
在进行大语言模型(LLM)推理时,您可能会面临因KVCache占用大量显存而导致的响应延迟高、并发处理能力不足等问题。PolarKVCache是专为解决此类场景设计的推理加速方案,它基于PolarDB分布式内存池(DMP),通过创新的架构将KVCache从有限的GPU显存扩展到TB级的分布式内存中。这能帮助您在不修改模型的前提下,显著降低首Token时延(TTFT),提升服务吞吐量(TPS),并支持更长的上下文处理。
PolarKVCache功能目前处于灰度阶段。如需使用该功能或对当前功能有任何疑问,请提交工单联系我们为您处理。
核心概念
关键术语 | 定义 | |
KVCache | 在大模型进行自回归生成时,为避免重复计算,系统会将先前计算过的键(Key)和值(Value)缓存起来,这份缓存即KVCache。它的体积与上下文长度和并发请求数成正比,是消耗GPU显存的主要部分,也是制约推理服务性能的瓶颈。 | |
推理阶段 | 预填充(Prefill) | 处理用户输入(Prompt)并计算初始KVCache的阶段。此阶段可并行计算,但计算量大,其耗时直接决定了响应速度,即首Token时间(TTFT)。 |
解码(Decode) | 基于已有的KVCache,逐个生成新词元(Token)的阶段。此阶段为串行计算,访存密集,其效率决定了后续内容的生成速度。 | |
首Token时延(TTFT) | Time To First Token,指从发送请求到接收到第一个输出词元的时间。这是衡量大模型服务响应速度的关键指标。 | |
工作原理
理解PolarKVCache的工作原理,有助于进行资源配置、性能调优和故障排查。其核心是基于计算存储分离,构建了多层级的KVCache存储体系。
产品架构
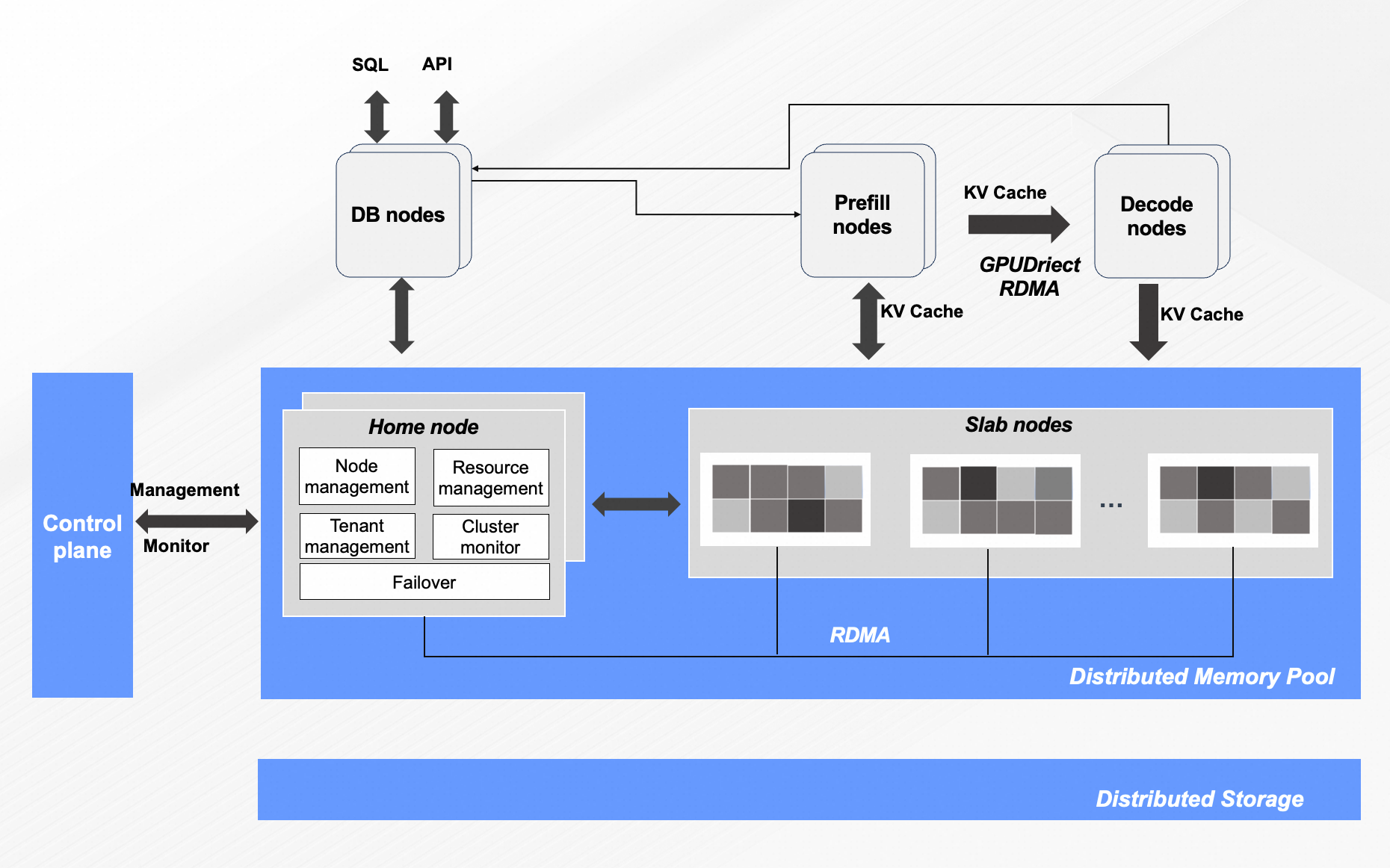
数据库节点(DB nodes):这是您与系统进行交互的主要入口,负责接收SQL或API请求。在该架构中,DB节点还充当智能调度员的角色,作为Prefill节点和Decode节点的亲和性调度节点。DB节点会根据任务类型(即初始的Prefill或后续的Decode),智能地将计算任务分派到最合适的GPU计算节点,以实现负载均衡和效率的最大化。
