在进行大语言模型(LLM)推理时,您可能会面临因KVCache占用大量显存而导致的响应延迟高、并发处理能力不足等问题。PolarKVCache是专为解决此类场景设计的推理加速方案,它基于PolarDB分布式内存池(DMP),通过创新的架构将KVCache从有限的GPU显存扩展到TB级的分布式内存中。这能帮助您在不修改模型的前提下,显著降低首Token时延(TTFT),提升服务吞吐量(TPS),并支持更长的上下文处理。
邀测说明
PolarKVCache功能目前处于灰度邀测阶段。如需试用或了解更多信息,请提交工单联系我们,我们将有专门的技术支持人员与您对接。
PolarKVCache能解决什么问题?
当您的LLM应用面临以下瓶颈时,PolarKVCache可以提供有效帮助:
高昂的推理延迟:在处理较长历史对话或长文档时,预填充(Prefill)阶段耗时过长,导致首个Token的响应缓慢,即TTFT高。
有限的并发能力:GPU显存被KVCache大量占用,限制了单张显卡能同时处理的请求数量,导致系统吞吐量(TPS)上不去。
上下文长度受限:受限于单机显存容量,无法处理如长文档问答、多轮复杂对话等需要超长上下文的任务。
核心优势
性能提升:通过KVCache复用和优化的数据传输,大幅降低推理延迟。
在Chatbot场景下,TTFT最高可降低26.8倍,吞吐量(TPS)提升62%。
在200K长文本的Coder场景下,TTFT最高可降低8.6倍。
扩展内存容量:突破单卡显存瓶颈,支持处理更长的上下文和更高的并发请求。单节点内存容量可从512 GB扩展至10 TB。
高效缓存共享:支持跨会话、跨用户的KVCache复用。例如:
在多轮对话中,系统无需重复计算历史对话的KVCache
对于相同的系统级提示(System Prompt),不同用户可直接共享已生成的KVCache,减少冗余计算。
无缝集成:可与vLLM、SGLang等主流推理框架平滑集成,您无需修改模型代码即可接入。
典型应用场景
实时高并发智能对话:如聊天机器人、AI助手、在线客服。PolarKVCache通过复用和低延迟访问,降低TTFT,提升响应速度。
长上下文处理任务:如长文档问答、代码生成、法律文书分析。通过将KVCache扩展至分布式内存,突破了单卡显存对输入序列长度的限制。
高并发推理服务:通过将KVCache移出GPU显存,可在单卡上承载更多并发请求,提升系统吞吐量和资源利用率。
性能表现
以下数据为特定测试环境下的结果,可供您评估参考。
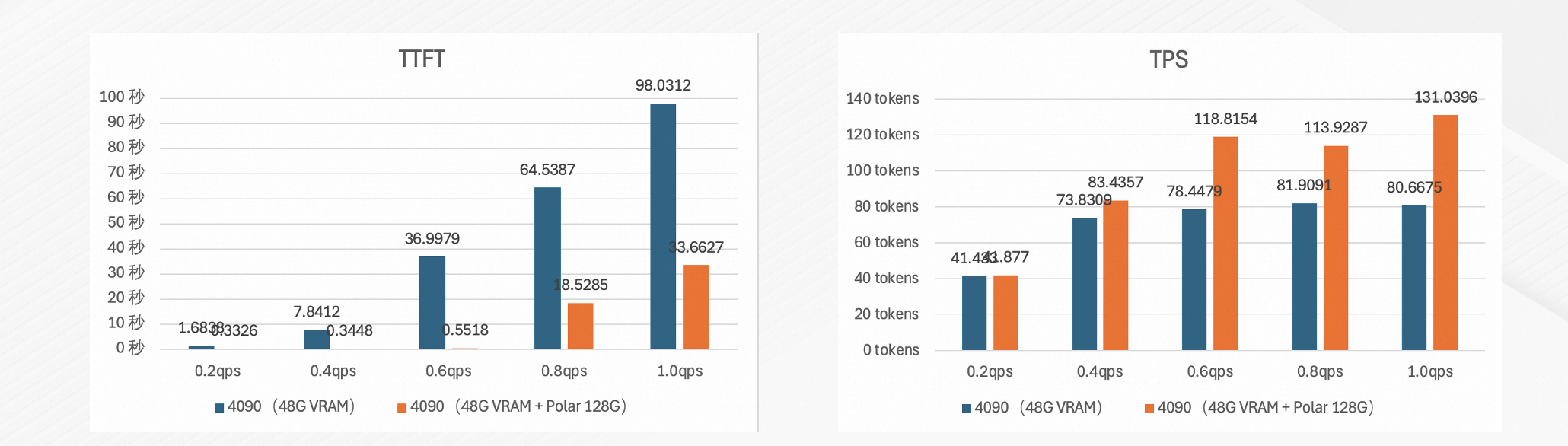
Chatbot(多轮对话)
测试目标:验证在长历史对话场景下,PolarKVCache对首Token时延(TTFT)和吞吐量(TPS)的优化效果。
测试环境:
硬件:NVIDIA 4090 48 GB。
模型:DeepSeek-R1-Distill-Qwen-32B-int8。
基准:vLLM 0.9.2,仅使用本地VRAM作为KVCache。
测试配置:历史上下文长度3000 tokens,进行10轮对话。
测试结果:
首Token时延(TTFT)降低26.8倍。
吞吐量(TPS)提升62%。
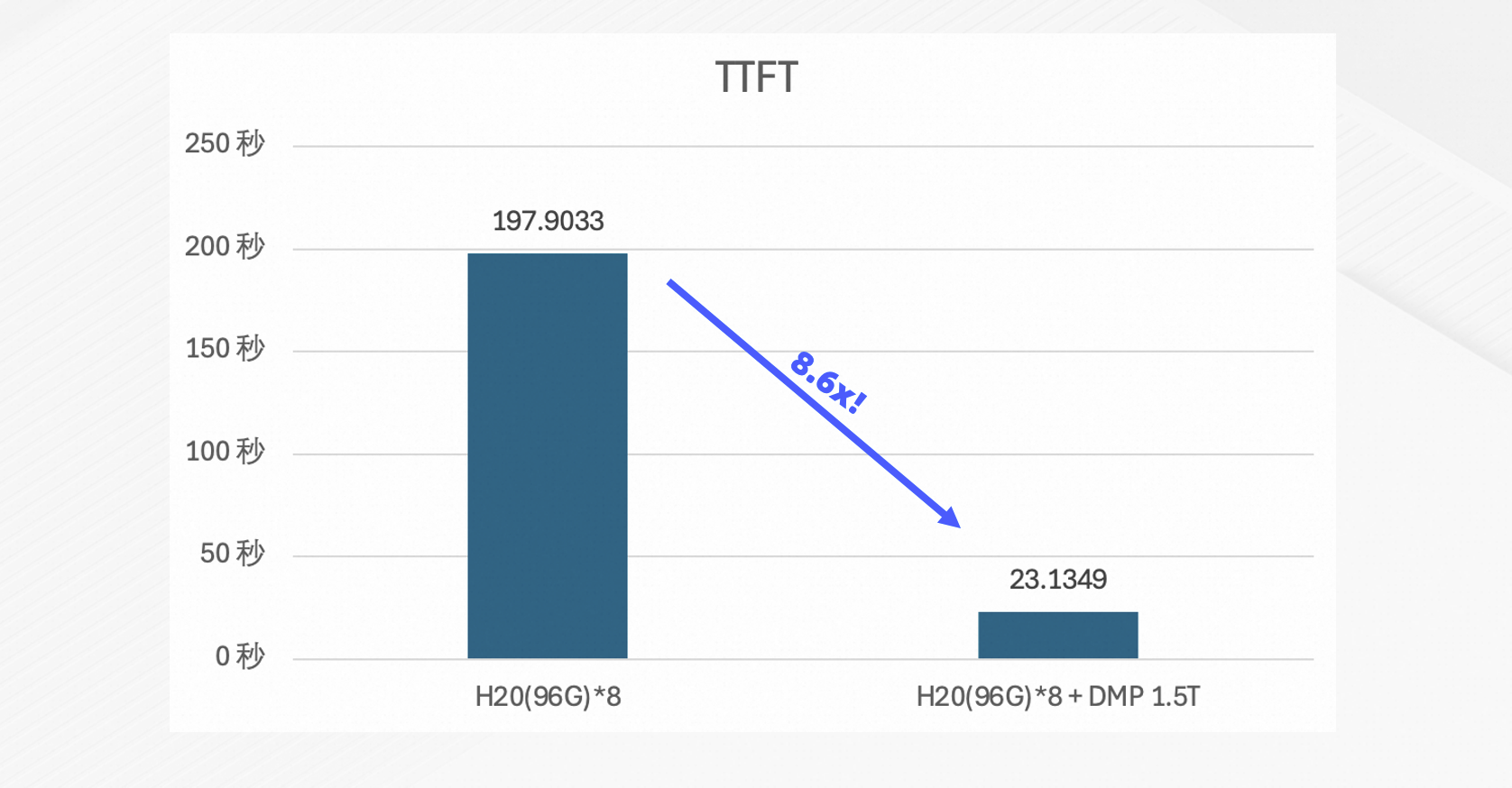
Coder(超长上下文代码生成)
测试目标:验证在处理超长上下文时,PolarKVCache对首Token时延(TTFT)的改善能力。
测试环境:
硬件:8 × NVIDIA H20 96 GB。
模型:Qwen3-Coder-480B-A35B-Instruct-FP8。
基准:vLLM 0.10.0,仅使用本地VRAM作为KVCache。
测试配置:历史上下文长度200K tokens,进行10轮对话。
测试结果:首Token时延(TTFT)降低8.6倍。
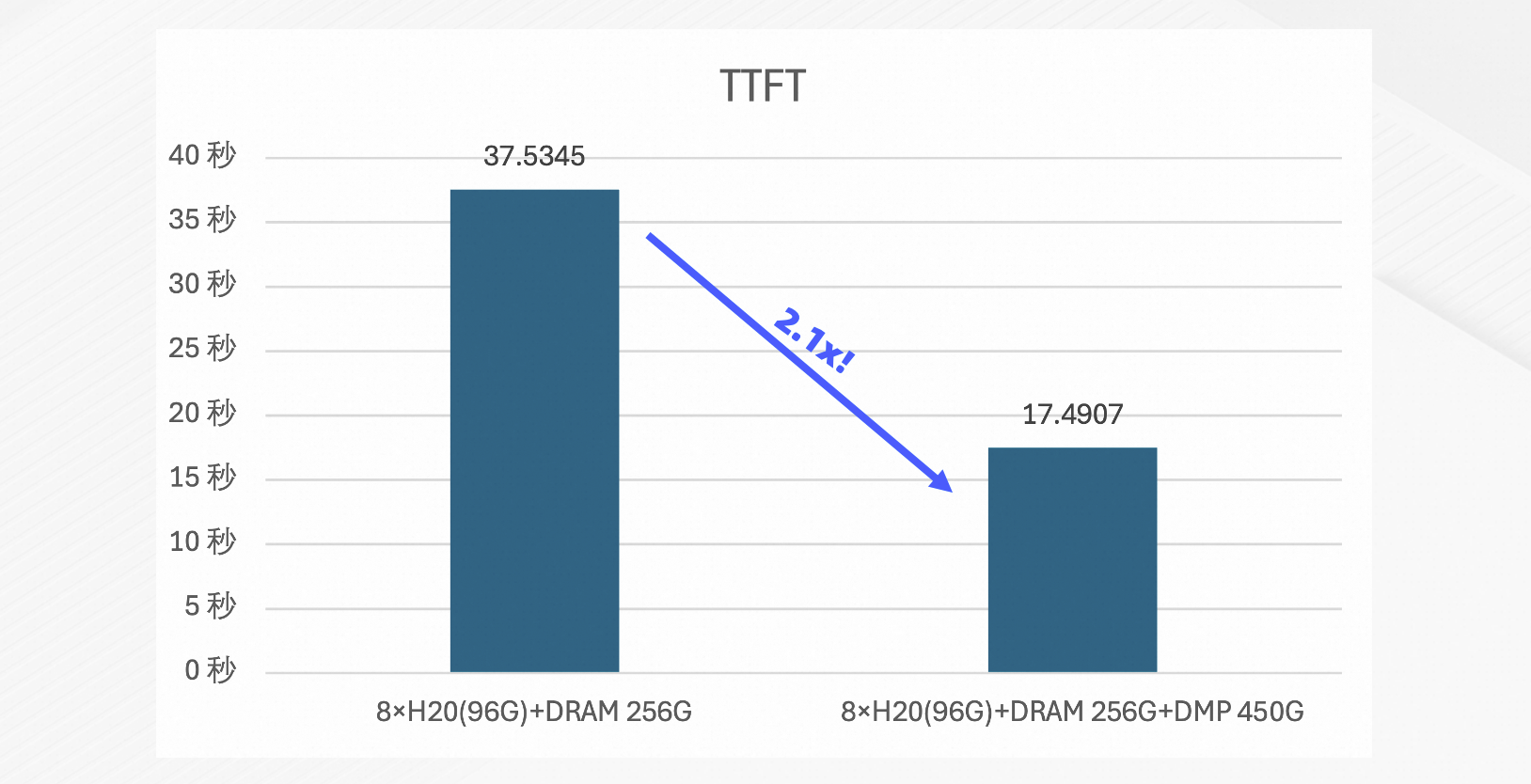
SGLang框架集成
测试目标:验证PolarKVCache在SGLang推理框架下的性能增益。
测试环境:
硬件:8 × NVIDIA H20 96 GB、44 GB HBM、256 GB 本地主机内存(DRAM)、450 GB 分布式内存池(DMP)。
模型:GLM-4.5。
基准:SGLang 0.5.0rc2,默认缓存策略。
测试配置:历史上下文长度10K tokens,10轮对话,QPS=4。
测试结果:首Token时延(TTFT)降低2.1倍。