在RAG(检索增强生成)架构中,知识库作为外部私有数据源,为大语言模型(LLM)提供上下文,其数据质量直接决定生成结果的准确性。知识库仅需一次创建,即可在多个应用流中复用,极大提升开发效率。此外,知识库还支持手动更新和定时调度更新,从而确保知识库的实时性和准确性。
工作原理
当用户创建知识库并更新索引后,系统会启动一个工作流,通过PAI-DLC任务来处理OSS数据源中的文件,该流程包含三个核心步骤:
预处理与分块:系统自动读取用户在OSS中指定的源文件,并将其预处理、切分成适合检索的文本块(结构化数据按行分块,图片不分块)。
向量化(Embedding):通过调用Embedding模型,将每个文本块或图片转换为能够表达其语义的数字向量。
入库与索引:将生成的向量数据存入向量数据库,并创建索引,以便于后续的高效检索。
核心流程:从创建到使用
步骤一:创建知识库
进入LangStudio,选择工作空间后,在知识库页签下单击新建知识库,根据如下说明完成参数配置。
基础配置
参数 | 描述 |
知识库名称 | 自定义知识库名称。 |
数据源OSS路径 | 知识库数据所在的OSS目录。 |
输出OSS路径 | 保存文档解析生成的中间结果和索引信息,最终输出内容与所选向量数据库类型相关。 重要 若运行时设置的实例RAM角色为PAI默认角色,建议将此参数配置为当前工作空间默认存储路径所在的OSS Bucket下的任一目录。 |
知识库类型 | 根据文件类型选择,不同类型知识库支持的文件格式如下:
|
特定类型配置
文档解析分块配置(文档类型知识库需配置)
文本分块大小:设置每个文本块的最大字符数,默认为 1024(字符)。
文本分块重叠大小:为确保检索信息连贯性,设置相邻文本块重叠的字符数,默认为200(字符)。通常建议重叠大小为分块大小的10%~20%。
说明关于如何合理设置分块参数,请参见分块参数调优。
字段配置(结构化数据类型知识库需配置):直接上传文件(如animal.csv)或手动添加字段,可以分别指定参与索引和召回的数据字段。
Embedding模型和数据库
在这里,需要为知识库选择一个 Embedding 模型服务和一个向量数据库。如果下拉框中没有想要的选项,可以参考连接配置进行创建。
知识库类型 | 支持的Embedding类型 | 支持的向量数据库类型 |
文档 |
|
|
结构化数据 | ||
图片 |
|
|
