本文介绍如何将表格存储中数据表的数据迁移或同步到另一个数据表。您可以通过通道服务、DataWorks、DataX或命令行工具等方式实现此操作。
前提条件
已获取源数据表和目标数据表的实例名称、实例访问地址、地域ID等信息。
已为阿里云账号或具有表格存储权限的RAM用户创建AccessKey。
使用SDK同步数据
该方式基于表格存储的通道服务实现数据表间的数据同步,支持同地域、跨地域以及跨账号间的同步。此处以Java为例,同步示例代码如下所示。
运行代码之前,请替换代码中源表和目标表的数据表名称、实例名称和实例访问地址,并将AccessKey ID和AccessKey Secret配置为环境变量。
import com.alicloud.openservices.tablestore.*;
import com.alicloud.openservices.tablestore.core.auth.DefaultCredentials;
import com.alicloud.openservices.tablestore.core.auth.ServiceCredentials;
import com.alicloud.openservices.tablestore.model.*;
import com.alicloud.openservices.tablestore.model.tunnel.*;
import com.alicloud.openservices.tablestore.tunnel.worker.IChannelProcessor;
import com.alicloud.openservices.tablestore.tunnel.worker.ProcessRecordsInput;
import com.alicloud.openservices.tablestore.tunnel.worker.TunnelWorker;
import com.alicloud.openservices.tablestore.tunnel.worker.TunnelWorkerConfig;
import com.alicloud.openservices.tablestore.writer.RowWriteResult;
import com.alicloud.openservices.tablestore.writer.WriterConfig;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicLong;
public class TableSynchronization {
// 源表配置项:表名称、实例名称、实例访问地址、AccessKey ID、AccessKey Secret
final static String sourceTableName = "sourceTableName";
final static String sourceInstanceName = "sourceInstanceName";
final static String sourceEndpoint = "sourceEndpoint";
final static String sourceAccessKeyId = System.getenv("SOURCE_TABLESTORE_ACCESS_KEY_ID");
final static String sourceKeySecret = System.getenv("SOURCE_TABLESTORE_ACCESS_KEY_SECRET");
// 目标表配置项:表名称、实例名称、实例访问地址、AccessKey ID、AccessKey Secret
final static String targetTableName = "targetTableName";
final static String targetInstanceName = "targetInstanceName";
final static String targetEndpoint = "targetEndpoint";
final static String targetAccessKeyId = System.getenv("TARGET_TABLESTORE_ACCESS_KEY_ID");
final static String targetKeySecret = System.getenv("TARGET_TABLESTORE_ACCESS_KEY_SECRET");
// 通道名称
static String tunnelName = "source_table_tunnel";
// TablestoreWriter:高并发数据写入工具
static TableStoreWriter tableStoreWriter;
// 成功和失败行数统计
static AtomicLong succeedRows = new AtomicLong();
static AtomicLong failedRows = new AtomicLong();
public static void main(String[] args) {
// 创建目标表
createTargetTable();
System.out.println("Create target table Done.");
// 初始化 TunnelClient
TunnelClient tunnelClient = new TunnelClient(sourceEndpoint, sourceAccessKeyId, sourceKeySecret, sourceInstanceName);
// 创建数据通道
String tunnelId = createTunnel(tunnelClient);
System.out.println("Create tunnel Done.");
// 初始化 TablestoreWriter
tableStoreWriter = createTablesStoreWriter();
// 通过数据通道同步数据
TunnelWorkerConfig config = new TunnelWorkerConfig(new SimpleProcessor());
TunnelWorker worker = new TunnelWorker(tunnelId, tunnelClient, config);
try {
System.out.println("Connect tunnel and working ...");
worker.connectAndWorking();
// 监听通道状态,通道状态从全量同步变成增量同步时,表示数据同步完成
while (true) {
if (tunnelClient.describeTunnel(new DescribeTunnelRequest(sourceTableName, tunnelName)).getTunnelInfo().getStage().equals(TunnelStage.ProcessStream)) {
break;
}
Thread.sleep(5000);
}
// 同步结果
System.out.println("Data Synchronization Completed.");
System.out.println("* Succeed Rows Count: " + succeedRows.get());
System.out.println("* Failed Rows Count: " + failedRows.get());
// 删除通道
tunnelClient.deleteTunnel(new DeleteTunnelRequest(sourceTableName, tunnelName));
// 关闭资源
worker.shutdown();
config.shutdown();
tunnelClient.shutdown();
tableStoreWriter.close();
}catch(Exception e){
e.printStackTrace();
worker.shutdown();
config.shutdown();
tunnelClient.shutdown();
tableStoreWriter.close();
}
}
private static void createTargetTable() throws ClientException {
// 查询源表信息
SyncClient sourceClient = new SyncClient(sourceEndpoint, sourceAccessKeyId, sourceKeySecret, sourceInstanceName);
DescribeTableResponse response = sourceClient.describeTable(new DescribeTableRequest(sourceTableName));
// 创建目标表
SyncClient targetClient = new SyncClient(targetEndpoint, targetAccessKeyId, targetKeySecret, targetInstanceName);
TableMeta tableMeta = new TableMeta(targetTableName);
response.getTableMeta().getPrimaryKeyList().forEach(
item -> tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema(item.getName(), item.getType()))
);
TableOptions tableOptions = new TableOptions(-1, 1);
CreateTableRequest request = new CreateTableRequest(tableMeta, tableOptions);
targetClient.createTable(request);
// 关闭资源
sourceClient.shutdown();
targetClient.shutdown();
}
private static String createTunnel(TunnelClient client) {
// 创建数据通道,返回通道 ID
CreateTunnelRequest request = new CreateTunnelRequest(sourceTableName, tunnelName, TunnelType.BaseAndStream);
CreateTunnelResponse response = client.createTunnel(request);
return response.getTunnelId();
}
private static class SimpleProcessor implements IChannelProcessor {
@Override
public void process(ProcessRecordsInput input) {
if(input.getRecords().isEmpty())
return;
