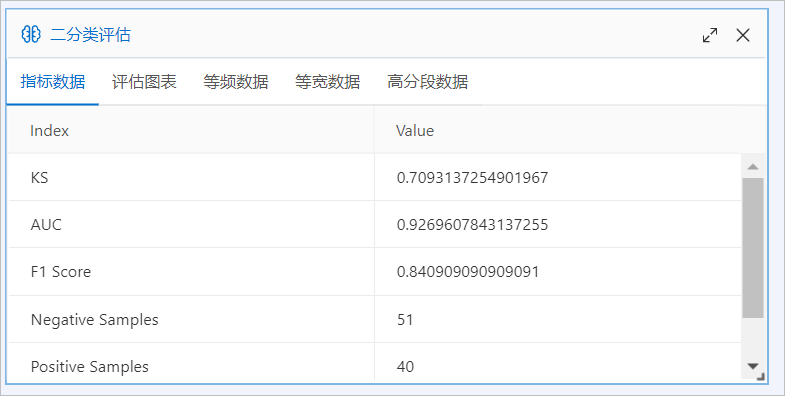 其中AUC值表示该工作流模型的预测准确率达到了90%以上。
其中AUC值表示该工作流模型的预测准确率达到了90%以上。 -
右键单击画布中的混淆矩阵,在快捷菜单,单击可视化分析。
-
在混淆矩阵对话框,单击统计信息页签,即可查看模型准确率等信息。
-
附录:心脏病数据集
本工作流使用的数据集为UCI开源数据集,包含了303条美国某区域的心脏病检查患者的体测数据,具体字段如下。
|
字段名 |
类型 |
描述 |
|
age |
STRING |
对象的年龄。 |
|
sex |
STRING |
对象的性别,取值为female或male。 |
|
cp |
STRING |
胸部疼痛类型,痛感由重到轻依次为typical、atypical、non-anginal及asymptomatic。 |
|
trestbps |
STRING |
血压。 |
|
chol |
STRING |
胆固醇。 |
|
fbs |
STRING |
空腹血糖。如果血糖含量大于120mg/dl,则取值为true,否则取值为false。 |
|
restecg |
STRING |
心电图结果是否有T波,由轻到重依次为norm和hyp。 |
|
thalach |
STRING |
最大心跳数。 |
|
exang |
STRING |
是否有心绞痛。true表示有心绞痛,false表示没有心绞痛。 |
|
oldpeak |
STRING |
运动相对于休息的ST Depression,即ST段压值。 |
|
slop |
STRING |
心电图ST Segment的倾斜度,程度取值包括down、flat及up。 |
|
ca |
STRING |
透视检查发现的血管数。 |
|
thal |
STRING |
病发种类,由轻到重依次为norm、fix及rev。 |
|
status |
STRING |
是否患病。buff表示健康,sick表示患病。 |
通过模板创建工作流已内置该数据。如需下载或获取更多关于数据集的信息,请参见Heart Disease Data Set。
后续操作
如果工作流运行结果符合预期,您可以将运行生成的模型进行部署,待部署成功后便可进行服务调用。关于部署详情,请参见单模型部署在线服务、PMML。