计算节点(Prefill/Decode nodes):真正执行AI计算任务的GPU节点,分别负责预填充和解码任务。
元数据管理服务器(PolarKVCache Meta Server):它并不存储实际的KVCache数据,而是维护这些数据的元数据。其精确记录了每个KVCache数据块的存储位置(例如,存储于哪个GPU节点的显存中,或位于下方的分布式内存池中),以及它们所属的推理会话。
分布式内存池 (PolarDB DMP):这是PolarKVCache实现内存容量扩展的核心技术,支持PB级内存缓存能力。它将多台服务器的内存资源虚拟化成一个统一的、可按需访问的巨大内存池。当GPU节点的本地显存(VRAM)和内存(DRAM)不足以存放海量的KVCache时,多余的数据就会被存放到这个分布式内存池中。这使得系统能够支持远超单机内存容量的KVCache,从而从容应对长文本和高并发场景。
共享存储层(Distributed Storage):这是整个PolarDB数据库的持久化数据底座,通常由PolarStore、云盘(如ESSD)或对象存储(OSS)等组成。虽然在实时推理过程中,KVCache主要在上述的内存层级间高速流动,但共享存储层为数据库本身的数据(例如模型权重、数据库表等)提供了最终的可靠性和持久化保障。
多层级KVCache存储体系
PolarKVCache将KVCache数据按访问频次和重要性,分布在四个不同成本和性能的层级中。
存储层级 | 介质 | 性能 | 容量 | 说明 |
L1 Cache | 本地GPU显存(VRAM) | 最高 | 最小 | 存放最高频访问的、当前正在计算的Token所对应的KVCache Page。 |
L2 Cache | 本地主机内存(DRAM) | 较高 | 较大 | 作为VRAM的扩展,用于换入/换出不那么活跃的KVCache Page。 |
L3 Cache | 分布式内存池(DMP) | 居中 | 巨大 | 核心存储层,提供PB级扩展能力,用于跨节点、跨会话共享KVCache。 |
L4 Cache | 分布式磁盘池 | 最低 | 海量 | 用于冷KVCache的持久化归档,成本最低。 |
核心技术解析
KVCache复用与共享
在多轮对话或多用户场景中,存在大量重复的上下文(如System Prompt、历史对话)。PolarKVCache能识别这些共享前缀,并让不同的请求直接复用已存在于分布式内存池中的KVCache,避免重复计算,从而降低TTFT。GPU Direct RDMA
为降低GPU节点与远程分布式内存池之间的数据传输延迟,PolarKVCache利用GPU Direct RDMA技术。该技术允许GPU绕过CPU,直接通过RDMA网卡读写远程内存,将数据传输延迟降至微秒级,性能接近访问本地内存。Layer-wise分层与流水线传输
在传输KVCache时,PolarKVCache并非整体传输,而是按Transformer模型的层(Layer)进行。它采用Scatter/Gather流水线操作,当上一层的KVCache正在通过RDMA网络传输时,计算单元可以同时开始计算下一层,从而掩盖部分网络延迟,提升端到端效率。CacheBlend智能缓存策略
CacheBlend是PolarKVCache的核心创新技术之一,采用了一种选择性重计算策略。该策略根据KVCache的访问模式和重要性,动态决定哪些页面应保留在高速缓存中,哪些可以被驱逐到下一级存储(在未来需要时可从DMP提取或直接重计算),从而在生成质量与推理效率之间实现平衡。
方案对比
对比维度 | 原生vLLM部署 | 集成PolarKVCache的vLLM部署 |
KVCache存储 | 仅使用GPU本地显存(VRAM),或少量换出到本地内存(DRAM)。 | 使用本地显存+本地内存+分布式内存池的多层级存储体系。 |
容量限制 | 容量受单节点GPU显存大小严格限制,通常为几十到上百GB。 | 容量可扩展至10 TB级别,支持超长上下文和高并发。 |
KVCache共享 | 无法在不同GPU节点间共享KVCache。 | 可在所有计算节点间实现全局KVCache共享与复用,避免重复计算。 |
架构 | 计算与KVCache存储紧密耦合在同一节点。 | 计算与存储解耦,支持独立扩展和灵活调度。 |
功能优势
性能提升:通过KVCache复用和优化的数据传输,大幅降低推理延迟。
在Chatbot场景下,TTFT最高可降低26.8倍,吞吐量(TPS)提升62%。
在200K长文本的Coder场景下,TTFT最高可降低8.6倍。
扩展内存容量:突破单卡显存瓶颈,支持处理更长的上下文和更高的并发请求。单节点内存容量可从512 GB扩展至10 TB。
高效缓存共享:支持跨会话、跨用户的KVCache复用。例如:
在多轮对话中,系统无需重复计算历史对话的KVCache
对于相同的系统级提示(System Prompt),不同用户可直接共享已生成的KVCache,减少冗余计算。
无缝集成:可与vLLM、SGLang等主流推理框架平滑集成,您无需修改模型代码即可接入。
应用场景
PolarKVCache适用于对响应延迟、并发处理能力和长上下文有高要求的场景。
实时高并发智能对话:如聊天机器人、AI助手、在线客服。PolarKVCache通过复用和低延迟访问,降低TTFT,提升响应速度。
长上下文处理任务:如长文档问答、代码生成、法律文书分析。通过将KVCache扩展至分布式内存,突破了单卡显存对输入序列长度的限制。
高并发推理服务:通过将KVCache移出GPU显存,可在单卡上承载更多并发请求,提升系统吞吐量和资源利用率。
性能测试报告
以下性能数据均在特定测试环境下得出,为评估PolarKVCache的收益提供参考。
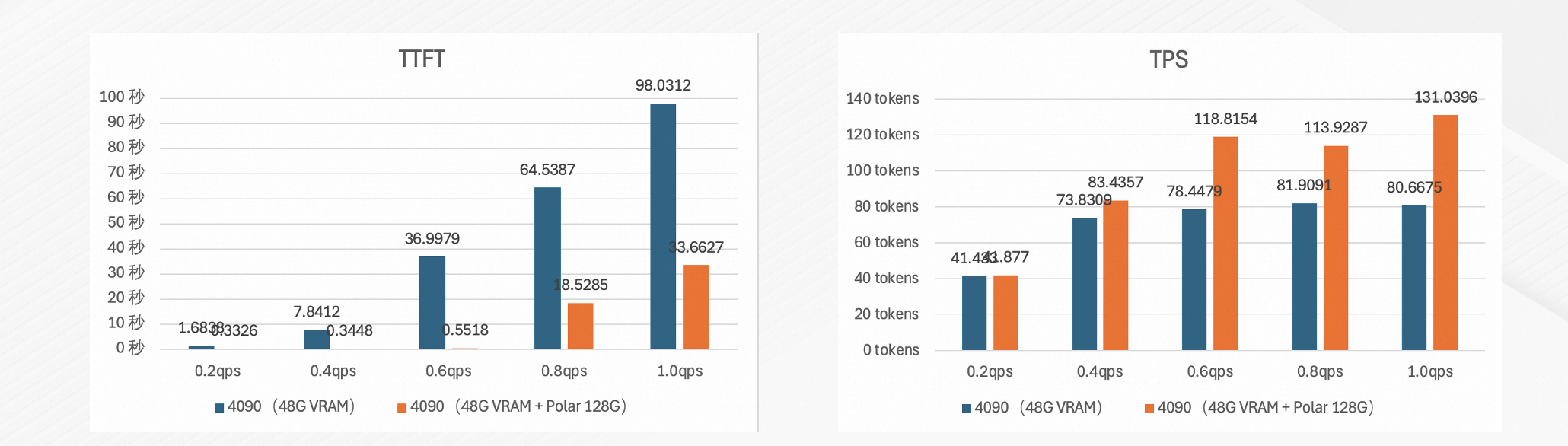
Chatbot(多轮对话)
测试目标:验证在长历史对话场景下,PolarKVCache对首Token时延(TTFT)和吞吐量(TPS)的优化效果。
测试环境:
硬件:NVIDIA 4090 48 GB。
模型:DeepSeek-R1-Distill-Qwen-32B-int8。
基准:vLLM 0.9.2,仅使用本地VRAM作为KVCache。
测试配置:历史上下文长度3000 tokens,进行10轮对话。
测试结果:
首Token时延(TTFT)降低26.8倍。
吞吐量(TPS)提升62%。
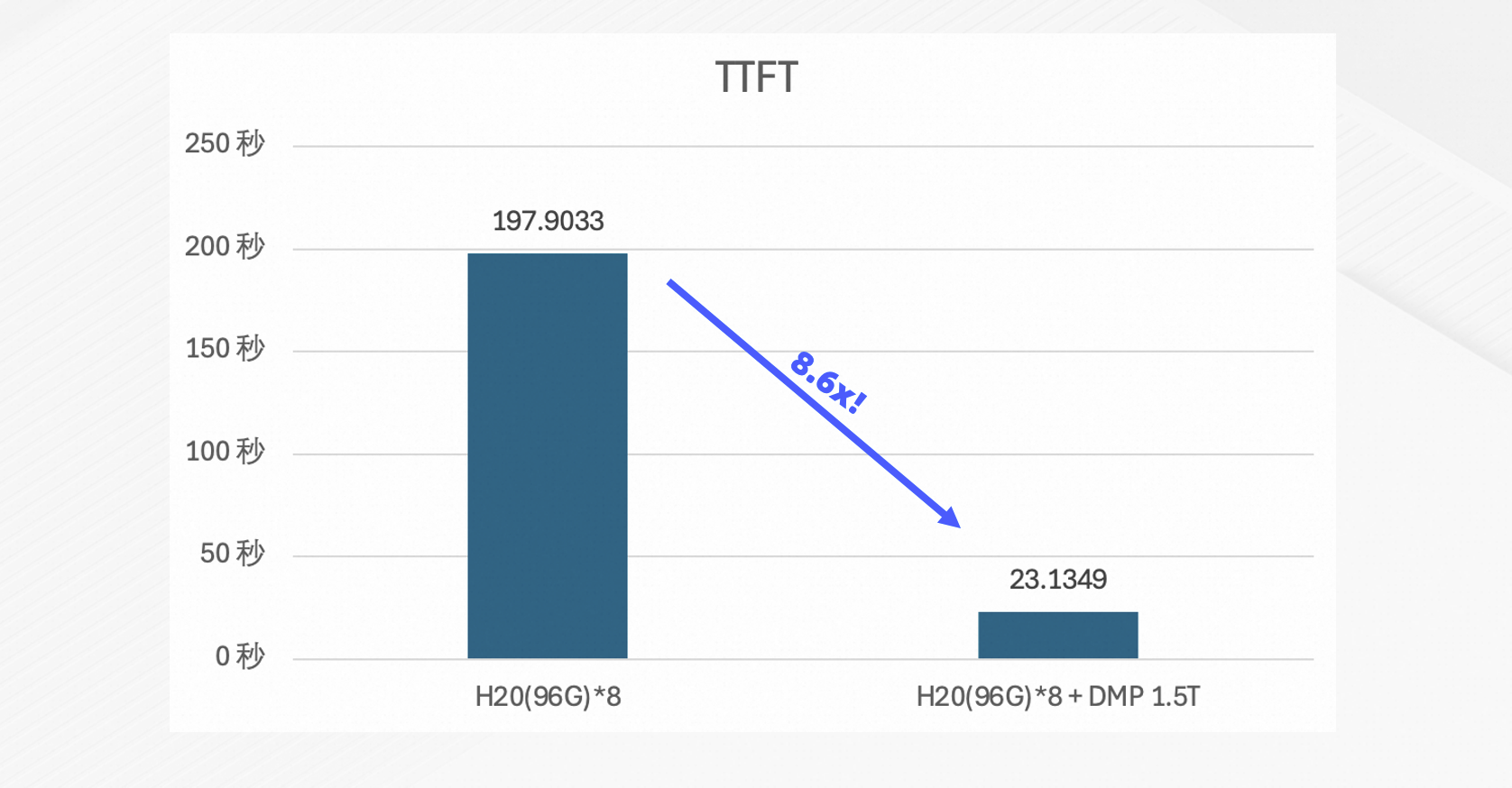
Coder(超长上下文代码生成)
测试目标:验证在处理超长上下文时,PolarKVCache对首Token时延(TTFT)的改善能力。
测试环境:
硬件:8 × NVIDIA H20 96 GB。
模型:Qwen3-Coder-480B-A35B-Instruct-FP8。
基准:vLLM 0.10.0,仅使用本地VRAM作为KVCache。
测试配置:历史上下文长度200K tokens,进行10轮对话。
测试结果:首Token时延(TTFT)降低8.6倍。
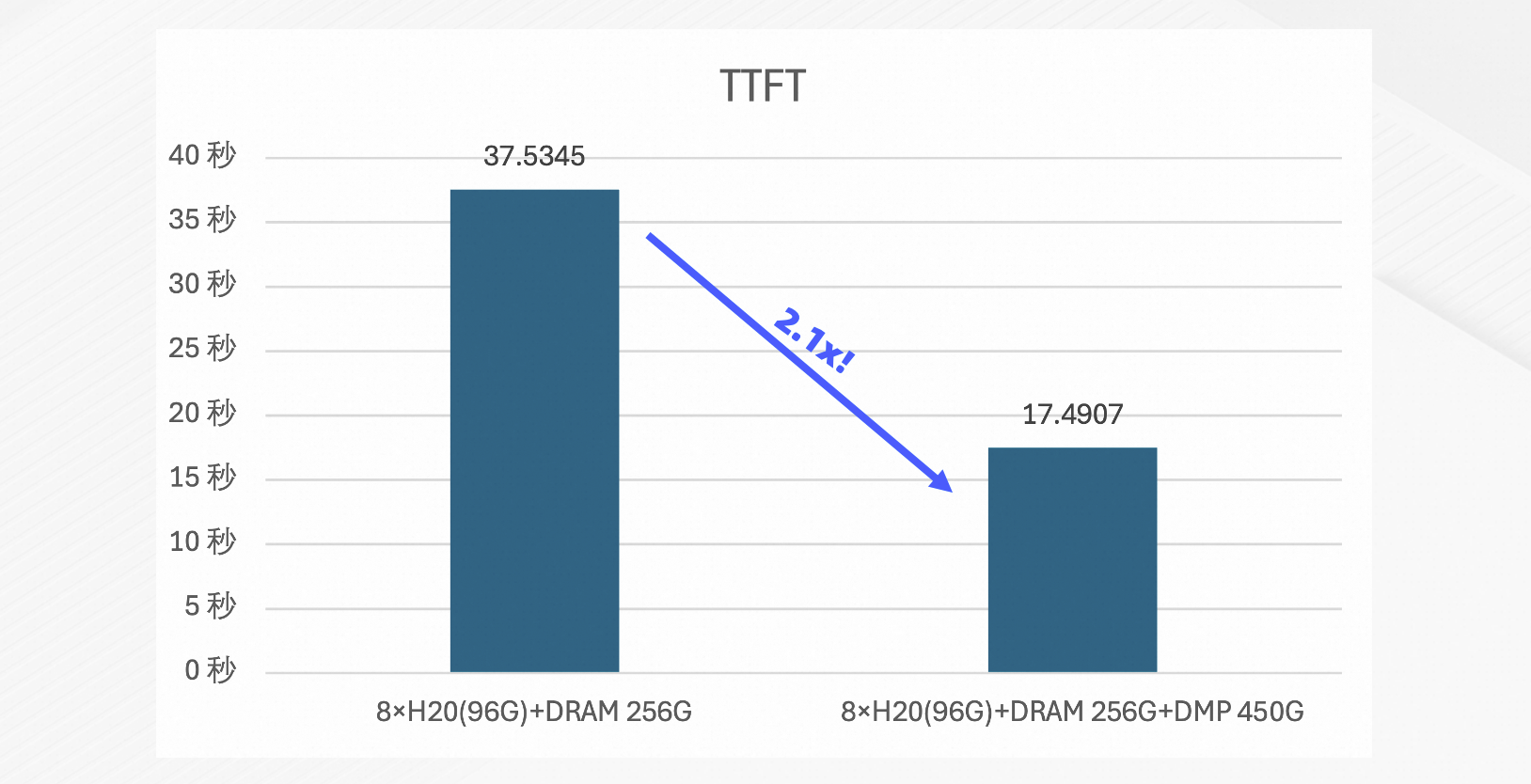
SGLang框架集成
测试目标:验证PolarKVCache在SGLang推理框架下的性能增益。
测试环境:
硬件:8 × NVIDIA H20 96 GB、44 GB HBM、256 GB 本地主机内存(DRAM)、450 GB 分布式内存池(DMP)。
模型:GLM-4.5。
基准:SGLang 0.5.0rc2,默认缓存策略。
测试配置:历史上下文长度10K tokens,10轮对话,QPS=4。
测试结果:首Token时延(TTFT)降低2.1倍。
计费说明
地域 | 价格(元/GB/月) |
中国内地 | 8.0 |
中国(香港) | 13.2 |
日本(东京) | 12.8 |
韩国 | 12.8 |
新加坡 | 15.2 |
马来西亚(吉隆坡) | 15.2 |
印度尼西亚(雅加达) | 14.0 |
菲律宾 | 15.2 |
泰国(曼谷) | 15.2 |
英国(伦敦) | 13.2 |
德国(法兰克福) | 13.6 |
美国(硅谷) | 12.4 |
美国(弗吉尼亚) | 10.4 |
华北2 阿里政务云1 | 16.0 |
适用范围
集群版本:MySQL 8.0.2,且内核小版本8.0.2.2.31及以上。
开始使用
