跨机并行查询功能还可以用于加速构建B-tree索引,同时支持加速创建B-Tree索引的GLOBAL索引。本文介绍工作原理以及如何使用该功能加速索引构建。
原理介绍
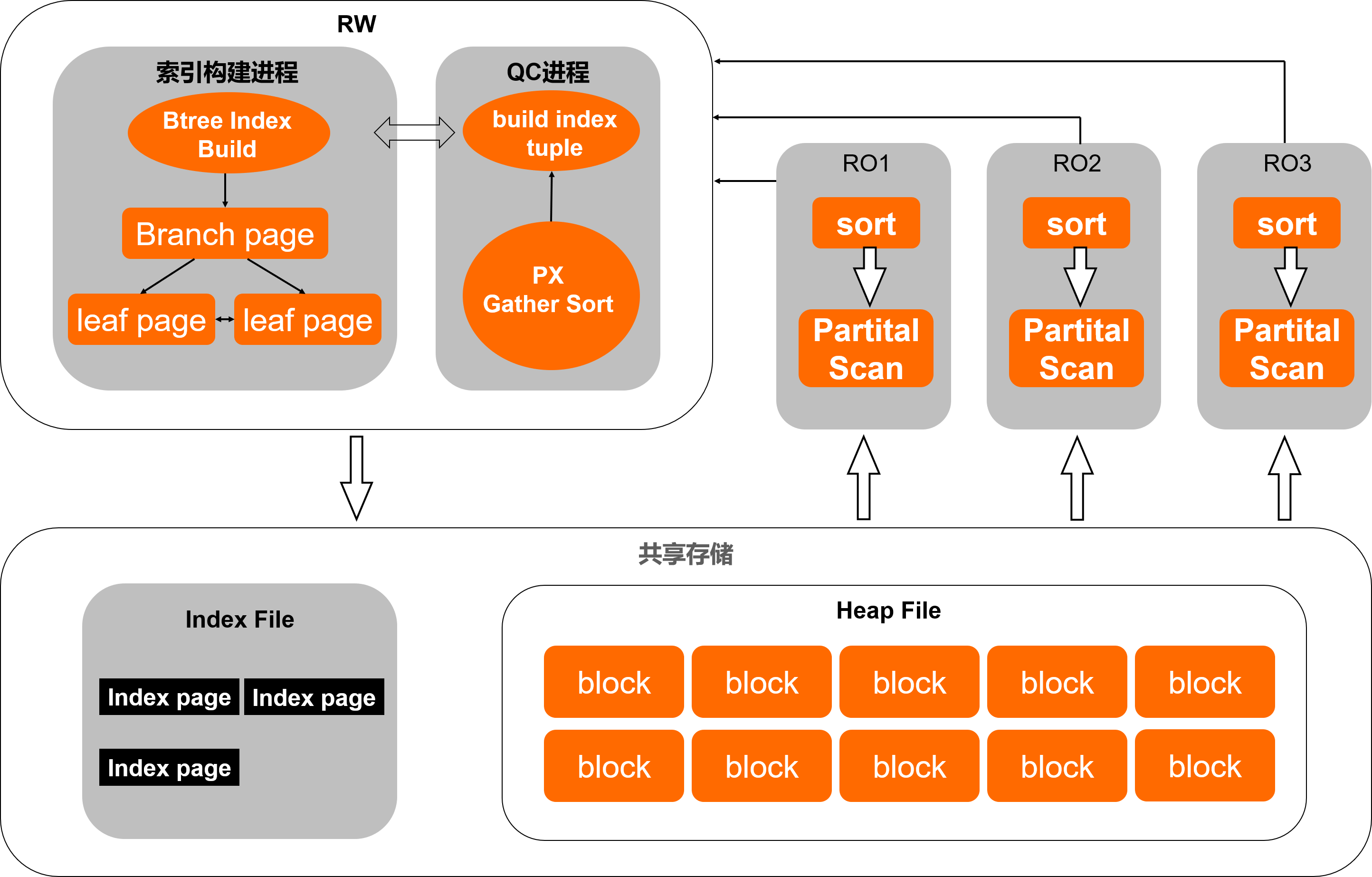
PolarDB PostgreSQL版在执行索引构建时,会首先扫描待构建索引的基表构造出索引项,然后再进一步的根据索引项完成整棵索引树的构建过程。
当使用跨机并行查询功能加速Btree索引构建时,系统会自动构建出一个QC进程完成对基表项的并行扫描,并由索引构建进程接收QC进程扫描结果完成后续的索引创建逻辑。
注意事项
- 当前仅支持简单场景,对普通列类型的索引构建过程,暂不支持CONCURRENTLY,INCLUDE等索引构建语法。
- 暂不支持表达式等索引列类型。
参数说明
如果需要使用跨机并行查询功能加速创建索引,请使用如下参数:
| 参数 | 说明 |
|---|---|
| polar_px_enable_btbuild | 是否开启使用跨机并行查询加速创建索引。取值如下:
|
| polar_px_dop_per_node | 指定通过跨机并行查询加速构建索引的并行度。默认为1,推荐值8或者16。 该参数同时也指定了跨机并行查询的并行度。详细信息,请参见使用跨机并行查询进行分析型查询。 该参数可以指定数据库角色进行开启。 |
| polar_px_enable_replay_wait | 当使用跨机并行查询加速索引构建时,当前会话内无需再手动开启polar_px_enable_replay_wait,该参数将自动生效,以便保证最近更新的数据表项可以被创建到索引中,保证索引表的完整性。索引创建完成后,该参数将会被重置为数据库默认设置。 |
| polar_bt_write_page_buffer_size | 指定索引构建过程中的写IO策略。该参数默认值为0,不开启,单位为块,最大值可设置为8192。推荐设置为4096。
|
示例
示例背景:
执行如下命令,创建test表。
CREATE TABLE test(id int,id2 int);查询表结构:
\d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
id2 | integer | | |执行如下步骤,对test表通过跨机并行查询构建索引。
- 开启使用跨机并行查询加速创建索引功能。命令如下:
SET polar_px_enable_btbuild=on;查看设置状态:
SHOW polar_px_enable_btbuild;返回结果如下:
polar_px_enable_btbuild ------------------------- on (1 row) - 使用如下语法创建索引。
CREATE INDEX t ON test(id) WITH(px_build=on);查询表结构:
\d test Table "public.test" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+--------- id | integer | | | id2 | integer | | | Indexes: "t" btree (id) WITH (px_build=finish)
说明 若要使用跨机并行查询加速索引创建,创建索引的语法需要添加px_build选项。
构建完成后,该表的索引类型会带有(px_build=finish)字段,说明该索引项是通过跨机并行查询的方式构建的。
如果开启polar_px_enable_btbuild,但创建索引的语法上未添加px_build选项,则会使用PolarDB PostgreSQL版原生的索引创建方式构建索引。示例如下:
CREATE INDEX t ON test(id);查询表结构:
\d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
Indexes:
"t" btree (id)性能数据
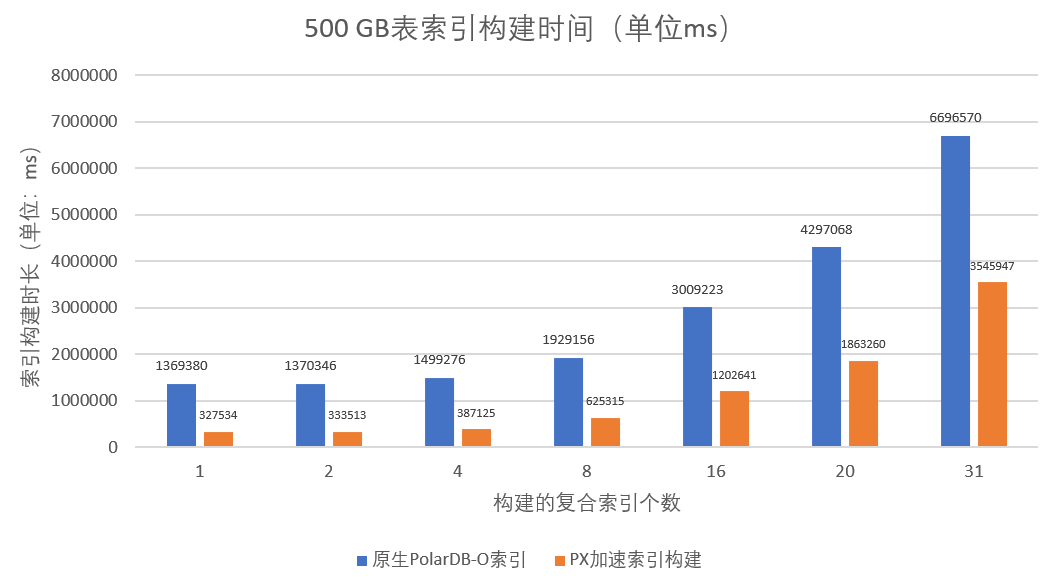
使用跨机并行查询加速索引构建功能,对于大表创建索引时间,相较于原生PolarDB PostgreSQL版的索引创建,可缩短近5倍。
如下是500GB数据表索引构建性能对比,横坐标为构建的复合索引个数,纵坐标为索引构建时长(单位:ms)。