System.out.print("* Begin consume " + input.getRecords().size() + " records ... ");
for (StreamRecord record : input.getRecords()) {
switch (record.getRecordType()) {
// 写入行数据
case PUT:
RowPutChange putChange = new RowPutChange(targetTableName, record.getPrimaryKey());
putChange.addColumns(getColumnsFromRecord(record));
tableStoreWriter.addRowChange(putChange);
break;
// 更新行数据
case UPDATE:
RowUpdateChange updateChange = new RowUpdateChange(targetTableName, record.getPrimaryKey());
for (RecordColumn column : record.getColumns()) {
switch (column.getColumnType()) {
// 新增属性列
case PUT:
updateChange.put(column.getColumn().getName(), column.getColumn().getValue(), System.currentTimeMillis());
break;
// 删除属性列版本
case DELETE_ONE_VERSION:
updateChange.deleteColumn(column.getColumn().getName(),
column.getColumn().getTimestamp());
break;
// 删除属性列
case DELETE_ALL_VERSION:
updateChange.deleteColumns(column.getColumn().getName());
break;
default:
break;
}
}
tableStoreWriter.addRowChange(updateChange);
break;
// 删除行数据
case DELETE:
RowDeleteChange deleteChange = new RowDeleteChange(targetTableName, record.getPrimaryKey());
tableStoreWriter.addRowChange(deleteChange);
break;
}
}
// 发送缓冲区数据
tableStoreWriter.flush();
System.out.println("Done");
}
@Override
public void shutdown() {
}
}
public static List<Column> getColumnsFromRecord(StreamRecord record) {
List<Column> retColumns = new ArrayList<>();
for (RecordColumn recordColumn : record.getColumns()) {
// 将数据版本号替换为当前时间戳,防止超过最大版本偏差
Column column = new Column(recordColumn.getColumn().getName(), recordColumn.getColumn().getValue(), System.currentTimeMillis());
retColumns.add(column);
}
return retColumns;
}
private static TableStoreWriter createTablesStoreWriter() {
WriterConfig config = new WriterConfig();
// 行级别回调,统计成功和失败行数,打印同步失败的数据行
TableStoreCallback<RowChange, RowWriteResult> resultCallback = new TableStoreCallback<RowChange, RowWriteResult>() {
@Override
public void onCompleted(RowChange rowChange, RowWriteResult rowWriteResult) {
succeedRows.incrementAndGet();
}
@Override
public void onFailed(RowChange rowChange, Exception exception) {
failedRows.incrementAndGet();
System.out.println("* Failed Rows: " + rowChange.getTableName() + " | " + rowChange.getPrimaryKey() + " | " + exception.getMessage());
}
};
ServiceCredentials credentials = new DefaultCredentials(targetAccessKeyId, targetKeySecret);
return new DefaultTableStoreWriter(targetEndpoint, credentials, targetInstanceName,
targetTableName, config, resultCallback);
}
