列存索引中TopK算子的实现一文中介绍了PolarDB IMCI如何利用统计信息在运行时进行剪枝,以提高TopK算法的查询性能。本文将进一步全面介绍PolarDB IMCI的查询剪枝(pruning or data skipping)技术。
背景与作用
在HTAP场景中,PolarDB IMCI(In Memory Column Index)选择列式Heap Table作为底层主要存储架构来支持实时更新,SQL Server以及Oracle的Column Index也采用了相同的存储架构。然而,Heap Table架构虽然更新速度快,但在小范围的扫描上表现并不理想,很多时候需要进行全表扫描。为了尽量减少全表扫描的问题,SQL Server主要通过Min-Max、分区以及聚簇索引来降低扫描数据量;Oracle是全内存的列索引,其主要通过Min-Max以及metadata dictionary来减少全表扫描。PolarDB IMCI属于列存表的模式,数据支持落盘,实现了更加多样化的方法来优化全表数据扫描。
技术选型 | 特点 | 示例 |
列式HeapTable |
|
|
列式LSM |
|
|
PolarDB IMCI按RowGroup组织数据,每个RowGroup包含64K行。对于每一列的列索引,其存储都采用的是无序且追加写的格式。因此,IMCI无法像InnoDB的普通有序索引那样,可以精确地过滤掉不符合要求的数据。在读取DataPack时,需要从磁盘中加载进内存并解压缩,然后遍历DataPack中的所有记录,利用过滤条件筛选出符合条件的记录。对于大表而言,这些扫描任务的代价很大,并会对LRU cache造成一定程度的污染,导致整体查询延迟升高,QPS大幅降低。
为了解决大表扫描代价过高的问题,PolarDB IMCI引入了查询剪枝技术。该技术可以在过滤数据时,提前过滤掉不需要访问的DataPack,从而减少数据访问量,提高查询效率。具体实现方式是通过访问分区信息和统计信息,结合特定的过滤条件,在查询之前就把不符合条件的数据剪去。这样就可以减少对存储的扫描次数,进而减少数据传输和计算消耗。该技术不仅适用于单表数据的查询,也适用于多表连接查询,并能大幅度提升PolarDB IMCI的查询性能。
基本原理与方法
分区信息剪枝
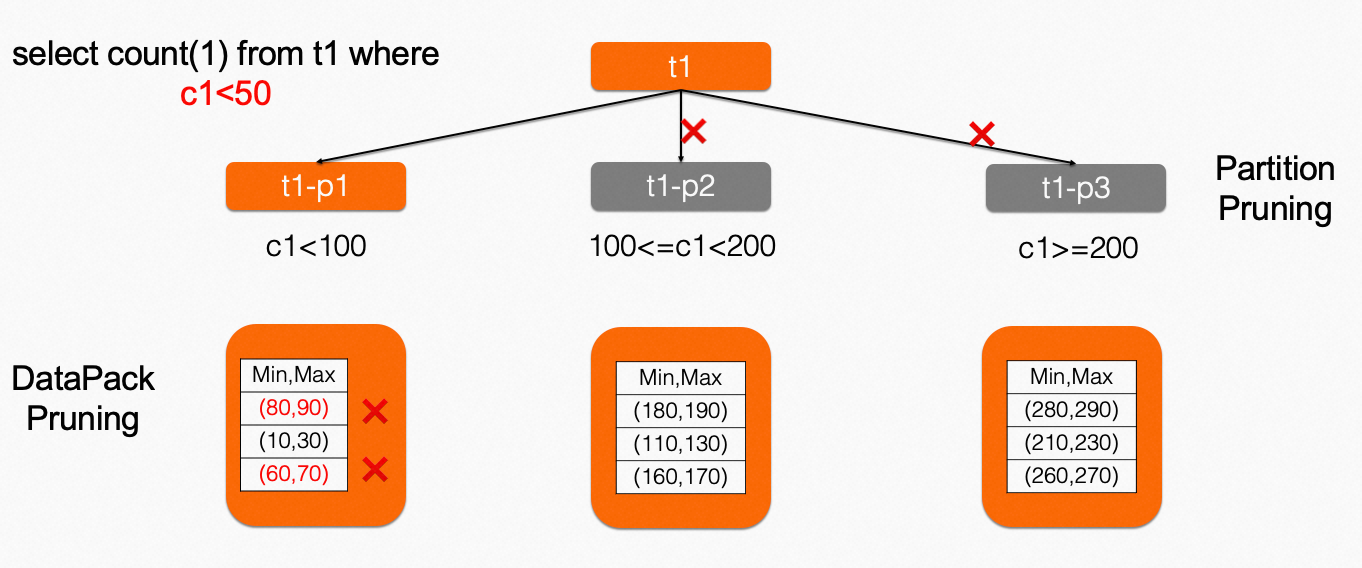
