本文介绍基于Tair(企业版)的向量检索能力与大语言模型(Large Language Model, LLM)构建企业专属Chatbot的解决方案。
背景信息
大语言模型已具备了相当丰富的基础知识、阅读理解和逻辑推理能力。但想在实际使用过程中充分发挥它的潜力,仍需提供额外的信息进行辅助,原因如下:
不了解私域数据:尽管大语言模型已通过大量训练样本,但无法保证其已学习、掌握指定的私域数据或新知识。
不具备多轮对话能力:大语言模型能够接收的请求大小(即Token数)是有限制的,通常是4 KB~32 KB之间,并且响应速度随着请求变大而变慢。以ChatGLM为例,将用户的历史记录作为请求的一部分持续追加,当超过Token数限制时就需要丢弃老的聊天记录,无法实现长期、多轮对话能力。
因此,可以使用Tair(企业版)作为大语言模型的外部存储,将私域数据和长期对话记录存储在Tair向量检索中,结合Tair高效的向量检索能力与大语言模型的AI能力,使企业专属Chatbot更加智能。
Tair特性与优势
Tair向量检索是在Tair(企业版)的基础上,以内置引擎的方式,为用户提供实时高性能、多模混合检索、简单易用的向量数据库服务。
实时高性能:所有操作均在内存中进行,支持FLAT、HNSW索引算法,支持欧式距离、向量内积、余弦距离等多种距离函数,索引创建与向量数据点查询的时延均小于1ms,更多信息请参见TairVector性能白皮书。
多模混合检索:完全兼容Redis生态与使用方式,同时还支持向量检索、全文检索及其他多种扩展数据结构,更多信息请参见Tair扩展数据结构概览。
简单易用:1 GB规格(低成本)起步,支持在线扩、缩容,最高可扩容至16 TB集群。
应用场景
私域数据问答
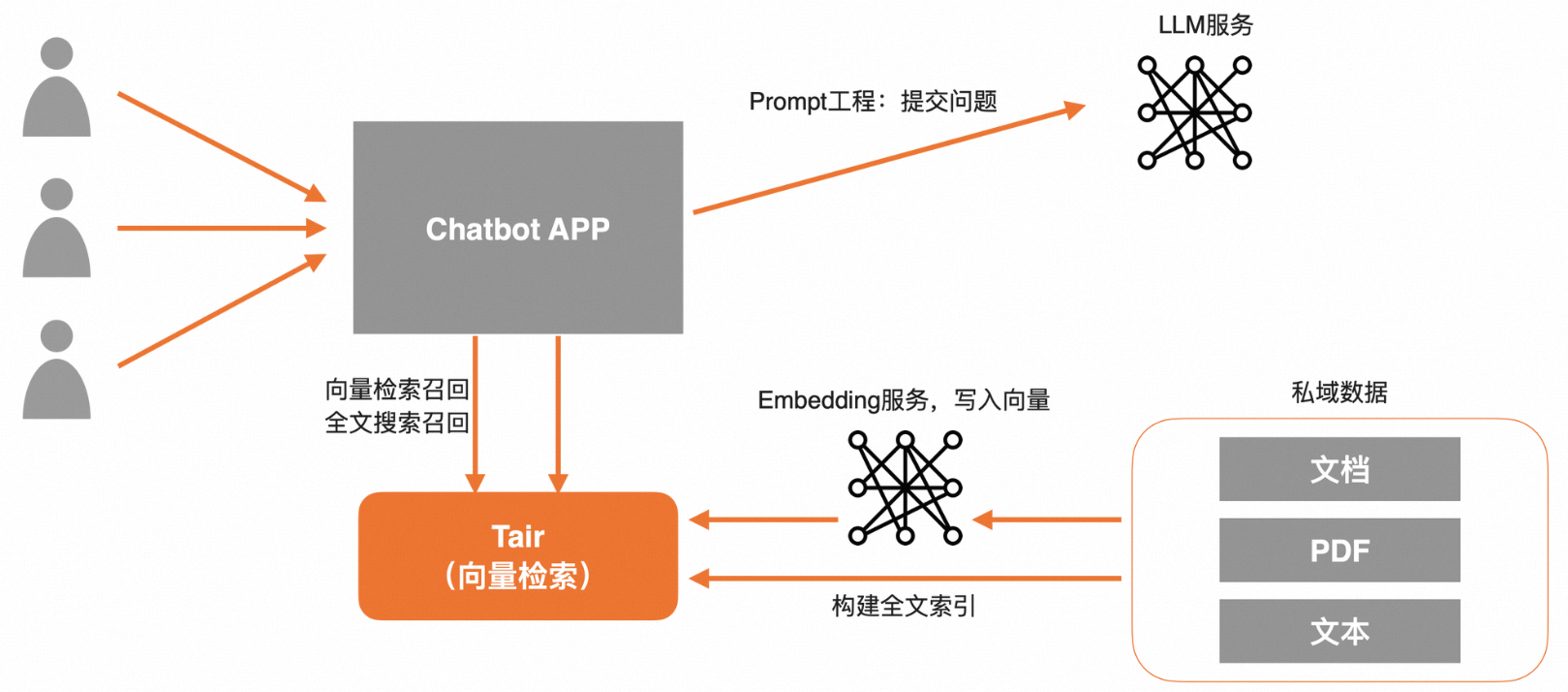
提前将私域数据写入Tair向量中,同时也可以在Tair中构建一份全文索引。在请求LLM前,Tair支持提供向量检索和全文检索两路召回,再通过Prompt润色,一并将问题与私域数据提交给LLM,可实现企业专属Chatbot定制。
长Session会话
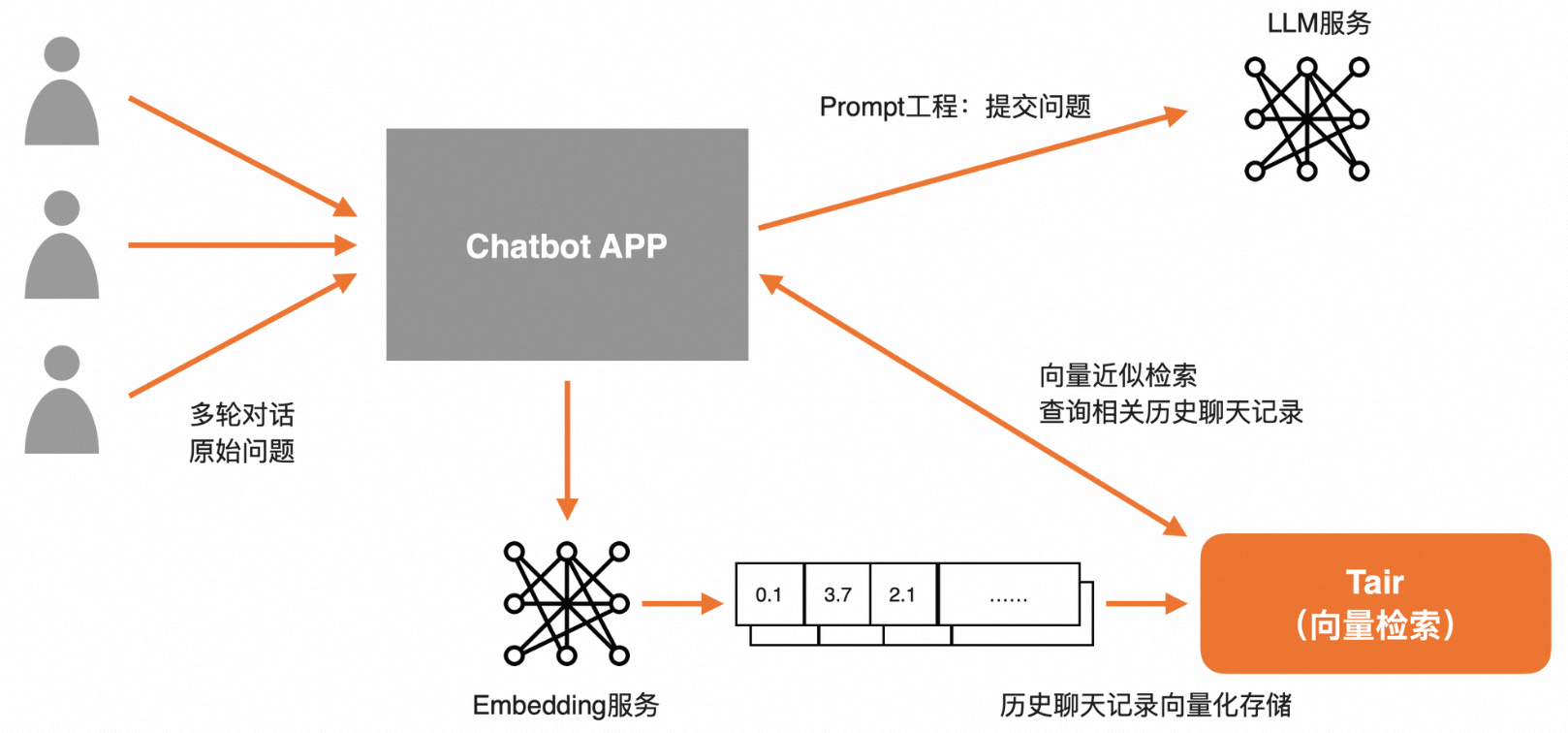
将用户的历史会话记录存储在Session中(支持设置TTL等过期机制)。在请求LLM前,通过Tair向量检索技术将相关历史信息检索出来,再通过Prompt润色后,一并提交给LLM,可实现基于长期、多轮对话下的上下文感知能力。
快速体验
在阿里云云速搭CADT平台中已上线大模型结合Tair构建企业级专属Chatbot解决方案。