向量数据库选择建议:
生产环境:建议使用Milvus和Elasticsearch,支持处理大规模的向量数据。
测试环境:建议使用FAISS,无需额外创建数据库(知识库文件及生成的索引文件将存放于输出OSS路径中)。适合功能测试或处理小规模文件,文件量过大时会显著影响检索和处理性能。
运行时
选择一个运行时,用于执行文档分块预览、召回测试(即检索效果测试)等操作(需访问向量数据库和Embedding服务)。
请注意运行时的设置:
若通过内网地址访问向量数据库或 Embedding 服务,请确保运行时的 VPC 网络与它们保持一致或可互通。
若实例RAM角色选择自定义角色,请务必为该角色授予 OSS 访问权限(建议授予AliyunOSSFullAccess权限),详情请参见为RAM角色授权。
如果您的运行时版本过旧(低于 2.1.4),可能无法在下拉框中选择。请重新创建一个运行时即可。
步骤二:上传文件
方式一:直接将文件上传到知识库设置的数据源OSS路径。
方式二:在知识库页签,单击目标知识库名称进入详情页面,在文档/图片页签上传文件/图片。
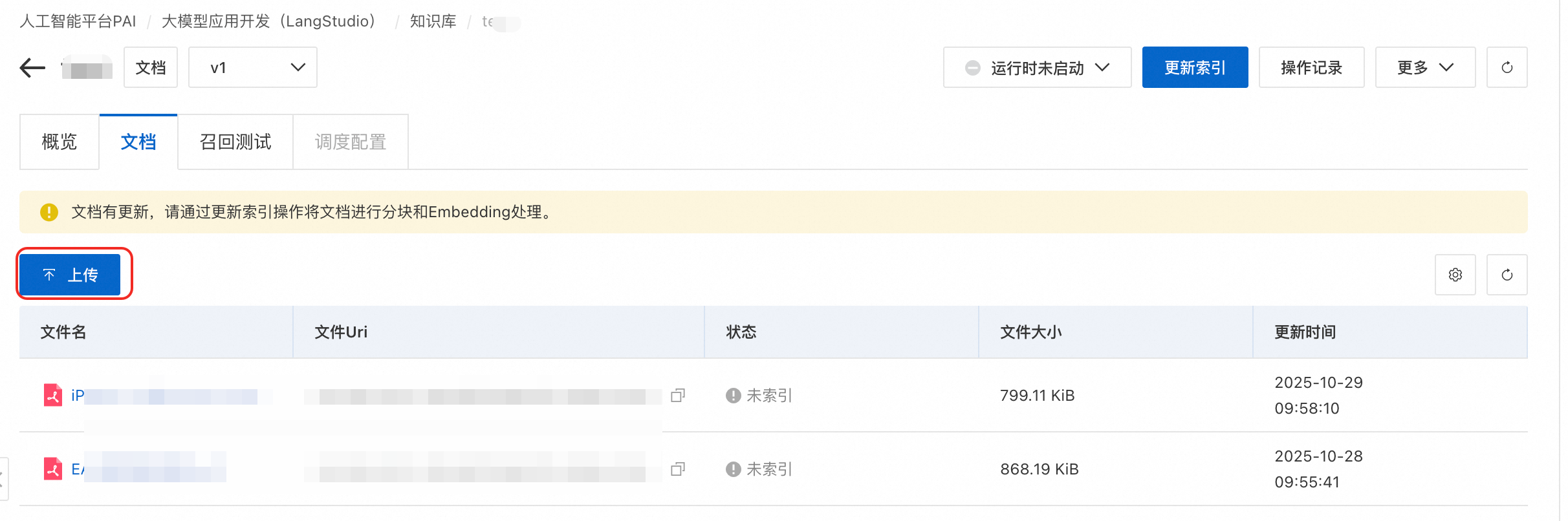
步骤三:构建索引
更新索引。文件上传后,单击右上角更新索引,系统会提交一个PAI工作流任务,通过执行DLC任务对OSS数据源中的文件进行预处理、分块和向量化并构建索引。任务参数配置说明如下:
参数
描述
计算资源
执行工作流节点任务所需的计算资源,可使用公共资源或者通过资源配额使用灵骏智算资源和通用计算资源。
图片类型知识库更新索引时,节点数量必须大于2。
为高质量提取复杂PDF中的图表,建议更新索引时使用 GPU 资源且驱动版本 550 以上。系统会对满足资源类型和驱动版本的任务自动调用模型进行图表识别或 OCR,图片将存储于输出路径的
chunk_images目录。在应用流中使用时,文本中的图片会替换为一个HTML<img>标签,如<img src="临时的签名URL">。
专有网络配置
若通过内网访问向量数据库或 Embedding 服务,请确保所选 VPC 与这些服务的 VPC 相同或可互通。
Embedding配置
最大并发数(图片类型知识库需配置):同时调用 Embedding 服务的请求数。由于百炼多模态模型服务限制每分钟请求120次,调高此并发数可能会触发限流。
