本文以开源项目RedPajama在GitHub中的少量数据为例,为您介绍如何使用PAI提供的LLM大语言模型数据处理组件,对GitHub代码数据进行数据清洗和处理。
前提条件
数据集
本文从开源项目RedPajama的GitHub原始数据中抽取5000个样本数据进行演示。
您可以参考数据处理流程对数据进行清洗和处理,以提高数据质量,进而提升模型的训练效果。
数据处理流程
进入Designer页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应的工作空间。
在工作空间页面的左侧导航栏选择,进入Designer页面。
构建工作流。
在Designer页面,单击预置模板页签。
在LLM大语言模型页签的LLM大语言模型数据处理 - github code区域中,单击创建。
在新建工作流对话框中,配置参数(可以全部使用默认参数),然后单击确定。
其中:工作流数据存储配置为OSS Bucket路径,用于存储工作流运行中产出的数据。
在工作流列表中,双击目标工作流,进入工作流。
系统根据预置的模板,自动构建工作流,如下图所示。
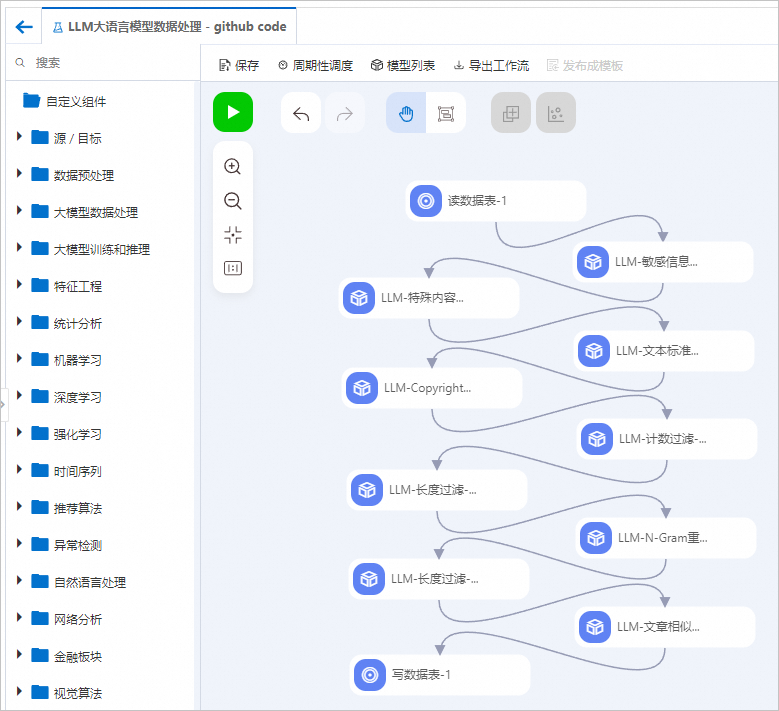
组件
描述
LLM-敏感信息打码-1
将敏感信息打码。例如:
将邮箱地址字符替换成
[EMAIL]。将手机电话号码替换成
[TELEPHONE]或[MOBILEPHONE]。将身份证号码替换成
IDNUM。
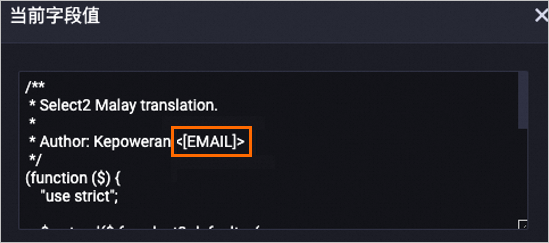
以下是对content字段经过处理后的数据示例,其中的邮箱地址已被替换成了
[EMAIL]。处理前
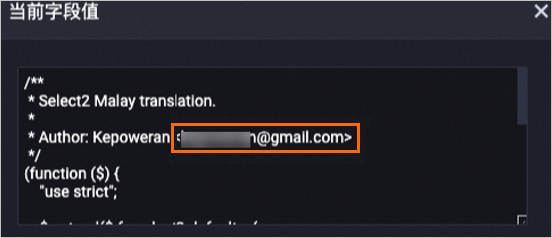
处理后
LLM-特殊内容移除-1
将content字段中的URL链接删除。
以下是对content字段经过处理后的数据示例,其中相关的URL已被删除。
处理前
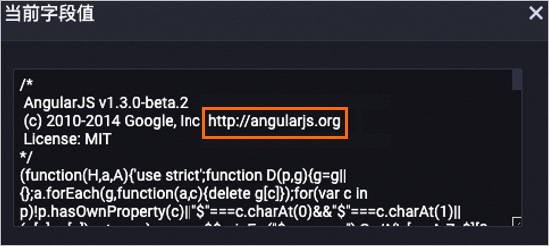
处理后
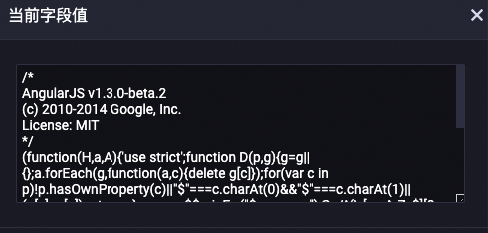
LLM-文本标准化-1
将content字段中的文本进行Unicode标准化处理。
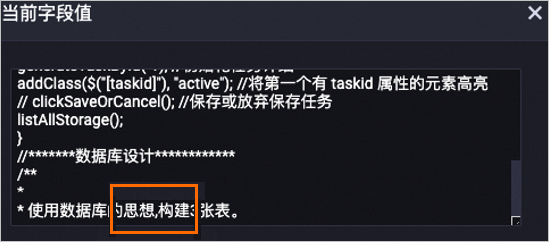
以下是对content字段经过处理后的数据示例,其中相关的文本已被标准化处理。
处理前
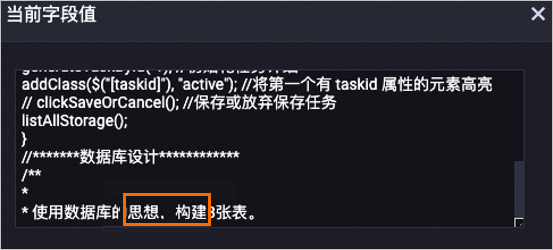
处理后
LLM-Copyrigtht信息移除-1
将content字段中的Copyright信息删除。
以下是对content字段经过处理后的数据示例,其中相关的Copyright信息已被删除。
处理前
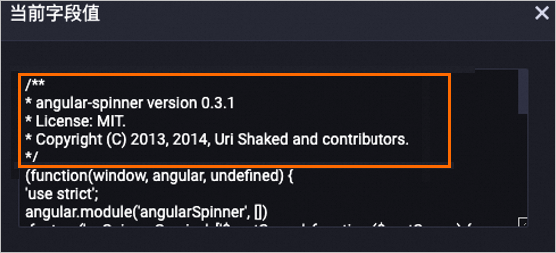
处理后
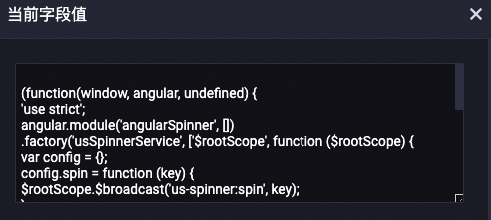
LLM-计数过滤-1
将content字段中不符合数字和字母字符占比的样本去除。GitHub代码数据集中大部分字符都由字母和数字组成,通过该组件可以去除部分脏数据。
以下是被去除的部分数据列表,可以看到很多的脏数据被去除。
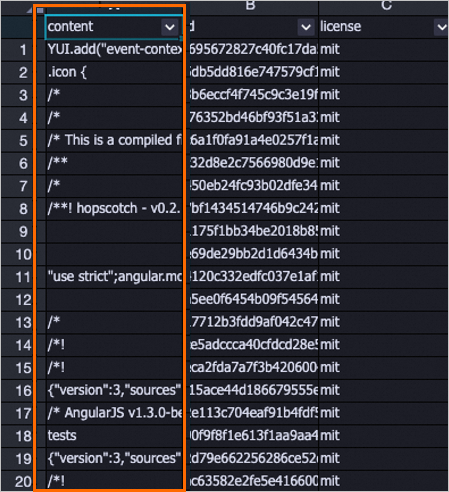
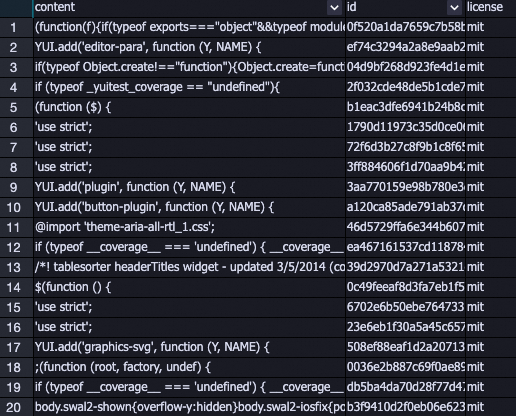
LLM-长度过滤-1
根据content字段的总长度、平均长度和最大行长度进行样本过滤。平均长度和最大行长度使用换行符("\n")分割样本。
以下是被去除的部分数据集列表,很多过短和过长的代码脏数据会被去除。
LLM-N-Gram重复比率过滤-1
根据content字段的字符级以及词语级N-Gram重复比率进行样本过滤。
将文本里的内容按照字符或词语进行大小为N的滑动窗口操作,形成了长度为N的片段序列。每一个片段称为gram,对所有gram的出现次数进行统计。最后统计
频次大于1的gram的频次总和 / 所有gram的频次总和两者比率作为重复比率进行样本过滤。说明如果是词语级统计,会先将所有单词转成小写格式再计算重复度。
LLM-长度过滤-2
使用该组件根据空格将样本切分成单词列表,根据切分后的列表长度过滤样本,实际是根据单词个数过滤样本。
LLM-文章相似度去重-1
使用该组件去除相似的文本。
单击画布上方的运行按钮
 ,运行工作流。
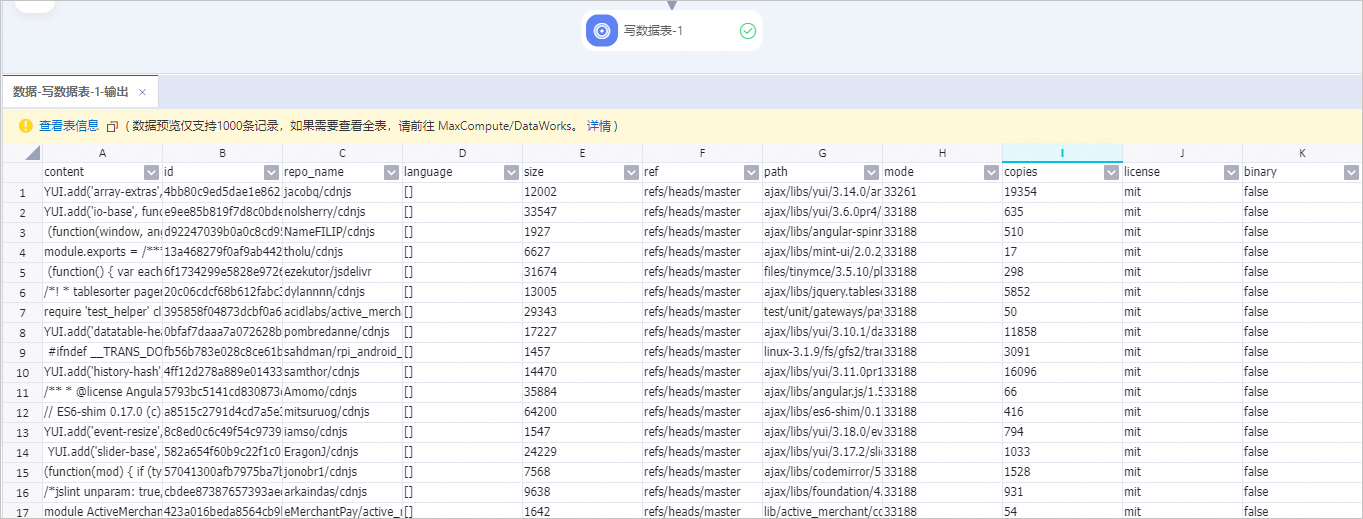
,运行工作流。工作流成功运行后,右键单击写数据表-1组件,在快捷菜单中选择。
输出的样本为经过上述所有处理组件过滤以及处理后的样本。
相关文档
在完成数据处理后,您可以使用PAI平台提供的一系列大模型组件(包括数据处理组件、训练组件以及推理组件),来实现大模型从开发到使用的端到端流程。详情请参见LLM大语言模型端到端链路:数据处理+模型训练+模型推理。