IMCI的分区剪枝技术是指在查询时根据分区键的条件来过滤不需要查询的分区,从而减少查询的数据量和提高查询效率的技术。IMCI支持的分区类型包括RANGE、LIST、HASH三种。其中,RANGE和LIST分区会把数据表分成若干个区间或列表,HASH分区会将数据散列到不同的分区。在使用分区剪枝技术时,需要使用符合分区条件的查询语句,并将分区键作为查询条件进行查询。
例如,假设有一个订单表orders,根据订单日期分为12个分区,通过以下查询语句可查询某一天的订单:
SELECT * FROM orders WHERE order_date = '2022-01-01';IMCI在执行该查询时,会根据订单表的分区order_date,找到符合条件的分区,并只查询该分区的数据,从而减少了查询的数据量和提高了查询效率。同时,也支持JOIN列的等价关系进行推导,从而更加充分的进行分区剪枝。例如关系R,S的分区键均为a,查询select count(1) from R,S where R.a = S.a and R.a > 10,利用R.a = S.a以及R.a > 10可推导出S.a > 10,从而用来做关系S的分区剪枝。
不同分区类型的剪枝算法描述如下:
对于RANGE分区,其不同分区的分界点有序存储在一个数组里,因此直接使用二分搜索法;
对于LIST分区,会将所有分区的list值及其对应的分区ID组成tuple <value, part_id>,按value有序存储,也是按照二分搜索法寻找命中分区;
对于HASH分区,则枚举可能的取值进行hash,计算可能落在哪些分区,只能用于整型字段并且需要枚举的数量较少。
此处以分区Pruning算法(以一级分区)为例:

实际使用中,需要根据具体的数据量和查询需求来选择适合的分区类型和分区键,以达到最优的查询性能。
统计信息剪枝
IMCI利用DataPack上的统计信息来跳过不需要访问的pack,类似于Clickhouse中的skipping index以及infobright里的knowledge grid,在IMCI中称为Pruner(粗糙索引),Pruner可以帮助IMCI优化查询性能。其基本原理是在查询时利用统计信息与过滤条件进行剪枝,判断是否需要扫描某个pack。由于统计信息内存占用较少,可以常驻内存。如果剪枝成功,则可以减少IO次数和条件判断次数,从而提升查询性能。
