您可以使用向量检索库进行企业专属知识库的检索,并使用EAS进行AI语言大模型推理。同时,EAS还支持通过开源框架LangChain将两者有机结合,无缝集成到您的业务服务中,以获得更好的推理效果。文本为您介绍使用PAI和向量检索搭建大模型知识库对话的具体操作步骤。
背景信息
LangChain是一个开源框架,使得AI开发人员能够将像通义千问这样的大语言模型(LLM)和外部数据结合起来,从而在尽量节约计算资源的前提下,获得更好的性能和效果。通过LangChain,将输入的用户知识文件进行自然语言处理后存储在向量数据库中。每次推理时,LangChain会首先在知识库中查找与用户输入问题相近的答案,然后将这些知识库答案与用户输入一起输入到EAS的大模型服务中,以生成基于知识库的定制答案。同时,LangChain支持用户自定义Prompt,并在对话过程中提供基于LLM和向量检索的多轮对话功能。
前提条件
已开通PAI(EAS),详情请参见开通PAI并创建默认工作空间。
步骤一:准备向量检索库
您可以选择以下任意一种产品构建本地向量库:
其中,Faiss无需开通或购买即可使用,Hologres、AnalyticDB for PostgreSQL和ElasticSearch需要开通并准备相应的WebUI界面配置参数。后续您可以使用准备好的参数连接向量检索库。
Hologres
开通Hologres实例并创建数据库。具体操作,请参见购买Hologres。您需要将已创建的数据库名称保存到本地。
在实例详情页面查看调用信息。
单击实例名称,进入实例详情页面。
在网络信息区域,单击指定VPC后的复制,将域名
:80前面的内容保存到本地。
切换到账号管理Tab页,创建自定义用户。并将账号和密码保存到本地,后续用于连接Hologres实例。具体操作,请参见创建自定义用户。
其中:选择成员角色选择实例超级管理员(SuperUser)。
AnalyticDB for PostgreSQL
ElasticSearch
创建阿里云Elasticsearch实例。具体操作,请参见创建阿里云Elasticsearch实例。
其中:
选择服务选择通用商业版。
场景初始化配置选择通用场景。
您需要将在网络及系统配置向导页面配置的登录名和登录密码保存到本地。
单击实例名称,进入实例基本信息页面。在该页面获取私网地址和私网端口并保存到本地。
Faiss
使用Faiss构建本地向量库,无需购买线上向量库产品,免去了线上开通向量库产品的复杂流程,更轻量易用。
步骤二:使用EAS部署LLM大模型推理服务
进入PAI-EAS 模型在线服务页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择模型部署>模型在线服务(EAS),进入PAI-EAS 模型在线服务页面。
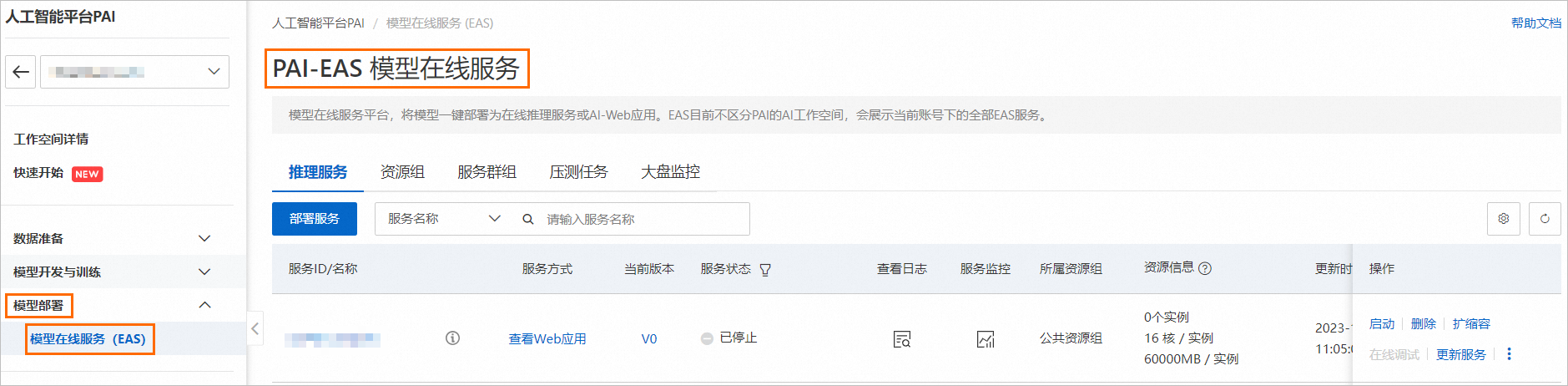
