
阿里云日志服务SLS支持导入Amazon S3中的日志文件。您可以通过数据导入的方式将Amazon S3的日志文件导入到阿里云的日志服务,实现日志的查询分析、加工等操作。目前日志服务只支持导入单个大小不超过5 GB的S3文件,压缩文件大小按照压缩后的大小计算。
前提条件
-
已上传日志文件到S3中。
-
已创建Project和LogStore。具体操作,请参见管理Project和创建基础LogStore。
-
自定义权限:
-
参见如下示例,创建具备操作S3资源权限的自定义权限策略。具体操作,请参见AWS创建自定义权限。
说明S3配置自定义权限后,才可以将S3的文件导入到日志服务。
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::your_bucket_name", "arn:aws:s3:::your_bucket_name/*" ] } ] } -
创建具备操作SQS资源权限的自定义权限策略。具体操作,请参见AWS创建自定义权限。
说明只有当启用SQS开关需要配置。
{ "Effect": "Allow", "Action": [ "sqs:ReceiveMessage", "sqs:DeleteMessage", "sqs:GetQueueAttributes", "kms:Decrypt" ], "Resource": "*" }
-
创建数据导入配置
登录日志服务控制台。
-
在接入数据区域的数据导入页签中,选择S3-数据导入。
-
选择目标Project和LogStore,单击下一步。
-
设置导入配置。
-
在导入配置步骤中,设置如下参数。
参数
说明
任务名称
SLS任务的唯一名称。
S3区域
待导入的文件所在Bucket的地域。
AWS AccessKey ID
用于访问AWS的AWS AccessKey ID。
重要请确保您的AccessKey具有访问AWS相应资源的权限。
AWS Secret AccessKey
用于访问AWS的AWS Secret AccessKey。
SQS Queue URL
SQS队列标识。更多信息,请参见队列和消息的标识。
重要只有当开启了SQS开关后该功能才能生效。
文件路径前缀过滤
通过文件路径前缀过滤S3文件,用于准确定位待导入的文件。例如待导入的文件都在csv/目录下,则可以指定前缀为csv/。
如果不设置该参数,则遍历整个S3 Bucket。
说明建议设置该参数。当Bucket中的文件数量非常多时,全量遍历将导致数据导入效率非常低。
文件路径正则过滤
通过文件路径的正则表达式过滤S3文件,用于准确定位待导入的文件。只有文件名(包含文件路径)匹配该正则表达式的文件才会被导入。默认为空,表示不过滤。
例如S3文件为
testdata/csv/bill.csv,您可以设置正则表达式为(testdata/csv/)(.*)。调整正则表达式的方法,请参见如何调试正则表达式。
文件修改时间过滤
通过文件修改时间过滤S3文件,用于准确定位待导入的文件。
-
所有:如果您想导入所有符合条件的文件,请选择该项。
-
某时间开始:如果您想导入某个时间点后修改过的文件,请选择该项。
-
特定时间范围:如果您想导入某个时间范围内修改过的文件,请选择该项。
数据格式
文件的解析格式,如下所示。
-
CSV:分隔符分割的文本文件,支持指定文件中的首行为字段名称或手动指定字段名称。除字段名称外的每一行都会被解析为日志字段的值。
-
单行JSON:逐行读取S3文件,将每一行看做一个JSON对象进行解析。解析后,JSON对象中的各个字段对应为日志中的各个字段。
-
单行文本日志:将S3文件中的每一行解析为一条日志。
-
跨行文本日志:多行模式,支持指定首行或者尾行的正则表达式解析日志。
压缩格式
待导入的S3文件的压缩格式,日志服务根据对应格式进行解压并读取数据。
编码格式
待导入的S3文件的编码格式。目前仅支持UTF-8和GBK。
检查新文件周期
如果目标S3文件路径中不断有新文件产生,您可以根据需求设置检查新文件周期。设置后,导入任务会一直在后台运行,自动周期性地发现并读取新文件(后台保证不会将同一个S3文件中的数据重复写入到日志服务)。
如果目标S3文件路径中不再产生新文件,请修改为永不检查,即导入任务读取完所有符合条件的文件后,将自动退出。
日志时间配置
时间字段
当选择数据格式为CSV、单行JSON时,您可以设置一个时间字段,即设置为文件中代表时间的列名,用于指定导入日志到日志服务时的时间。
提取时间正则
您可以使用正则表达式提取日志中的时间。
例如日志样例为127.0.0.1 - - [10/Sep/2018:12:36:49 0800] "GET /index.html HTTP/1.1"时,则您可以设置提取时间正则为
[0-9]{0,2}\/[0-9a-zA-Z]+\/[0-9:,]+。说明针对其他类型的数据格式,如果您只需提取时间字段中的部分内容,也可通过正则表达式提取。
时间字段格式
指定时间格式,用于解析时间字段的值。
-
支持Java SimpleDateFormat语法的时间格式,例如
yyyy-MM-dd HH:mm:ss。时间格式的语法详情,请参见Class SimpleDateFormat。常见的时间格式,请参见时间格式。 -
支持epoch格式,包括epoch、epochMillis、epochMicro和epochNano。
时间字段分区
选择时间字段对应的时区。当时间字段格式为epoch类别时,不需要设置时区。
如果解析日志时间需要考虑夏令时,可以选择UTC格式;否则,选择GMT格式。
说明默认使用东八区时间。
当选择数据格式为CSV时,需要额外设置相关参数,具体说明如下表所示。
-
CSV特有参数
参数
说明
分隔符
设置日志的分隔符,默认值为半角逗号(,)。
引号
CSV字符串所使用的引号字符。
转义符
配置日志的转义符,默认值为反斜线(\)。
日志最大跨行数
打开首行作为字段名称开关后,将使用CSV文件中的首行作为字段名称。
自定义字段列表
关闭首行作为字段名称开关后,请根据需求自定义日志字段名称,多个字段名称之间用半角逗号(,)隔开。
跳过行数
指定跳过的日志行数。例如设置为1,则表示从CSV文件中的第2行开始采集日志。
-
跨行文本日志特有参数
参数
说明
正则匹配位置
设置正则表达式匹配的位置,具体说明如下:
-
首行正则:使用正则表达式匹配一条日志的行首,未匹配部分为该条日志的一部分,直到达到最大行数。
-
尾行正则:使用正则表达式匹配一条日志的行尾,未匹配部分为下一条日志的一部分,直到达到最大行数。
正则表达式
根据日志内容,设置正确的正则表达式。
调整正则表达式的方法,请参见如何调试正则表达式。
最大行数
一条日志的最大行数。
-
-
-
单击预览,预览导入结果。
-
确认无误后,单击下一步。
-
-
预览数据及创建索引,然后单击下一步。
日志服务默认开启全文索引。您也可以根据采集到的日志,手动创建字段索引,或者单击自动生成索引,日志服务将自动生成字段索引。更多信息,请参见创建索引。
重要如果您要查询和分析日志,那么全文索引和字段索引必须至少启用一种。同时启用时,以字段索引为准。
查看导入配置
创建导入配置成功后,您可以在控制台中查看已创建的导入配置及生成的统计报表。
-
在Project列表区域,单击目标Project。
-
在中,选择目标日志库下的,单击配置名称。
-
查看导入配置的基本信息和统计报表。
-
您还可以修改配置、开始或停止导入、删除配置 。
警告删除配置后不可恢复,请谨慎操作。
费用说明
日志服务不针对导入功能收取费用,但导入功能需要访问服务商API,会产生对应的流量费用和请求费用。相关计价模型如下,具体的费用以服务商账单为准。
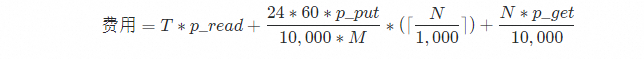
|
字段 |
说明 |
|
|
每天导入的总数据量,单位:GB。 |
|
|
每GB数据的外网流出费用。 |
|
|
每万次的Put类型请求费用。 |
|
|
每万次的Get类型请求费用。 |
|
|
新文件检查周期,单位:分钟。 您可以在创建数据导入配置时,设置检查新文件周期。 |
|
|
Bucket中根据前缀可列出的文件数量。 |
常见问题
|
问题 |
可能原因 |
解决方法 |
|
预览时显示无数据。 |
S3中没有文件、文件中没有数据或者没有符合过滤条件的文件。 |
|
|
数据中存在乱码。 |
数据格式、压缩格式或编码格式配置不符合预期。 |
确认S3文件的真实格式,然后调整数据格式、压缩格式或编码格式等配置项。 如果需要修复已有的乱码数据,请创建新的LogStore和导入配置。 |
|
日志服务中显示的数据时间和数据本身的时间不一致。 |
设置导入配置时,没有指定日志时间字段或者设置时间格式、时区有误。 |
设置指定的日志时间字段以及正确的时间格式和时区。更多信息,请参见日志时间配置。 |
|
导入数据后,无法查询和分析数据。 |
|
|
|
导入的数据条目数量少于预期。 |
部分文件存在单行数据大小超过3 MB的数据,导致数据在导入过程中被丢弃。更多信息,请参见采集限制。 |
写入数据到S3文件时,避免单行数据大小超过3 MB。 |
|
文件数量和总数据量都很大,但导入数据的速度不及预期(正常情况下,可达到80 MB/s)。 |
LogStore Shard数量过少。更多信息,请参见性能限制。 |
LogStore Shard数量较少时,请尝试增加Shard的个数(10个及以上),并观察延迟情况。具体操作,请参见管理Shard。 |
|
部分文件没有导入。 |
过滤条件设置存在问题或者存在单个文件大小超出5 GB的文件。更多信息,请参见采集限制。 |
|
|
多行文本日志解析错误。 |
首行正则表达式或尾行正则表达式设置错误。 |
检查首行正则表达式或尾行正则表达式的正确性。 |
|
新文件导入延迟大。 |
存量文件太多(即符合文件路径前缀过滤的文件数量太多)。 |
如果符合文件路径前缀过滤条件文件数量太多(超过100万),建议前缀设置的更加详细,同时创建多个任务来进行数据导入。否则,发现新文件的效率非常低。 |
错误处理机制
|
错误项 |
说明 |
|
读取文件失败 |
读文件时,如果遇到文件不完整的错误(例如由网络异常、文件损坏等导致),导入任务会自动重试,重试3次后仍然读取失败,将跳过该文件。 重试间隔和检查新文件周期一致。如果检查新文件周期为永不检查,则重试周期为5分钟。 |
|
压缩格式解析错误 |
解压文件时,如果遇到文件压缩格式无效的错误,导入任务将直接跳过该文件。 |
|
数据格式解析错误 |
解析数据失败时,导入任务会将原始文本内容存放到日志的content字段中。 |
|
S3 Bucket不存在 |
导入任务会定期重试,即重建Bucket后,导入任务会自动恢复导入。 |
|
权限错误 |
从S3 Bucket读取数据或者写数据到日志服务LogStore存在权限错误时,导入任务会定期重试,即修复权限问题后,导入任务会自动恢复。 遇到权限错误时,导入任务不会跳过任何文件,因此修复权限问题后,导入任务会自动将Bucket中还未被处理的文件中的数据导入到日志服务LogStore中。 |