
本文介绍了自定义函数的执行原理及使用方法。
原理介绍

创建成功的自定义函数,会被持久化到Meta center中,按需加载到计算节点中执行。SQL相关的执行逻辑会发送到SQL engine中执行,然后获取执行结果,控制流程等相关的逻辑会在PL engine中执行。
自定义函数在真正执行前会注册到运行时函数管理中心,同时整个执行过程中单条Query的内存大小会被严格限制。
函数下推
PolarDB-X通过识别SQL DATA ACCESS字段,来判断是否需要将该自定义函数在DN上进行注册,当且仅当SQL DATA ACCESS字段为no sql时,该函数会同时在DN上进行注册。在DN上注册后,该函数便具备了在DN上执行的条件,即该自定义函数可被下推。
为了保持和MySQL的兼容性,PolarDB-X的自定义函数均会注册到MySQL库中。
函数下推与扩缩容
扩容后需要手动执行pushdown udf指令,将可下推的自定义函数在新的DN节点进行注册。
与MySQL的区别
自定义函数中仅允许DQL,不允许DML和DDL等涉及到数据修改的操作。
MySQL的存储函数为库级别,PolarDB-X的自定义函数为实例级别。
由于涉及到自定义函数的下推逻辑,因此SQL DATA ACCESS字段不允许修改。
注意事项
5.4.16及以上版本支持此功能。
语法
创建自定义函数
CREATE
[DEFINER = user]
FUNCTION sp_name ([func_parameter[,...]])
RETURNS type
[characteristic ...] routine_body
func_parameter:
param_name type
characteristic:
COMMENT 'string'
| LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
routine_body:
Valid SQL routine statement示例
CREATE FUNCTION my_mul(x int, y int)
RETURNS int
LANGUAGE SQL
DETERMINISTIC
COMMENT 'my multiply function'
RETURN x*y*31;调用自定义函数
自定义函数与普通的系统内置函数调用方法一致。
删除自定义函数
DROP FUNCTION [IF EXISTS] FUNCTION_NAME;修改自定义函数
ALTER FUNCTION func_name [characteristic ...]
characteristic: {
COMMENT 'string'
| LANGUAGE SQL
| SQL SECURITY { DEFINER | INVOKER }
}查看所有已定义的自定义函数
SELECT * FROM information_schema.Routines WHERE ROUTINE_TYPE = 'FUNCTION';查看某个特定的自定义函数
SHOW FUNCTION STATUS [LIKE 'pattern' | WHERE expr]SHOW CREATE FUNCTION 函数名;SELECT * FROM information_schema.Routines WHERE ROUTINE_NAME = '函数名';查看已下推的自定义函数
SELECT * FROM information_schema.pushed_function;取消正在执行的自定义函数
使用kill命令结束正在执行的查询即可。
kill {query | connection} connection_id;自定义函数缓存管理
自定义函数的所有元信息,即是否存在某自定义函数,始终会在缓存中,但具体的函数体仅会在需要时被加载。
查看缓存条目
select * from information_schema.function_cache;查看缓存容量
select * from information_schema.function_cache_capacity;设置缓存大小
resize function cache num;清空缓存
clear function cache;重新加载自定义函数
reload functions;示例
# 开始创建自定义函数
CREATE FUNCTION my_mul(x int, y int)
RETURNS int
LANGUAGE SQL
DETERMINISTIC
COMMENT 'my multiply function'
RETURN x*y*31;
# 此时未进行任何调用,查看function_cache,发现cache中已包含该function
# 而size为0,说明并没有真正进行加载
select * from information_schema.function_cache;
+--------------------+--------------+------+
| ID | FUNCTION | SIZE |
+--------------------+--------------+------+
| xx.xx.xx.xx:3000 | mysql.my_mul | 0 |
| yy.yy.yy.yy:3100 | mysql.my_mul | 0 |
+--------------------+--------------+------+
# 调用my_mul
select my_mul(2,2);
+--------------+
| my_mul(2, 2) |
+--------------+
| 124 |
+--------------+
# 查看相关视图,发现已经进行了加载
select * from information_schema.function_cache;
+--------------------+--------------+------+
| ID | FUNCTION | SIZE |
+--------------------+--------------+------+
| xx.xx.xx.xx:3000 | mysql.my_mul | 0 |
| yy.yy.yy.yy:3100 | mysql.my_mul | 79 |
+--------------------+--------------+------+
select * from information_schema.function_cache_capacity;
+--------------------+-----------+-------------+
| ID | USED_SIZE | TOTAL_SIZE |
+--------------------+-----------+-------------+
| xx.xx.xx.xx:3000 | 0 | 15139759718 |
| yy.yy.yy.yy:3100 | 79 | 15139759718 |
+--------------------+-----------+-------------+
# reload function后,缓存被重置
reload functions;
# 查看相关视图,发现已被重置
select * from information_schema.function_cache;
+--------------------+--------------+------+
| ID | FUNCTION | SIZE |
+--------------------+--------------+------+
| xx.xx.xx.xx:3000 | mysql.my_mul | 0 |
| yy.yy.yy.yy:3100 | mysql.my_mul | 0 |
+--------------------+--------------+------+自定义函数资源管理
内存管理
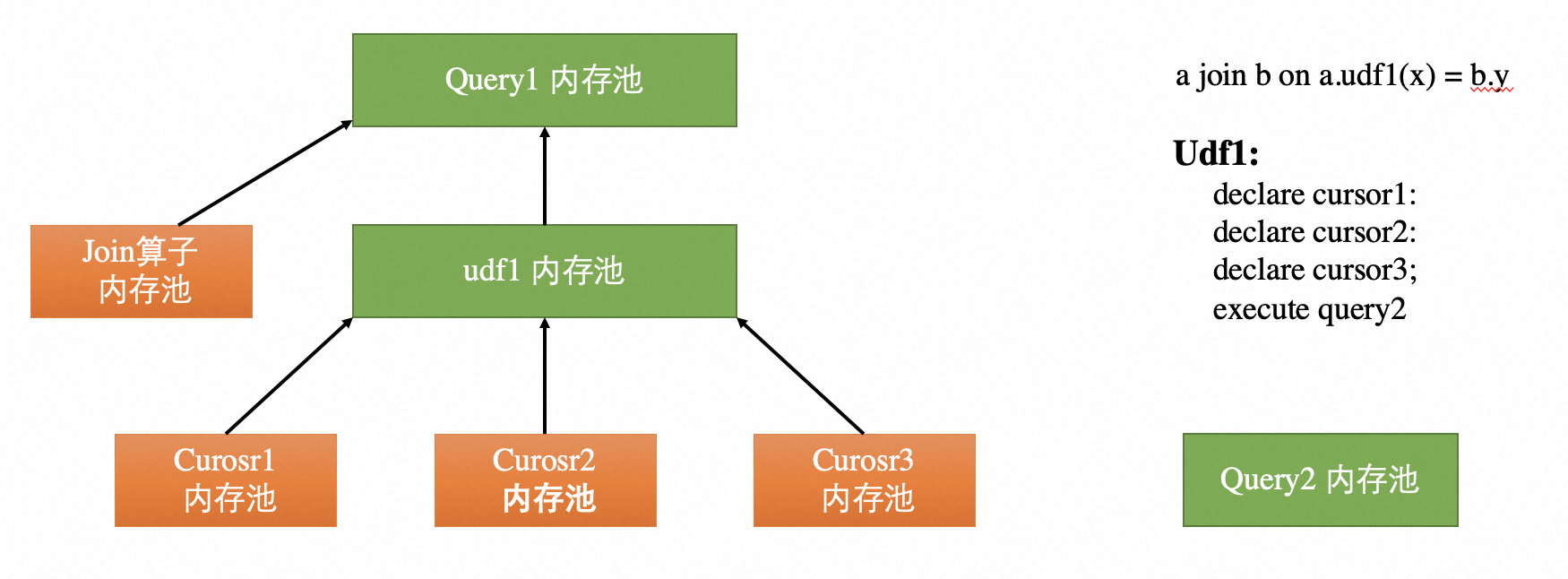
自定义函数执行过程中的内存占用主要为缓存的Cursor,因此PolarDB-X对单个Cursor所能使用的最大内存以及整个自定义函数在执行时占用的内存进行了限制,由参数PL_CURSOR_MEMORY_LIMIT和PL_MEMORY_LIMIT控制。同时,调用自定义函数的整个查询语句的内存也会被限制。
建议PL_CURSOR_MEMORY_LIMIT的值不小于128k,即131072,同时PL_CURSOR_MEMORY_LIMIT不应当大于PL_MEMORY_LIMIT。
其中,变量PL_CURSOR_MEMORY_LIMIT用于控制每个Cursor所占用的内存,超过该阈值时会溢出到硬盘中;变量PL_MEMORY_LIMIT用于控制每个自定义函数所能使用的最大内存。
调用深度限制
可通过参数MAX_PL_DEPTH对调用深度进行限制,因为过深的调用不利于理解自定义函数的执行逻辑,同时会导致大量资源的占用。