分批大小(文档/结构化数据类型知识库需配置):对文本块进行向量化处理时,每批处理的数量。根据模型服务的QPS限制设置合适值可以提升处理速度。
文件切片/图片预览。更新索引任务执行成功之后,可预览文档分块或图片。
说明对于已存入Milvus的文档分块,可以单独设置其状态为启用或禁用。被禁用的分块将不会被检索到。

步骤四:测试召回效果
更新索引之后,切换到召回测试页签,输入问题并调整检索参数,以测试召回效果。图片知识库将返回图片列表。

检索设置参数说明:
Top K:控制从知识库中最多检索多少个相关的文本片段,取值范围 1~100。
Score阈值:设置相似度分数门槛(0~1),只有高于此分数的片段才会被返回。数值越高说明对于文本与检索内容要求的相似度越高。
检索模式:默认Dense(向量检索)。如果需要使用 Hybrid 混合检索(向量+关键字),向量数据库需为 Milvus 2.4.x 以上 或 Elasticsearch。检索模式选择请参见选择检索模式。
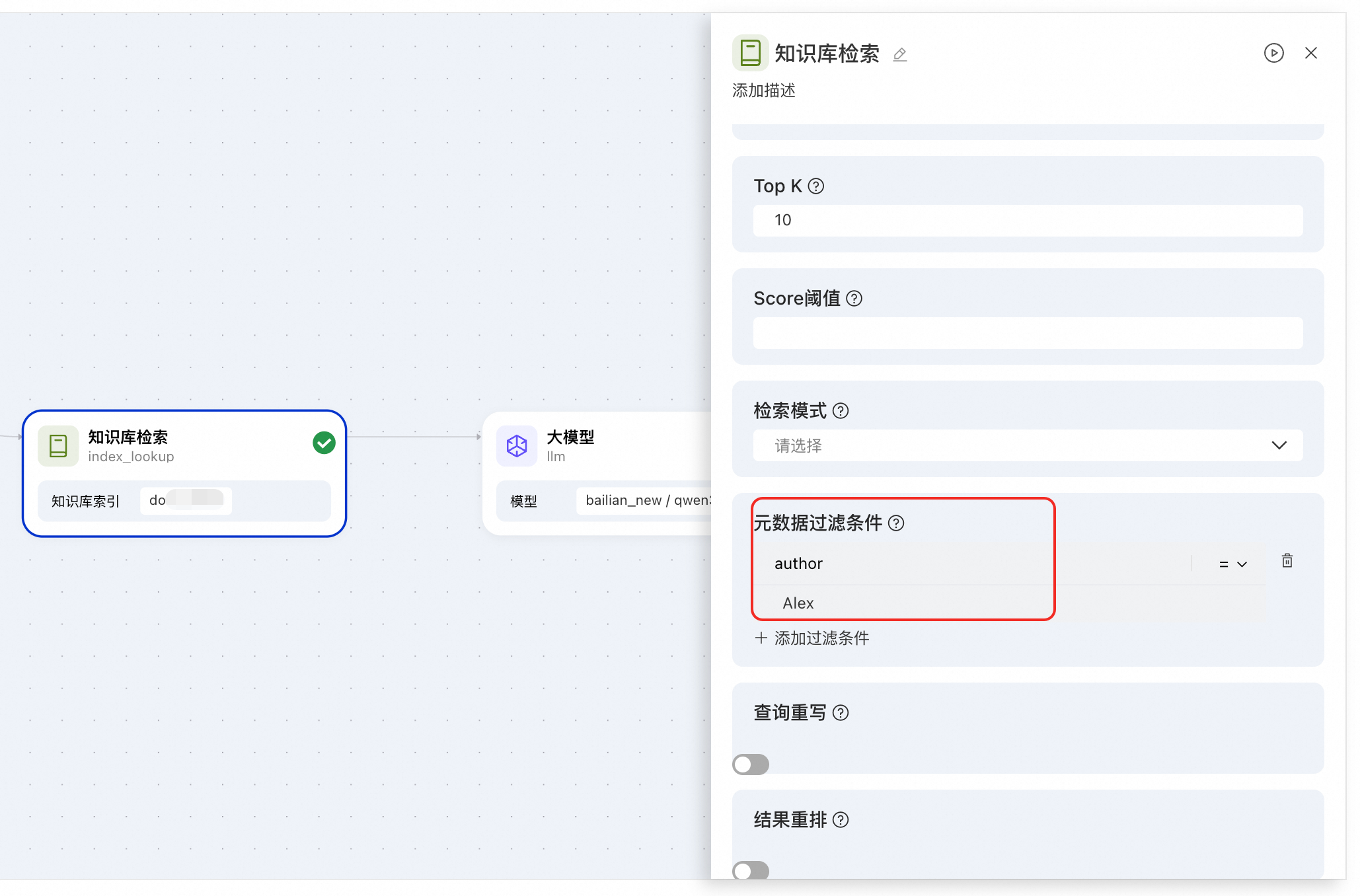
元数据过滤条件:通过元数据对检索范围进行精确过滤,提升准确性。详情参见使用元数据。
查询重写:利用大语言模型优化用户模糊、口语化或依赖上下文的原始查询,使其更清晰完整、意图更明确,以提升检索准确率。使用场景请参见查询重写。
结果重排:使用重排模型对初步检索到的结果进行二次排序,将最相关的结果排在最前。使用场景请参见结果重排。
说明结果重排需要使用重排模型。支持的模型服务连接类型有:百炼大模型服务、AI搜索开放平台模型服务、通用Reranker模型服务。
步骤五:在应用流中使用
完成测试之后,可以在应用流中通过知识库来检索信息。在知识库节点中可开启查询重写和结果重排功能,并能在链路中查看重写后的问题。
返回结果为List[Dict],其中Dict的Key包含content和score,分别对应文档分片与输入查询的内容和相似度得分。返回结果包含得分最高的Top K条记录,示例如下:
[
{
"score": 0.8057173490524292,