该方案模板中已预部署ECS和Tair实例,预安装了前置安装包,Demo中已实现了私域数据问答、长Session会话功能,您可以结合教程快速体验专属Chatbot,更多信息请参见大模型结合Tair构建企业级专属Chatbot。
代码说明
本项目来自于开源项目langchain-ChatGLM,其中向量数据库使用Tair、模型为ChatGLM-6B,请自觉遵守相关协议及法律法规等。
如下图所示,灰色箭头表示文本(TXT)文件经过一系列处理,把向量信息以及切分后的原始文本一起写入到Tair中。橙色箭头表示在用户发起一个查询后,先从Tair中检索出最相似的TopK个向量,然后与用户问题进行Prompt,一并提交给LLM,让LLM更好地回答用户的问题。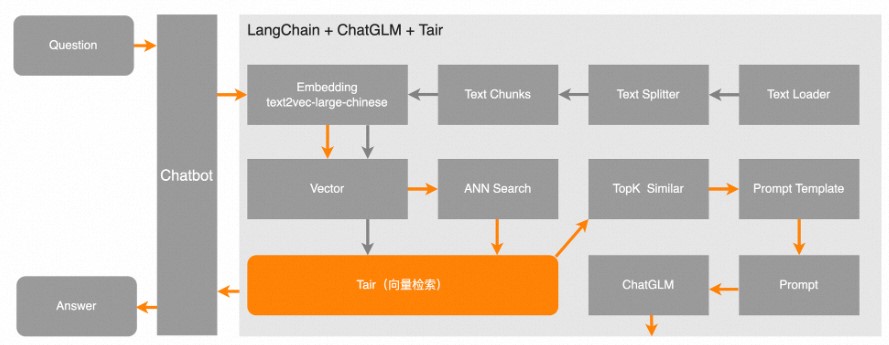
以下代码仅说明Tair与大语言模型结合的部分,具体Demo运行,请参见快速体验章节。
# -*- coding: utf-8 -*-
# !/usr/bin/env python
import torch
from langchain.document_loaders import TextLoader
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from transformers import AutoTokenizer, AutoModel
from langchain.vectorstores import Tair
from utils import ChineseTextSplitter
from langchain.schema import Document
from typing import List
from tair import Tair as TairClient
TOPK = 2
EMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
PROMPT_TEMPLATE =
"""
已知信息:
{context}
根据上述已知信息,简洁回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,答案请使用中文。 问题是:{question}
"""
PROMPT_TEMPLATE_SESSION =
"""
已知用户以前提供的问题:
{context}
根据上述已知信息,简洁回答用户问题。如果无法从中得到答案,请自行回答用户问题,答案请使用中文。 问题是:{question}
"""
class ChatBot():
"""