对于一个DataPack来说,被Pruner过滤后有三种可能的结果:Accept(AC)、Reject(RE)以及Partial Accept(PA)。被Accept的DataPack,无需对每条记录进行过滤,减少了计算开销;被Reject的DataPack,与本次查询无关,无需加载进内存,同时减少IO与计算开销,避免LRU Cache污染;被Partial Accept的DataPack,则需要进一步扫描每条记录来筛选出符合条件的记录。
IMCI的Pruner有minmax和Bloom filter两种类型,分别适用于不同的场景。此外,IMCI还针对Nullable列进行了优化,在查询时Pruner可以跳过包含Null值的DataPack,进一步提升查询速度。
Minmax
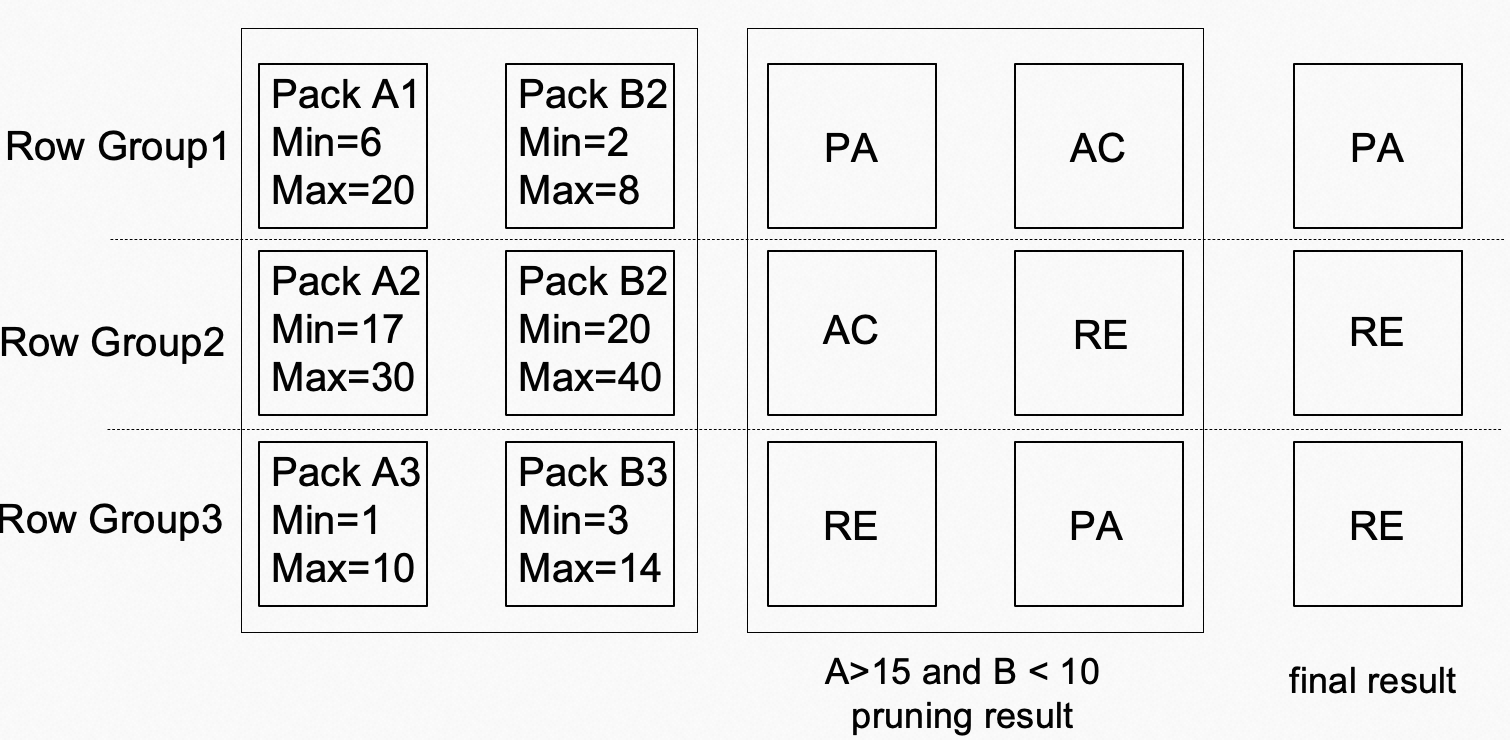
minmax索引是针对大型数据集的一种增强型索引技术。它通过存储每个数据块的最小值和最大值来为数据集构建索引,从而提供快速和高效的数据检索。minmax索引适用于数据集中、数值连续的数据,例如时间戳或实数值。它将数据集拆分成块,然后计算每个块的最小值和最大值,存储在索引中。当进行数据查询时,minmax索引可以根据查询范围的最小值和最大值快速定位数据块,从而减少对不相关数据的访问。以下图为例,A、B列包含3个DataPack,条件A>15 and B<10结合minmax索引,最终RowGroup2与RowGroup3可跳过,只需访问RowGroup1,从而减少了2/3的扫描代价。
minmax索引的优点是它可以在非常快的时间内处理非常大的数据集。它能够减少为了处理查询而必须扫描的数据量,因为它只需要处理与查询范围相关的数据块。另外,minmax索引有助于减少存储索引所需的空间,因为它只需要存储每个块的最小值和最大值,而不是所有数据的索引。
Bloom filter
Bloom filter是一种常用的概率型数据结构,用于判断一个元素是否属于某个集合中。它使用一个比特数组和一组哈希函数来存储和搜索元素。当一个元素被添加到过滤器中时,哈希函数将元素映射到比特数组中的几个位置,并将相应的比特设置为1。当检查一个元素是否在过滤器中时,哈希函数再次应用于该元素,如果所有相应的比特位都是1,则该元素可能在集合中。然而,如果任何一个相应的比特位为0,则该元素肯定不在集合中。Bloom filter是具有空间效率的表示方法,可以快速确定一个元素在不在集合中,但它们可能会产生误报(false positives)- 查询一个不在集合中的元素可能会错误地指示它在集合中。
