在PolarDB-X中,为加速SQL的执行效率,当分区表间通过各自的分区键进行等值关联的JOIN操作时,优化器会倾向于将这些操作转化为Partition-Wise Join来实现计算下推。这种方法可以显著提升查询的执行效率。然而,在表A发生诸如分区分裂、迁移等变更后,其分区规则与表B不再对齐,原本A表和B表支持下推的JOIN查询条件将会不复存在,由此导致计算下推变得无效,并对业务的执行效率造成不利影响。
为了保障表之间的JOIN操作能够稳定地实现计算下推,在PolarDB-X中引入了表组的概念。在PolarDB-X中,任何一个表都会有且只有一个与之关联的表组,这个表组可以是用户提前创建好的;也可以是默认的,系统自动维护,对用户无感。当用户业务中的多个表之间存在强关联查询,一般建议显式的创建表组,然后在创建表的时候指定表与表组绑定关系。对于建表过程不指定表组的表,PolarDB-X会自动的根据其分区特点为其创建一个表组或者关联到已有的表组中。对于同一个表组内的表具有以下特点:
分区方式完全相同:
分区策略完全一致,例如都是HASH策略。
拆分键的数据类型完全一致,对于字符类型,还包括字符集也要一致。
分区数目完全一致。
对应分区名称完全一致,例如所有的表的第一个分区都是P1(该命名也可以根据实际情况调整)。
分区名称相同的分区定义完全一致,例如对于List分区,所有表的P1的定义都是 PARTITION P1 VALUES IN ('杭州','广州')。
分区名称相同的物理表都在一个存储节点。
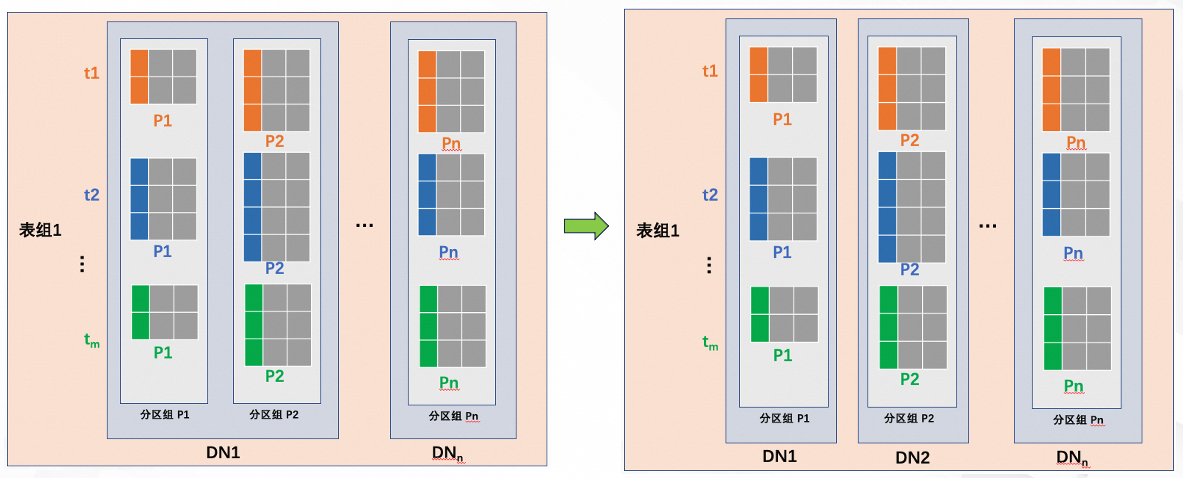
在表组内,分区名称相同的分区集合称为分区组,例如所有表的P1分区集合称为分区组P1,依此类推,Pn分区的集合称为分区组Pn。
当表需要做分区变更操作时,如果当前表和其他表在业务上有JOIN关系且之前能保持JOIN的下推,建议不要对单个表进行变更,而是通过对表组进行变更,这样会让表组内的所有表同步进行变更,变更前后表组内的表始终保持分区对齐,并不会破坏表之间的JOIN下推关系。所谓表组变更就是以分区组为单位进行变更。
以下是表组变更的一个示例:
假设表组1包含t1到tm的m个分区表,每个表具有从P1到Pn的n个分区。最初,分区组P1和P2都位于存储节点DN1上。为了缓解DN1的压力或为其他目的隔离分区组P2,可以将整个分区组P2迁移到存储节点DN2。迁移变更前后,原表t1~tm之间的JOIN下推关系不变,对于业务来说,原来能下推的JOIN SQL,变更后仍然能下推,不会有性能的损失。