"content": "受疫情带来的不确定性影响,xx银行根据经济走势及中国或中国内地环境预判,主动\n加大了贷款和垫款、非信贷资产减值损失的计提力度,加大\n不良资产核销处置力度,提升拨备覆盖率,2020 年实现净利\n润289.28亿元,同比增长 2.6%,盈利能力逐步改善。\n(人民币百万元) 2020年 2019年 变动(%)\n经营成果与盈利\n营业收入 153,542 137,958 11.3\n减值损失前营业利润 107,327 95,816 12.0\n净利润 28,928 28,195 2.6\n成本收入比(1)(%) 29.11 29.61下降 0.50个\n百分点\n平均总资产收益率 (%) 0.69 0.77下降 0.08个\n百分点\n加权平均净资产收益率 (%) 9.58 11.30下降 1.72个\n百分点\n净息差(2)(%) 2.53 2.62下降 0.09个\n百分点\n注: (1) 成本收入比 =业务及管理费/营业收入。",
"id": "49f04c4cb1d48cbad130647bd0d75f***1cf07c4aeb7a5d9a1f3bda950a6b86e",
"metadata": {
"page_label": "40",
"file_name": "2021-02-04_中国xx保险集团股份有限公司_xx_中国xx_2020年__年度报告.pdf",
"file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__中国xx保险集团股份有限公司__601318__中国xx__2020年__年度报告.pdf",
"file_type": "application/pdf",
"file_size": 7982999,
"creation_date": "2024-10-10",
"last_modified_date": "2024-10-10"
}
},
{
"score": 0.7708036303520203,
"content": "72亿元,同比增长 5.2%。\n2020年\n(人民币百万元)寿险及\n健康险业务财产保险\n业务 银行业务 信托业务 证券业务其他资产\n管理业务 科技业务其他业务\n及合并抵消 集团合并\n归属于母公司股东的净利润 95,018 16,083 16,766 2,476 2,959 5,737 7,936 (3,876) 143,099\n少数股东损益 1,054 76 12,162 3 143 974 1,567 281 16,260\n净利润 (A) 96,072 16,159 28,928 2,479 3,102 6,711 9,503 (3,595) 