在PAI-EAS 模型在线服务页面,单击部署服务,在弹出对话框中,选择自定义部署,然后单击确定。
在部署服务页面,配置以下关键参数。
参数
描述
服务名称
自定义服务名称。
部署方式
选择镜像部署AI-Web应用。
镜像选择
在PAI平台镜像列表中选择chat-llm-webui;镜像版本选择2.0。
说明由于版本迭代迅速,部署时镜像版本选择最高版本即可。
运行命令
不同的模型类型对应的运行命令如下:
使用chatglm2-6b模型进行部署:
python webui/webui_server.py --port=8000 --model-path=THUDM/chatglm2-6b。使用通义千问-7b模型进行部署:
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-7B-Chat。使用llama2-7b模型进行部署:
python webui/webui_server.py --port=8000 --model-path=meta-llama/Llama-2-7b-chat-hf。使用Llama2-13b模型进行部署:
python webui/webui_server.py --port=8000 --model-path=meta-llama/Llama-2-13b-chat-hf --precision=fp16。
端口号配置为:8000。
资源组种类
选择公共资源组。
资源配置方法
选择常规资源配置。
资源配置选择
必须选择GPU类型,实例规格推荐使用ml.gu7i.c16m60.1-gu30(性价比最高);
若您选择使用Llama2-13b模型,实例规格推荐使用ecs.gn6e-c12g1.3xlarge。
专有网络配置
当选择Hologres、AnalyticDB for PostgreSQL或ElasticSearch作为向量检索库时,请确保所配置的专有网络与选定的向量检索库保持一致。
当选择Faiss作为向量检索库时,请随意选择一个专有网络。
单击部署,等待一段时间即可完成模型部署。
当服务状态为运行中时,表明服务部署成功。
获取VPC地址调用的服务访问地址和Token。
单击服务名称,进入服务详情页面。
在基本信息区域,单击查看调用信息。
在调用信息对话框的VPC地址调用页签,获取服务访问地址和Token,并保存到本地。
步骤三:部署LangChain服务并启动WebUI
PAI提供了最方便快捷的部署方式,您可以直接在EAS中选择指定的镜像即可部署LangChain的WebUI服务。更多关于LangChain的详细内容,请参见GitHub开源代码。
在PAI-EAS 模型在线服务页面,单击部署服务,在弹出对话框中,选择自定义部署,然后单击确定。
在部署服务页面,配置以下关键参数。
参数
描述
服务名称
自定义服务名称。本案例使用的示例值为:chatbot_langchain_vpc。