(可选)创建PolarDB MySQL版集群
若您没有符合适用范围的集群,或现有的集群因业务原因不便进行更改,您可在PolarDB控制台上另行创建一个集群以体验PolarKVCache。
购买PolarKVCache
登录PolarDB控制台,在集群详情页中,单击左侧导航栏中的,并单击创建KVCache。
在应用购买页面中,请根据您的需求选择适合的配置:
配置项
说明
付费类型
仅支持包年包月,预付费模式。在创建应用时,您需选择固定规格的资源,并预先支付应用的费用。购买周期越长,所享受的折扣也越大。该模式一般适用于业务需求长期稳定的场景。
引擎
固定为PolarDB。
地域
选择应用所在的地域和可用区。
说明应用购买完成后,不支持更改地域。
应用需与PolarDB MySQL版集群位于同一地域。因此,请选择与该集群相同的地域。
建议将应用与需要连接的ECS创建在同一地域,否则它们将无法通过内网(私网)实现互通,只能通过外网(公网)进行通信,这将无法充分发挥最佳性能。
架构
选择为KVCache。
源PolarDB集群
选择需要创建应用的PolarDB集群。
KVCache空间
选择您需要购买的KVCache容量,默认100 GB。
网络类型
固定为专有网络。
VPC网络
配置VPC网络,建议选择与PolarDB MySQL版集群相同的VPC网络,以发挥最佳网络性能。
说明如果已有的VPC无法满足您的要求,您可以自行创建/删除专有网络与交换机。
可用区和交换机
配置VPC网络的交换机,建议选择与PolarDB MySQL版集群的主可用区相同的交换机,以发挥最佳网络性能。
说明如果已有的交换机无法满足您的要求,您可以自行创建/删除专有网络与交换机。
购买数量
选择需要购买的应用数量。
说明仅付费类型为包年包月时,支持配置。
购买时长
选择应用的购买时长。
说明仅付费类型为包年包月时,支持配置。
自动续费
配置是否开启自动续费。为避免因忘记续费而导致业务中断,建议您开启自动续费。
说明仅付费类型为包年包月时,支持配置。
购买成功后,请返回集群的AI应用页面,即可查看新创建的应用。
说明系统需要3~5分钟创建应用,请耐心等待。