159,359\n剔除项目 :\n 短期投资波动(1)(B) 10,308 – – – – – – – 10,308\n 折现率变动影响 (C) (7,902) – – – – – – – (7,902)\n 管 理层认为不属于 \n日常营运收支而剔除的 \n一次性重大项目及其他 (D) – – – – – – 1,282 – 1,282\n营运利润 (E=A-B-C-D) 93,666 16,159 28,928 2,479 3,102 6,711 8,221 (3,595) 155,670\n归属于母公司股东的营运利润 92,672 16,",
"id": "8066c16048bd722d030a85ee8b1***36d5f31624b28f1c0c15943855c5ae5c9f",
"metadata": {
"page_label": "19",
"file_name": "2021-02-04_中国xx保险集团股份有限公司_xxx_中国xx__2020年__年度报告.pdf",
"file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__中国xx保险集团股份有限公司__601318__中国xx__2020年__年度报告.pdf",
"file_type": "application/pdf",
"file_size": 7982999,
"creation_date": "2024-10-10",
"last_modified_date": "2024-10-10"
}
}
]检索优化
分块参数调优:奠定召回基础
设置原则
模型上下文限制:确保分块大小不超过 Embedding 模型处理的 token 上限,避免信息被截断。
信息完整性:分块应足够大以包含完整语义,但也要避免因包含过多信息而影响相似度计算的精度。如果文本内容是按段落组织的,可以选择让每个块包含完整的段落,而不是生硬地切割。
保持连续性:设置适当的重叠大小(建议为分块大小的10%-20%),可以有效避免因分块边界切割关键信息而导致的上下文丢失。
避免重复干扰:过多的重叠会引入重复信息,影响检索效率。需要在“信息完整性”和“信息冗余”之间找到平衡。
调试建议
迭代优化:从一个初始值(如分块大小300,重叠大小50)开始,根据实际的检索和问答效果不断调整、尝试,找到最适合数据特性的设置。
