该解决方案基于大语言模型(LLM)的意图识别技术,能够从海量的数据中学习到复杂的语言规律和用户行为模式,实现对用户意图的更精准识别和更自然流畅的交互体验。本方案以通义千问1.5(Qwen1.5)大语言模型为基础,为您介绍基于LLM的意图识别解决方案的完整开发流程。
背景信息
什么是意图识别
即AI智能体通过理解人们用自然语言所表达的需求,来执行相应的操作或提供相应的信息,它是智能交互系统中不可或缺的一环。目前,基于大语言模型(LLM)的意图识别技术已经得到业界的广泛关注,并被广泛应用。
意图识别技术的典型场景示例
在智能语音助手领域,用户通过简单的语音命令与语音助手进行交互。例如,当用户对语音助手说“我想听音乐”时,系统需要准确识别出用户的需求是播放音乐,然后执行相应操作。
在智能客服场景中,挑战则体现在如何处理各种客户服务请求,并将它们快速准确地分类至例如退货、换货、投诉等不同的处理流程中。例如,在电子商务平台上,用户可能会表达“我收到的商品有瑕疵,我想要退货”。在这里,基于LLM的意图识别系统要能够迅速捕捉到用户的意图是“退货”,并且自动触发退货流程,进一步引导用户完成后续操作。
使用流程
基于LLM的意图识别解决方案的使用流程如下:

您可以参照数据格式要求和数据准备策略并针对特定的业务场景准备相应的训练数据集。您也可以参照数据准备策略准备业务数据,然后通过智能标注(iTAG)进行原始数据标注。导出标注结果,并转换为PAI-QuickStart支持的数据格式,用于后续的模型训练。
在快速开始(QuickStart)中,基于Qwen1.5-1.8B-Chat模型进行模型训练。模型训练完成后,对模型进行离线评测。
当模型评测结果符合您的预期后,通过快速开始(QuickStart)将训练好的模型部署为EAS在线服务。
前提条件
在开始执行操作前,请确认您已完成以下准备工作:
已开通PAI(DLC、EAS)后付费,并创建默认工作空间,详情请参见开通PAI并创建默认工作空间。
已创建OSS存储空间(Bucket),用于存储训练数据和训练获得的模型文件。关于如何创建存储空间,详情请参见控制台创建存储空间。
准备训练数据
支持使用以下两种方式准备训练数据:
方式二:依据数据准备策略,使用iTAG平台进行数据标注。适用于大规模数据场景,显著提升标注效率。
数据准备策略
为了提升训练的有效性和稳定性,您可以参考以下策略准备数据:
对于单意图识别场景,确保每类意图的标注数量至少为50至100条,当模型微调效果不佳时,您可以考虑增加标注数据量。同时,您需要注意每类意图的标注数据量尽量均衡,不宜出现某类意图的标注数据量过多的情况。
对于多意图识别场景或多轮对话场景,建议标注数据量在单意图识别场景数据量的20%以上,同时多意图识别场景或多轮对话场景涉及的意图需要在单意图识别场景中出现过。
意图描述需要覆盖尽可能丰富的问法和场景。
数据格式要求
训练数据格式要求为:JSON格式的文件,包含instruction和output两个字段,分别对应输入的指令和模型预测的意图以及对应的关键参数。对于不同的意图识别场景,相应的训练数据示例如下:
对于单意图识别场景,您需要针对特定的业务场景,准备相应的业务数据,用于大语言模型(LLM)的微调训练。以智能家居的单轮对话为例,训练数据示例如下:
[ { "instruction": "我想听音乐", "output": "play_music()" }, { "instruction": "太吵了,把声音开小一点", "output": "volume_down()" }, { "instruction": "我不想听了,把歌关了吧", "output": "music_exit()" }, { "instruction": "我想去杭州玩,帮我查下天气预报", "output": "weather_search(杭州)" }, ]对于多意图识别场景或多轮对话场景,用户的意图可能会在多个对话轮次中表达。在这种情况下,您可以准备多轮对话数据,并对多轮用户的输入进行标注。以语音助手为例,给定一个多轮对话流:
User:我想听音乐。 Assistant:什么类型的音乐? User:给我放个***的音乐吧。 Assistant:play_music(***)相应的多轮对话训练数据格式如下:
[ { "instruction": "我想听音乐。给我放个***的音乐吧。", "output": "play_music(***)" } ]
