
本文介绍了列存索引数据的排序流程、使用方法以及构建和查询有序列存索引数据的时间对比等内容。
简介
列存索引数据是按照行组进行组织,默认包含64K行。每个行组中不同的列会各自打包形成列数据块,列数据块按照行存原始数据的主键次序并行构建,更新数据则按照追加次序写入,总体上是无序的。
列存索引支持粗糙索引,每一个列数据块的元数据包含全部数据的最小值和最大值等信息。查询数据时,正常情况下需要遍历指定列的所有列数据块。开启Pruner后,会根据查询条件与元数据信息将所有列数据块分为相关、可能相关和不相关三大类。读取数据时只考虑相关和可能相关的列数据块。列数据块有不同次序的组织方式,进而会产生不同组合的列数据块集合,Pruner也会有不同的过滤效果,因此,用户可以根据查询条件来修改列数据块的排列顺序,以提高查询性能。
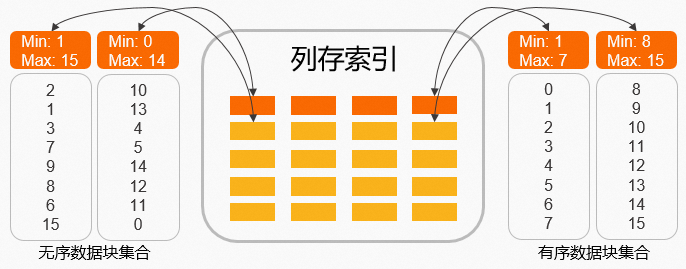 如上图所示,当执行以下SQL语句时,针对无序列数据块集合,需要加载所有列数据块并进行处理。而有序数据块集合则可以通过每个列数据块内存中元数据的最大值和最小值等信息过滤掉第一个列数据块,只需要针对第二个列数据块进行处理即可。
如上图所示,当执行以下SQL语句时,针对无序列数据块集合,需要加载所有列数据块并进行处理。而有序数据块集合则可以通过每个列数据块内存中元数据的最大值和最小值等信息过滤掉第一个列数据块,只需要针对第二个列数据块进行处理即可。
SELECT * FROM t WHERE c >= 8;适用范围
开启新增列存索引时数据排序功能,企业版集群版本需满足以下条件之一:
PolarDB MySQL版8.0.1版本且修订版本为8.0.1.1.32及以上。
PolarDB MySQL版8.0.2版本且修订版本为8.0.2.2.12及以上。
增量数据排序功能,企业版集群版本需满足以下条件之一:
PolarDB MySQL版8.0.1版本且修订版本为8.0.1.1.39.1及以上。
PolarDB MySQL版8.0.2版本且修订版本为8.0.2.2.20.1及以上。
您可以通过查询版本号来确认集群版本。
注意事项
不支持将BLOB、JSON和GEOMETRY类型的数据作为排序键。
增量数据排序功能不支持无符号整型和Decimal类型的排序键。
增量排序只按照排序键的第一列维护有序性。
增量数据排序会占用一定的资源。因此,当集群的写入负载较高时,为了让出更多的资源供前台写入数据,增量数据排序的速度会变慢。
排序流程
新建列存索引时数据排序流程
列存索引数据排序总体上实现与DDL过程中二级索引的排序算法类似,支持单线程与多线程排序。单线程使用标准二路归并排序,多线程使用败者树多路外排且支持抽样排序法策略。总体流程如下:
按照主键索引遍历并将读取到的完整数据保存至数据文件,然后将排序列添加到排序缓存区,其中每个线程使用不同的数据文件,累积达到一定数据后再写入;
不断遍历并插入到排序缓存区,当排序缓存区满时,在内存中根据排序键组合进行排序并保存到合并文件中;
遍历完成后,对合并文件按段两两排序,并将排序后的数据保存在临时文件中,随后将合并文件与临时文件进行切换;
重复执行步骤3,直到合并文件有序排列,然后读取合并文件中的每一行记录,根据偏移值读取数据文件中对应的记录并追加到列存索引中。
增量数据排序流程
增量数据的排序流程是渐进式的,不能保证数据完全有序。总体流程如下:
将所有的数据块进行两两分组,挑选出多个数据范围重合度较高的数据块组。
将每个数据块组进行归并排序,生成两个有序的数据块。
重复执行步骤2,直到所有的数据块有序排列。
参数说明
您需要在数据库中设置下表中参数的值,来开启或关闭列存索引排序功能,以及根据实际业务需求设置线程数量等信息。
PolarDB集群参数在控制台与会话中修改方式存在差异,详细区别如下:
在PolarDB控制台上修改:
兼容性说明:部分集群参数在PolarDB控制台上均已添加MySQL配置文件的兼容性前缀loose_。
操作方法:找到并修改这些带
loose_前缀的参数。
在数据库会话中修改(使用命令行或客户端):
操作方法:当您连接到数据库,使用
SET命令修改参数时,请去掉loose_前缀,直接使用参数的原始名称进行修改。
参数 | 说明 |
loose_imci_enable_pack_order_key | 新建列存索引时数据排序功能控制开关。取值如下:
|
loose_imci_enable_pack_order_key_changed_rebuild | 列存索引在索引排序发生变化时,是否需要重建表。取值范围如下:
|
loose_imci_parallel_build_threads_per_table | 构建列存索引数据的单张表的线程数量。 取值范围:1~128。默认值为8。 |
使用说明
您可以按照以下步骤来使用列存索引数据排序功能:
开启列存索引排序功能:
将参数
imci_enable_pack_order_key的值设置为ON,来开启新建列存索引时数据排序功能。在以下SQL语句的
comment中添加order_key属性来构建有序列存索引数据。ALTER TABLE table_name COMMENT 'columnar=1 order_key=column_name[,column_name]';参数说明:
参数
说明
table_name
表名。
column_name
列名。您可以配置多个列名,多个列名之间使用英文逗号(,)分隔。
您可以在
INFORMATION_SCHEMA.IMCI_ASYNC_DDL_STATS表中查看列存索引数据的构建进度。INFORMATION_SCHEMA.IMCI_ASYNC_DDL_STATS表的详细信息请参见查看列存索引构建的执行进度。
SELECT * FROM INFORMATION_SCHEMA.IMCI_ASYNC_DDL_STATS;列存索引数据排序与DDL排序的区别
列存索引数据排序的本质是按照指定键组合进行排序,类似于其他普通二级索引DDL排序过程,但两者也有不同之处,具体区别如下:
列存索引排序不使用索引列作为排序键,而是可以指定任意组合的排序键。
列存索引排序后,需要读取完整的数据。而二级索引DDL仅需要保存索引部分的数据。如VARCHAR字段只保存前缀部分作为索引数据。
有序列存索引数据构建和查询时间对比
以TPCH 100 GB为例,测试构建和查询有序列存索引数据的时间。
测试构建有序列存索引数据的时间。
以
lineitem表为例,来构建有序列存索引数据,且并行线程数量为16。示例如下:ALTER TABLE lineitem COMMENT='columnar=1 order_key=l_receiptdate,l_shipmode';构建时间如下:
无序数据集
有序数据集
6分钟
35分钟
测试有序列存索引数据的查询时间。
以TCPH的Q12为例,在LRU缓存与执行器内存均为10 GB的配置下,执行如下查询语句:
SELECT l_shipmode, SUM(CASE WHEN o_orderpriority = '1-URGENT' OR o_orderpriority = '2-HIGH' THEN 1 ELSE 0 END) AS high_line_count, SUM(CASE WHEN o_orderpriority <> '1-URGENT' AND o_orderpriority <> '2-HIGH' THEN 1 ELSE 0 END) AS low_line_count FROM orders, lineitem WHERE o_orderkey = l_orderkey AND l_shipmode in ('MAIL', 'SHIP') AND l_commitdate < l_receiptdate AND l_shipdate < l_commitdate AND l_receiptdate >= date '1994-01-01' AND l_receiptdate < date '1994-01-01' + interval '1' year GROUP BY l_shipmode ORDER BY l_shipmode;查询时间如下:
无序数据集
有序数据集
7.47s
1.25s
添加排序键与分区表的查询时间对比
在TPC-H使用的数据集为1 TB,节点规格为32核256 GB场景下,测试开启列存索引功能(列存)以及开启列存索引功能(添加分区和排序列)的查询性能。
测试使用的标准建表语句如下:
CREATE TABLE region ( r_regionkey BIGINT NOT NULL,
r_name CHAR(25) NOT NULL,
r_comment VARCHAR(152)) COMMENT 'COLUMNAR=1';
CREATE TABLE nation ( n_nationkey BIGINT NOT NULL,
n_name CHAR(25) NOT NULL,
n_regionkey BIGINT NOT NULL,
n_comment VARCHAR(152)) COMMENT 'COLUMNAR=1';
CREATE TABLE part ( p_partkey BIGINT NOT NULL,
p_name VARCHAR(55) NOT NULL,
p_mfgr CHAR(25) NOT NULL,
p_brand CHAR(10) NOT NULL,
p_type VARCHAR(25) NOT NULL,
p_size BIGINT NOT NULL,
p_container CHAR(10) NOT NULL,
p_retailprice DECIMAL(15,2) NOT NULL,
p_comment VARCHAR(23) NOT NULL) COMMENT 'COLUMNAR=1';
CREATE TABLE supplier ( s_suppkey BIGINT NOT NULL,
s_name CHAR(25) NOT NULL,
s_address VARCHAR(40) NOT NULL,
s_nationkey BIGINT NOT NULL,
s_phone CHAR(15) NOT NULL,
s_acctbal DECIMAL(15,2) NOT NULL,
s_comment VARCHAR(101) NOT NULL) COMMENT 'COLUMNAR=1';
CREATE TABLE partsupp ( ps_partkey BIGINT NOT NULL,
ps_suppkey BIGINT NOT NULL,
ps_availqty BIGINT NOT NULL,
ps_supplycost DECIMAL(15,2) NOT NULL,
ps_comment VARCHAR(199) NOT NULL) COMMENT 'COLUMNAR=1';
CREATE TABLE customer ( c_custkey BIGINT NOT NULL,
c_name VARCHAR(25) NOT NULL,
c_address VARCHAR(40) NOT NULL,
c_nationkey BIGINT NOT NULL,
c_phone CHAR(15) NOT NULL,
c_acctbal DECIMAL(15,2) NOT NULL,
c_mktsegment CHAR(10) NOT NULL,
c_comment VARCHAR(117) NOT NULL) COMMENT 'COLUMNAR=1';
CREATE TABLE orders ( o_orderkey BIGINT NOT NULL,
o_custkey BIGINT NOT NULL,
o_orderstatus CHAR(1) NOT NULL,
o_totalprice DECIMAL(15,2) NOT NULL,
o_orderdate DATE NOT NULL,
o_orderpriority CHAR(15) NOT NULL,
o_clerk CHAR(15) NOT NULL,
o_shippriority BIGINT NOT NULL,
o_comment VARCHAR(79) NOT NULL) COMMENT 'COLUMNAR=1'
PARTITION BY RANGE (year(`o_orderdate`))
(PARTITION p0 VALUES LESS THAN (1992) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (1993) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (1994) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (1995) ENGINE = InnoDB,
PARTITION p4 VALUES LESS THAN (1996) ENGINE = InnoDB,
PARTITION p5 VALUES LESS THAN (1997) ENGINE = InnoDB,
PARTITION p6 VALUES LESS THAN (1998) ENGINE = InnoDB,
PARTITION p7 VALUES LESS THAN (1999) ENGINE = InnoDB);
CREATE TABLE lineitem ( l_orderkey BIGINT NOT NULL,
l_partkey BIGINT NOT NULL,
l_suppkey BIGINT NOT NULL,
l_linenumber BIGINT NOT NULL,
l_quantity DECIMAL(15,2) NOT NULL,
l_extendedprice DECIMAL(15,2) NOT NULL,
l_discount DECIMAL(15,2) NOT NULL,
l_tax DECIMAL(15,2) NOT NULL,
l_returnflag CHAR(1) NOT NULL,
l_linestatus CHAR(1) NOT NULL,
l_shipdate DATE NOT NULL,
l_commitdate DATE NOT NULL,
l_receiptdate DATE NOT NULL,
l_shipinstruct CHAR(25) NOT NULL,
l_shipmode CHAR(10) NOT NULL,
l_comment VARCHAR(44) NOT NULL) COMMENT 'COLUMNAR=1'
PARTITION BY RANGE (year(`l_shipdate`))
(PARTITION p0 VALUES LESS THAN (1992) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (1993) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (1994) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (1995) ENGINE = InnoDB,
PARTITION p4 VALUES LESS THAN (1996) ENGINE = InnoDB,
PARTITION p5 VALUES LESS THAN (1997) ENGINE = InnoDB,
PARTITION p6 VALUES LESS THAN (1998) ENGINE = InnoDB,
PARTITION p7 VALUES LESS THAN (1999) ENGINE = InnoDB);数据导入后,为表设置排序列。设置排序列的操作方法请参见设置列索引的排序键。
ALTER TABLE customer COMMENT='COLUMNAR=1 order_key=c_mktsegment';
ALTER TABLE nation COMMENT='COLUMNAR=1 order_key=n_name';
ALTER TABLE part COMMENT='COLUMNAR=1 order_key=p_brand,p_container,p_type';
ALTER TABLE region COMMENT='COLUMNAR=1 order_key=r_name';
ALTER TABLE orders COMMENT='COLUMNAR=1 order_key=o_orderkey,o_custkey,o_orderdate';
ALTER TABLE lineitem COMMENT='COLUMNAR=1 order_key=l_orderkey,l_linenumber,l_receiptdate,l_shipdate,l_partkey';挑选TPC-H的部分查询语句进行测试,查询时间结果见下表:
查询SQL | 无序数据集(秒) | 有序数据集(添加分区和排序列)(秒) |
Q3 | 71.951 | 36.566 |
Q4 | 46.679 | 32.015 |
Q6 | 34.652 | 4.4 |
Q7 | 74.749 | 34.166 |
Q12 | 86.742 | 28.586 |
Q14 | 50.248 | 12.56 |
Q15 | 79.22 | 21.113 |
Q20 | 51.746 | 10.178 |
Q21 | 216.942 | 148.459 |