自然语言边界:如果文本结构清晰(如按章节、段落划分),可优先考虑基于自然语言边界进行切分,以最大程度保持语义完整性。
快速优化指南
问题现象 | 优化建议 |
检索结果不相关 | 增大分块大小,减少分块重叠大小。 |
结果上下文不连贯 | 增大分块重叠大小。 |
找不到合适的匹配(召回率低) | 适当增加分块大小。 |
计算或存储开销过高 | 降低分块大小,减少分块重叠大小。 |
以下是基于以往经验推荐的各类文本对应的分块大小和重叠大小:
文本类型 | 推荐分块大小(chunk_size) | 推荐重叠大小(chunk_overlap) |
短文本(FAQ、摘要) | 100~300 | 20~50 |
普通文本(新闻、博客) | 300~600 | 50~100 |
技术文档(API、论文) | 600~1024 | 100~200 |
长篇文档(法律、书籍) | 1024~2048 | 200~400 |
选择检索模式:平衡语义与关键词
检索模式决定了系统如何匹配您的问题和知识库中的内容。不同的模式各有优劣,适用于不同场景。
Dense(向量)检索:擅长理解语义。将问题和文档都转换为向量,通过计算向量间的相似度来判断语义相关性。
Sparse(关键词)检索:擅长精确匹配。基于传统的词频统计模型(如 BM25),通过关键词在文档中的出现频率和位置计算相关性。
Hybrid (混合)检索:兼顾两者。结合向量检索和关键词检索的结果,通过 RRF(Reciprocal Rank Fusion) 或加权融合算法(如线性加权、模型集成)重新排序。
检索模式 | 优缺点 | 适用场景 |
Dense(向量)检索 |
|
|
Sparse(关键词)检索 |
|
|
Hybrid (混合)检索 |
|
|
使用元数据:过滤检索
元数据过滤的价值
精准检索,减少噪声干扰:元数据可作为检索时的过滤条件或排序依据,通过元数据过滤,可排除不相关的文档,避免将无关内容引入生成模型。例如:用户提问“查找刘慈欣写的科幻小说”时,系统可以通过
作者=刘慈欣和类别=科幻两个元数据条件,直接定位到最相关的文档。提升用户体验
支持个性化推荐:可根据用户的历史偏好(如喜欢“科幻类”文档),利用元数据进行个性化推荐。
增强结果解释性:在结果中附上文档的元信息(如作者、来源、时间),帮助用户判断内容的可信度和相关性。
