
PolarDB-X是一款支持HTAP(Hybrid Transaction/Analytical Processing)的数据库,在支持高并发、事务性请求的同时,也对分析型的复杂查询提供了良好的支持。
查询优化器
PolarDB-X的优化器面向HTAP负载设计,对复杂查询有着良好的支持。TP(Transaction Processing)类事务型查询包含的表数量通常有限(例如3个以内),并且Join条件往往被索引覆盖,且查询涉及的数据量较小。而对于不符合上述特征的复杂查询,对优化器提出了更高的要求。
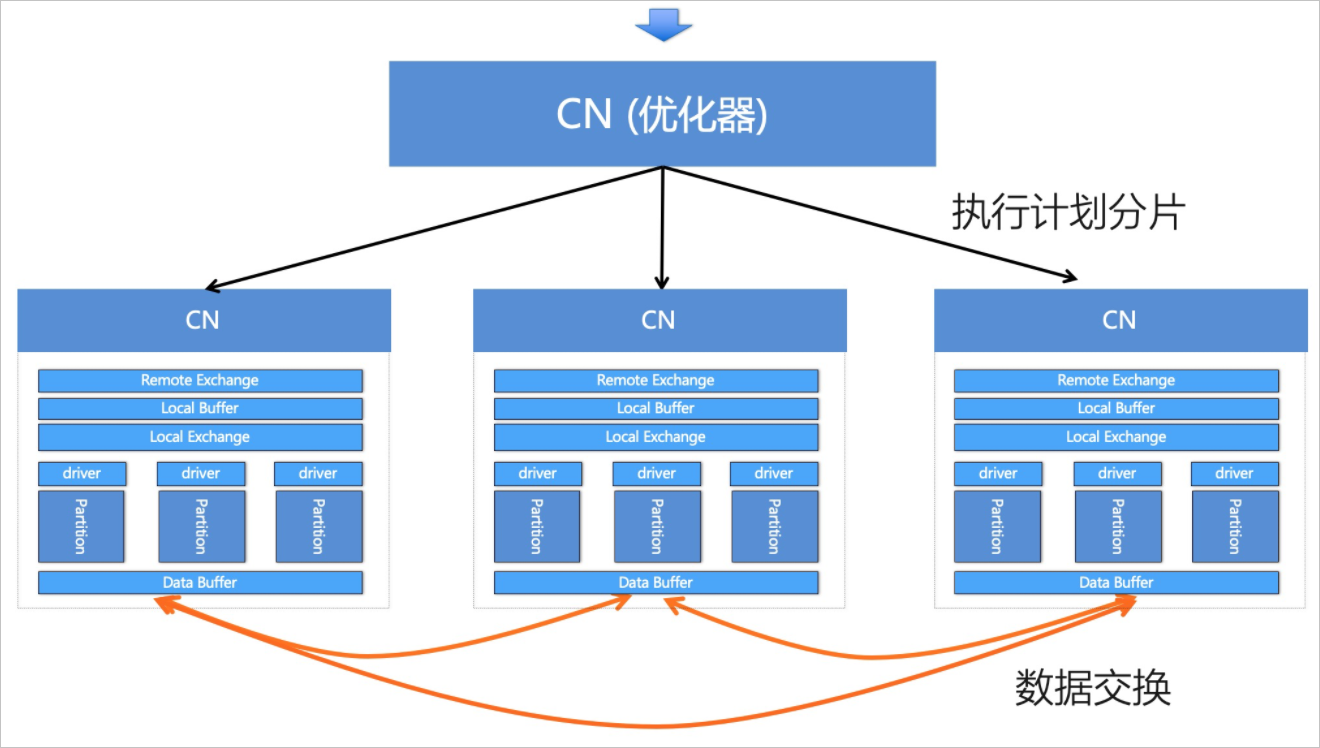
PolarDB-X采用了基于代价的优化器技术,能够根据实际数据量、数据分布情况等,搜索到较优的执行计划,例如,对Join顺序进行调整、选择合适的Join或聚合算法,对关联子查询去关联化等。执行计划的好坏很大程度上决定了查询效率,查询优化对于AP(Analytical Processing)类分析型查询至关重要。
读写分离
当在线业务流量比较多时,对PolarDB-X主实例压力比较大。此种场景下,PolarDB-X建议您购买只读实例,按照预先设置好的比例将一部分TP类读查询通过主实例CN转发给只读DN,这个过程称为读写分离。通过读写分离对读流量进行分流,可以减轻主实例存储层DN的读压力。
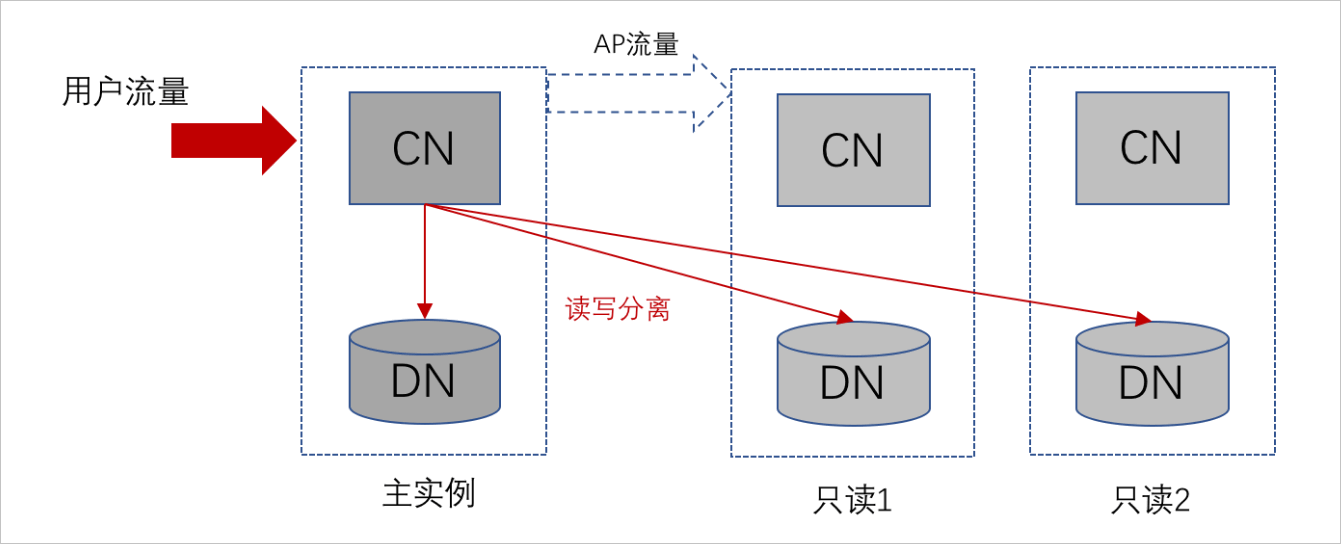
- 强一致性读:路由到只读实例的请求,保证一定能够查询到读请求执行前在主实例上已完成更新的数据,提供外部强一致性;
- 弱一致性读:路由到只读实例的请求,读请求仅访问只读实例上当前的最新数据,会因为主从异步复制的架构产生数据读取延迟。
您可以通过Hint指定哪些读SQL在主实例上执行,也可以预先设置读写比例,详情请参见配置读写分离。
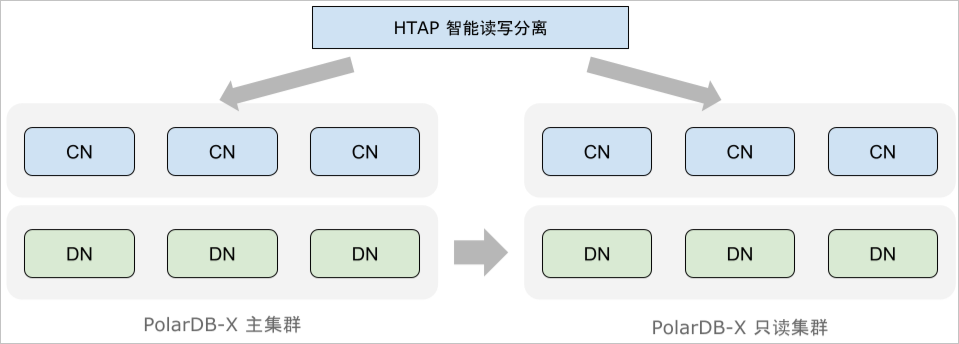
智能读写分离现阶段,HTAP数据库实际应用的一大障碍是AP类查询对TP类查询的影响。为了解决这一问题,PolarDB-X建议您部署独立的只读实例,只读实例与原实例在硬件资源上完全分离,从而将AP类查询对TP类查询的影响降到最低。
PolarDB-X优化器支持基于代价将请求区分为TP与AP,其中AP查询会被进一步改写为分布式执行计划,发往只读实例进行计算,避免它对主实例的TP类查询造成影响,这个过程称为智能读写分离。
分布式执行
全局一致性读
传统读写分离架构下,数据复制的延迟可能带来的数据写后读(read-after-write)不一致问题。PolarDB-X中,对于路由给只读实例的查询,默认开启全局一致性读能力,确保业务不会读到过期的数据,向主实例写入成功后能在只读库读到写入的数据。