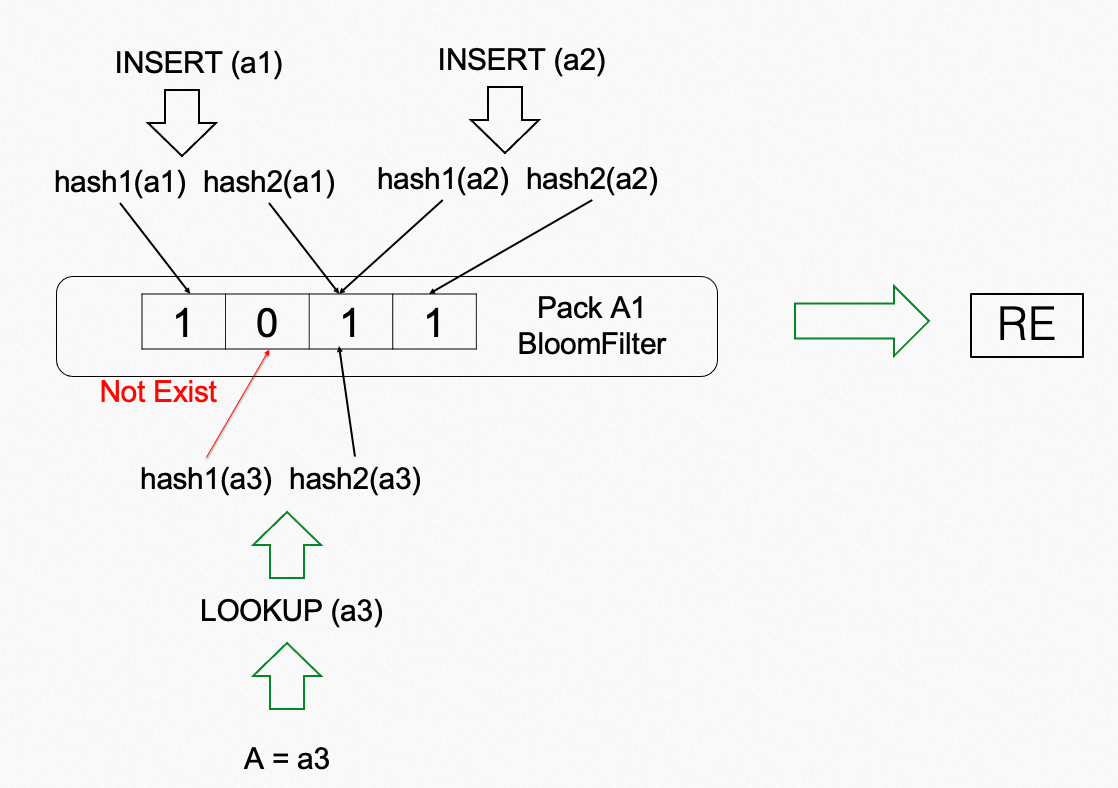
Bloom filter的优点是高效、空间效率高、可扩展性强和误判率可控。这些优点使Bloom filter成为处理大规模数据集中的元素存在性问题的一种非常有用的数据结构。
Bloom filter与minmax也可以结合使用,IMCI会根据两者的综合结果来判断是否要跳过某个数据块。
Nullable列优化
由于Null值处理逻辑比较特殊,数据库索引一般针对Null值的列支持不太好。不同数据库对Nullable列的处理不尽相同。
PolarDB IMCI针对Nullable列进行了优化,使得Null值对查询的性能影响大大减少。在PolarDB的用户使用场景中,经常出现包含Null值列的情况,如果让现有用户使用默认值填充Null值,不仅需要通过DDL花费大量时间更改表的结构,可能还需要更改现有业务的查询SQL。PolarDB IMCI支持对Null值的列构建minmax以及Bloom filter索引,不仅支持IS Null/IS NOT Null谓词,还支持>、<、=等其他谓词的查询。
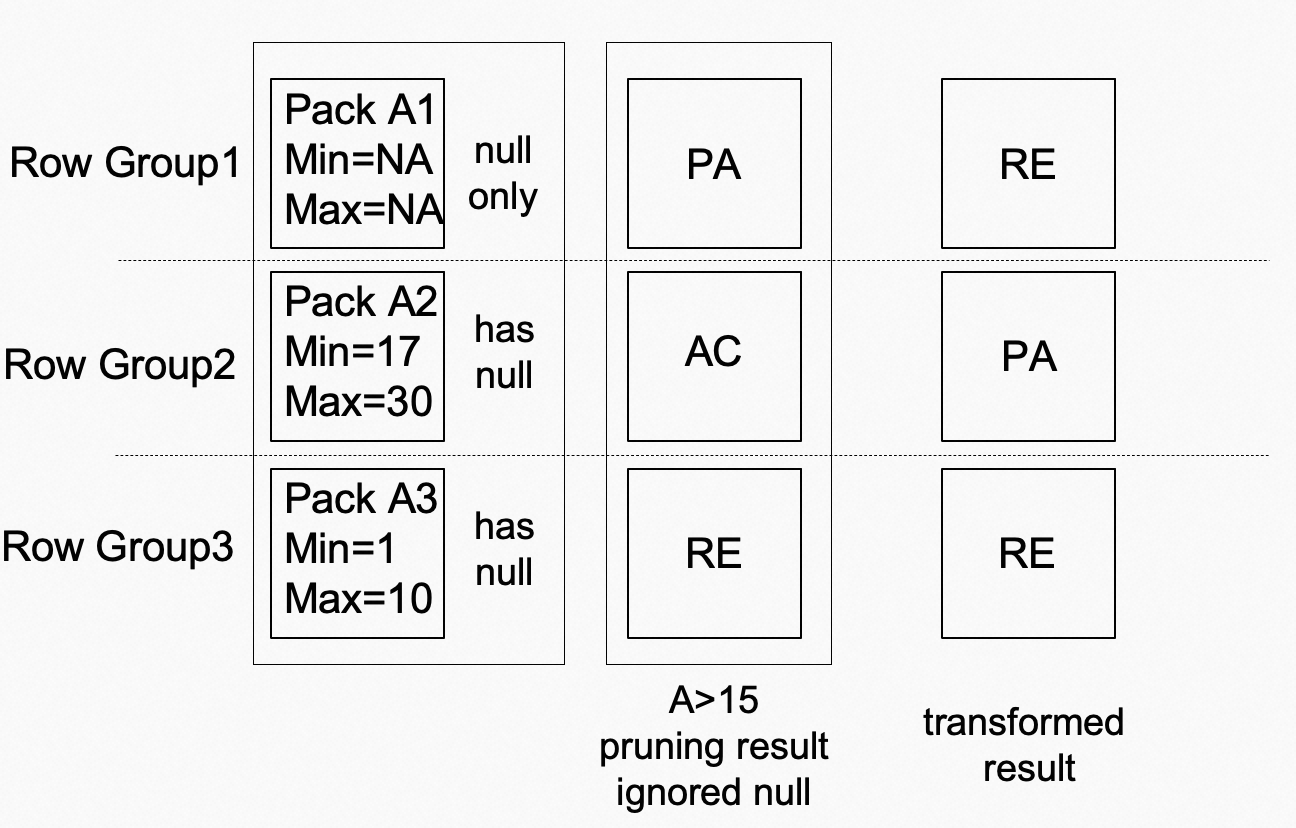
对于pack中包含Null值的情况,构建pruner时,跳过该值。例如pack中有[1, 2, 3, null ]四条数据,那么min=1,max=3。在查询时,先按照没有Null值的逻辑进行处理,然后根据处理的结果,结合是否包含Null值,对结果进行转化。如上图所示,Pack A1中只有Null,而Pack A2与A3均包含部分Null,此时条件A>15在不考虑Null的情况下先得出[PA, AC, RE] 这样的结果(由于A1中没有minmax,因此无法过滤),然后再根据每个pack包含Null值的情况,将结果转成[RE, PA, RE],最终可以剪枝掉其中的两个DataPack,从而提升查询性能。
Runtime filter