支持多语言或多模态扩展:通过“语言”、“媒体类型”等元数据,可以轻松管理包含多语言、图文混合的复杂知识库。
使用方式
功能限制:
运行时镜像版本:需为 2.1.8 或更高版本。
向量数据库:仅支持Milvus和Elasticsearch。
知识库类型:支持文档或结构化数据,不支持图片。
配置元数据变量。仅使用Milvus的知识库在概览页签可以找到元数据区域,单击编辑进行配置(如变量名称为
author),请注意不要使用系统预留字段。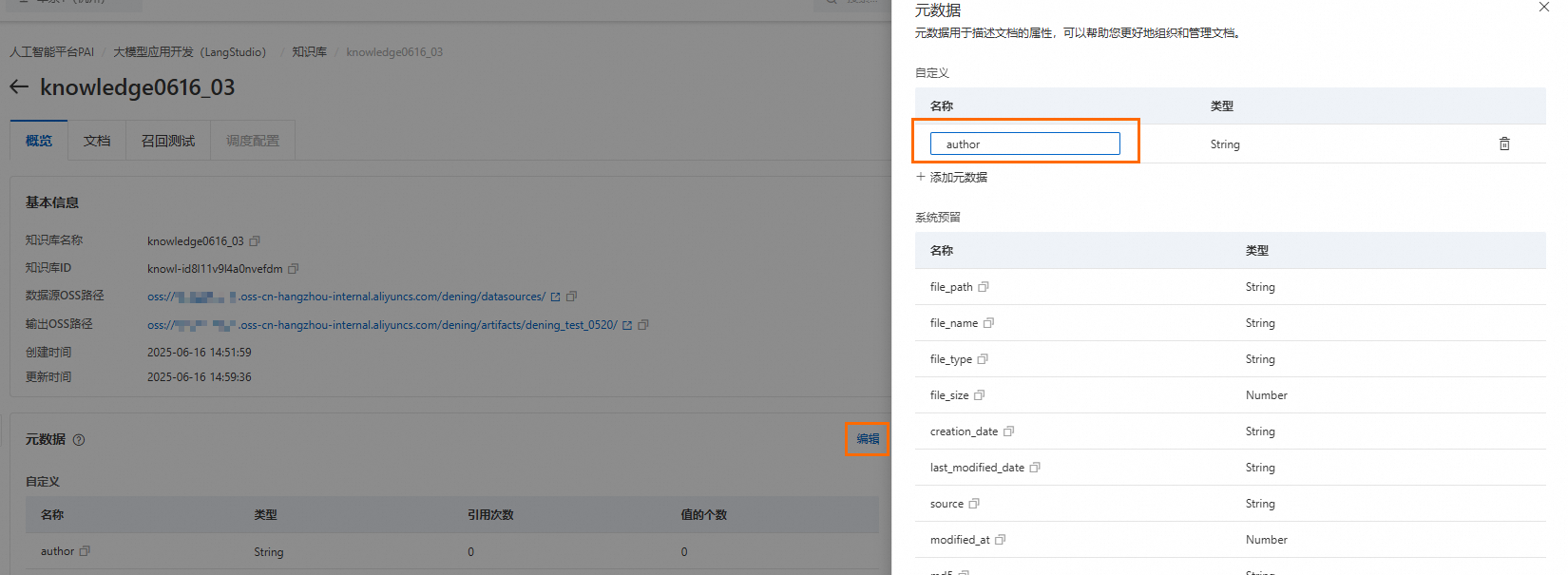
为文档打标。进入文档分块详情页面,单击编辑元数据,添加元数据变量和值(如
author=Alex)。回到概览页可以看到元数据的引用情况及值的个数。
测试过滤效果。在召回测试页签,添加元数据过滤条件并进行测试。
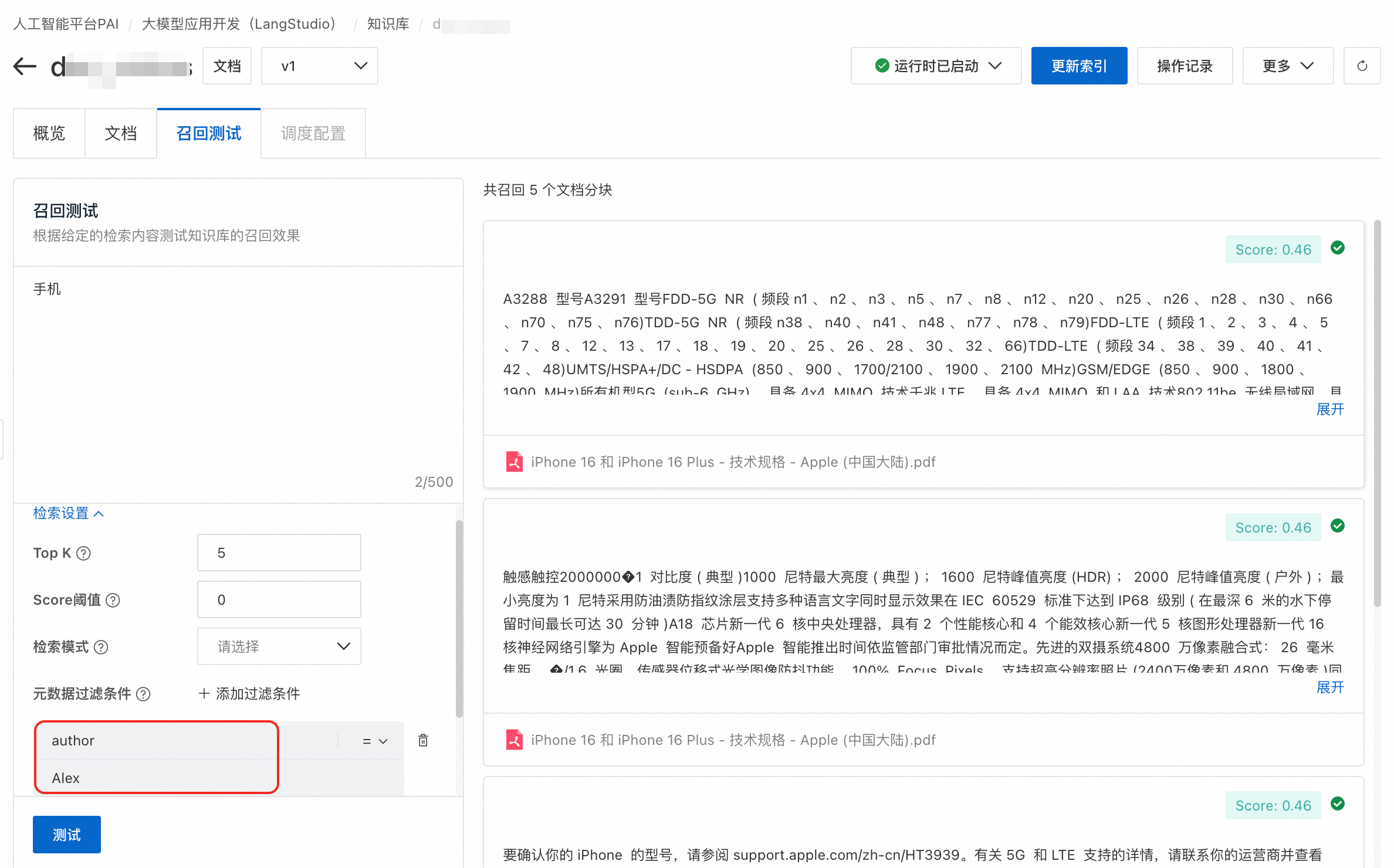
注:图中召回的文档均为步骤2中打标的文档。
在应用流中使用。在知识库节点中配置元数据过滤条件。
查询重写与结果重排:优化检索链路
查询重写
利用大语言模型将用户模糊、口语化或依赖上下文的问题,改写成一个更清晰、更完整的独立问题,从而提升后续的检索准确率。
建议使用场景:
用户问题模糊、不完整(如“他什么时候出生的?”但没有上下文)。
多轮对话中,问题依赖上下文(如“那他后来做了什么?”)。
检索器或LLM 性能较弱,对原始问题理解不准确时。
使用的是传统倒排索引检索(如BM25)而非语义检索时。
不建议使用的场景:
用户问题已经非常清晰明确。
LLM 性能非常好,对原始问题理解能力强。
系统要求低延迟,无法接受重写带来的额外延迟。
结果重排
对检索器返回的初始结果进行重新排序,优先展示最相关的文档,提升排序质量。
建议使用场景:
初步检索器(如BM25或DPR)返回的结果质量不稳定。
对检索结果的排序要求高(如搜索、问答系统中要求Top 1准确率)。
不建议使用的场景:
系统资源受限,无法承受额外的推理开销。
初步检索器的性能已足够强大,重排带来的提升有限。
对响应时间要求极高,如实时搜索场景。
运维与管理
配置定时调度:自动更新
定时调度功能依赖于DataWorks,请确保您已开通该服务。若未开通,请前往开通DataWorks服务。
在知识库详情页,单击右上角的,完成相关配置后提交。

查看调度配置/周期任务
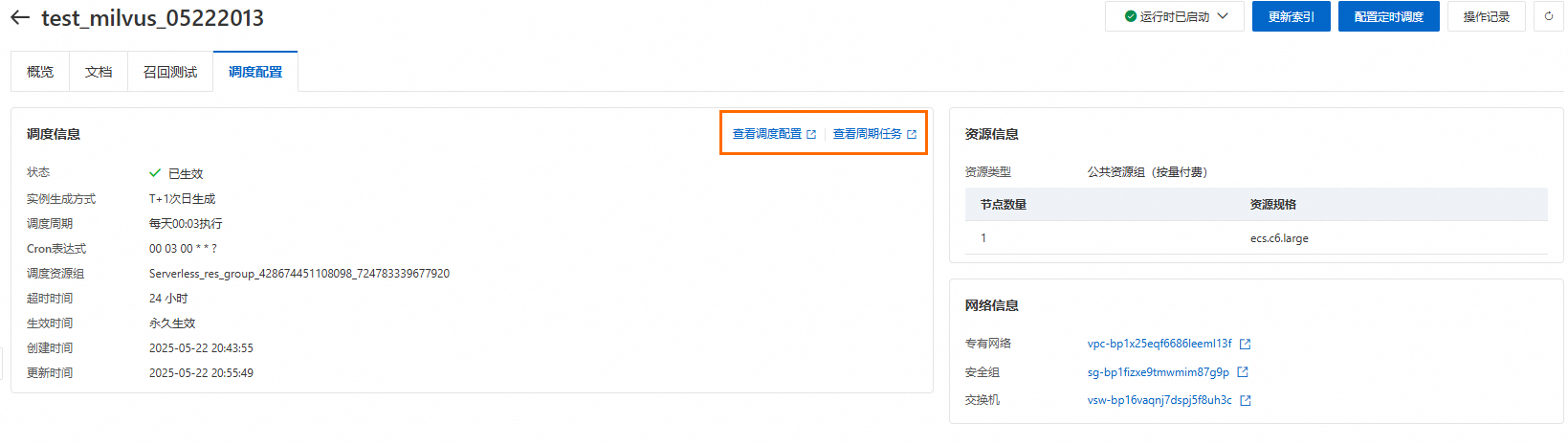
提交表单后,系统会自动在DataWorks数据开发中心创建知识库定时调度的Workflow,并发布到DataWorks数据运维中心的周期任务(目前周期任务是T+1生效),DataWorks周期任务会按您配置的定时调度时间执行更新知识库的操作。您可以在知识库详情的调度配置页面,查看调度配置和周期任务。
定时调度配置参数说明:
调度周期:用于定义节点在生产环境中的运行频率(生成周期实例个数及实例运行的时间)。
调度时间:用于定义节点具体运行的时间。
超时定义:用于定义节点运行超过多长时间会失败退出。
生效日期:用于定义节点正常自动调度运行的时间范围,该时间范围外,节点将不再自动调度。
调度资源组:用于DataWorks定时调度功能。如果尚未创建DataWorks资源组,可单击下拉框中的立即新建跳转至创建页面。创建完成后,需将资源组绑定到当前工作空间。
更多调度参数说明,请参见时间属性配置说明。
多版本管理:开发与生产隔离
通过版本克隆功能,可以将测试验证好的知识库(v1版本)发布为一个新的正式版本,从而实现开发环境与生产环境的隔离。
克隆版本成功后,可以在知识库详情页的类型旁切换和管理不同版本,同时在应用流的知识库检索节点中选择需要使用的版本。

克隆版本和更新索引类似,会提交一个工作流任务,可在操作记录中查看任务。
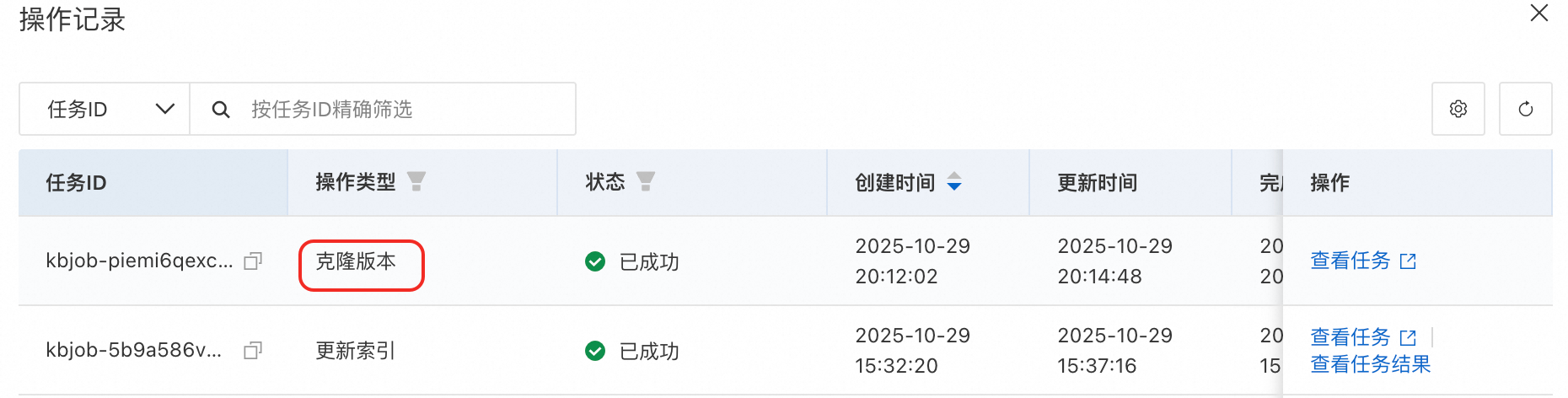
故障排查:查看工作流任务
更新索引或克隆版本之后,单击右上角操作记录,选择目标任务,单击操作列的查看任务可以查看任务每个节点的运行详情,包括运行信息、任务日志和输出结果。

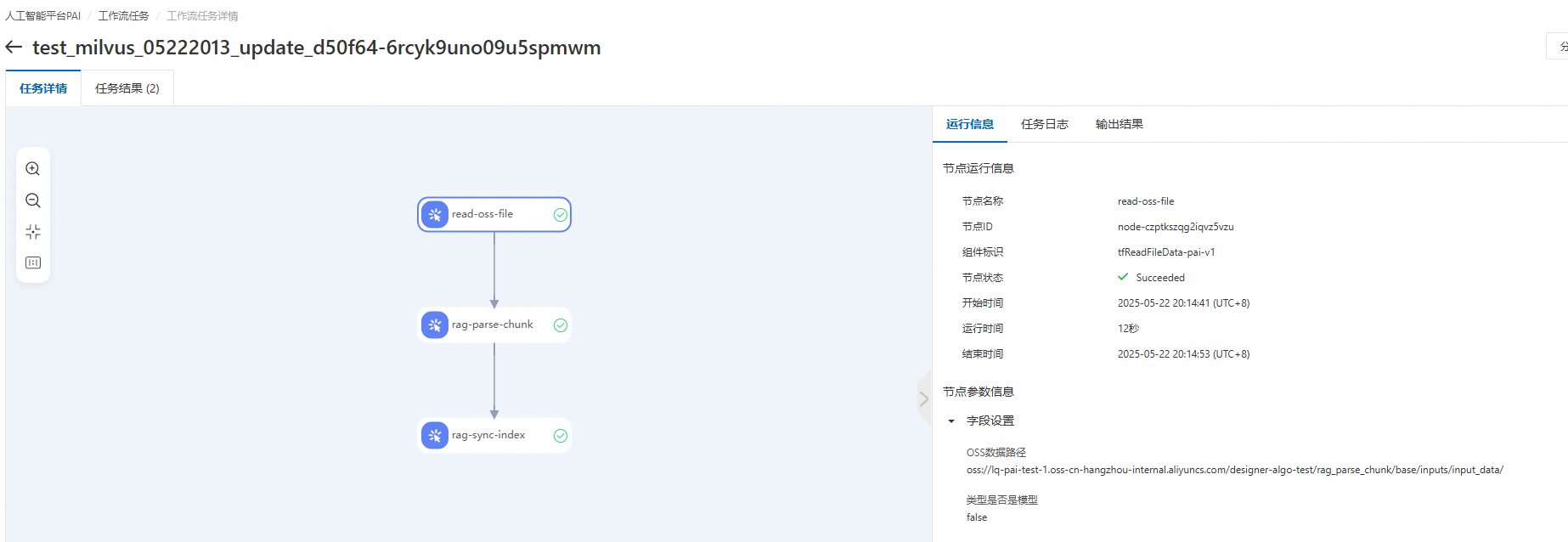
例如,文档类型知识库更新索引的工作流任务包括以下三个节点,除read-oss-file节点外,每个节点会创建一个PAI-DLC任务。还可以通过日志中的Job URL来查看DLC任务详情。
read-oss-file:读取OSS文件。
rag-parse-chunk:负责文档的预处理和分块。
rag-sync-index:负责对文本块进行 Embedding 处理,并将其同步至向量数据库。
资产管理:查看数据集
更新索引任务成功之后,系统会自动将输出OSS路径注册为数据集。可以在AI资产管理-数据集中查看。这个数据集与知识库同名,记录了索引构建过程的输出信息。