
本文介绍了PolarDB-X的Binlog日志服务,以及其两种形态和适用场景。
介绍
Binlog是MySQL记录变更数据的二进制日志,它可以看做是一个消息队列,队列中按顺序保存了MySQL中详细的增量变更信息,通过消费队列中的变更条目,下游系统或工具实现了与MySQL的实时数据同步,此机制也称为CDC(Change Data Capture,增量数据捕捉)。
PolarDB-X是兼容MySQL生态的分布式数据库。通过实例内PolarDB-X的CDC组件,能够提供与MySQL binlog格式兼容的变更日志,并且对外隐藏了实例扩缩容、分布式事务、全局索引等分布式特性,让您获得与单机MySQL数据库一致的使用体验。
PolarDB-X提供了两种形态的binlog日志消费订阅能力,且两种形态可同时共存。
单流形态:即单流binlog日志(也称为Global binlog),将所有DN的binlog归并到同一个全局队列,提供了保证事务完整性和有序性的日志流,可以提供更高强度的数据一致性保证。例如在转账场景下,基于Global binlog接入PolarDB-X的下游MySQL,可以在任何时刻查询到一致的余额。
多流形态:即多流binlog日志(也称为Binlog-X),并不是将所有DN的binlog归并到一个全局队列,而是将数据进行Hash打散并分发到不同的日志流,在一定程度上牺牲了事务的完整性,但大大提升了扩展性,可以解决大规模集群下单流binlog存在的单点瓶颈问题。
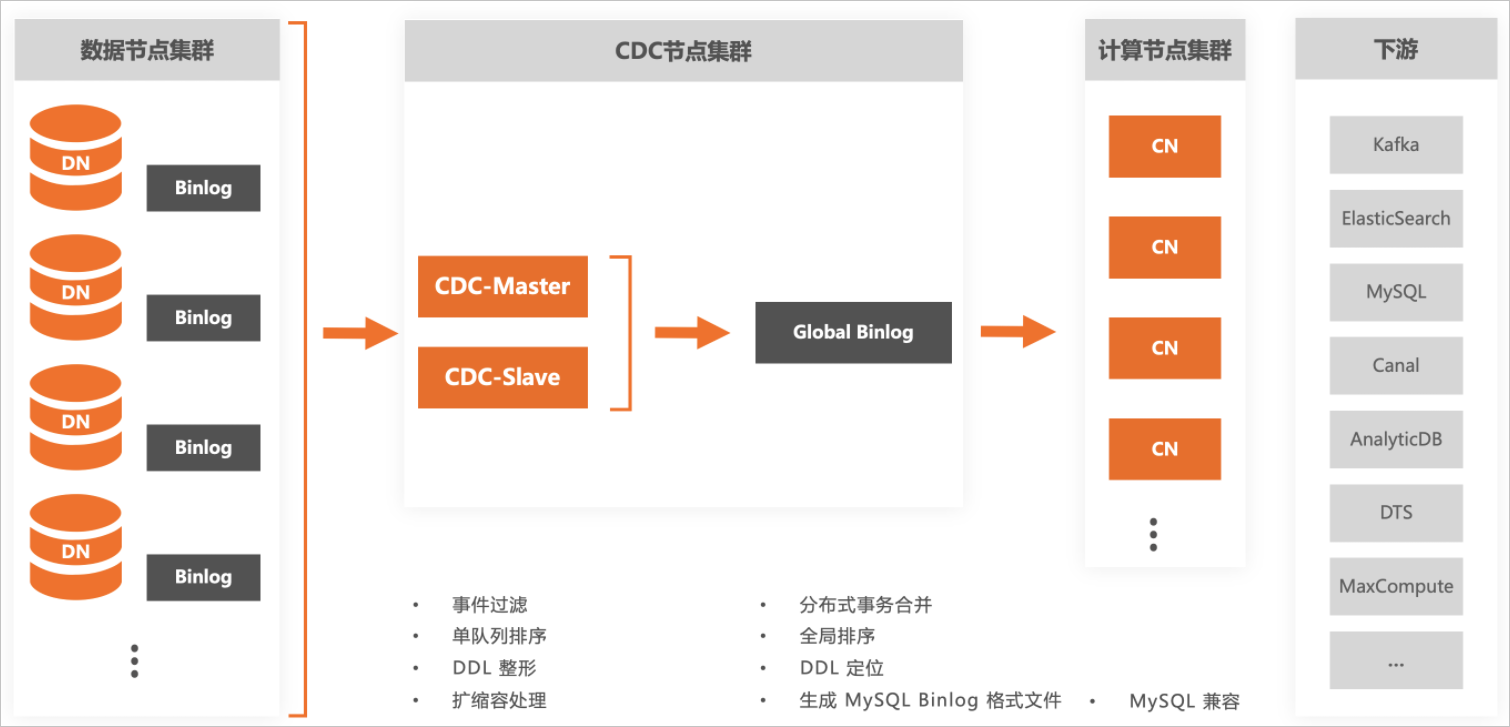
单流形态
将所有DN节点的原始binlog日志归并到一个队列,并进行排序和合并,剔除内部细节,对外提供兼容MySQL binlog格式和dump协议的日志流。当购买PolarDB-X实例时,默认开通单流binlog服务。
注意事项
CDC的Master节点和Slave节点之间会进行binlog文件的复制,并保证两边数据完全一致,即下游按照filename+position的方式进行消费订阅,当CDC发生主从切换时,无需担心文件名和位点会发生变化。
仅当事务策略指定为TSO时,才支持对分布式事务的合并,否则只能保证数据的最终一致性,PolarDB-X默认的事务策略为TSO。
当需要对某行数据进行分区键值变更时,需在采用TSO事务策略的分布式事务内进行,才能保证delete事件在binlog中的位置早于insert事件,从而保证数据一致。具体来讲,首先需要采用TSO事务策略,然后按如下任意一种进行操作都可以实现分区键值的变更,并可以保证数据一致。
执行一条update sql进行分区键值的修改;
执行一条replace sql进行分区键值的修改;
显示开启事务,先执行delete,调整分区键值,重新insert。
多流形态
多流binlog依然完全兼容MySQL binlog文件格式和dump协议,可以将每条binlog日志流看作一个单机MySQL,针对单个日志流,可执行change master、show binlog events等SQL命令消费或查看binlog数据。
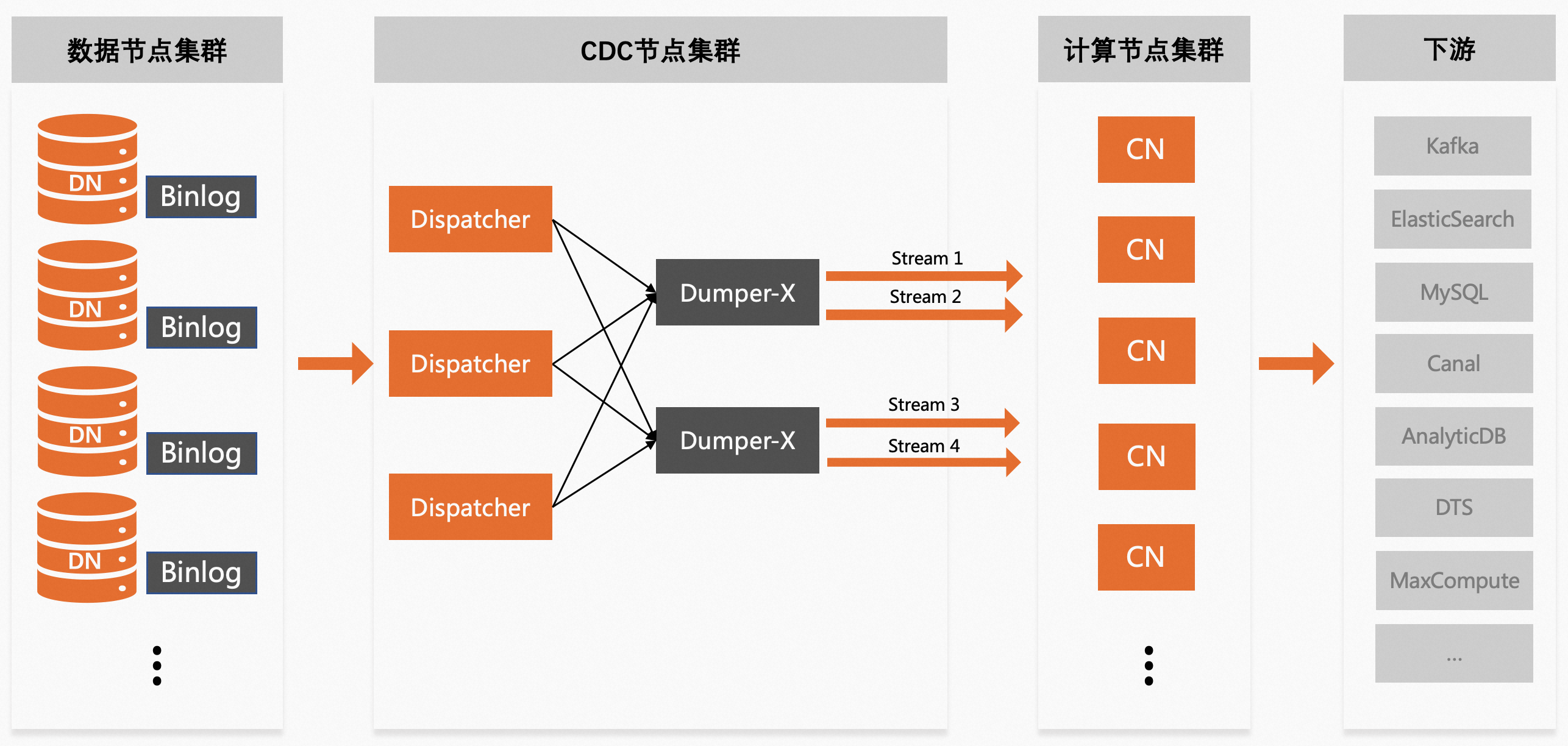
多流服务不是默认开通的,需通过控制台手动开通,对于同一个PolarDB-X实例,可支持同时开通多个多流服务,每个多流服务中支持多个流,不同服务之间是完全隔离的,可设置不同的拆分数量、不同的数据拆分级别、不同的参数规则等,可根据实际需求开通不同形态的多流服务。
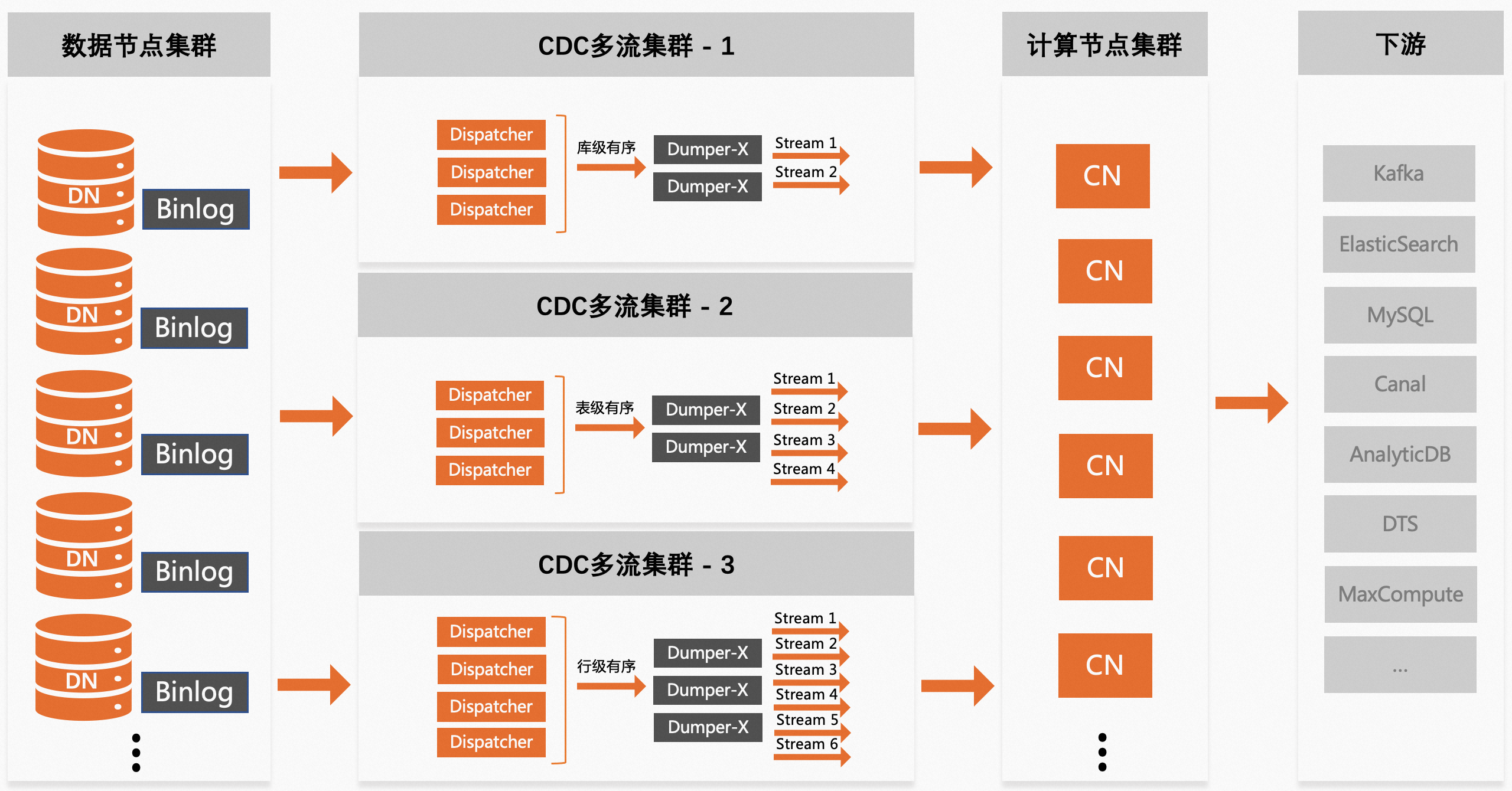
拆分级别
多流binlog提供了3种形式的数据拆分级别,在开通多流服务时可进行设定,满足不同场景下的使用需求。
库级别
按照数据库的名字计算Hash值并进行分发,即对应同一个库的binlog数据,会始终按序路由给同一个binlog数据流,适用于单个PolarDB-X实例上数据库比较多的场景,如果事务不涉及跨库操作,该策略下不仅可以具备多流能力,还可以保证事务的完整性。
表级别
按照数据表的名字计算Hash值并进行分发,即对应同一张表的binlog数据,会始终按序路由给同一个binlog数据流,适用于表的数量较多且希望针对单张表的操作(如DML、DDL等)在binlog日志流中保持有序的场景。
记录级别
按照数据行的主键计算Hash值并进行分发,即对应同一数据行的binlog数据,会始终按序路由给同一个binlog数据流,适用于希望将数据充分打散且不要求日志数据按库或按表保持有序的场景,该策略要求数据表必须含有主键,无主键表的数据会被直接丢弃。
数据拆分级别支持分层配置,分别为服务层和库表层,层级配置成功就不支持修改,否则会触发相同数据在不同流之间的“漂移”,导致数据一致性问题。开通多流服务前,建议结合实际业务场景进行评估,预先规划好拆分级别。
服务层
该多流服务的默认拆分级别,如果针对某个库或表没有单独设置拆分级别,则使用服务层的默认配置。
库表层
可以针对某个库或表单独设置分发策略,该分发策略会对实例级别的配置进行重载,以满足差异性需求。
注意事项
多流服务创建成功后,不支持修改流的个数,请提前规划好流的数量,建议流的数量大于等于DN的个数。
多流服务创建成功后,不支持调整已经生效的拆分级别,建议提前进行规划。
如果希望对新增加的数据表独立设置拆分级别,请在该表有数据写入之前进行配置。
当拆分级别为表级时,支持对表进行
Rename操作,PolarDB-X会始终依据初始表名进行数据拆分。当拆分级别为表级时,为避免大表数据集中到少数几个流,出现数据倾斜的问题,可单独设定路由规则。
如果想调整流的个数和已经生效的数据拆分级别,可以通过开通一个新的多流服务来进行替换,此时会涉及下游消费链路的一些运维调整。
当拆分级别为记录级时,如果数据表包含唯一性约束并且会发生唯一键交换,按照记录级进行拆分,可能会触发数据一致性问题。例如,uk(name)=a先后被id=1和id=2的数据所持有,但因无法保证
delete(id=1,name=1)和insert(id=2,name=a)在目标库的执行顺序,当insert(id=2,name=2)先于delete(id=1,name=1)执行时,会出现写入冲突。此类场景建议设置拆分级别为表级。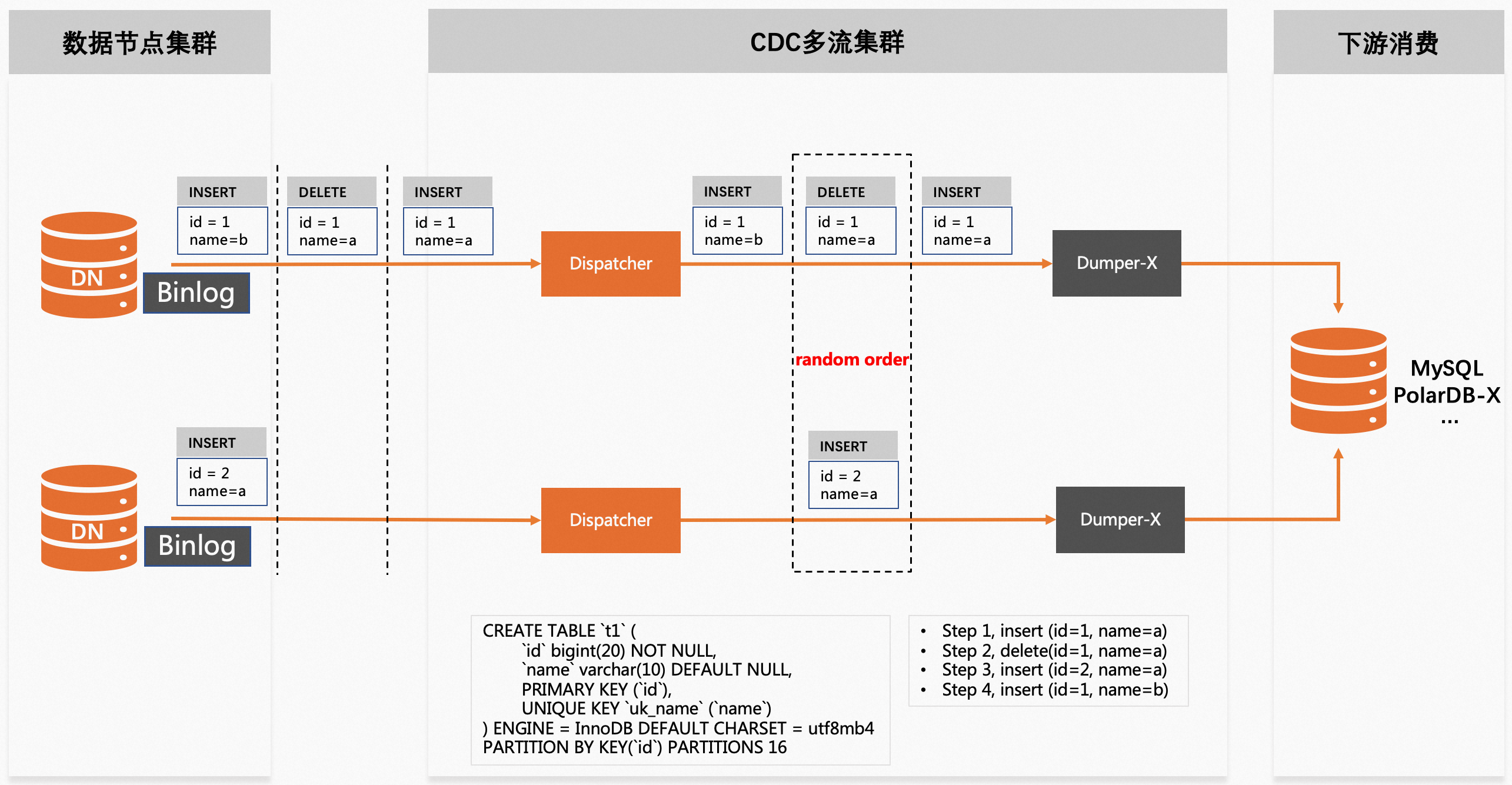
透明消费
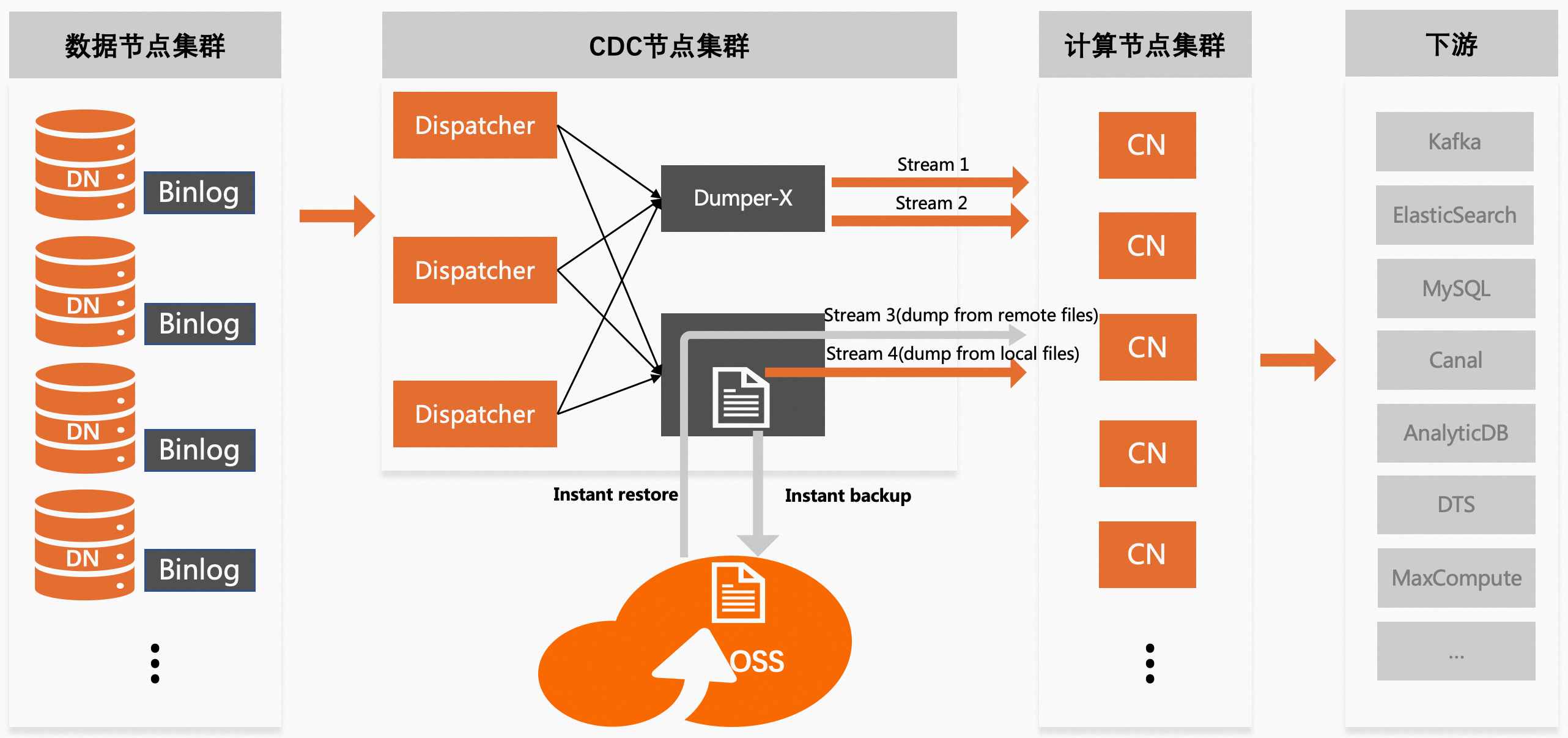
CDC会优先把构建好的binlog文件保存在本地磁盘,并支持实时上传到远端存储(例如OSS)。本地磁盘上的文件一般存活周期较短,远端存储上的文件存活周期较长(例如15天)。针对远端存储上的文件,CDC提供了透明消费能力,即屏蔽了本地和远端的存储差异,下游系统无需为访问远端存储上的binlog数据做任何额外适配。
CDC 2.0.0及以上版本支持透明消费能力。
异地多活
除了通过CDC将数据导入其他外部系统,PolarDB-X的CDC也可以用于实现异地多活的业务部署。例如,将用户ID按照所在地区划分到不同机房,写入操作必须在特定机房进行,而读取操作可以读就近的“副本”,这些副本数据就可以通过CDC从原机房同步得到。