由于多轮对话模型训练的长度明显提升,而且在实际应用中,多轮对话意图识别场景数量有限。建议您仅当单轮对话的意图识别无法满足实际业务需求时,考虑应用多轮对话的模型训练方式。本方案将以单轮对话为例,为您展示该解决方案的整个使用流程。
使用iTAG平台进行数据标注
您也可以参考以下操作步骤,使用PAI-iTAG平台对数据进行标注,以生成满足特定要求的训练数据集。
将用于iTAG标注的数据注册到PAI数据集。
参考数据准备策略,准备manifest格式的数据文件,内容示例如下。
{"data":{"instruction": "我想听音乐"}} {"data":{"instruction": "太吵了,把声音开小一点"}} {"data":{"instruction": "我不想听了,把歌关了吧"}} {"data":{"instruction": "我想去杭州玩,帮我查下天气预报"}}创建数据集,其中关键参数说明如下,其他参数配置详情,请参见创建及管理数据集。
参数
描述
选择数据存储
选择阿里云对象存储(OSS)。
属性
选择文件。
从阿里云云存储创建
选择已创建的OSS目录,按照以下操作步骤上传已准备好的manifest文件:
在选择OSS目录对话框,单击上传文件。
单击查看本地文件或拖拽上传文件,根据提示上传manifest文件。
在智能标注iTAG页面创建模板,其中关键配置说明如下,其他配置详情,请参见模板管理。
配置
描述
显示内容
将内容组件下的文本组件拖拽到显示内容区域,然后单击文本组件,并在配置面板中,将选择文本内容所在字段配置为instruction。
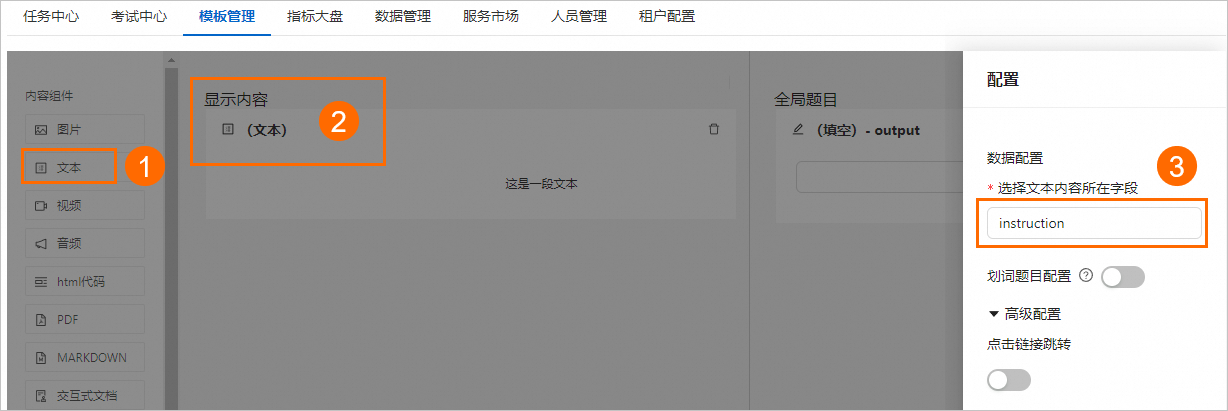
全局题目
将题目组件下的填空组件拖拽到全局题目区域,然后单击填空组件,并在配置面板中,将题目名称设置为output。
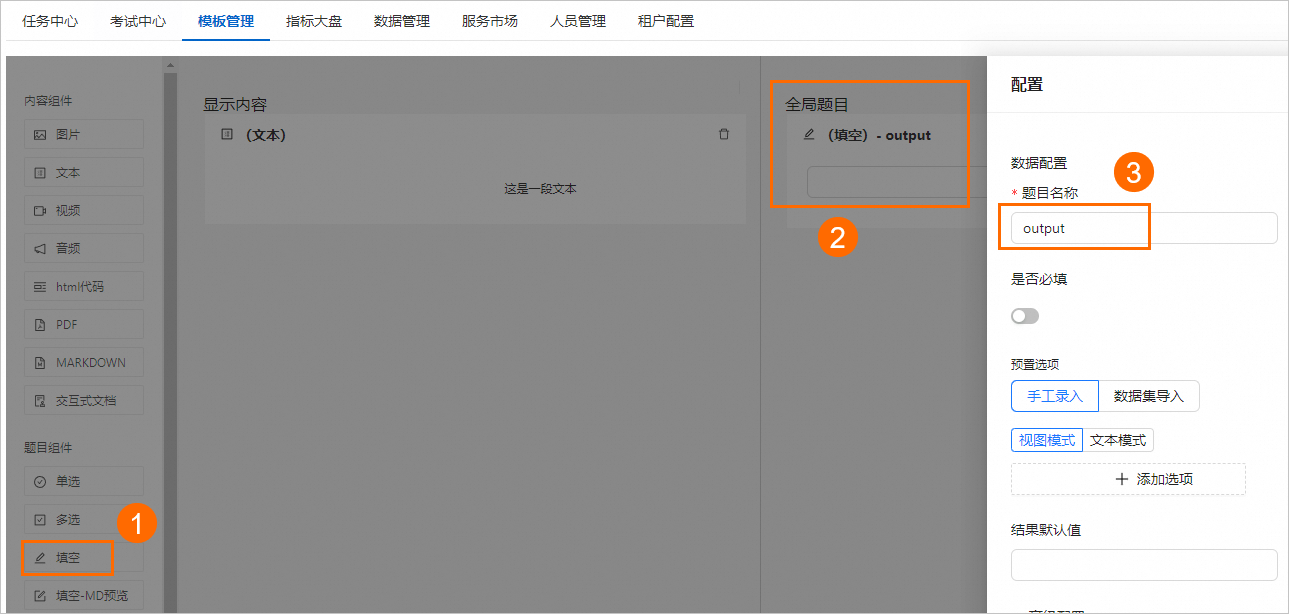
创建标注任务,其中关键配置说明如下,其他参数配置详情,请参见创建标注任务。
参数
描述
输入数据集
选择上述步骤已创建的数据集。
说明请注意,输入的数据和使用的模板对应。
模板类型
选择自定义模板,并在已有模板下拉框中,选择已创建的模板。
标注任务创建完成后,开始标注数据。具体操作,请参见处理标注任务。

完成数据标注后,将标注结果导出至OSS目录中。具体操作,请参见导出标注结果数据。
在本方案中,输出的manifest文件的内容示例如下,数据格式说明,请参见标注数据格式概述。
{"data":{"instruction":"我想听音乐","_itag_index":""},"label-1787402095227383808":{"results":[{"questionId":"2","data":"play_music()","markTitle":"output","type":"survey/value"}]},"abandonFlag":0,"abandonRemark":null} {"data":{"instruction":"太吵了,把声音开小一点","_itag_index":""},"label-1787402095227383808":{"results":[{"questionId":"2","data":"volume_down()","markTitle":"output","type":"survey/value"}]},"abandonFlag":0,"abandonRemark":null} {"data":{"instruction":"我不想听了,把歌关了吧","_itag_index":""},"label-1787402095227383808":{"results":[{"questionId":"2","data":"music_exit()","markTitle":"output","type":"survey/value"}]},"abandonFlag":0,"abandonRemark":null} {"data":{"instruction":"我想去杭州玩,帮我查下天气预报","_itag_index":""},"label-1787402095227383808":{"results":[{"questionId":"2","data":"weather_search(杭州)","markTitle":"output","type":"survey/value"}]},"abandonFlag":0,"abandonRemark":null}在终端中,使用如下Python脚本,将上述生成的manifest格式的数据标注结果文件,转换为适用于快速开始(QuickStart)的训练数据格式。
