时序数据的降采样是指将频率较高的时序数据降低到较低频率的时序数据的过程。降采样可以减少数据量从而延长存储时间,提升查询速度,同时尽可能地保留原始数据的趋势和特征。日志服务的降采样通过将时间序列中的数据点进行特定算法的分组与聚合来实现。
本功能不再支持新开通,如果已有的MetricStore已开通降采样功能,则保留该功能。
使用限制
需保证时序库活跃时间线(即最大降采样周期内出现的时间线)的数量小于ReadWrite Shard数 * 100W,否则可能出现降采样库数据不完整的情况。
工作原理
当创建一个降采样配置时,会根据配置的存储时长创建时序子库,并根据配置的聚合周期创建降采样定时任务。第一条降采样配置,由主时序库向第一个时序子库中写入;第二条降采样配置,由第一个时序子库向第二个时序子库中写入,以此类推。当发生降采样配置条目修改时,会根据前后配置差异,自动创建、修改、删除时序子库或降采样定时任务。
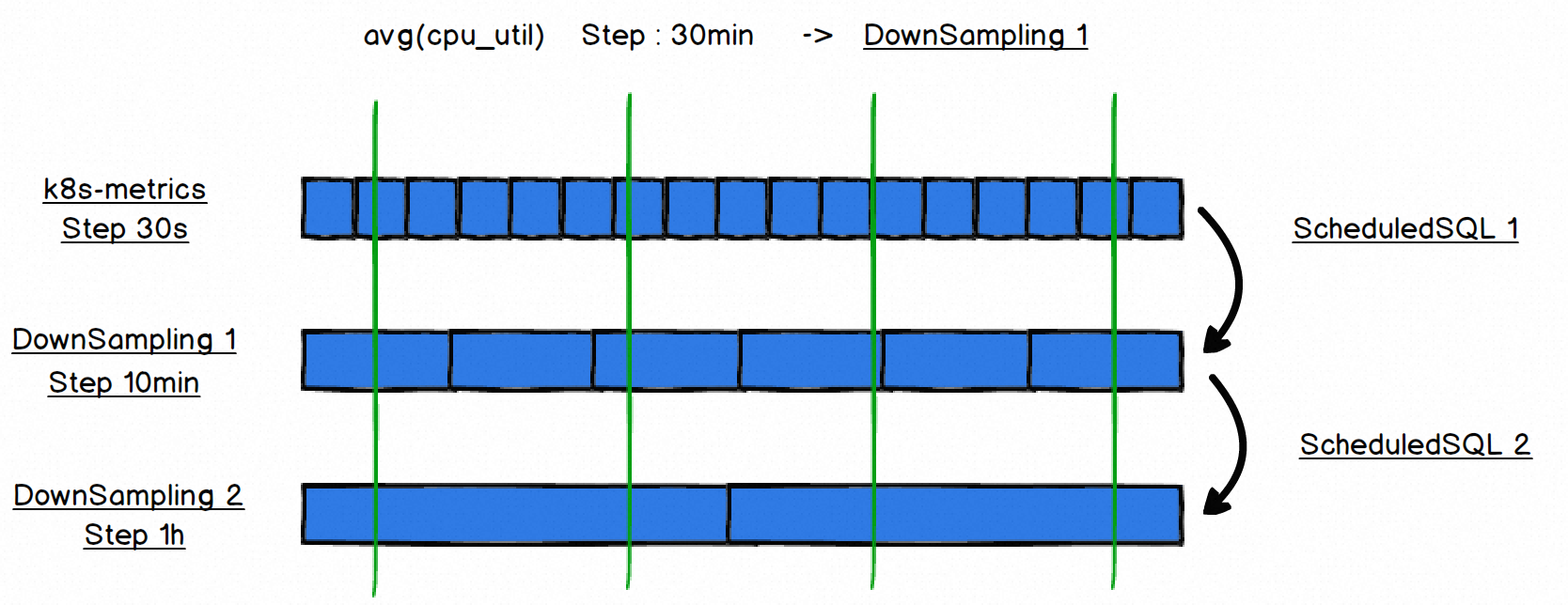
在查询时,如果降采样配置的范围满足查询时间范围,将自动以降采样子库的数据作为查询数据源,以获得超越原始时序库的存储时长、更快的查询速度。例如下述样例,在查询Step为30min时将自动选择降采样 1 的时序库。
资产详情
开启降采样配置后,日志服务会在Project中创建一个专属的MetricStore和定时SQL任务。
MetricStore
监控指标Metricstore用于存储降采样的数据。开启降采样配置后,自动生成该专属Metricstore,其名称为 {metricstore}--ds-{config-no}。
定时SQL任务
定时SQL任务用于定期执行降采样导入。开启降采样配置后,自动生成该专属定时SQL任务,其名称为 {metricstore}_{config-no - 1}_to_{config-no}_downsampling。
创建降采样配置
前提条件
已创建Project和MetricStore。具体操作,请参见创建项目Project和创建MetricStore。
已采集到时序数据。
登录日志服务控制台。
在Project列表区域,单击目标Project。

在页签中,单击目标MetricStore右侧的
 ,进入MetricStore属性页。
,进入MetricStore属性页。单击页面右上角的修改,并单击降采样配置对应的操作。
设置降采样配置参数。
参数
说明
自身指标间隔(秒)
原始时序库中两条相同时间线的采集间隔。
您可以根据实际情况自行填写,也可以单击自动计算。自动计算的方式为,随机提取当前时序库中的一条时间线,计算指标间隔并对齐到5秒。
自身存储时长(天)
原始时序库的数据保存时间。
当MetricStore属性页中原始时序库数据保存时间发生改变时,将自动同步到降采样配置的该字段中,无需自行更改。如果发生了某些特殊情况导致MetricStore属性页中的数据保存时间和降采样配置中记录的时间不一致,可以手动单击同步。
降采样配置
一个原始时序库最多配置5条降采样配置。
支持手动配置降采样参数及自动生成降采样配置。
手动配置:
聚合周期:降采样子库的指标间隔。
重要聚合周期取值需大于等于60且不能为空。
当前配置的聚合周期,必须整除上一个配置(或自身指标间隔)。
当前配置的聚合周期,必须是上一个配置(或自身指标间隔)的2倍及以上。
存储时长:降采样子库的存储时长。
重要存储时长取值必须大于0且不能为空。
当前配置的存储时长,不能低于上一个配置。
自动生成:单击推荐降采样配置,可以根据您当前的指标间隔和存储时长,自动生成降采样配置。
重要单击推荐降采样配置时,已编辑未提交的降采样配置将被覆盖。
单击提交保存配置。
删除降采样配置
删除降采样配置将删除所有降采样配置和相关资源。
在MetricStore属性页中,单击页面右上角的修改,并单击降采样配置对应的操作。
单击删除降采样配置关闭降采样功能。
降采样任务异常处理
当降采样任务发生异常时,可以对任务状态中查看详细原因并进行处理。
在MetricStore属性页中,单击降采样配置对应的查看。
在降采样配置页面中,单击
 查看详细原因。重要
查看详细原因。重要当任务未完成时(运行中、失败),禁止再次提交新任务。
单击重试运行上一个任务,或单击删除降采样配置后重新创建降采样配置。