使用开源模型,请遵循相关协议及法律法规。参数说明:
tair_url: Tair的连接地址,例如"redis://account_name:account_password@r-bp10xx****.redis.rds.aliyuncs.com:6379"。
GanymedeNil/text2vec-large-chinese:需下载"https://huggingface.co/GanymedeNil/text2vec-large-chinese",并替换为本地目录。
THUDM/chatglm-6b:需下载"https://huggingface.co/THUDM/chatglm-6b",并替换为本地目录。
"""
def __init__(self, tair_url):
self.tair_url = tair_url
self.text_embeddings_model= HuggingFaceEmbeddings(model_name='GanymedeNil/text2vec-large-chinese',
model_kwargs={'device': EMBEDDING_DEVICE})
self.tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
self.llm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
self.tair_session_client = TairClient.from_url(tair_url)
"""
该代码示例的私域数据存储langchain的index中。
"""
def get_langchain_tair(self, index_name="langchain"):
return Tair(self.text_embeddings_model, self.tair_url, index_name)
"""
结合EXPIRE可以给某个index设置过期时间。
"""
def expire_index(self, index_name):
return self.tair_session_client.expire(index_name, 1200)
"""
判断不存在某个index,不存在返回True, 存在返回False。
"""
def not_exists_index(self, session_id):
index = self.tair_session_client.tvs_get_index(session_id)
if index is not None:
return False
return True
"""
与大模型交互接口,该代码示例的history为空,LLM中对history的处理,请参考"https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/webui.py"。
"""
def chat(self, question:str):
response, history = self.llm_model.chat(self.tokenizer, question, history=[])
return response
"""
写入私域数据,该方法需输入文件路径。
ChineseTextSplitter请参考"https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/textsplitter/chinese_text_splitter.py"。
"""
def insert_text(self,filepath:str):
loader = TextLoader(filepath, autodetect_encoding=True)
textsplitter = ChineseTextSplitter(pdf=False, sentence_size=100)
docs= loader.load_and_split(textsplitter)
self.insert_text_to_tair(docs,filepath)
"""
Tair.from_documents具体实现,请参考"https://github.com/langchain-ai/langchain/blob/master/libs/community/langchain_community/vectorstores/tair.py"。
最终也是调用Tair的TVS.HSET接口写入向量与标量。
"""
def insert_text_to_tair(self,docs:List[Document]=None,filename:str=""):
Tair.from_documents(docs, self.text_embeddings_model, tair_url=self.tair_url)
"""
结合私域数据,做prompt提交给大模型。
"""
def chat_by_prompt(self,query:str,topk:int=TOPK):
context = self.get_langchain_tair().similarity_search(query, k=topk)
context = "\n".join([doc.page_content for doc in context])
prompt = PROMPT_TEMPLATE.replace("{question}", query).replace("{context}", context)
response = self.chat(prompt)
return response
"""
获取用户历史会话Session,根据用户的历史提示回答问题。
"""
def get_prompt_by_tair_session(self, query, session_id):
if self.not_exists_index(session_id):
prompt = query
return prompt
related_docs_with_score = self.get_langchain_tair(session_id).similarity_search(query, k=self.top_k)
if len(related_docs_with_score)>0:
context = "\n".join([doc.page_content for doc in related_docs_with_score])
prompt = PROMPT_TEMPLATE_SESSION.replace("{question}", query).replace("{context}", context)
else:
prompt = query
return prompt
"""
将用户历史回答写入Session。关于Session如何存储仍需不断探索,您可以根据自己的需求进行定制化开发。
"""
def insert_tair_session(self, query, resp, session_id):
text = f"{query}"
Tair.from_texts([text], self.embeddings, None, session_id, "content", "metadata", tair_url=self.insert_tair_session, index_type="FLAT")
self.expire_index(session_id)效果展示
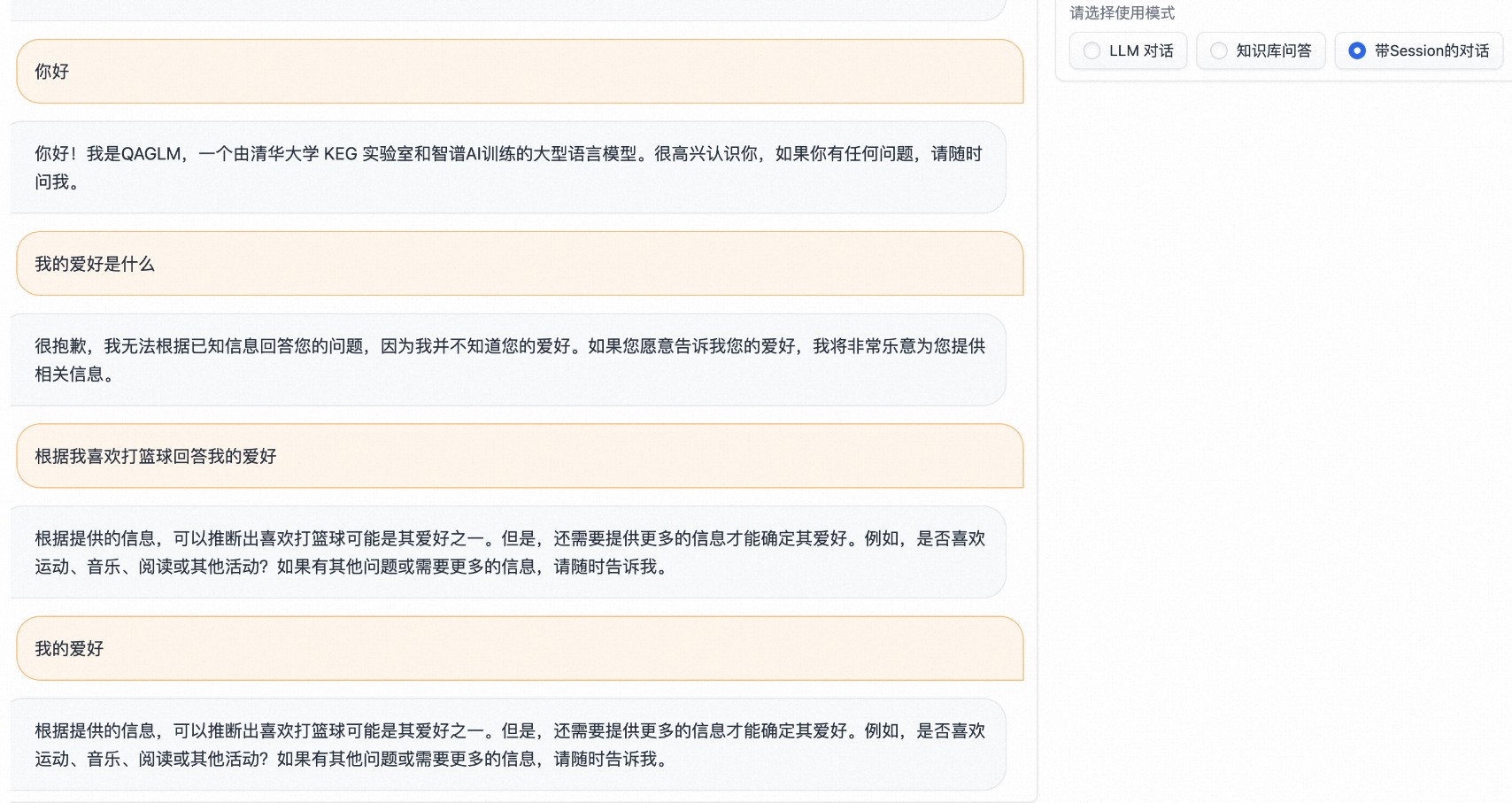
私域数据问答
下图展示了上传私域数据,回答私域数据问题的示例。
长Session会话
下图展示了根据用户已提供的信息,回答用户问题的示例。