
本文介绍了PolarDB-X中热点散列的方法。
PolarDB-X作为分布式数据库,对于分区表的各个分区会尽可能均衡的分布到不同的存储节点,更好地利用上整体系统资源,避免出现单点性能。对于Range和List分区,分区数据是按照用户的定义来划分的,对于HASH策略的分区,PolarDB-X采用的是一致性HASH算法,将分区键的值映射为一个具体的哈希值,进而映射到分区所在的哈希空间。对分区键分布均衡(例如分区键是主键),且采用的是HASH分区策略的数据表,PolarDB-X能保证各个分区的数据也是均衡的。反之,分区之间的数据可能就会与不均,甚至出现严重的数据热点(数据倾斜)。
这里以一张订单表来阐述下HASH策略下的数据表是如何产生数据热点(数据倾斜)的,该表的主键为自增的ID,表定义如下:
CREATE TABLE orders (
id int(11) NOT NULL AUTO_INCREMENT,
seller_id int(11) DEFAULT NULL,
PRIMARY KEY (id)
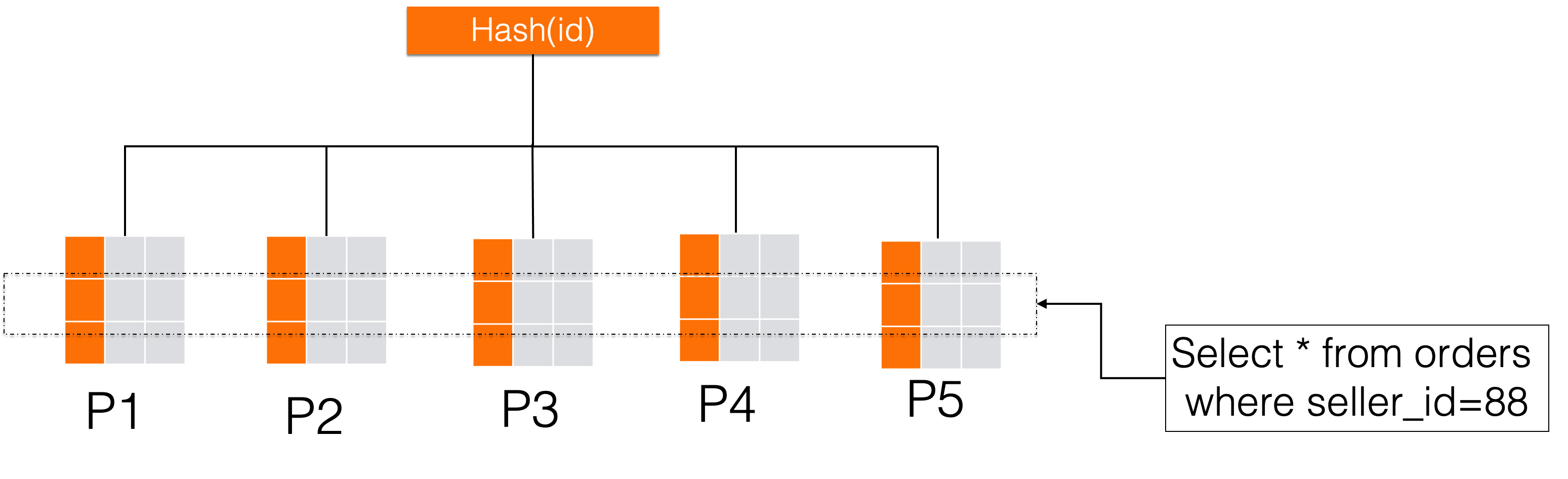
)对于这个订单表来说,如果我们为了追求数据的分布的均匀性,拆分键选择主键通过Hash的方式拆分,主键的具有唯一性,因为在PolarDB-X中,采取的是一致性Hash算法,所以按主键hash之后数据一定会均匀在分布在各个分区中。但是对于业务来说,通常不是按一个自增id维度去查询,业务更多的是需要频繁的按照卖家维度查询某卖家的数据,那么如下图所示,要查seller_id=88的数据,无法根据seller_id来做分区裁剪,就需要做一遍全分片扫描,这种查询效率是极低的。
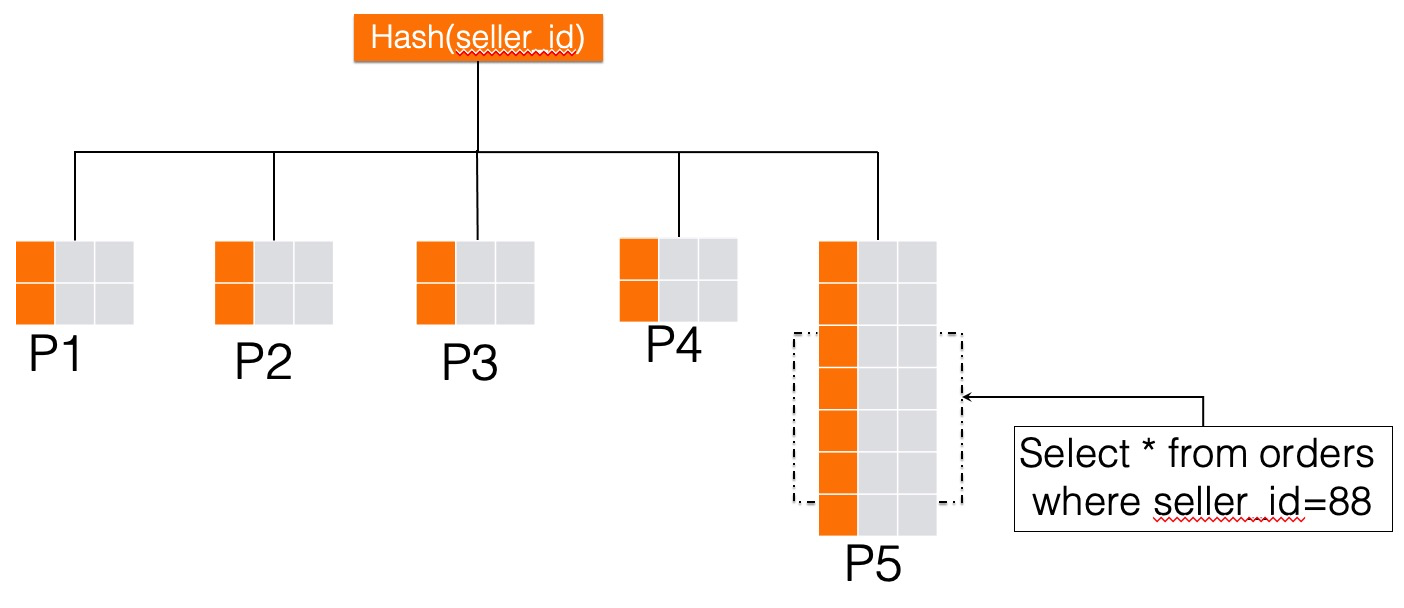
自然而然就想到更换一下我们的拆分键,采用seller_id通过Hash方式拆分,这种方式的好处是在按卖家维度查询数据时,我们能在优化器中利用分区裁减技术,将大部分无关分区裁减掉,仅仅扫描部分分区就可以满足业务的需求,如下图所示。但是这种拆分方式按照卖家ID拆分,相同的卖家数据会分布到相同的分区,这就会导致大卖家所在的分区数据异常的大,数据倾斜严重,大卖家的数据都在一个分区(例如下图中的P5),会导致这个分区出现严重的写入热点。
PolarDB-X是如何有效的解决这类数据热点问题的?
首先,新增一个列作为第二个拆分键。
alter table orders partition by key(seller_id,id) partitions 5这个拆分变更并没有改变orders表的数据分布,没有任何数据rehash,分区数还是5,将id作为第二个拆分键加进来了,仅仅修改表的分区元数据,代价是非常小的。此时的id列实际上并没有参与具体的路由计算,仅仅是一个分区键的"占位符"。
直观的对比一下加入id拆分列前后orders表各个分区的hash空间情况:
增加拆分键前:

增加拆分键后:
当只有一个拆分键时若分区有数据热点时,也就是大量的数据集中到一个具体的哈希值,而不是一个范围,无法进一步分裂。有两个拆分键后,哈希空间从一维变成了二维,这种转换赋予了我们更多的灵活性,允许我们根据第二个拆分键去进一步地拆分那些数据热点区域。在PolarDB-X中可以对热点分区对热点值按照第二个拆分键继续拆分。例如对于上面例子中的orders表中seller_id=88的大卖家数据,目前都集中在P5分区,可以通过以下命令将其打散:
alter table orders split into H88_ partitions 2 by hot value(88)分裂后的效果如下图所示:
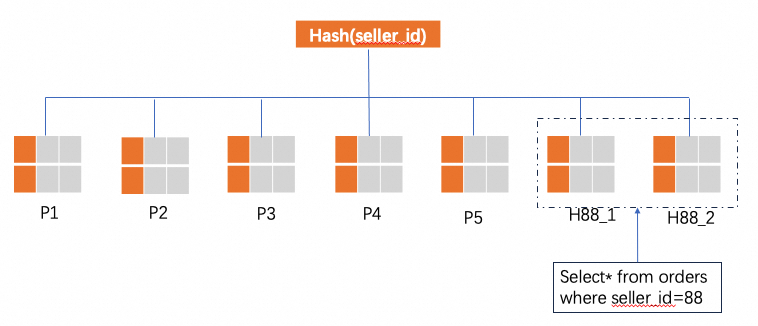
分裂的原理是对于seller_id=88的数据从P5中分裂出来并按照第二个拆分列id进一步分裂为N个分区,示例中N=2,分裂成两个分区H88_1和H88_2。
分裂前后非热点数据(seller_id不等于88)并没有发生变化,原来在P1的还在P1,在P2的还在P2,仅仅是影响到了热点数据的,分裂前seller_id=88会自动路由到P5分区,分裂后路由到H88_1和H88_2。
限制
只有采用KEY分区策略的分区才能实现热点散列(KEY分区是属于HASH分区的一种)。