Runtime filter是一种查询优化技术,它是在查询执行期间动态生成的过滤器。在查询执行过程中,Runtime filter可以根据已经扫描到的数据值或者其他信息,过滤掉不需要的数据,从而减少查询的数据量,提高查询性能。常见的Runtime filter有Bloom Filter和Min-Max Filter等。它们可以用于多种查询场景,如join、group by、order by等。
例如,PolarDB IMCI对TopK(order by+limit)进行了优化,可以利用Topk算子构建的Self-sharpening Input Filter,结合存储层数据块上的minmax索引进行pruning,从而加快topk性能,具体实现原理请参见计算下推 。
此外,Runtime filter可用于Hash Join的加速。以SQLSELECT * FROM sales JOIN items ON sales.item_id = items.id WHERE items.price > 1000为例,sales表是事实表,items是维度表,维度表较小,通过条件price>1000可以进一步减少返回的记录数。在执行join时,可以依据满足条件的item_id结果集建立filter,例如满足条件的min,max分别是1,100,可以生成id > 1 and id < 100的过滤表达式,也可以生成ID的in(id1,id2,id3 ...)表达式。Runtime filter传递给左表,左表在扫描记录进行probe时,可以通过filter提前过滤不满足条件的记录,减少probe的次数。对于字符串类型,还可以为右表结果集建立Bloom filter来做提前过滤,当然本身Bloom filter也有代价,不太适合结果集比较大的场景。更进一步,如果左表列上有粗糙索引,可以依据filter来做过滤,减少数据块扫描。在MPP场景,Runtime filter也能发挥作用,可以有效减少shuffle的数据量。

位图索引
位图索引在行存中也有使用,例如Oracle就提供位图索引的功能,比较适合于列的基数较少的场景。具体来说,就是为每个列值存储所在行的位置信息,每个位置信息只需要一个bit位标识值存在与否。执行查询过滤时,只需要根据列值拿到位图信息即可定位行的位置,对于多个列组合的AND/OR等谓词尤其适合。一般来说,B+tree索引比较适合于高基数列,方便快速过滤定位;位图索引则正好与B+tree互补。B+tree索引适合搜索模式固定的场景,对于谓词OR不是很友好,位图索引在这个场景也能有不错的效果。
位图索引的相对于B+tree索引的另外一个优势是,对于低基数列,存储空间非常小。如下图,为表的性别列和职级建立了位图索引,表中只有5行数据,那么一个列值对应的位图只需要5个bit即可。相对于传统的B+tree索引,位图索引所需要的存储空间非常少,具体大小与基数和总的行数相关。对于全局位图索引来说,由于位图索引的特征,使得修改任何一行,都需要维护位图索引,需要将整个表锁住,因此代价非常大,适合于读多写少的场景。
PolarDB IMCI当前支持datapack粒度的位图索引,可以通过位图索引可以直接返回所需数据的行号,从而可以有效减少DataPack的访问。

优势与适用场景
PolarDB IMCI的多种查询剪枝技术是相辅相成的,可以结合使用,用户需要根据自己的数据特征以及查询场景,选择使用相应的方法。IMCI的查询剪枝技术都需要数据具有一定的分布特征,局部性越强,pruning效果越好,但现实场景可能并不是很直观,这时候需要仔细设计。
分区剪枝:该功能需要用户选择合适的分区键构建分区表。优点是数据预先按分区键分布,通常均具有较好的过滤效果,如果用户大部分查询条件均包含分区键,并且还有按分区管理数据生命周期的需求,分区表pruning是个不错的选择,可根据需要建立一级或二级分区。
minmax:一般需要该列数据分布有较好的局部性,且支持范围查询。例如时间戳数据类型,一般天然是有序插入的,这种字段类型构建minmax一般具有较好的应用价值。
Bloom filter:用于等值条件以及IN条件过滤,对于过滤性较强的等值条件,一般具有比较好的过滤效果。例如各种随机生成的ID,通常单个ID仅对应少数记录,包含这种ID的等值过滤条件具有较好的pruning效果。
位图索引:适用于单一条件过滤性差、组合条件过滤性强,或者查询无需物化数据的场景(例如
select count(*) from t where xxx)。
局限性与解决方案
IMCI的查询各项剪枝技术均具有一定局限性,实际场景需要结合多种技术来提升其查询剪枝能力。
分区剪枝:缺点是对于存量数据来说,是一个比较昂贵的DDL操作,另外查询条件必须包含分区键才能生效。对于存量数据来说,可以找个空闲时间进行变更操作,而如果查询条件很多不包含分区键,则建议采用其他优化手段。
统计信息剪枝:由于写入时不排序,统计信息对于数据分布离散均匀的场景效果比较差,有以下优化方案:
减小pack大小。对于minmax与Bloom filter来说,更小的pack意味着更细粒度的索引,通常也具有更好的剪枝效果。IMCI支持调整表的列索引pack大小,然而减小pack大小可能也会导致内存占用的增加。
数据排序。对于数据分布比较随机的情况,可以考虑使用PolarDB IMCI的排序键功能,这样的数据具有良好的局部性,非常有利于统计信息剪枝。
关闭pruner。和其他任何索引一样,统计信息剪枝不一定有效果,但存在一定的计算与内存开销,对于Bloom filter还存在一定的IO开销,此时可以查询时关闭pruner。
性能测试
本小节测试了PolarDB HTAP的粗糙索引和位图索引的性能,粗糙索引主要覆盖了min/max和Bloom filter两种。测试数据集采用了TPCH的100 GB数据,主要测试了几种典型的查询场景,包括点查,范围查询等,数据类型主要涉及到数值类型和字符串类型。
测试SQL
轻量级索引是否有效果主要取决于数据分布和查询类型。为了体现轻量级索引带来的作用,人为构造了几条以Scan算子为主的SQL,对比使用粗糙索引(pruner)和位图索引(bitmap-index)加速前后的效果。测试环境采用了全内存场景,并发度设置为1,在有IO的场景下,索引的加速效果会更明显。
Q1:select count(*) from partsupp where ps_suppkey = 41164;
Q2:select count(*) from partsupp where ps_suppkey in (41164,58321);
Q3:select count(*) from partsupp where ps_suppkey between 40000 and 50000;
Q4:select count(*) from orders where o_clerk = 'Clerk#000068170';
Q5:select count(*) from orders where o_clerk in ('Clerk#000068170', 'Clerk#000087784');
Q6:select count(*) from customer where c_mktsegment = 'AUTOMOBILE';
Q7:select count(*) from customer where c_mktsegment in ('AUTOMOBILE','FURNITURE','BUILDING');
Q8:select count(*) from customer where c_mktsegment = 'AUTOMOBILE' or c_phone = '18-338-906-3675';
Q9:select count(*) from customer where c_mktsegment = 'AUTOMOBILE' and c_phone = '18-338-906-3675';测试结果
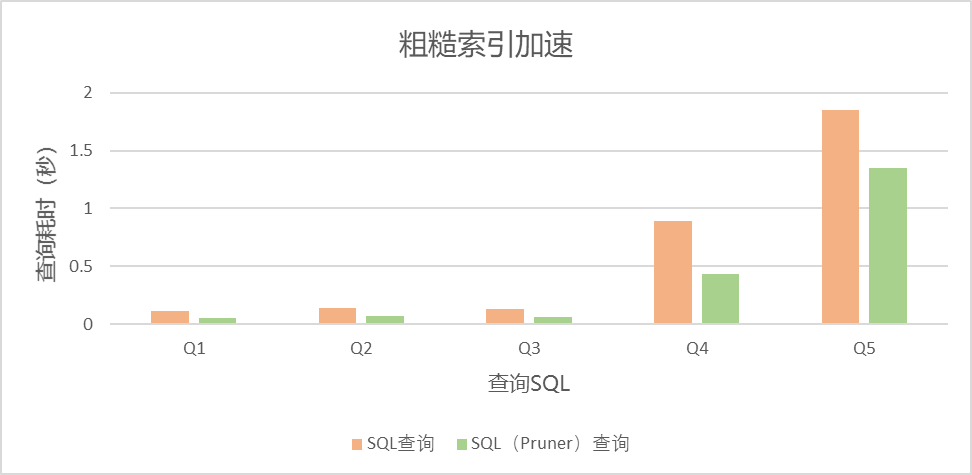
Q1到Q5主要验证了粗糙索引(Pruner)的加速效果,partsupp表和orders表的ps_suppkey列,以及o_clerk列分别可以利用min/max索引和Bloom filter索引进行加速,从加速比来看,也基本与过滤的块成比例。
查询时间如下:
SQL
查询耗时(单位:秒)
SQL查询耗时(单位:秒)
SQL(Pruner)查询耗时(单位:秒)
Q1
0.11
0.05
Q2
0.14
0.07
Q3
0.13
0.06
Q4
0.89
0.43
Q5
1.85
1.35
查询时间对比图如下:
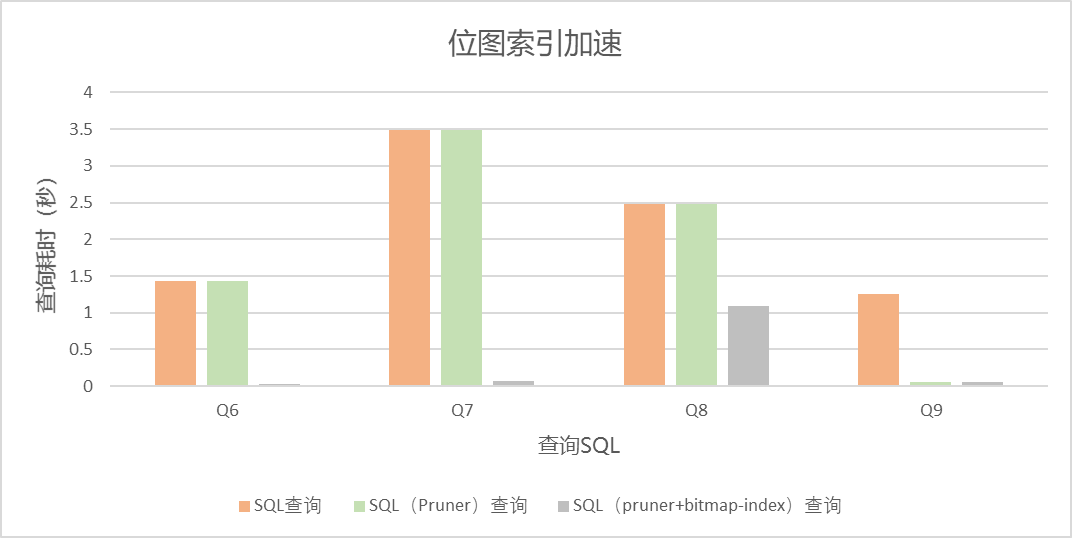
Q6到Q9主要验证了位图索引的加速效果,customer的c_mktsegment列值在各个数据块分布均匀,因此仅通过pruner并不能起到加速效果,通过与位图索引叠加使用,才能提升这种SQL的执行效率。
查询时间如下:
SQL
查询耗时(单位:秒)
SQL查询耗时(单位:秒)
SQL(Pruner)查询耗时(单位:秒)
SQL(pruner+bitmap-index)查询耗时(单位:秒)
Q6
1.43
1.43
0.03
Q7
3.49
3.49
0.07
Q8
2.48
2.48
1.09
Q9
1.25
0.05
0.05
查询时间对比图如下: