本文将介绍在主机场景下,当ECS与日志服务的Project属于同一个账号且在同一地域时,日志服务借助运维编排服务OOS,在ECS实例中自动安装LoongCollector采集文本日志的操作流程。
前提条件
已开通日志服务。具体操作,请参见开通日志服务。
已创建Project和Logstore。更多信息,请参见创建项目Project和创建Logstore。
仅支持Project地域:华南2(河源)。
已创建与日志服务Project同账号同地域的可用的ECS。更多信息,请参见云服务器ECS快速入门。若您的主机不满足此条件,请参考LoongCollector采集主机文本日志进行采集配置。
ECS需开放80和443端口,供LoongCollector上传数据。
若您使用的不是阿里云主账号,而是使用RAM用户,需要为RAM用户开通权限。
操作步骤
步骤一:安装LoongCollector与创建机器组
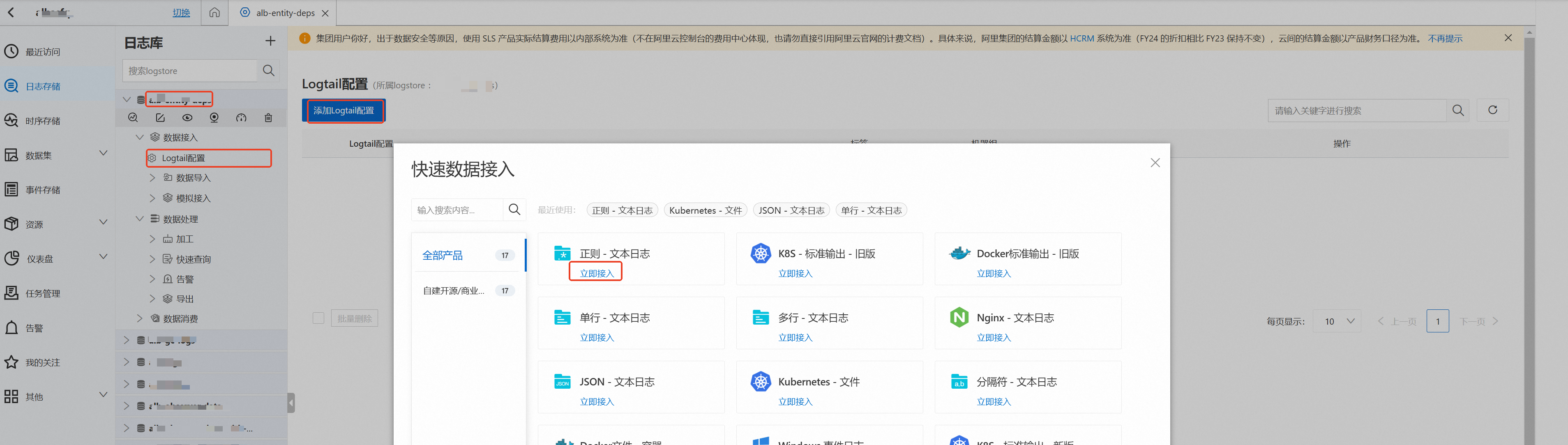
使用创建Project的账号登录日志服务控制台。在Project列表区域,单击创建的Project。

单击您的Project后会进入下图所示页面,按图示在日志存储中选择对应Logstore后在Logtail配置中添加Logtail配置,单击立即接入,本例使用正则-文本日志。
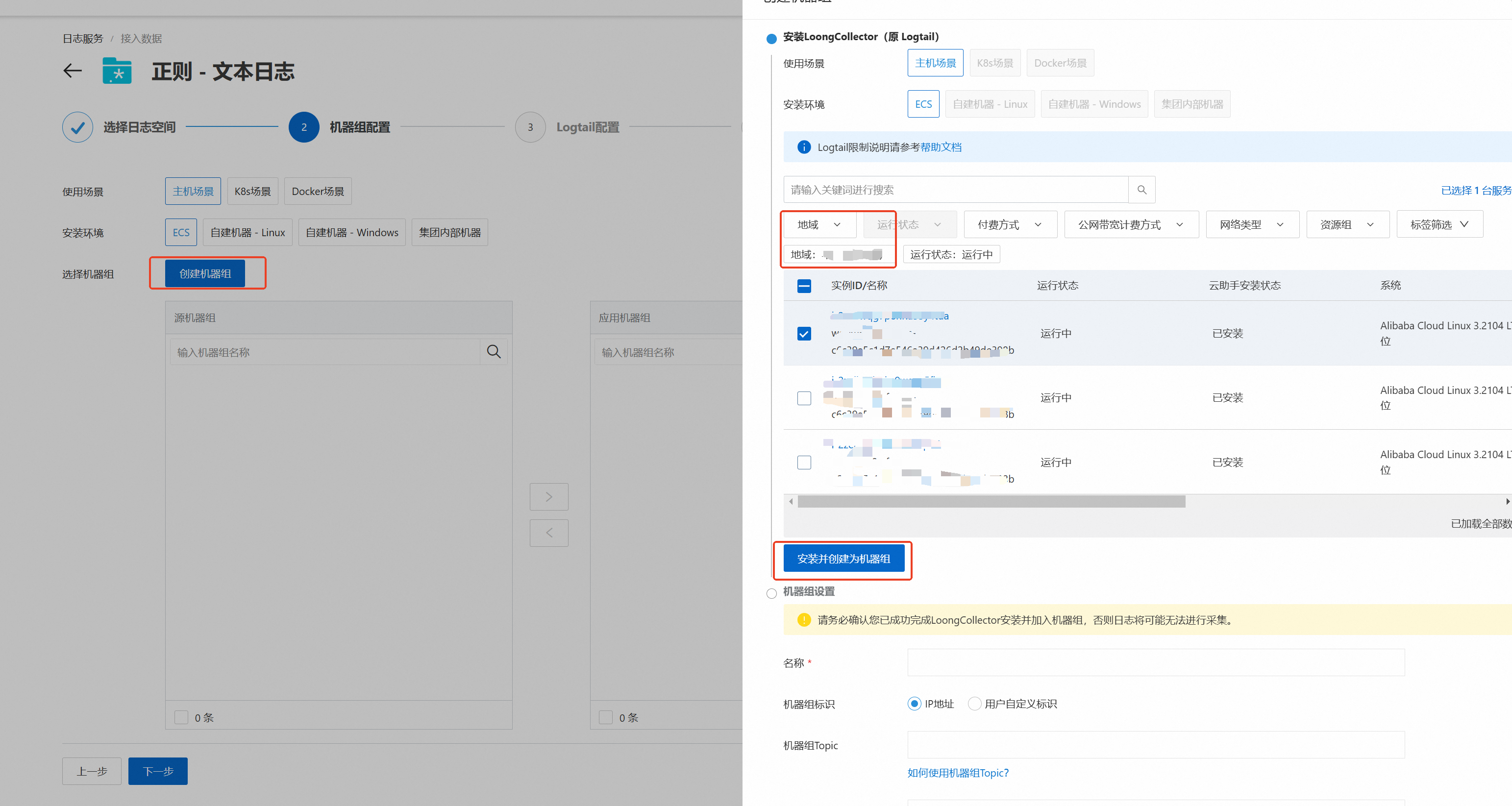
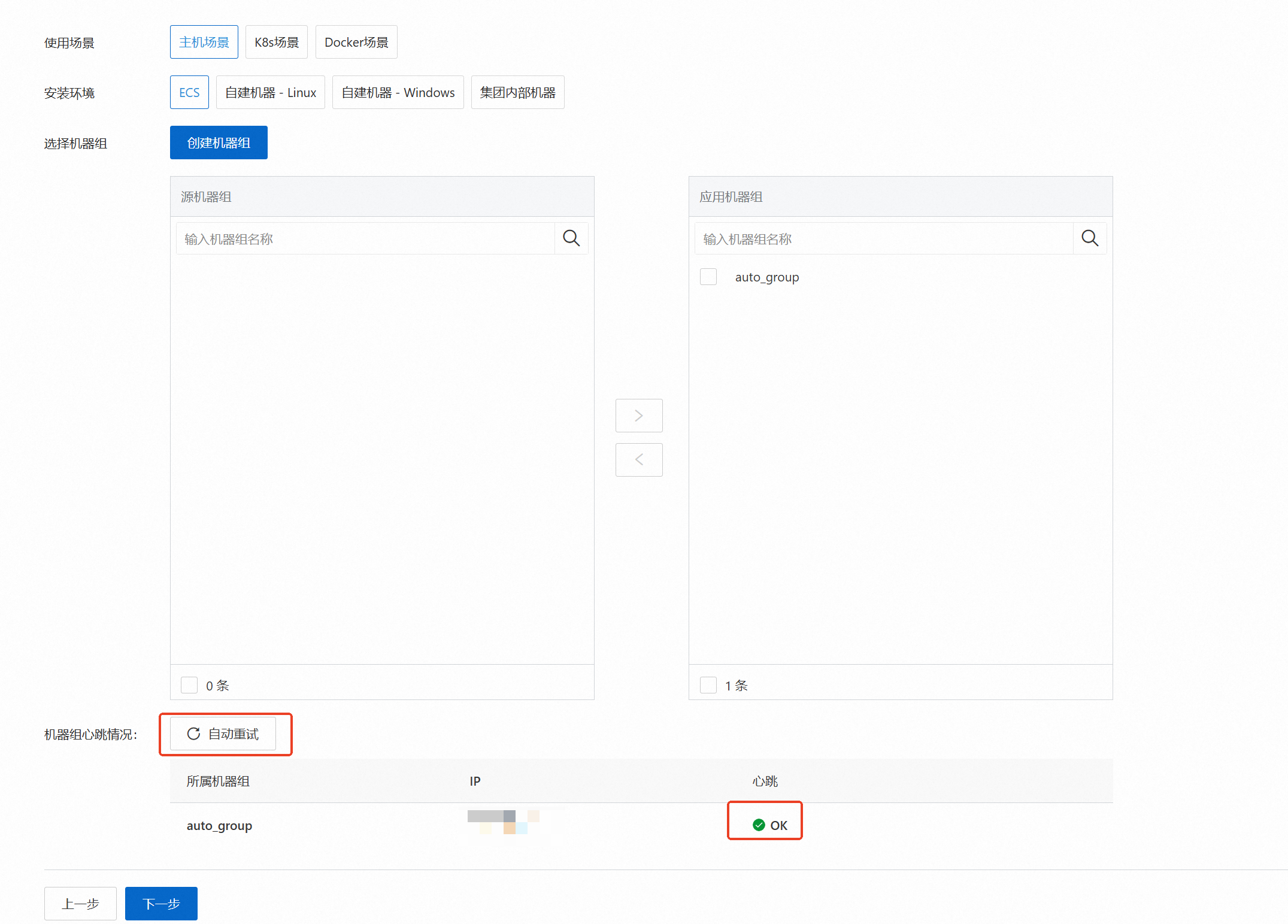
单击,在创建机器组面板中,选择与Project同地域的ECS实例,单击安装并创建为机器组。
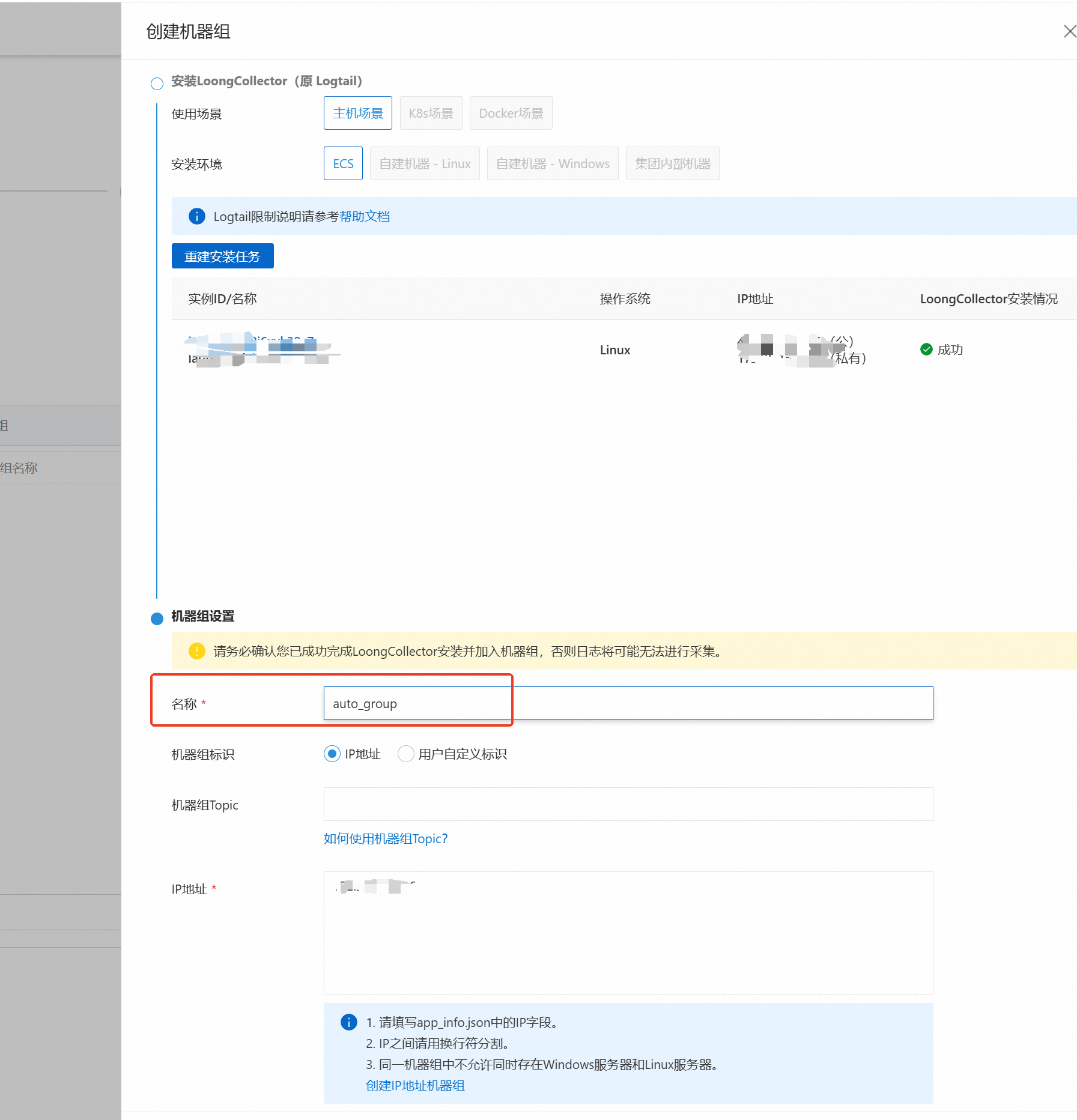
等待安装完成,填写名称后即可点击确定。
点击下一步,如果心跳为FAIL,点击自动重试后等待两分钟左右直到心跳变为OK,点击下一步。此处自动安装LoongCollector同时也为您配置了IP类型机器组,如果您希望修改为用户自定义标识机器组,您可以参考管理机器组。
步骤二:采集配置
在全局配置中输入配置名称。
在输入配置中配置文件路径,代表日志采集的路径,日志路径必须以正斜线(/)开头,例如下图
/data/wwwlogs/main/**/*.Log表示/data/wwwlogs/main目录下后缀名为.Log的文件。如果需要设置日志目录被监控的最大深度,即文件路径中通配符**匹配的最大目录深度。可以修改最大目录监控深度的取值,0代表只监控本层目录。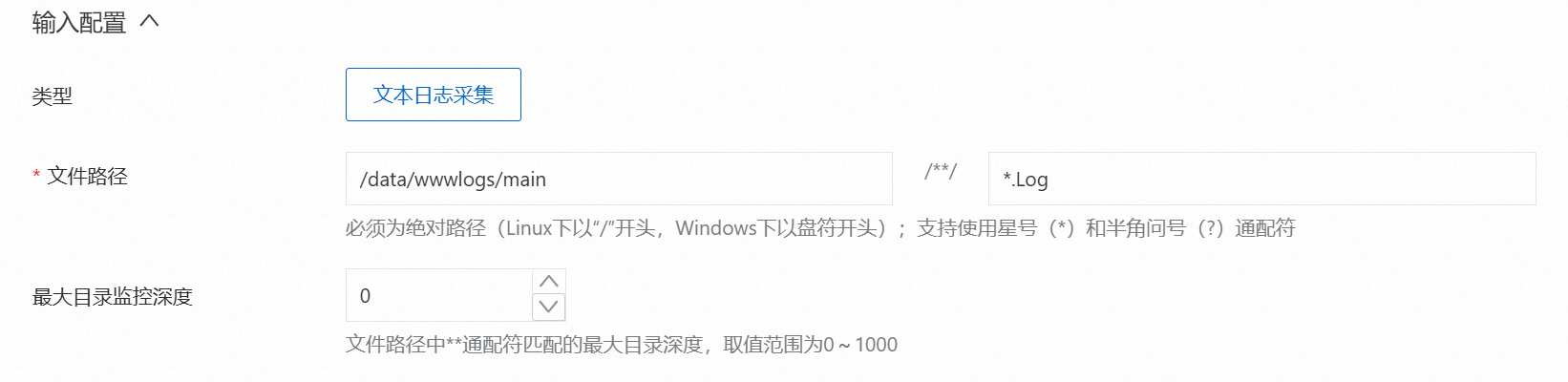
在处理配置中,设置日志样例,多行模式以及处理模式。
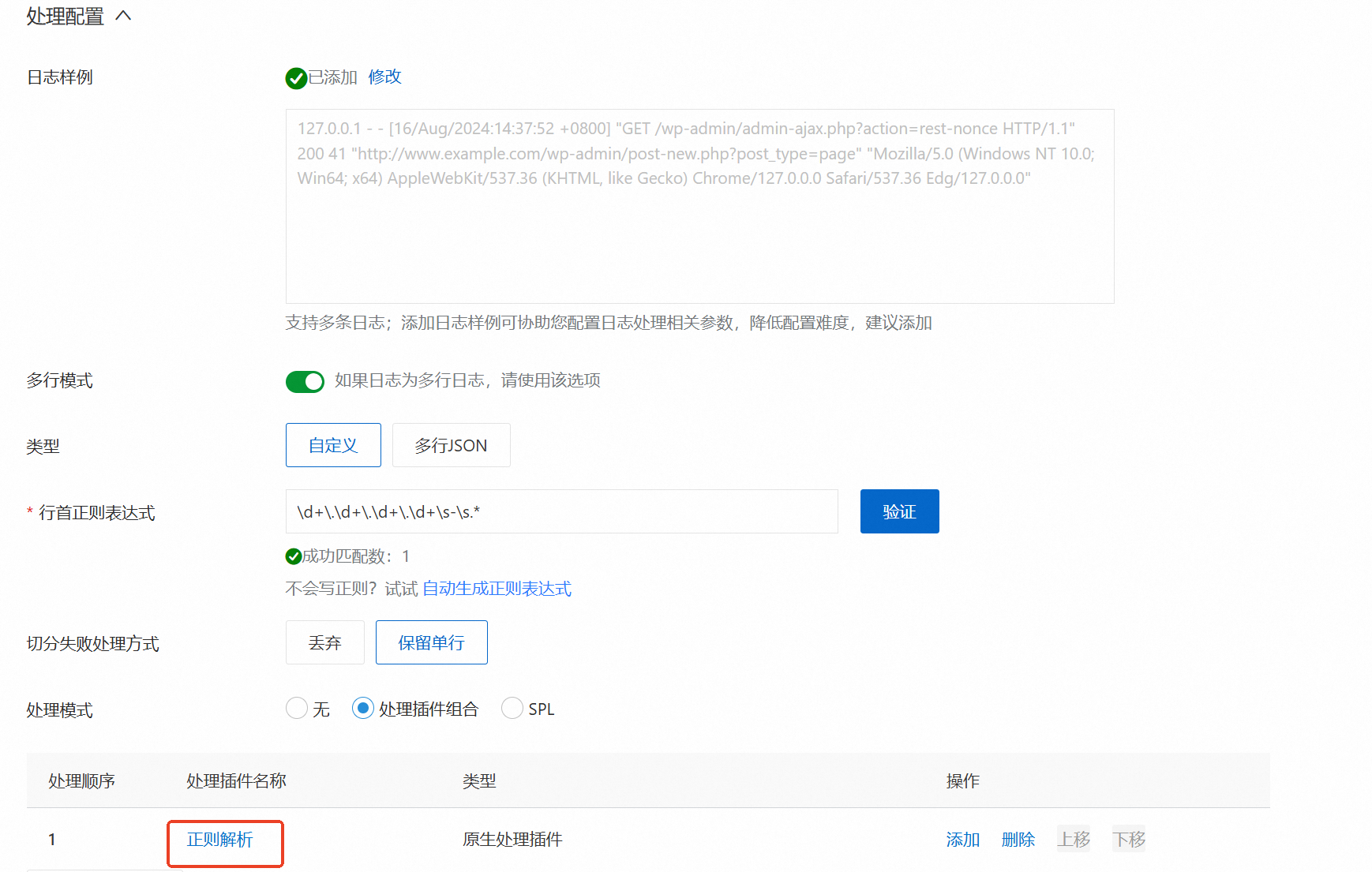
建议您在日志样例中添加日志样例:日志样例可协助您配置日志处理相关参数,降低配置难度。若配置请务必使用实际场景中待采集日志的样例。
按需选择是否开启多行模式:多行日志是指每条日志占用了连续的多行,不开启则是单行模式,即每一行为一条日志。若开启多行模式请配置:
类型:
自定义:原始日志的格式不固定,则配置行首正则表达式,来标定每一条日志的起始行。例如我们使用行首正则表达式
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*,即可将示例中五行原始数据切分为两条日志。需要注意,行首正则表达式需要能够匹配完整的一行数据。[2023-10-01T10:30:01,000] [INFO] java.lang.Exception: exception happened at TestPrintStackTrace.f(TestPrintStackTrace.java:3) at TestPrintStackTrace.g(TestPrintStackTrace.java:7) at TestPrintStackTrace.main(TestPrintStackTrace.java:16) [2023-10-01T10:31:01,000] [INFO] java.lang.Exception: exception happened多行JSON:当原始日志均为标准JSON格式时,可以选择多行JSON,Logtail会自动处理单条JSON日志内部的换行。
切分失败处理方式:
丢弃:直接丢弃这段日志。
保留单行:将每行日志文本单独保留为一条日志。
处理模式:处理模式配置的是对一条日志切割处理的方式。示例为正则-文本日志,因此处理插件中自动生成了一个正则解析插件,您也可以根据需要使用其他插件。
以下为您介绍常用的插件配置方式:有关时间解析,过滤处理,脱敏处理等更多插件能力请参考处理插件概述。日志服务也提供了SPL处理方式,在实现类似于传统处理插件功能的前提下处理效率更高,详细了解请参考使用Logtail SPL解析日志。
正则解析
单击正则解析可进入处理插件详细配置页面。

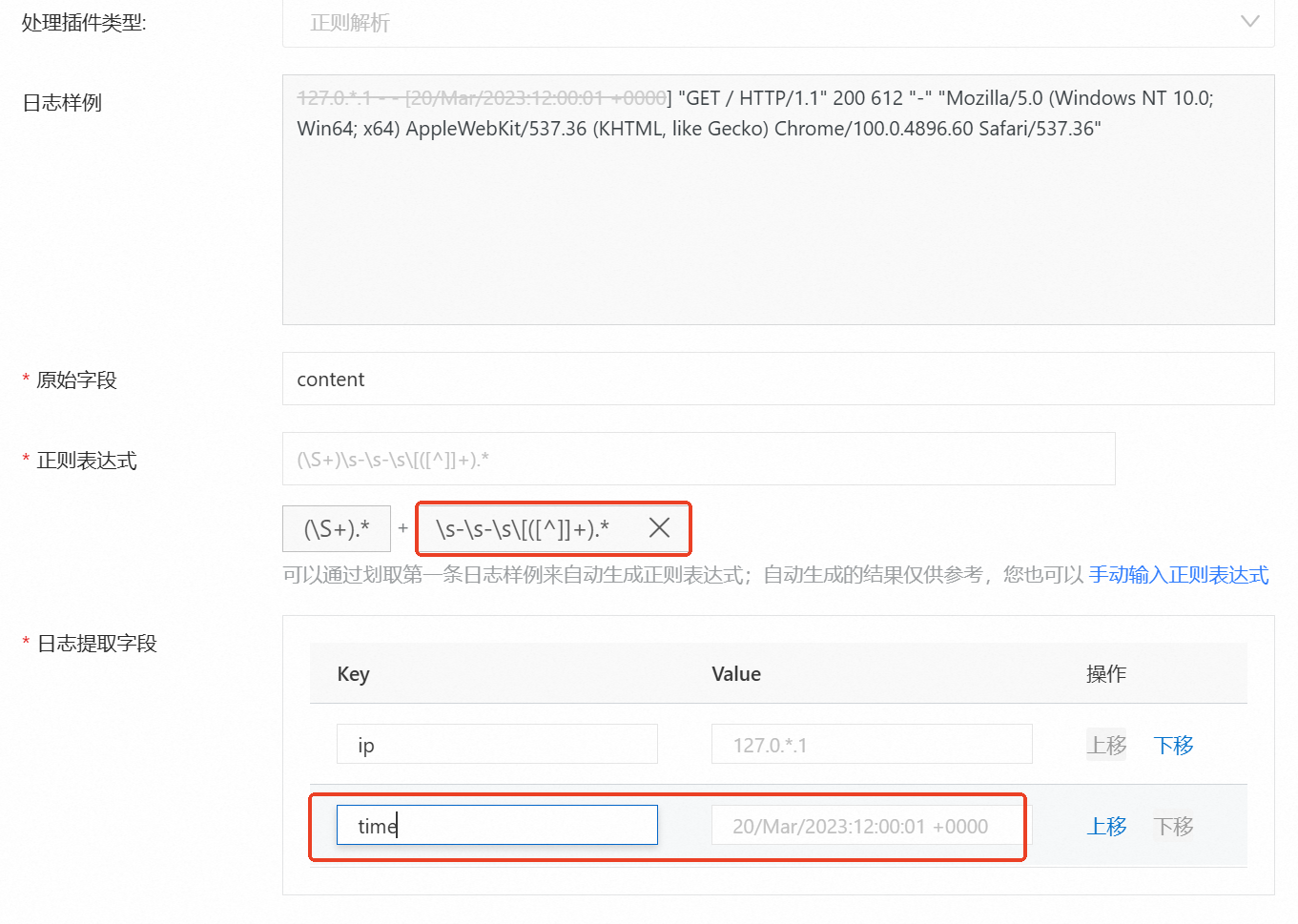
需要在此页面配置正则表达式,以及根据提取的value设置key值。您可以单击正则表达式下方的自动生成正则表达式,之后如图所示选中日志样例中的内容后,单击产生的生成正则,会自动生成选择内容的正则表达式。
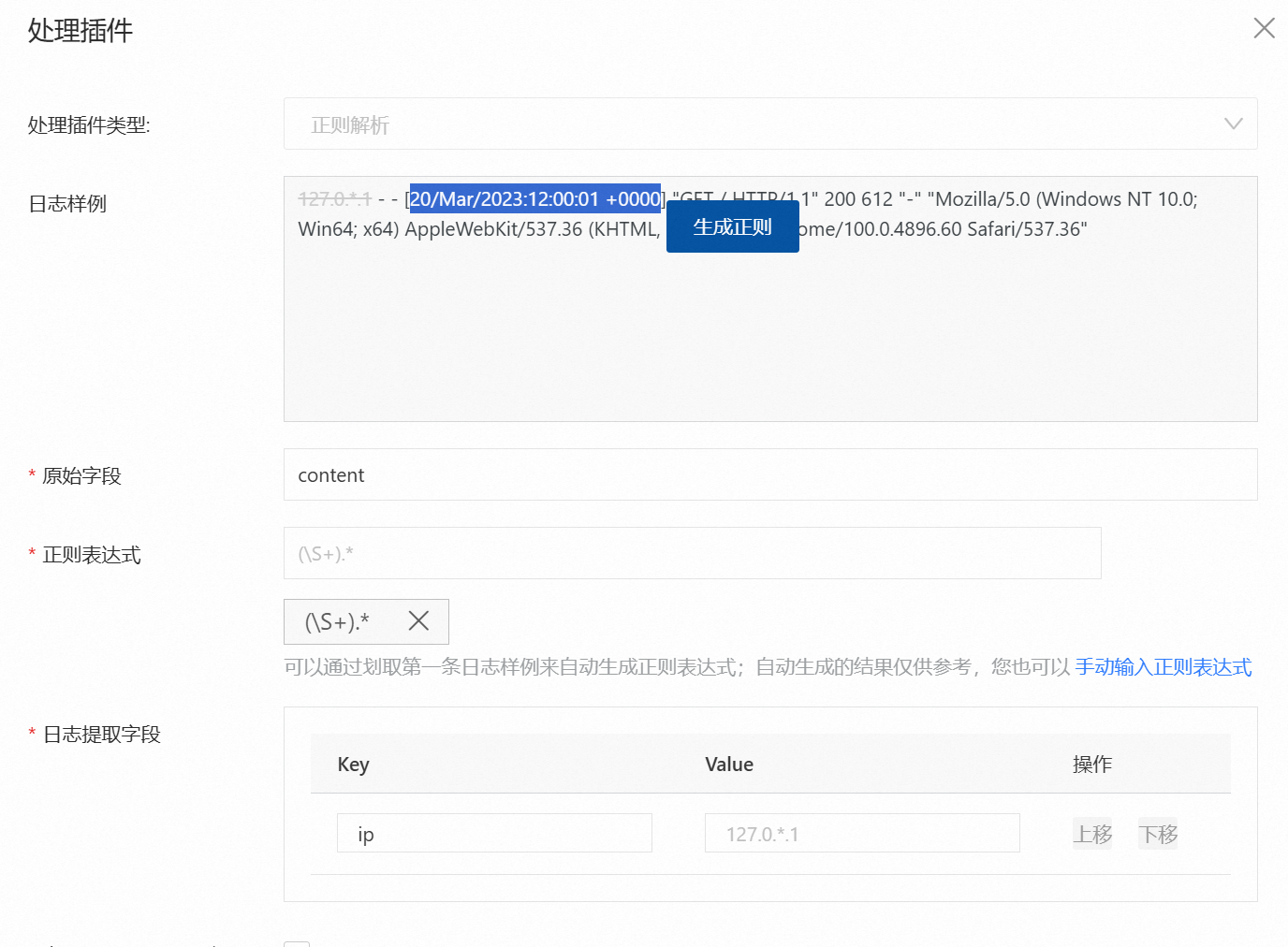
生成对应的正则表达式后,您还需要对在日志提取字段中对应生成的value设置key值,这些键值对将有助于您后续设置日志索引。完成后点击确认并点击下一步。
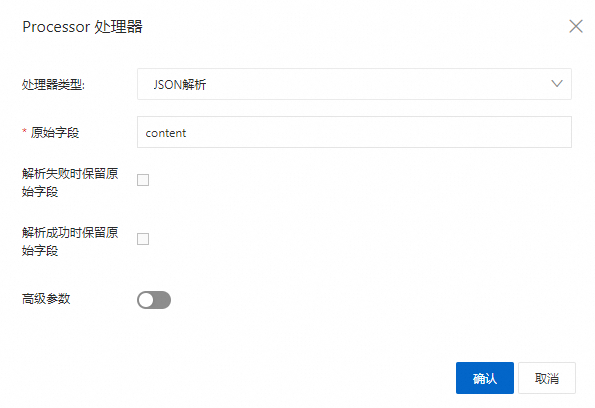
JSON解析
重要本模式适用于采集JSON日志。
JSON日志有两种结构,Object类型(键值对的集合)和Array类型(值的有序列表)。Logtail JSON解析插件支持解析Object类型的JSON日志,提取为键值对,即提取Object首层的键作为Key,Object首层的值作为Value。但插件不支持解析Array类型的JSON日志。如需更细粒度请配合展开JSON字段进行处理。
根据需要选择是否开启处理配置中的多行模式,如果开启,请使用以下选项:
类型,选择多行JSON。
切分失败处理方式,选择保留单行。
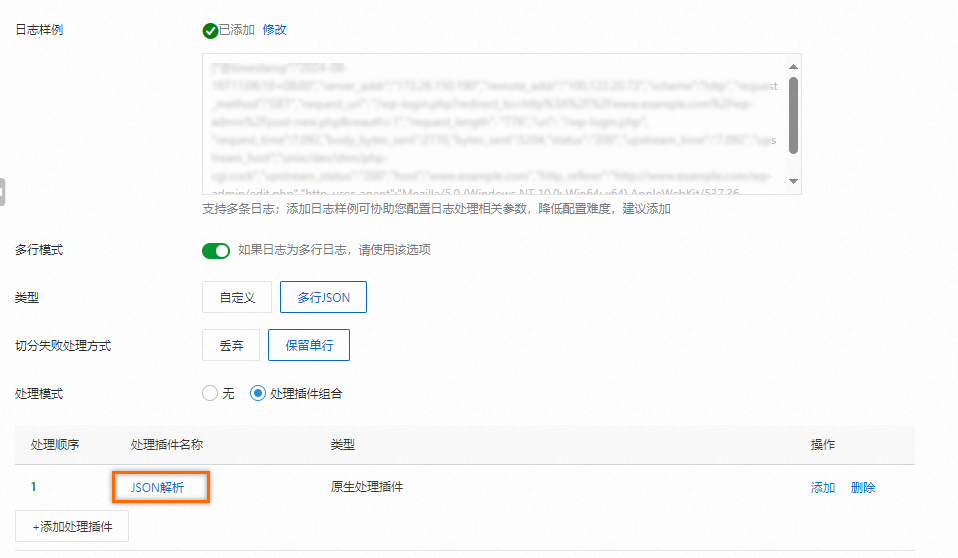
删除处理模式中的正则解析插件,然后添加一个JSON解析插件后点击确认,点击下一步。
APACHE模式解析
说明Logtail Apache模式解析插件支持根据Apache日志配置文件中的定义将日志内容结构化并解析为多个键值对形式。
删除处理模式中的正则解析插件,然后添加一个APACHE模式解析插件。
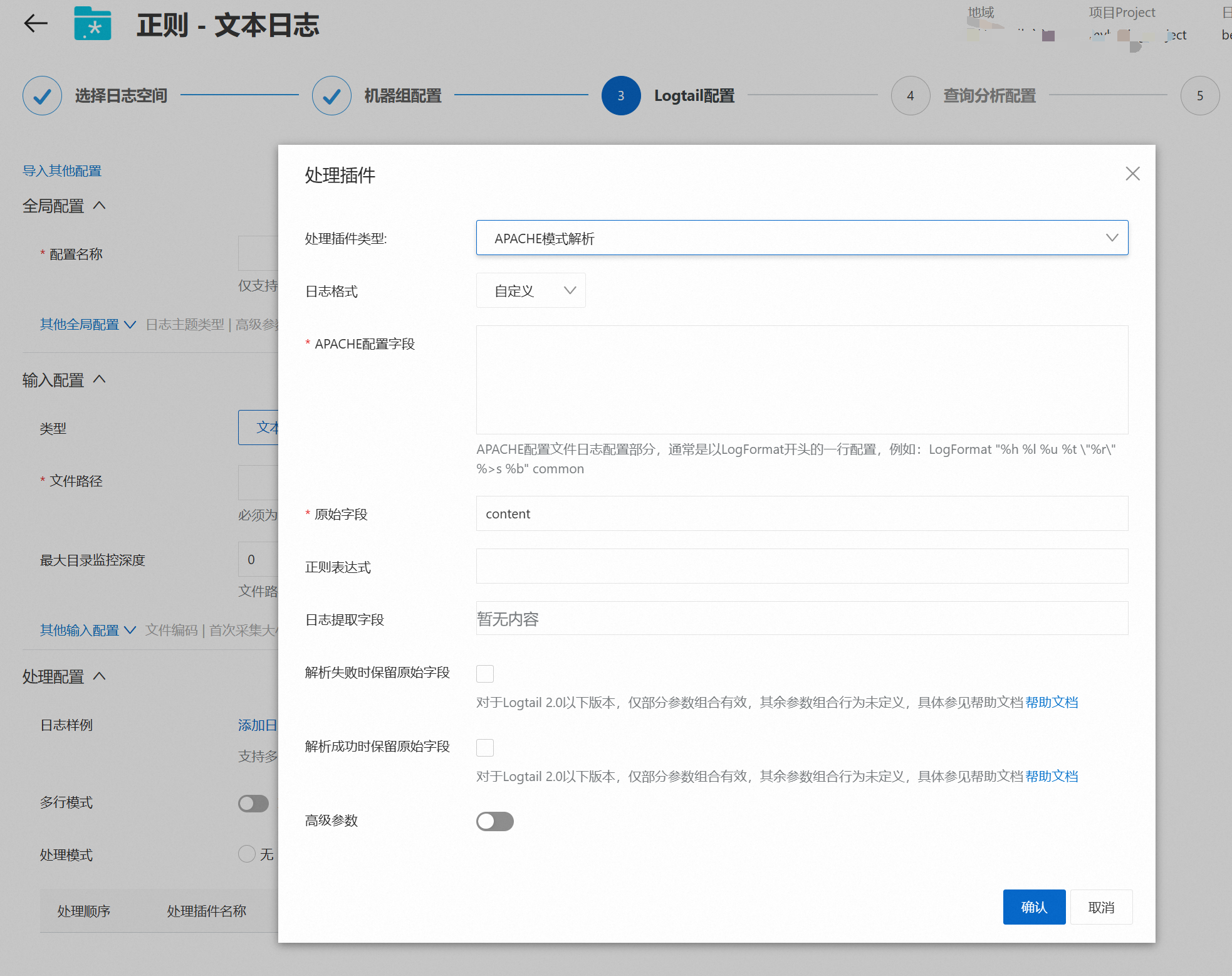
根据如下表格的配置说明进行插件配置,完成后点击确认,点击下一步。
参数名称
说明
日志格式
根据Apache日志配置文件中定义的日志格式进行选择,包括common、combined和自定义。
APACHE配置字段
Apache配置文件中的日志配置部分,通常以LogFormat开头。
当配置日志格式为common或combined时,此处会自动填充对应格式的配置字段,请确认是否和Apache配置文件中定义的格式一致。
当配置日志格式为自定义时,请根据实际情况填写,例如
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %D %f %k %p %q %R %T %I %O" customized。
原始字段
解析日志前,用于存放日志内容的原始字段,默认值为content。
正则表达式
用于提取Apache日志的正则表达式。日志服务会根据APACHE配置字段中的内容自动生成该正则表达式。
日志提取字段
根据APACHE配置字段中的内容自动生成日志字段(key)。
解析失败时保留原始字段
选中解析失败时保留原始字段,则解析失败时,将保留原始字段。
解析成功时保留原始字段
选中解析成功时保留原始字段,则解析成功时,将保留原始字段。
重命名的原始字段
选中解析失败时保留原始字段或解析成功时保留原始字段后,可重命名原始字段名,用于存放原始的日志内容。
NGINX模式解析
说明Logtail Nginx模式插件支持根据log_format中的定义将日志内容结构化,解析为多个键值对形式。
删除处理模式中的正则解析插件,然后添加一个NGINX模式解析插件。
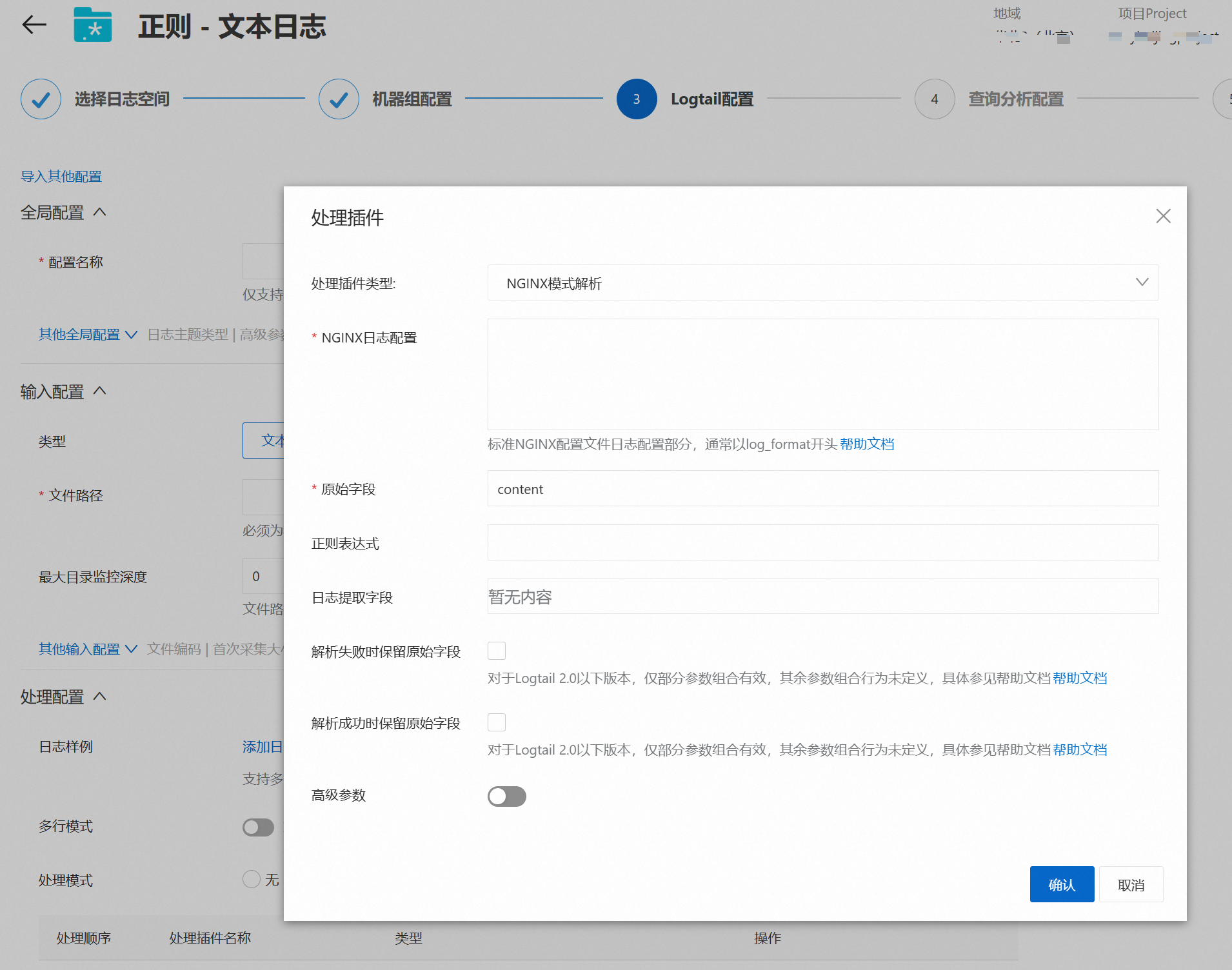 根据如下表格的配置说明进行插件配置,完成后点击确认,点击下一步。
根据如下表格的配置说明进行插件配置,完成后点击确认,点击下一步。参数名称
说明
NGINX日志配置
Nginx配置文件中的日志配置部分,以log_format开头。例如:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$request_time $request_length ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent"';更多信息,请参见Nginx日志简介。
原始字段
解析日志前,用于存放日志内容的原始字段,默认值为content。
正则表达式
用于提取Apache日志的正则表达式。日志服务会根据NGINX日志配置 中的内容自动生成该正则表达式。
日志提取字段
根据NGINX日志配置自动提取对应的日志字段(Key)。
解析失败时保留原始字段
选中解析失败时保留原始字段,则解析失败时,将保留原始字段。
解析成功时保留原始字段
选中解析成功时保留原始字段,则解析成功时,将保留原始字段。
重命名的原始字段
选中解析失败时保留原始字段或解析成功时保留原始字段后,可重命名原始字段名,用于存放原始的日志内容。
IIS模式解析
说明Logtail IIS模式插件支持根据IIS日志格式定义将日志内容结构化,解析为多个键值对形式。
删除处理模式中的正则解析插件,然后添加一个IIS模式解析插件。
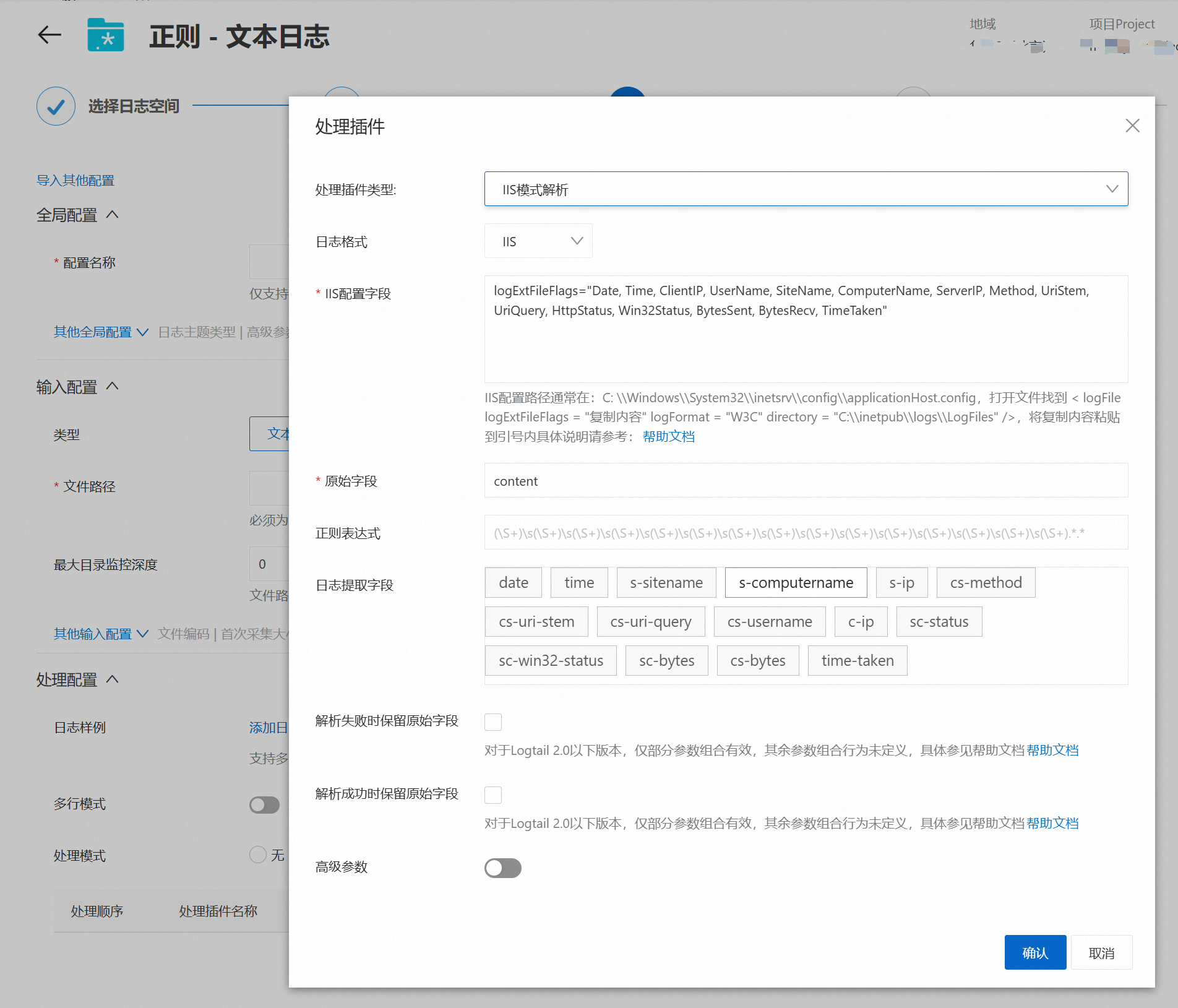
根据如下表格的配置说明进行插件配置,完成后点击确认,点击下一步。
参数名称
说明
日志格式
选择您的IIS服务器日志采用的日志格式,具体说明如下:
IIS:Microsoft IIS日志文件格式。
NCSA:NCSA公用日志文件格式。
W3C:W3C扩展日志文件格式。
IIS配置字段
配置IIS配置字段,具体说明如下:
日志格式为IIS或NCSA时,日志服务已默认设置了IIS配置字段。
日志格式为W3C日志时,设置为IIS配置文件中
logExtFileFlags参数中的内容,例如:logExtFileFlags="Date, Time, ClientIP, UserName, SiteName, ComputerName, ServerIP, Method, UriStem, UriQuery, HttpStatus, Win32Status, BytesSent, BytesRecv, TimeTaken, ServerPort, UserAgent, Cookie, Referer, ProtocolVersion, Host, HttpSubStatus"IIS5配置文件默认路径:
C:\WINNT\system32\inetsrv\MetaBase.bin。IIS6配置文件默认路径:
C:\WINDOWS\system32\inetsrv\MetaBase.xml。IIS7配置文件默认路径:
C:\Windows\System32\inetsrv\config\applicationHost.config。
原始字段
解析日志前,用于存放日志内容的原始字段,默认值为content。
正则表达式
用于提取IIS日志的正则表达式。日志服务会根据IIS配置字段中的内容自动生成该正则表达式。
日志提取字段
根据IIS配置字段中的内容自动生成日志字段(Key)。
解析失败时保留原始字段
选中解析失败时保留原始字段,则解析失败时,将保留原始字段。
解析成功时保留原始字段
选中解析成功时保留原始字段,则解析成功时,将保留原始字段。
重命名的原始字段
选中解析失败时保留原始字段或解析成功时保留原始字段后,可重命名原始字段名,用于存放原始的日志内容。
分隔符解析
说明Logtail分隔符模式解析插件支持通过分隔符将日志内容结构化,解析为多个键值对形式。
删除处理模式中的正则解析插件,然后添加一个分隔符解析插件。
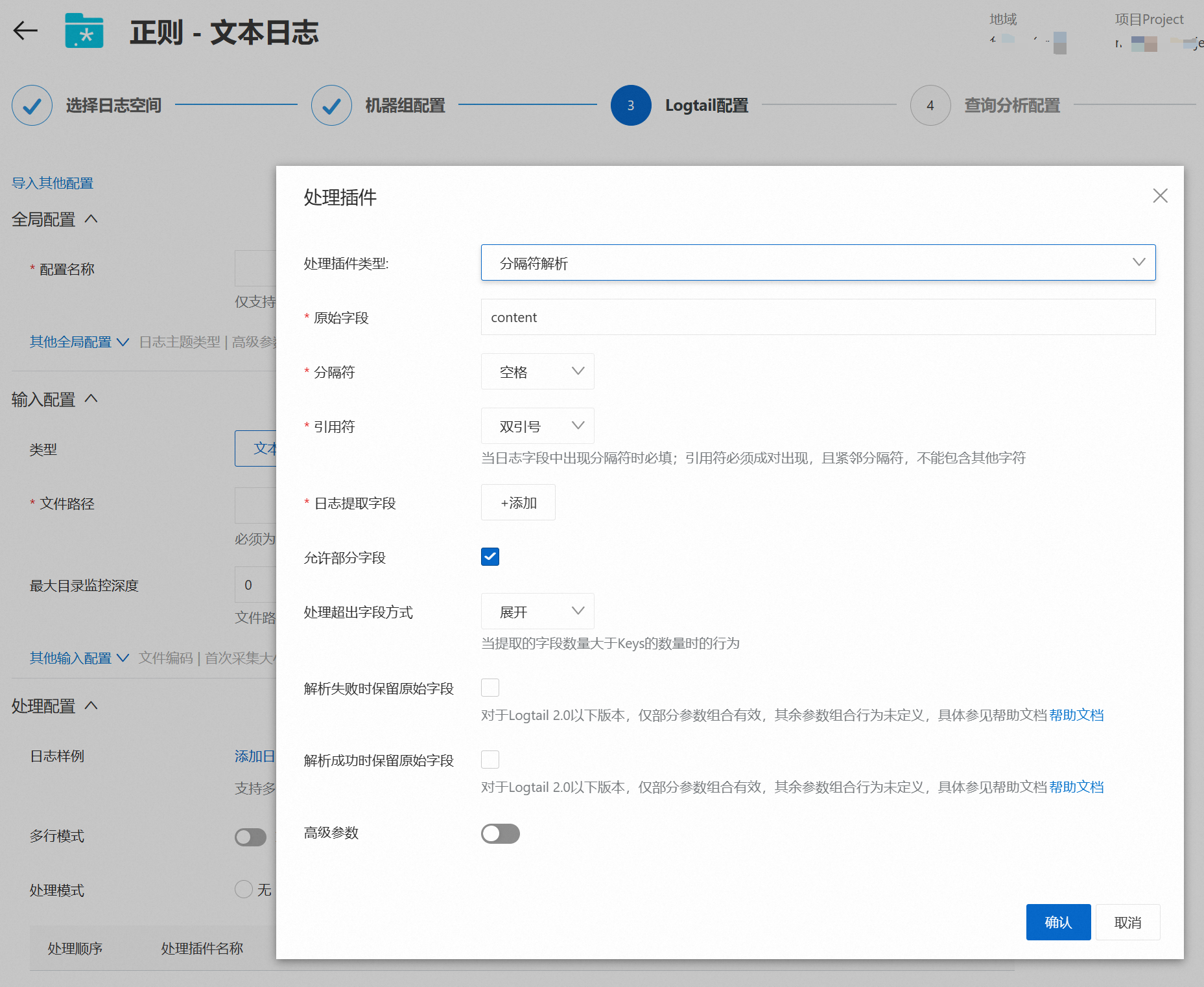
根据如下表格的配置说明进行插件配置,完成后点击确认,点击下一步。
参数
描述
原始字段
解析日志前,用于存放日志内容的原始字段,默认值为content。
分隔符
请根据您的日志内容选择正确的分隔符,例如竖线(|)。
说明指定分隔符为不可见字符时,您需要查找不可见字符在ASCII码中对应的十六进制数,输入的格式为
0x<不可见字符在ASCII码中对应的十六进制数>。例如ASCII码中排行为1的不可见字符为0x01。引用符
当日志字段内容中包含分隔符时,需要指定引用符进行包裹,被引用符包裹的内容会被日志服务解析为一个完整字段。请根据您的日志格式选择正确的引用符。
说明指定引用符为不可见字符时,您需要查找不可见字符在ASCII码中对应的十六进制数,输入的格式为
0x<不可见字符在ASCII码中对应的十六进制数>。例如ASCII码中排行为1的不可见字符为0x01。日志提取字段
当您配置了日志样例时,日志服务会根据您输入的日志样例及选择的分隔符提取日志内容,并将其定义为Value,您需要为各个Value指定对应的Key。
当您未配置日志样例时,无Value列表,您需要根据实际日志及分隔符情况,输入对应的Key。
Key只能包括字母、数字或下划线(_),且只能以字母或下划线(_)开头。最大长度为128字节。
允许部分字段
如果日志中实际提取出的Value数量少于Key数量,是否上传日志到日志服务。选中允许部分字段表示上传。
例如日志为
11|22|33|44,分隔符为竖线(|),Key为A、B、C、D和E。如果选中允许部分字段,则
E字段的Value为空,该日志将被上传到日志服务。如果未选中允许部分字段,该日志会被丢弃。
说明Linux Logtail 1.0.28及以上版本或Windows Logtail 1.0.28.0及以上版本支持配置分隔符模式的允许部分字段参数。
处理超出字段方式
日志中提取的Value数量大于Key数量时的处理方法。
展开:保留多余的Value内容,分别添加到
__column$i__格式的字段中,其中$i代表多余字段序号,从0开始计数。例如__column0__、__column1__。保留:保留多余的Value内容,并整体添加到名为
__column0__的字段中。丢弃:丢弃多余的Value内容。
解析失败时保留原始字段
选中解析失败时保留原始字段,则解析失败时,将保留原始字段。
解析成功时保留原始字段
选中解析成功时保留原始字段,则解析成功时,将保留原始字段。
重命名的原始字段
选中解析失败时保留原始字段或解析成功时保留原始字段后,可重命名原始字段名,用于存放原始的日志内容。
SPL处理
日志服务还提供了自定义SPL处理方式,与传统的处理插件相比,使用SPL不仅提高了处理速度和效率,还提供了更多智能化和易用性方面的优势,使得日志服务的整体能力得到了显著增强。通过编写SPL语句,您可以充分利用其计算能力来处理数据,请参考使用Logtail SPL解析日志。
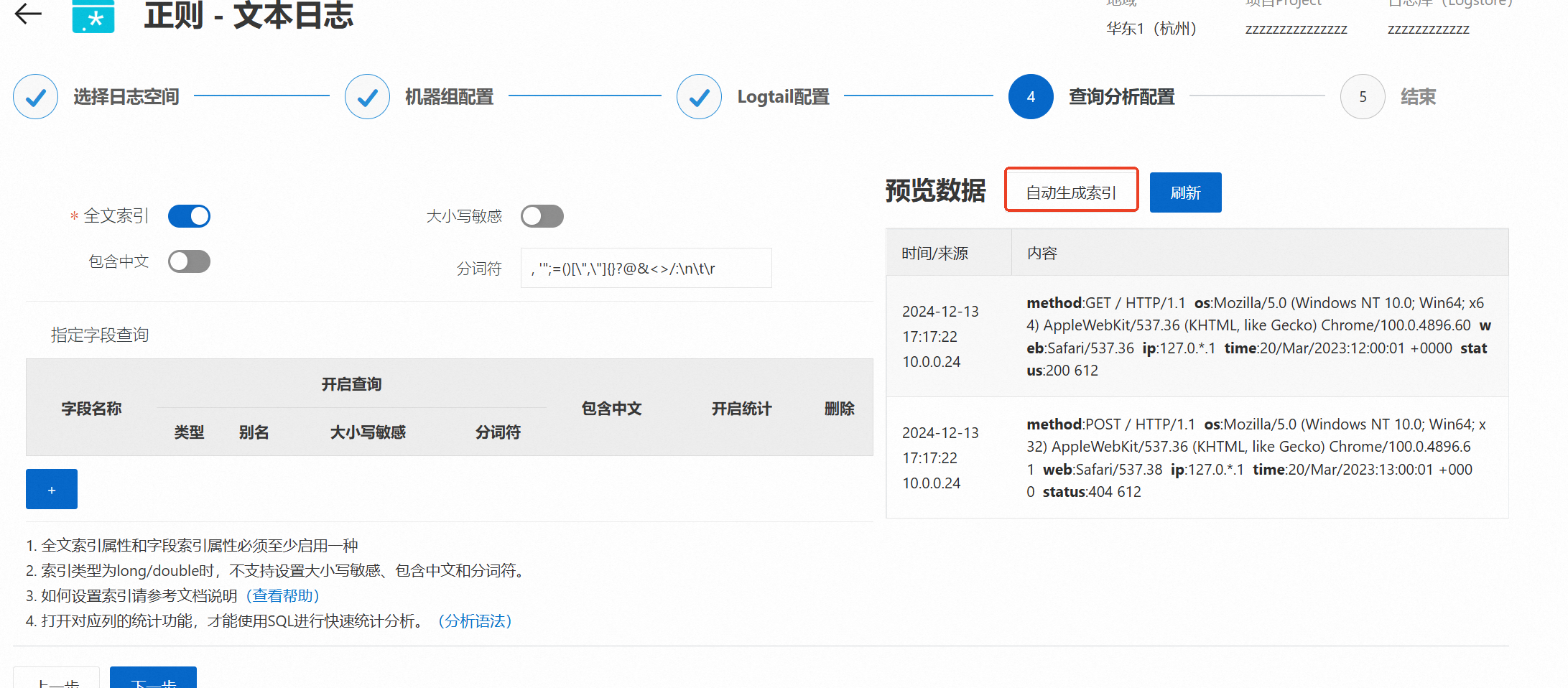
查询分析配置
Logtail配置生效需要1分钟左右,若您是第一次为Logstore进行配置,自动刷新后,采集路径下文件有增量日志且出现预览数据,则说明Logtail配置生效。 配置生效后,单击下一步,Logtail采集配置全部完成。
日志服务默认开启全文索引,此时查询会索引日志中所有字段。您也可以根据采集到的日志,手动创建字段索引,或者单击自动生成索引,日志服务将生成字段索引,通过此索引针对特定字段进行精确查询,从而减少索引费用和提高查询效率。更多信息请参见为什么需要创建索引。
如果您选择了正则解析,此时您设置的键值对会自动填入,如下图: