Highlight
终结分库分表,系统弹性、灵活性大幅提升。
数据生命周期管理,降低存储成本,提高运维效率。
CDC实现双机房容灾部署,无需同步工具介入,RPO=0。
客户简介
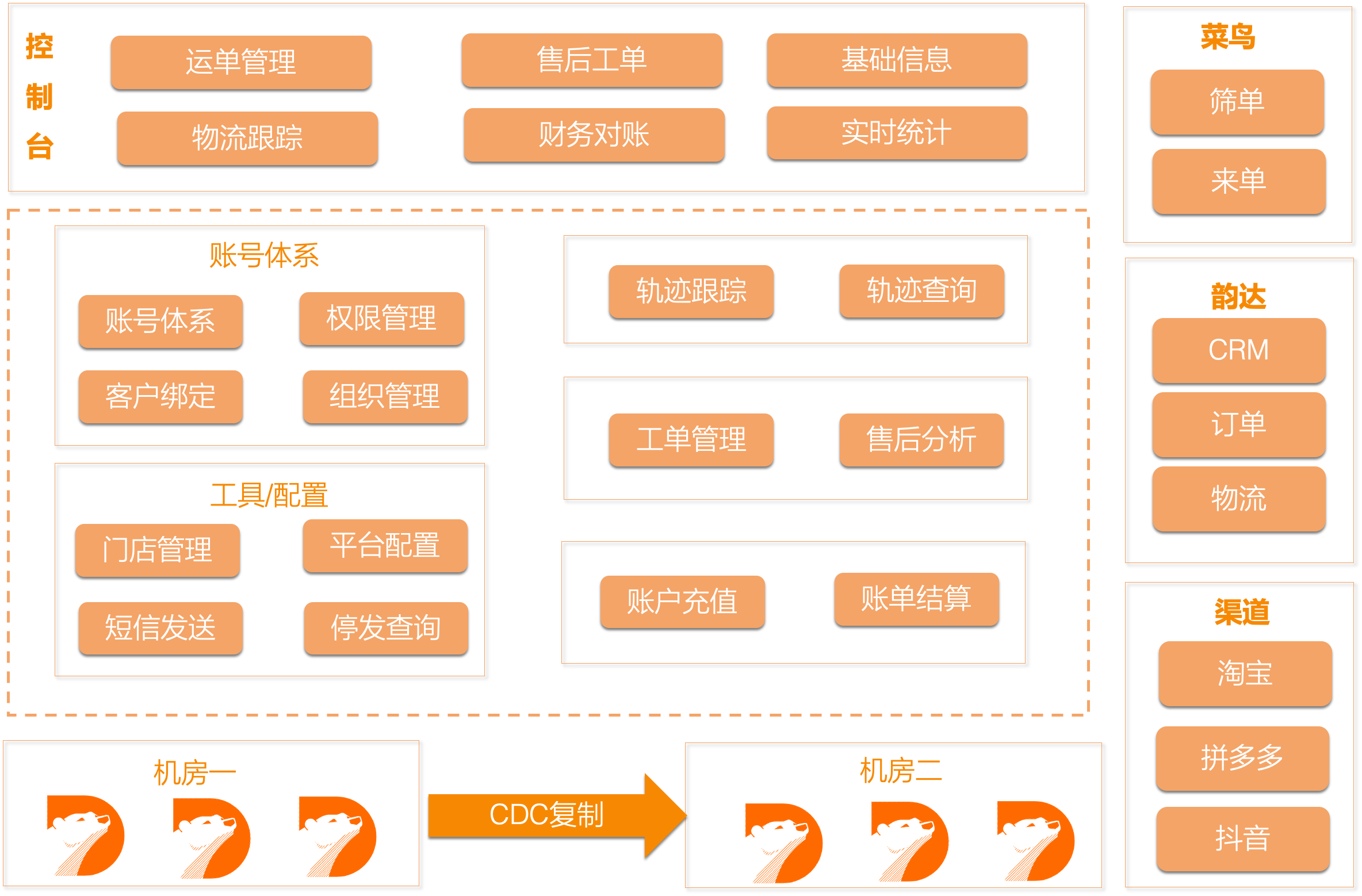
韵达物流作为国内快递行业第一梯队的领军企业之一,在全国拥有近5千个加盟商、超过3万个门店网点,随着公司在枢纽转运中心、设备自动化智能化、运力运能提升。数字化信息化建设等核心资产方面的投入逐渐完善, 客户管家便是其中的一个典型。
客户管家已于今年年初正式上线,借助后台强大的计算能力,以及以客户体验为中心的产品设计,得到用户的一致好评,客户管家是韵达物流提供的一站式、全新数字化管理工具,客户管家系统从已揽收、运输中、派件中、已签收等多维度,对客户发出快件进行全链路跟踪和数据可视化展示,协助客户实现对店铺快件全流程的可视、可控,并提高运单管理效率。
业务挑战
分库分表带来一系列约束
韵达目前日增运单量超过数千万,预计总量接近数百亿,工单数据也接近数十亿的量级。将这些信息存储并进行关联,才能为客户提供丰富的业务服务 。按我们的以往的惯例会采用分库分表方案 ,按照我们以往使用的经验,我们后续将面临扩容、运维管理、代码侵入等一系列的问题。
海量数据怎么存
按监管要求,我们需要保存数年的数据,面临日增千万的数据量,在任何一个数据库哪怕是分布式数据库内,也是一个极大的挑战,即便我们的DBA可以定期地人肉备份,清理。绝大部分数据库也不能及时地回收空间,需要DBA额外的介入,整个管理流程繁琐且效率低下,还很容易影响系统的稳定性。
异地容灾
运单数据对物流公司的意义不亚于账单数据对银行的意义。核心业务按照要求需要有完整的异地容灾方案,传统分库分表意味着每一个分库就需要维护一条同步链路,管理的复杂度随着分库数的增加而指数级上涨,同时数据一致性和完整性也很难得到保证。
解决方案
一体分布式演进
借助阿里云瑶池旗下的PolarDB分布式版和韵达成立的物流行业创新实验室的机会,我们在这个项目中成功引入了PolarDB分布式版作为我们的核心数据库。
PolarDB分布式版通过一体化的分布式设计和一体化的运维管理方案,让我们不再需要额外管理海量的MySQL实例。从维护多套转变成维护一套,彻底摆脱了分库分表带来的运维困扰。
同时与单机MySQL高度兼容的使用体验,也大大解放了业务层的代码设计,让我们不再去顾虑之前传统分库分表给我们带来的各种限制。更重要的一点,PolarDB分布式版提供的Binlog协议兼容,完美匹配了我们公司内部的数据同步方案,让我们的体感更多的是我们只是引入了一个超级大的MySQL而已,原公司内部MySQL的周边生态包括基于Binlog的上下游同步机制都被完整地继承了下来。
数据生命周期管理
TTL-数据的生命周期管理也是我们选择PolarDB分布式版很重要的原因,运单数据有着明显的时间周期属性,通常1年内的数据对客户是有意义的,太久远的运单大部分情况不会被高频地访问。按照以往的做法,我们会定期将过期数据备份导出后原地进行删除,由于MySQL的特性delete之后不会回收空间,还需要在业务低峰执行optimize回收空间。有多少套MySQL就需要重复多少次这样的管理动作,DBA毫无幸福感可言。
PolarDB分布式版提供了TTL功能,在建表时除了指定按照运单打散之外,还可以指定时间分区,并指定分区过期策略,数据库自动将过期数据归档到OSS或是直接删除,无需人为介入,自动管理,降低存储成本:
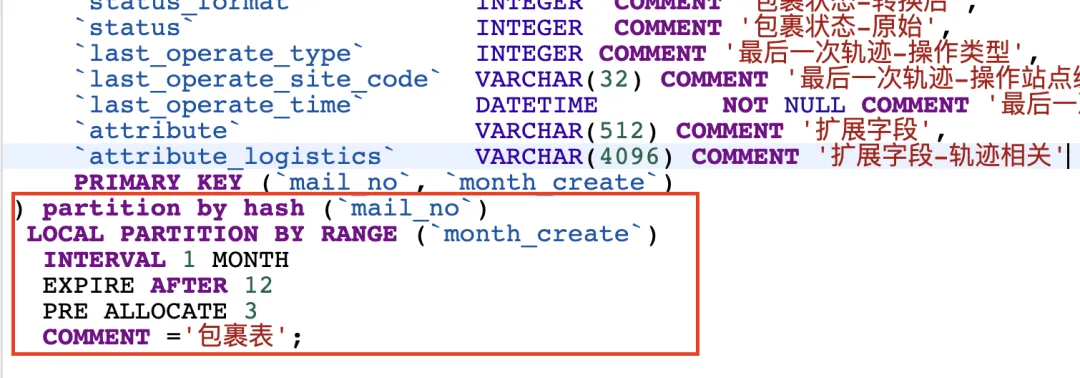
以我们真实的表结构为例,这里可以理解为是一个2级分区表,第一级分区是已运单号,第二级分区是时间,每个月一个分区,12个月后过期。到第13个月时,自动会将第1个月的数据进行detach后删除处理。如果结合云上的数据归档功能一起用的话,PolarDB分布式版还可以帮我们把过期的数据detach之后自动转储到OSS上,我们随时可以进行查询操作,体验与普通表一致,唯一的限制就是不能修改。而且整套动作内核自动完成,DBA只需要在建表时指定规则即可,DBA的幸福感瞬间爆棚。
CDC实现异地容灾
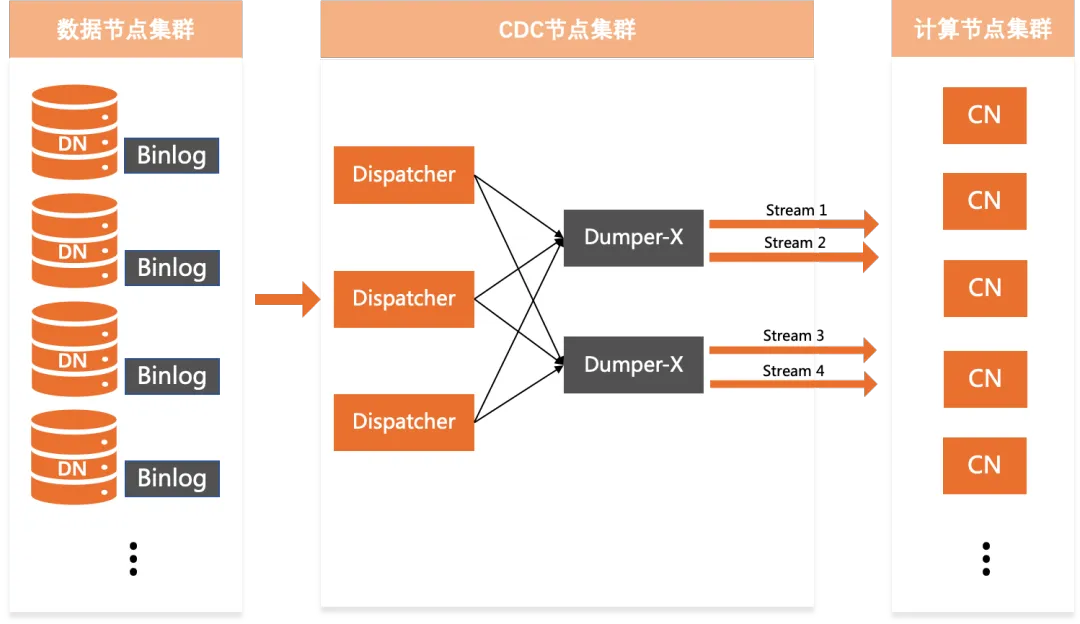
因为我们抛弃了分库分表的方案,借助PolarDB分布式版一体化的架构,异地容灾的架构也相应地变得简单,存储节点提供的Paxos协议多副本能力,每个DN自行可以完成跨地域数据同步。然后我们又遇到了另一个现实问题,我们的备机房规格要比主机房规格相对较低一些,如果直接采用Paxos协议多副本同步方案,我们的备机房的资源略显吃紧,就在我们打算放弃多副本方案采用canal双向同步的时候,阿里云的同学为我们同步了PolarDB分布式版的另一个最新的能力,PolarDB分布式版可以通过CDC节点自行实现2个实例间的双向同步,看起来就像两个单机MySQL在通过Binlog同步一样。这下我们的备机房资源不但节省了,连同步工具都不需要了。
两个独立的PolarDB分布式版实例通过CDC即可实现单向或双向的复制。 无需借助额外同步工具,且对两边实例的大小规格没有限制,用户可自行调配。
用户价值
单实例支撑全量运单数据,QPS峰值突破10万,RT稳定在5毫秒以下。
数据实现自动归档删除,无需额外人力和成本投入。
内核实现跨地域容灾,更加稳定可靠。
结语
继打标业务投产成功之后,客户管家是运行在PolarDB分布式版上的首个核心业务场景,自上线以来,PolarDB分布式版数据库运行平稳,整体QPS峰值接近10万,而SQL的响应时间稳定在5毫秒以内,很好地支撑了整个管家平台的平稳运行。平稳的性能加上轻量的运维让我们可以把更多的工作重心放在了业务设计上,大大提高了我们的业务迭代效率。我们也相信PolarDB分布式版凭借出色的分布式能力和极致的单机体验,未来在物流行业的其他领域如轨迹、仓储、物流等都会有它的一席之地。