import json # 输入文件路径和输出文件路径。 input_file_path = 'test_json.manifest' output_file_path = 'train.json' converted_data = [] with open(input_file_path, 'r', encoding='utf-8') as file: for line in file: data = json.loads(line) instruction = data['data']['instruction'] for key in data.keys(): if key.startswith('label-'): output = data[key]['results'][0]['data'] converted_data.append({'instruction': instruction, 'output': output}) break with open(output_file_path, 'w', encoding='utf-8') as outfile: json.dump(converted_data, outfile, ensure_ascii=False, indent=4)输出结果为JSON格式的文件。
训练及离线评测模型
训练模型
快速开始(QuickStart)汇集了优秀的国内外AI开源社区预训练模型。您可以在快速开始(QuickStart)中,实现从训练到部署再至推理的完整流程,无需编写代码,极大简化了模型的开发过程。
本方案以Qwen1.5-1.8B-Chat模型为例,为您介绍如何使用已准备好的训练数据,在快速开始(QuickStart)中进行模型训练。具体操作步骤如下:
进入快速开始页面。
登录PAI控制台。
在顶部左上角根据实际情况选择地域。
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间内。
在左侧导航栏选择快速开始。
在快速开始页面右侧的模型列表中,单击通义千问1.5-1.8B-Chat模型卡片,进入模型详情页面。
在模型详情页面,单击右上角的微调训练。
在微调训练配置面板中,配置以下关键参数,其他参数取默认配置。
参数
描述
训练方式
训练方式
全参数微调:资源要求高,训练时间长,效果一般更好。
说明参数量较小的模型支持全参数微调,请根据您的场景需要进行选择。
QLoRA:表示轻量化微调。相较于全参数微调,资源要求更低,训练时间更短,效果一般会差一些。
LoRA:同QLoRA。
数据集配置
训练数据集
参照以下操作步骤,选择已准备好的训练数据集。
在下拉列表中选择OSS文件或目录。
单击
 按钮,选择已创建的OSS目录。
按钮,选择已创建的OSS目录。在选择OSS目录或文件对话框中,单击上传文件,拖拽上传已准备好的训练数据集文件,并单击确定。
训练输出配置
model
选择OSS目录,用来存放训练输出的配置文件。
超参数配置
关于超参数详细介绍,请参见表1.全量超参数说明。
建议您按照以下超参数配置策略进行配置,针对不同的训练方式,关键超参数推荐配置,请参见表2.超参数推荐配置。
注意根据不同的训练方式配置超参数。
全局批次大小=卡数*per_device_train_batch_size*gradient_accumulation_steps为了最大化训练性能,优先调大卡数和per_device_train_batch_size。
一般将全局批次大小设置为64至256,当训练数据量很少时,可以适当调小。
序列长度(seq_length)可以根据实际场景进行调整。例如,数据集中本文序列最大长度为50,则可以将序列长度设置为64(一般设置为2的次幂数)。
当训练loss下降过慢或者不收敛时,建议您适当调大学习率(learning_rate)。同时,需要确认训练数据的数据质量是否有保证。
单击训练按钮,在计费提醒对话框中单击确定。
系统自动跳转到训练任务详情页面,训练任务启动成功,您可以在该页面查看训练任务状态和训练日志。
离线评测模型
当模型训练结束后,您可以在终端使用Python脚本,来评测模型效果。
准备评测数据文件testdata.json,内容示例如下:
[ { "instruction": "想知道的十年是谁唱的?", "output": "music_query_player(十年)" }, { "instruction": "今天北京的天气怎么样?", "output": "weather_search(杭州)" } ]在终端中,使用如下Python脚本来离线评测模型。
#encoding=utf-8 from transformers import AutoModelForCausalLM, AutoTokenizer import json from tqdm import tqdm device = "cuda" # the device to load the model onto # 修改模型路径 model_name = '/mnt/workspace/model/qwen14b-lora-3e4-256-train/' print(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(model_name) count = 0 ecount = 0 # 修改训练数据路径 test_data = json.load(open('/mnt/workspace/data/testdata.json')) system_prompt = '你是一个意图识别专家,可以根据用户的问题识别出意图,并返回对应的函数调用和参数。' for i in tqdm(test_data[:]): prompt = '<|im_start|>system\n' + system_prompt + '<|im_end|>\n<|im_start|>user\n' + i['instruction'] + '<|im_end|>\n<|im_start|>assistant\n' gold = i['output'] gold = gold.split(';')[0] if ';' in gold else gold model_inputs = tokenizer([prompt], return_tensors="pt").to(device) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=64, pad_token_id=tokenizer.eos_token_id, eos_token_id=tokenizer.eos_token_id, do_sample=False ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] pred = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] if gold.split('(')[0] == pred.split('(')[0]: count += 1 gold_list = set(gold.strip()[:-1].split('(')[1].split(',')) pred_list = set(pred.strip()[:-1].split('(')[1].split(',')) if gold_list == pred_list: ecount += 1 else: pass print("意图识别准确率:", count/len(test_data)) print("参数识别准确率:", ecount/len(test_data))
部署及调用模型服务
部署模型服务
当评测模型效果符合预期时,您可以按照以下操作步骤,将训练获得的模型部署为EAS在线服务。
在任务详情页面的模型部署区域,系统已默认配置了模型服务信息和资源部署信息,您也可以根据需要进行修改,参数配置完成后单击部署按钮。
在计费提醒对话框中,单击确定。
系统自动跳转到部署任务页面,当状态为运行中时,表示服务部署成功。
在语音助手的意图识别场景中,为了保证用户的交互体验,通常要求更高的延时。因此建议您使用PAI提供的BladeLLM推理引擎进行LLM服务的部署,详情请参见如何提升推理并发且降低延迟?。
调用模型服务
服务部署成功后,您可以在服务详情页面右侧,单击查看WEB应用,使用ChatLLM WebUI进行实时交互,也可以使用API进行模型推理。具体使用方法参考5分钟使用EAS一键部署LLM大语言模型应用。
以下提供一个示例,展示如何通过客户端发起Request调用:
获取服务访问地址和Token。
在服务详情页面,单击资源信息区域的查看调用信息。

在调用信息对话框中,查询服务访问地址和Token,并保存到本地。
在终端中,执行如下代码调用服务。
import argparse import json from typing import Iterable, List import requests def post_http_request(prompt: str, system_prompt: str, history: list, host: str, authorization: str, max_new_tokens: int = 2048, temperature: float = 0.95, top_k: int = 1, top_p: float = 0.8, langchain: bool = False, use_stream_chat: bool = False) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "use_stream_chat": use_stream_chat, "history": history } response = requests.post(host, headers=headers, json=pload, stream=use_stream_chat) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] history = data["history"] return output, history if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=4) parser.add_argument("--top-p", type=float, default=0.8) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=0.95) parser.add_argument("--prompt", type=str, default="How can I get there?") parser.add_argument("--langchain", action="store_true") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p use_stream_chat = False temperature = args.temperature langchain = args.langchain max_new_tokens = args.max_new_tokens host = "EAS服务公网地址" authorization = "EAS服务公网Token" print(f"Prompt: {prompt!r}\n", flush=True) # 在客户端请求中可设置语言模型的system prompt。 system_prompt = "你是一个意图识别专家,可以根据用户的问题识别出意图,并返回对应的意图和参数" # 客户端请求中可设置对话的历史信息,客户端维护当前用户的对话记录,用于实现多轮对话。通常情况下可以使用上一轮对话返回的histroy信息,history格式为List[Tuple(str, str)]。 history = [] response = post_http_request( prompt, system_prompt, history, host, authorization, max_new_tokens, temperature, top_k, top_p, langchain=langchain, use_stream_chat=use_stream_chat) output, history = get_response(response) print(f" --- output: {output} \n --- history: {history}", flush=True) # 服务端返回JSON格式的响应结果,包含推理结果与对话历史。 def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] history = data["history"] return output, history其中:
host:配置为已获取的服务访问地址。
authorization:配置为已获取的服务Token。
相关文档
更多关于iTAG的使用流程以及标注数据格式要求,请参见智能标注(iTAG)。
更多关于EAS产品的内容介绍,请参见模型在线服务(EAS)。
使用快速开始(QuickStart)功能,您可以轻松完成更多场景的部署与微调任务,包括Llama-3、Qwen1.5、Stable Diffusion V1.5等系列模型。详情请参见场景实践。