
本文介绍基于Tair向量检索(Vector)实现条件过滤、向量检索、全文检索融合的混合检索方案。
背景信息
大语言模型(Large Language Model, LLM)的发展使得文本、图片、音视频等非结构化数据都可以通过向量来表示其语义信息,基于向量的KNN检索在语义搜索、商品推荐、智能问答等领域有非常大的潜力。当前大多数产品通常仅支持经典的条件过滤、全文索引、向量检索这三类检索方案的一种或者两种组合,这三种检索方案的优缺点非常明显:
条件过滤:基于多种布尔条件组合过滤,对数据集和使用方式有严格的约束,限制了用户使用场景。
全文检索:针对用户通用查询Query,通过分词并计算文档相关度,返回相关性最高的结果列表。一般限于文本类字段的查询,且难以处理用户输入错误等语法问题。
向量检索:首先进行语义编码,通过计算向量之间相关度,返回相关性最高的结果列表。可以处理文档、图片、音视频等各类非结构化数据,极大拓展了应用场景,不过也存在高度依赖LLM的效果、对私域数据处理不准确等问题。
基于Tair向量检索可以在数据不出库情况下实现条件过滤、全文检索、向量检索三类检索方案的任意组合。您仅需通过一条查询语句即可实现三路结果召回,例如通过待检索的图片、文本、音视频等文件进行向量检索召回、通过输入的文本进行全文检索召回、通过布尔表达式进行条件过滤召回等,Tair向量检索还会对三路召回结果进行权重排序,返回最终的候选列表。
通过多路召回,可以避免因仅使用一种检索方案而受到单检索方案的能力限制,通过多种数据资源提高检索命中率。同时也支持针对特定的请求,通过hybrid_ratio参数调整不同检索方式的权重,更多信息请参见Vector。
方案概述
本示例将使用fashion-product-images-small开源数据集演示不同检索方案的效果。
请自觉遵守开源数据集的相关协议及法律法规等。
数据说明
该数据集包含4.4万条商品数据,数据格式如下:
id (int64) | gender (string) | masterCategory (string) | subCategory (string) | articleType (string) | baseColour (string) | season (string) | year (float64) | usage (string) | productDisplayName (string) | image (dict) |
15,970 | "Men" | "Apparel" | "Topwear" | "Shirts" | "Navy Blue" | "Fall" | 2,011 | "Casual" | "Turtle Check Men Navy Blue Shirt" | { "bytes": [ 255, 216, 255, ... ], "path": null } |
39,386 | "Men" | "Apparel" | "Bottomwear" | "Jeans" | "Blue" | "Summer" | 2,012 | "Casual" | "Peter England Men Party Blue Jeans" | { "bytes": [ 255, 216, 255, ...], "path": null } |
59,263 | "Women" | "Accessories" | "Watches" | "Watches" | "Silver" | "Winter" | 2,016 | "Casual" | "Titan Women Silver Watch" | { "bytes": [ 255, 216, 255, ...], "path": null } |
数据转换方案
Tair向量检索是简单直观的Tair向量索引Key-Key-(Key-Value)存储结构,首先需要创建一个向量索引(例如hybrid_index),用于存储所有商品数据。再对上述表数据结构进行转换,按照字段可以分为四类:
id:作为Tair向量检索中的主键,可通过该字段可以实现点查操作(只扫描少量数据的查询操作)。
image:通过LLM编码后作为Tair向量检索的向量信息,通过该向量信息可以实现向量检索。
productDisplayName:该字段为image的描述信息,可作为Tair向量检索中的Text文本信息。通过该字段可以实现全文检索。
其他列:作为Tair向量检索的最子级键值对,没有限制数量。通过该键值对可以实现传统的属性过滤检索。
Tair向量检索存储的数据结构示例如下: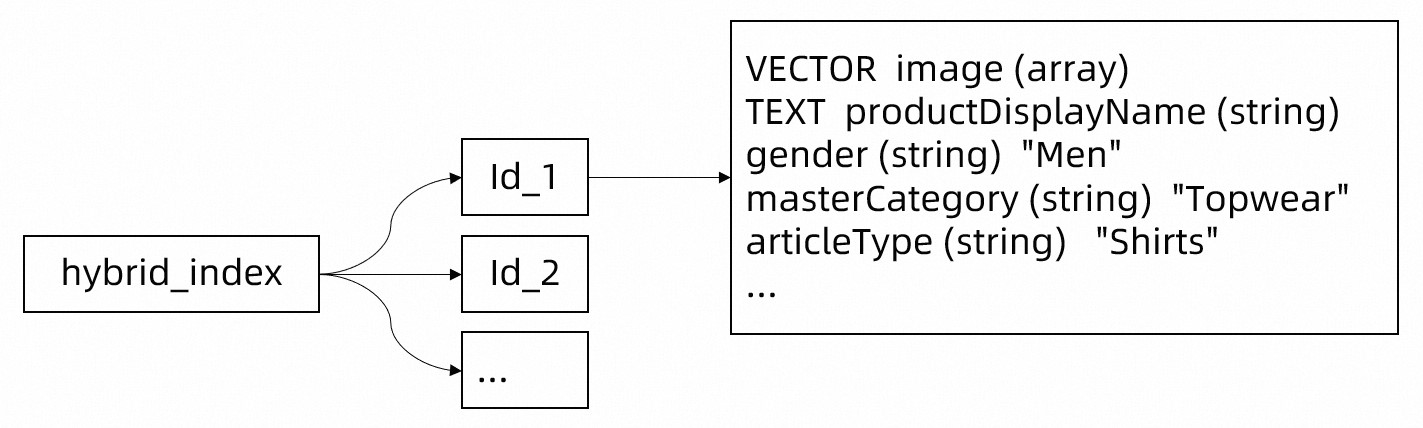
整体流程与示例代码
本示例的整体流程为:
加载数据集。
Tair环境准备。
导入数据集至Tair。
以不同检索方案进行查询。
详情请参见Hybrid search代码工程。
该代码文件为.ipynb文件,使用前需提前执行pip install jupyter命令,安装相关依赖。
查询展示
以下代码仅展示以不同的检索方案进行查询与对应效果。以查询Green Kidswear为例,通过调整hybrid_ratio参数(hybrid_ratio参数为向量检索的权重,全文检索的权重为1-hybrid_ratio),分别测试下面四种场景:
纯向量检索:将hybrid_ratio参数设置为0.9999,查询示例如下。
topk = 20 text = "Green Kidswear" vector = model.encode([text])[0] filter_str = None kwargs = {"TEXT" : text, "hybrid_ratio" : 0.9999} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)执行结果:

纯全文检索:将hybrid_ratio参数设置为0.0001,查询示例如下。
topk = 20 text = ""Green Kidswear" vector = model.encode([text])[0] filter_str = None kwargs = {"TEXT" : text, "hybrid_ratio" : 0.0001} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)执行结果:
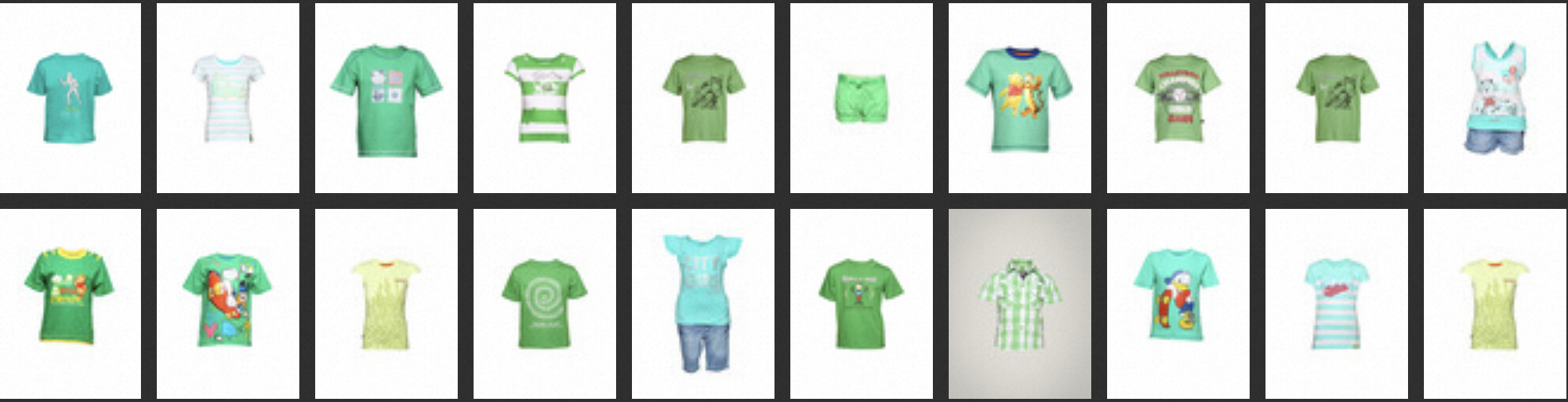
向量、全文混合检索:将hybrid_ratio参数设置为0.5,查询示例如下。
topk = 20 text = ""Green Kidswear" vector = model.encode([text])[0] filter_str = None kwargs = {"TEXT" : text, "hybrid_ratio" : 0.5} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)执行结果:

向量、全文、条件过滤混合检索:将hybrid_ratio参数设置为0.5,同时添加
subCategory == "Topwear"的条件语句,查询示例如下。topk = 20 text = "Green Kidswear" vector = model.encode([text])[0] filter_str = "subCategory == \"Topwear\"" kwargs = {"TEXT" : text, "hybrid_ratio" : 0.5} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) print(result) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)执行结果:

总结
直观上看,无论是向量检索还是全文检索,整体都比较符合查询需求。在排名最高的候选集中,全文检索体验要略微好于向量检索。
在混合检索中,若某一个目标存在于两个召回结果中,则其最终排名会更加靠前。
通过调整hybrid_ratio参数,可以动态对向量检索和全文检索各自召回的结果进行Rerank(重排),以得到更精准的结果。
可以通过条件过滤的方式进一步过滤掉特定的候选集,提高检索命中率。