部署方式
选择镜像部署AI-Web应用。
镜像选择
在PAI平台镜像列表中选择chatbot-langchain,镜像版本选择1.0。
由于版本迭代迅速,部署时镜像版本选择最高版本即可。
运行命令
服务运行命令:
uvicorn webui:app --host 0.0.0.0 --port 8000。端口号输入:8000。
资源组种类
选择公共资源组。
资源配置方法
实例规格选择CPU>ecs.c7.4xlarge。
额外系统盘:60G。
专有网络配置
当选择Hologres、AnalyticDB for PostgreSQL或ElasticSearch作为向量检索库时,请确保所配置的专有网络与选定的向量检索库保持一致。
当选择Faiss作为向量检索库时,与LLM大模型推理服务配置的专有网络保持一致。
单击部署,等待一段时间即可完成模型部署。
当服务状态为运行中时,表明服务部署成功。
服务部署成功后,单击服务方式列下的查看Web应用,进入WebUI页面。
步骤四:使用LangChain串联业务数据进行知识问答
配置WebUI界面参数
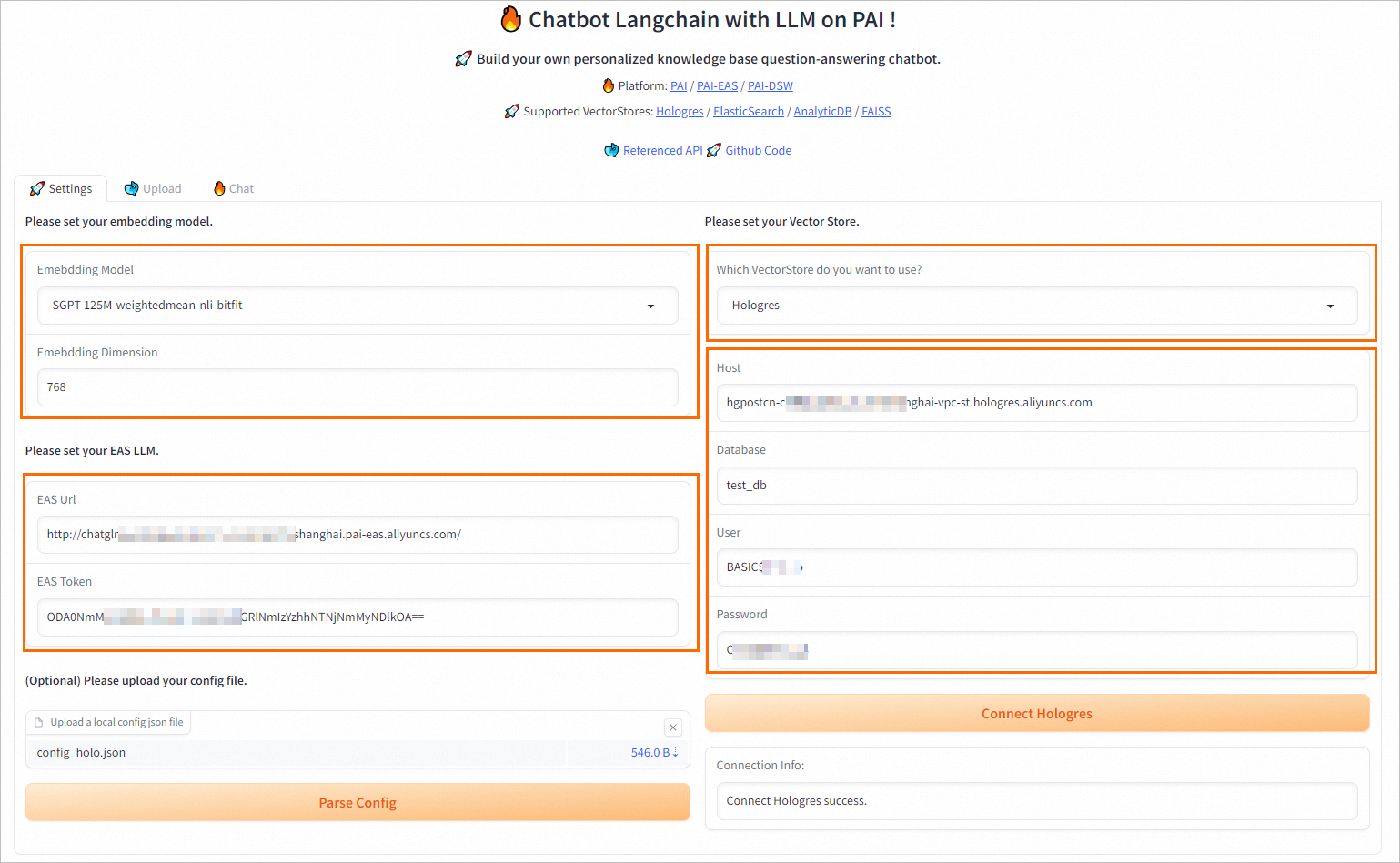
在WebUI页面的Settings选项卡中,根据选择的向量检索库配置相关参数。
Emebdding Model:支持选择4种embedding model和对应的维度(Emebdding Dimension)。推荐使用SGPT-125M-weightedmean-nli-bitfit。
Emebdding Dimension:选择Emebdding Model后,系统会自动进行配置,无需手动操作。
EAS Url:配置为步骤二中获取的服务访问地址。
EAS Token:配置为步骤二中获取的服务Token。
配置Vector Store。不同的向量检索库对应的参数配置详情如下:
Hologres
Host:配置为步骤一中查询到的Hologres调用信息。
Database:配置为步骤一中创建的数据库名称。
User:配置为步骤一中创建的自定义用户的账号。
Password:配置为步骤一中创建的自定义用户的密码。
以上参数配置完成后,单击Connect Hologres,验证Hologres实例是否连接正常。
AnalyticDB
ElasticSearch
URL:配置为步骤一中获取的私网地址和端口,格式为:
http://私网地址:端口。Index:用户自定义的索引名称。
User:配置为步骤一中创建ElasticSearch实例时配置的登录名。
Password:配置为步骤一中创建ElasticSearch实例时配置的登录密码。
以上参数配置完成后,单击Connect ElasticSearch,验证ElasticSearch实例是否连接正常。
Faiss
Path:用户自定义的数据库文件夹名称。例如faiss_path。
Index:用户自定义的索引文件夹名称。例如faiss_index。
此外,您还可以直接在WebUI页面的Settings选项卡中上传配置文件,并单击Parse config来解析配置文件。解析成功后,WebUI页面将自动根据配置文件内容填写相应的界面参数。不同的向量检索库对应的配置文件内容如下:
Hologres
{ "embedding": { "model_dir": "embedding_model/", "embedding_model": "SGPT-125M-weightedmean-nli-bitfit", "embedding_dimension": 768 }, "EASCfg": { "url": "http://xx.vpc.pai-eas.aliyuncs.com/api/predict/chatllm_demo_glm2", "token": "xxxxxxx==" }, "vector_store": "Hologres", "HOLOCfg": { "PG_HOST": "hgpostcn-cn.xxxxxx.vpc.hologres.aliyuncs.com", "PG_PORT": "80", "PG_DATABASE": "langchain", "PG_USER": "user", "PG_PASSWORD": "password" } }其中:EASCfg即为LLM大模型的服务访问地址和Token。HOLOCfg即为Hologres的相关配置。您可以参考WebUI界面参数说明进行配置。
AnalyticDB
{ "embedding": { "model_dir": "embedding_model/", "embedding_model": "SGPT-125M-weightedmean-nli-bitfit", "embedding_dimension": 768 }, "EASCfg": { "url": "http://xx.pai-eas.aliyuncs.com/api/predict/chatllm_demo_glm2", "token": "xxxxxxx==" }, "vector_store": "AnalyticDB", "ADBCfg": { "PG_HOST": "gp.xxxxx.rds.aliyuncs.com", "PG_USER": "xxxxxxx", "PG_DATABASE": "xxxxxxx", "PG_PASSWORD": "passwordxxxx" } }其中:EASCfg即为LLM大模型的服务访问地址和Token。ADBCfg即为AnalyticDB for PostgreSQL的相关配置。您可以参考WebUI界面参数说明进行配置。
ElasticSearch
{ "embedding": { "model_dir": "embedding_model/", "embedding_model": "SGPT-125M-weightedmean-nli-bitfit", "embedding_dimension": 768 }, "EASCfg": { "url": "http://xx.pai-eas.aliyuncs.com/api/predict/chatllm_demo_glm2", "token": "xxxxxxx==" }, "vector_store": "ElasticSearch", "ElasticSearchCfg": { "ES_URL": "http://es-cn-xxx.elasticsearch.aliyuncs.com:9200", "ES_USER": "elastic", "ES_PASSWORD": "password", "ES_INDEX": "test_index" } }其中:EASCfg即为LLM大模型的服务访问地址和Token。ElasticSearchCfg即为ElasticSearch的相关配置。您可以参考WebUI界面参数说明进行配置。
Faiss
{ "embedding": { "model_dir": "embedding_model/", "embedding_model": "SGPT-125M-weightedmean-nli-bitfit", "embedding_dimension": 768 }, "EASCfg": { "url": "http://xx.vpc.pai-eas.aliyuncs.com/api/predict/chatllm_demo_glm2", "token": "xxxxxxx==" }, "vector_store": "FAISS", "FAISS": { "index_path": "faiss_index", "index_name": "faiss_file" } }其中:EASCfg即为在步骤二中获取的LLM大模型的服务访问地址和Token。index_path为用户自定义的索引文件夹名称。index_name为用户自定义的数据库文件夹名称。
切换到WebUI页面的Upload选项卡中,在该页面上传用户知识库文档,并配置以下参数。
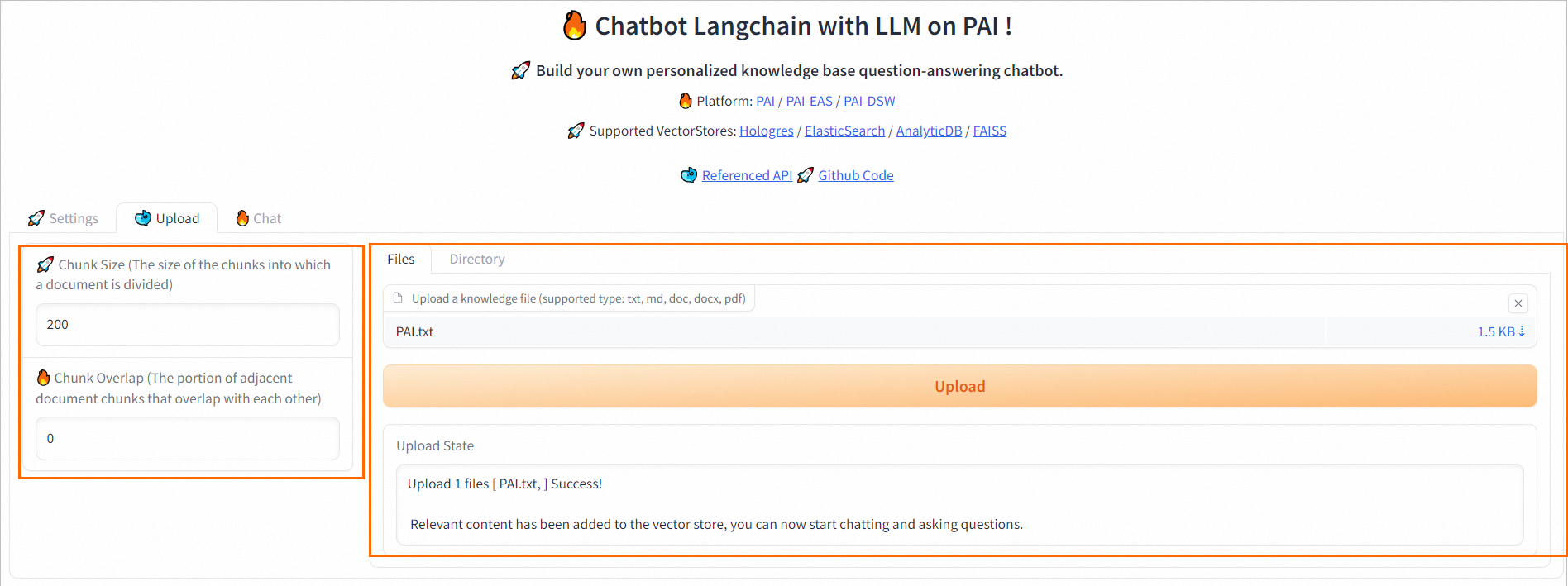
Chunk Size:指定每个分块的大小,默认200,单位为字节。
Chunk Overlap:相邻分块之间的重叠量,默认为0。
Files:参考界面操作指引上传知识库文档,然后单击Upload。支持多文件上传,文件格式为:
TXT、DOCS或PDF。Directory:参考界面操作指引上传包含知识库文档的目录,然后单击Upload。
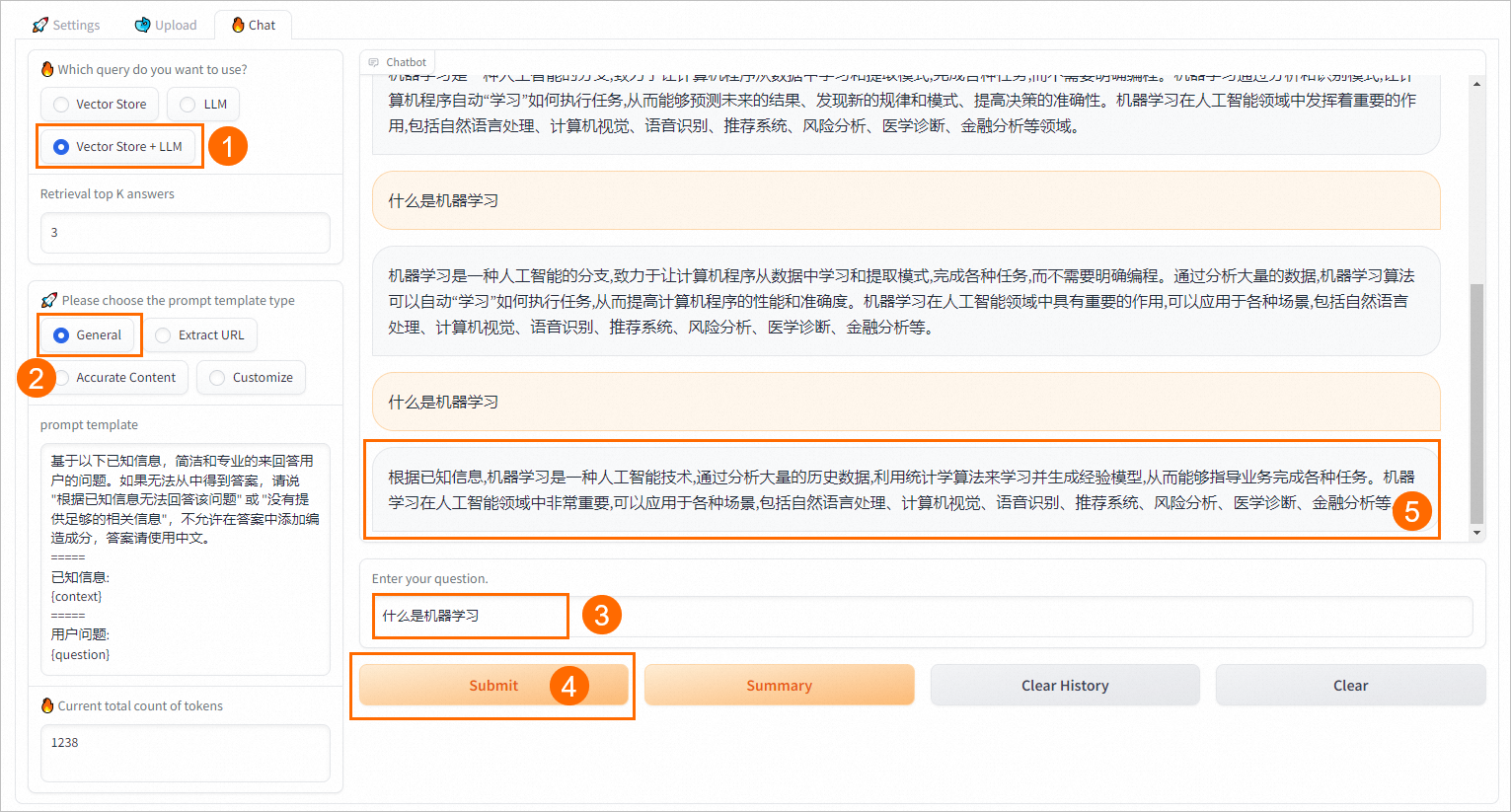
切换到WebUI页面的Chat选项卡,进行知识问答。
支持三种问答方式:
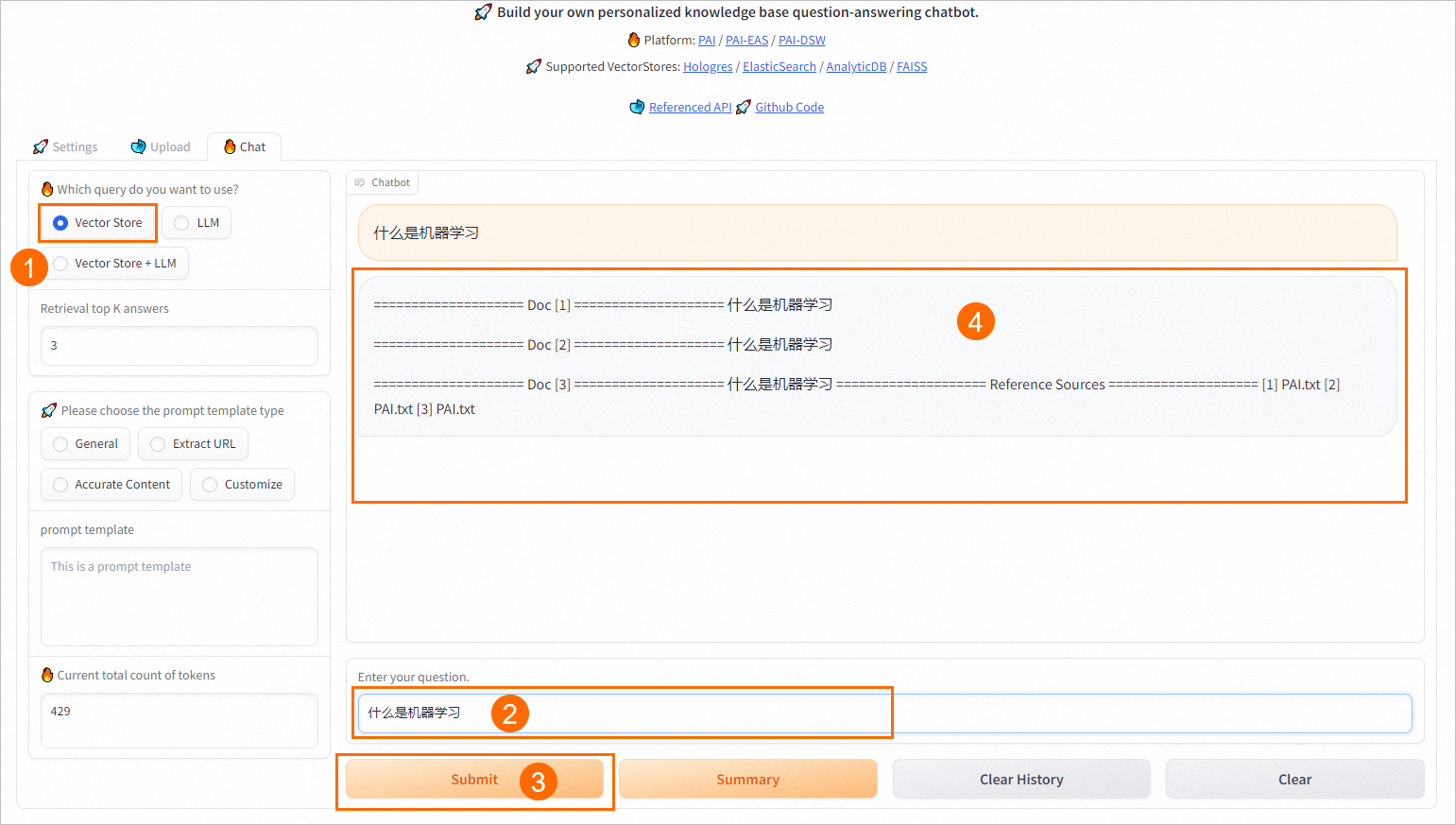
Vector Store:直接从向量数据库中检索并返回TopK条相似结果。
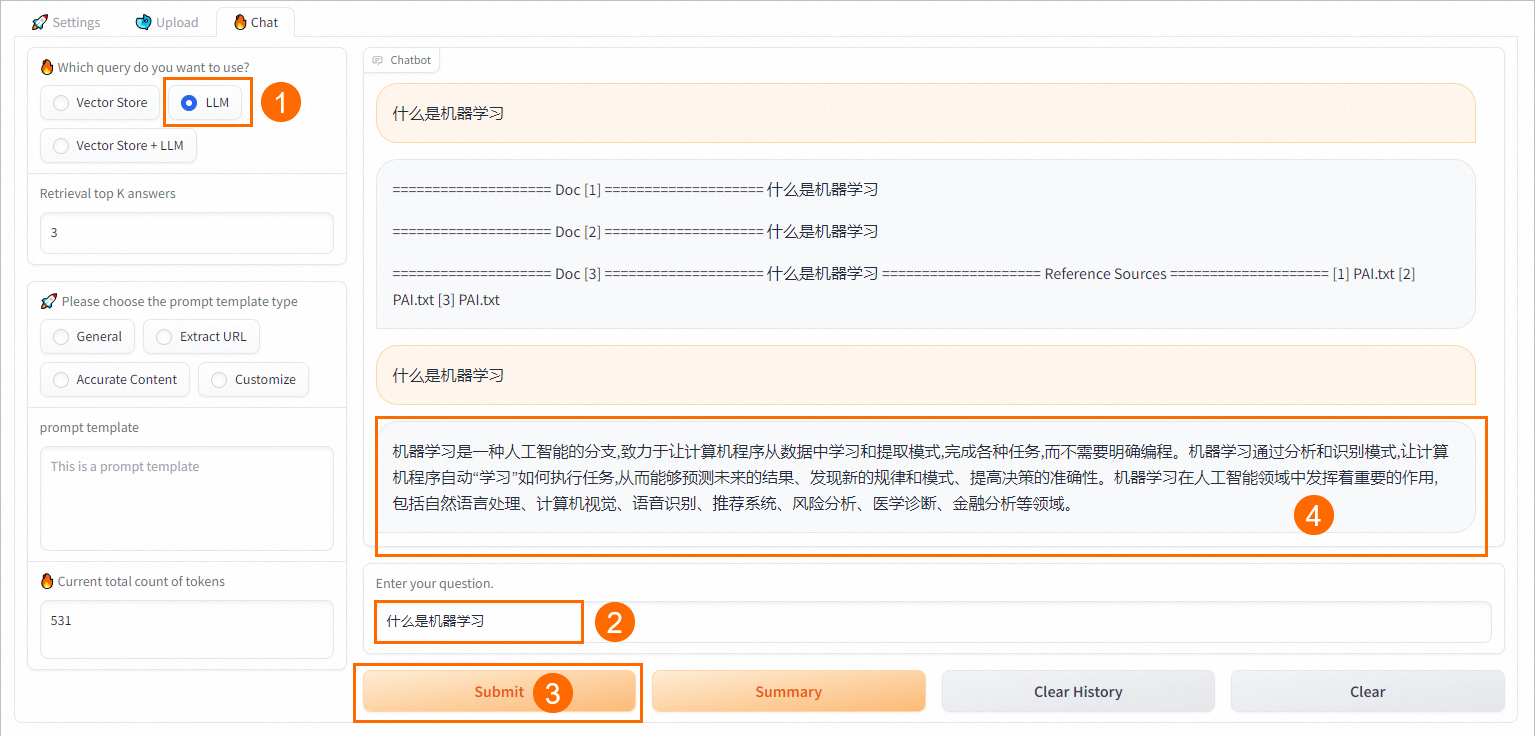
LLM:直接与EAS-LLM对话,返回大模型的回答。
Vector Store+LLM:将检索返回的结果与用户的问题组装成可自定义的Prompt,送入EAS-LLM服务,从中获取问答结果。
Retrieval top K answers:设置向量检索库返回的相似结果条数,默认为3。
Please choose the prompt template type:参考界面提示,选择合适的prompt模板。
推理效果演示
以Hologres为例,为您演示推理效果。其他几种向量检索库的使用方式与Hologres相同。
参考配置WebUI界面参数章节,在Settings选项卡中配置如下图所示的参数,并测试连接是否正常。
切换到Upload选项卡中,按照界面操作指引上传知识库文件,然后单击Upload。
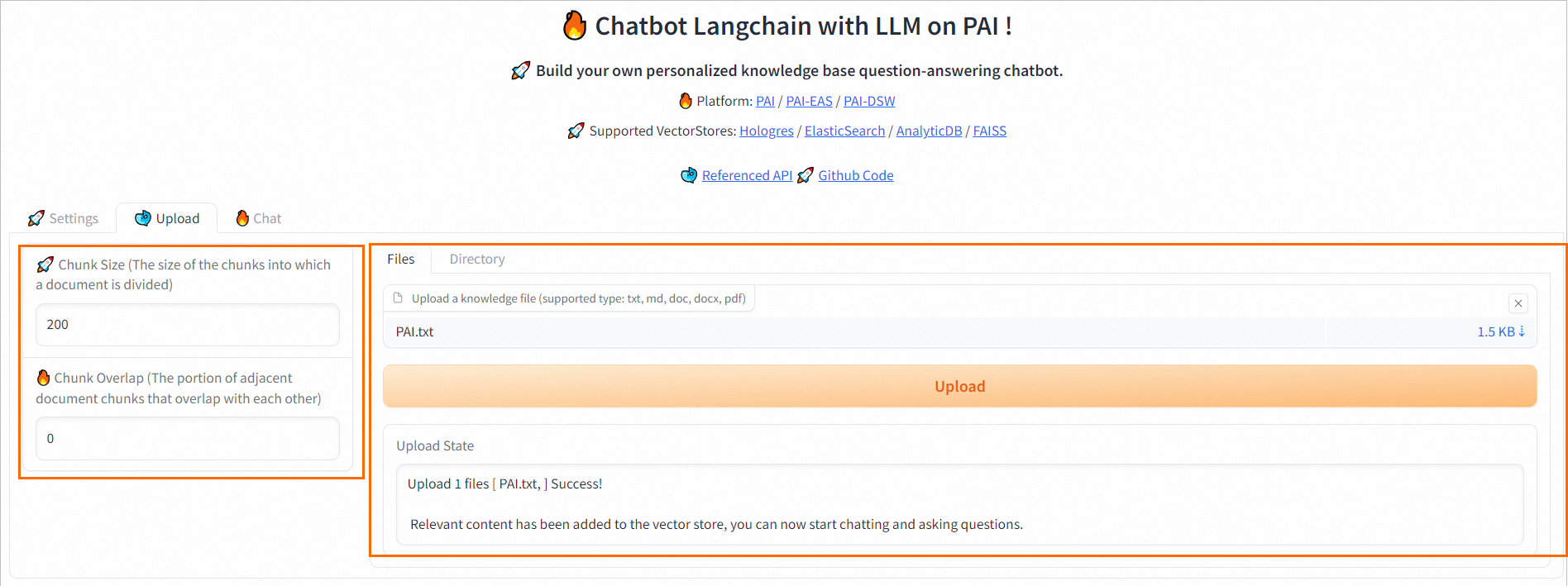
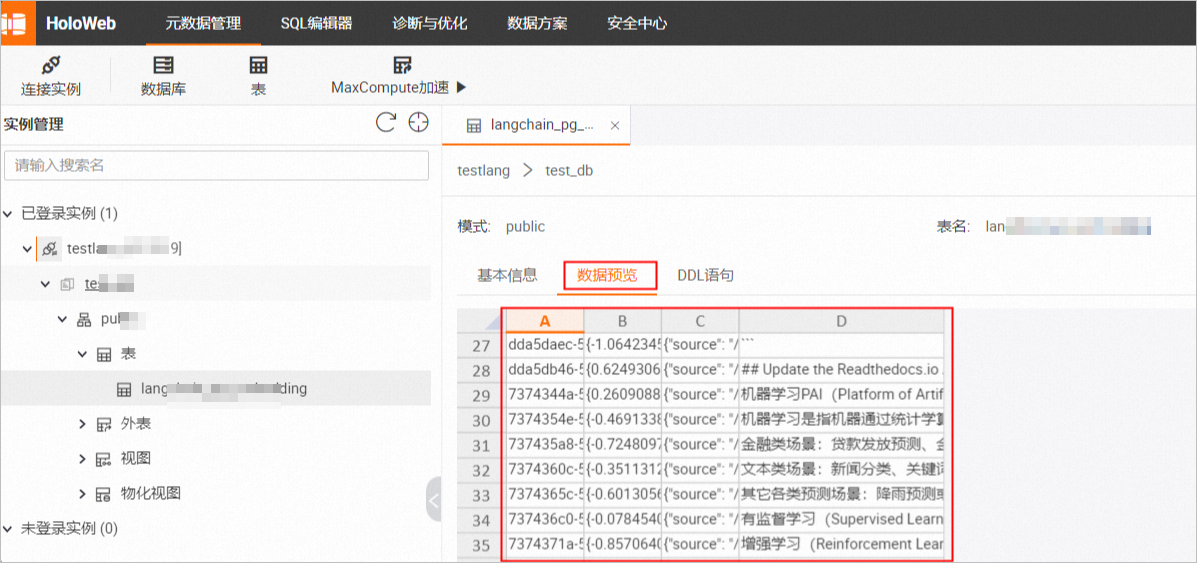
上传成功后,您可以在Hologres中查看写入的数据和向量等信息。具体操作,请参见表。
切换到Chat选项卡中,选择不同的查询方式,推理效果如下。
VectorStore
LLM
Vector Store + LLM
API调用
获取LangChain WebUI服务的调用信息。
单击步骤三部署的LangChain WebUI服务名称,进入服务详情页面。
在基本信息区域,单击查看调用信息。
在调用信息对话框的公网地址调用页签,获取服务访问地址和Token。
API调用服务。以Hologres为例来说明调用过程。
上传config_holo.json建立服务连接。
curl命令
请根据WebUI界面参数的配置准备好config_holo.json配置文件,并在config_holo.json所在的当前目录执行以下命令。
curl -X 'POST' '<service_url>config' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: multipart/form-data' -F 'file=@config_es.json'其中:<service_url>替换为步骤1获取的服务访问地址;<service_token>替换为步骤1获取的服务Token。
Python脚本
请根据WebUI界面参数的配置准备好config_holo.json配置文件,并在config_holo.json所在的当前目录执行以下脚本。
import requests EAS_URL = 'http://chatbot-langchain.xx.cn-beijing.pai-eas.aliyuncs.com' def test_post_api_config(): url = EAS_URL + '/config' headers = { 'Authorization': 'xxxxx==', } files = {'file': (open('config_es.json', 'rb'))} response = requests.post(url, headers=headers, files=files) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = response.json() return ans['response'] print(test_post_api_config())其中:EAS_URL配置为步骤1获取的服务访问地址;Authorization配置为步骤1获取的服务Token。
上传本地知识库文件。
Curl命令
准备好知识库文件,格式为
TXT、DOCS或PDF,例如PAI.txt。然后在知识库文件所在的当前目录执行以下命令。curl -X 'POST' '<service_url>uploadfile' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: multipart/form-data' -F 'file=@PAI.txt;type=text/plain'其中:<service_url>替换为步骤1获取的服务访问地址;<service_token>替换为步骤1获取的服务Token。
Python脚本
准备好知识库文件,格式为
TXT、DOCS或PDF,例如PAI.txt。然后在知识库文件所在的当前目录执行以下命令。import requests EAS_URL = 'http://chatbot-langchain.xx.cn-beijing.pai-eas.aliyuncs.com' def test_post_api_uploafile(): url = EAS_URL + '/uploadfile' headers = { 'Authorization': 'xxxxx==', } files = {'file': (open('PAI.txt', 'rb'))} response = requests.post(url, headers=headers, files=files) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = response.json() return ans['response'] print(test_post_api_uploafile()) # success其中:EAS_URL配置为步骤1获取的服务访问地址;Authorization配置为步骤1获取的服务Token。
使用
chat/vectorstore、chat/llm和chat/langchain三种问答方式进行知识问答。curl 命令
方式一:
chat/vectorstorecurl -X 'POST' '<service_url>chat/vectorstore' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是机器学习PAI?"}'方式二:
chat/llmcurl -X 'POST' '<service_url>chat/llm' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是机器学习PAI?"}'方式三:
chat/langchaincurl -X 'POST' '<service_url>chat/langchain' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是机器学习PAI?"}'其中:<service_url>替换为步骤1获取的服务访问地址;<service_token>替换为步骤1获取的服务Token。
Python脚本
import requests EAS_URL = 'http://chatbot-langchain.xx.cn-beijing.pai-eas.aliyuncs.com' def test_post_api_chat(): url = EAS_URL + '/chat/vectorstore' # url = EAS_URL + '/chat/llm' # url = EAS_URL + '/chat/langchain' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', 'Authorization': 'xxxxx==', } data = { 'question': '什么是机器学习PAI?' } response = requests.post(url, headers=headers, json=data) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = response.json() return ans['response'] print(test_post_api_chat())其中:EAS_URL配置为步骤1获取的服务访问地址;Authorization配置为步骤1获取的服务Token。
相关文档
更多关于EAS的内容介绍,请参见EAS模型服务概述。
您可以通过EAS一键部署LLM(大语言模型)应用,直接使用LangChain框架来集成企业知识库,详情请参见5分钟操作EAS一键部署通义千问模型。
- 本页导读 (1)