}使用DataWorks同步数据
此处以DataWorks为例介绍数据表同步,除了DataWorks,您还可以使用DataX实现表格存储数据表间的同步。
步骤一:准备工作
创建目标数据表,并确保其主键结构(包括数据类型及顺序)与源表一致。
开通DataWorks服务,并在源表或目标表所在地域创建工作空间。
创建Serverless资源组并绑定到工作空间。有关计费信息,请参见Serverless资源组计费。
如果源表和目标表不在同一地域,请参考以下操作步骤创建VPC对等连接实现跨地域网络连通。
此处以DataWorks工作空间和源表实例所在地域一致,都位于华东1(杭州)地域为例进行介绍,目标表位于华东2(上海)地域。
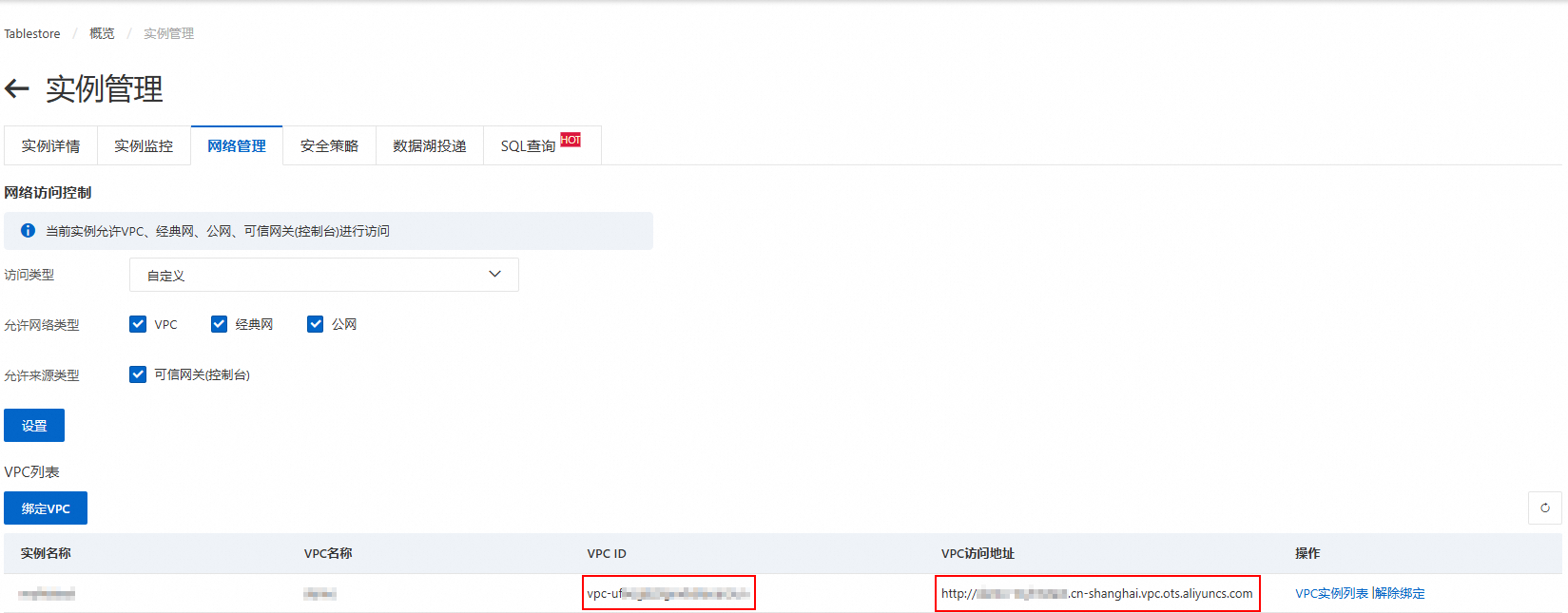
为Tablestore实例绑定VPC。
登录表格存储控制台,在页面上方选择目标表所在地域。
单击实例别名进入实例管理页面。
切换到网络管理页签,单击绑定VPC,选择VPC和交换机并填写VPC名称,然后单击确定。
请耐心等待一段时间,VPC绑定成功后页面将自动刷新,您可以在VPC列表查看绑定的VPC ID和VPC访问地址。
说明后续在DataWorks控制台添加Tablestore数据源时,将使用该VPC访问地址。
获取DataWorks工作空间资源组的VPC信息。
登录DataWorks控制台,在页面上方选择工作空间所在地域,然后单击左侧工作空间菜单,进入工作空间列表页面。
单击工作空间名称进入空间详情页面,单击左侧资源组菜单,查看工作空间绑定的资源组列表。
在目标资源组右侧单击网络设置,在资源调度 & 数据集成区域查看绑定的专有网络,即VPC ID。
创建VPC对等连接并配置路由。
登录专有网络VPC控制台。在页面左侧单击专有网络菜单,依次选择Tablestore实例和DataWorks工作空间所在地域,并记录VPC ID对应的网段地址。

在页面左侧单击VPC对等连接菜单,然后在VPC对等连接页面单击创建对等连接。
在创建对等连接页面,输入对等连接名称,选择发起端VPC实例、接收端账号类型、接收端地域和接收端VPC实例,单击确定。
在VPC对等连接页面,找到已创建的VPC对等连接,分别在发起端VPC实例列和接收端VPC实例列单击配置路由条目。
目标网段需填写对端VPC的网段地址。即在发起端VPC实例配置路由条目时,填写接收端VPC实例的网段地址;在接收端VPC实例配置路由条目时,填写发起端VPC实例的网段地址。
步骤二:新增表格存储数据源
分别为源数据表和目标数据表所在的实例新增表格存储数据源。
进入数据集成页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
在左侧导航栏,单击数据源。
在数据源列表页面,单击新增数据源。
在新增数据源对话框,搜索并选择数据源类型为Tablestore。
在新增OTS数据源对话框,根据下表配置数据源参数。
参数
说明
数据源名称
数据源名称必须以字母、数字、下划线(_)组合,且不能以数字和下划线(_)开头。
数据源描述
对数据源进行简单描述,不得超过80个字符。
地域
选择Tablestore实例所属地域。
Table Store实例名称
Tablestore实例的名称。
Endpoint
Tablestore实例的服务地址,推荐使用VPC地址。
AccessKey ID
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。
AccessKey Secret
测试资源组连通性。创建数据源时,您需要测试资源组的连通性,以保证同步任务使用的资源组能够与数据源连通,否则将无法正常执行数据同步任务。
在连接配置区域,单击相应资源组连通状态列的测试连通性。
测试连通性通过后,连通状态显示可连通,单击完成。您可以在数据源列表中查看新建的数据源。
说明如果测试连通性结果为无法通过,您可使用连通性诊断工具自助解决。如仍无法连通资源组与数据源,请提交工单处理。
步骤三:配置离线同步任务
数据开发(Data Studio)旧版
一、新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入数据开发。
在DataStudio控制台的数据开发页面,单击业务流程节点下的目标业务流程。
如果需要新建业务流程,请参见创建业务流程。
在数据集成节点上右键单击,然后选择新建节点 > 离线同步。
在新建节点对话框,选择路径并填写名称,然后单击确认。
在数据集成节点下,将显示新建的离线同步节点。
二、配置同步任务
在数据集成节点下,双击打开新建的离线同步任务节点。
配置网络与资源。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
在网络与资源配置步骤,选择数据来源为Tablestore,并选择数据源名称为新增的源数据源。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
说明Serverless资源组支持为同步任务指定运行CU上限,如果您的同步任务因资源不足出现OOM现象,请适当调整资源组的CU占用取值。
选择数据去向为Tablestore,并选择数据源名称为新增的目标数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置任务并保存。
向导模式
在配置任务步骤的配置数据来源与去向区域,根据实际情况配置数据来源和数据去向。
数据来源
参数
说明
数据源
默认显示上一步选择的Tablestore数据源。
表
源数据表。
主键区间分布(起始)
数据读取的起始主键和结束主键,格式为JSON数组。
起始主键和结束主键需要是有效的主键或者是由
INF_MIN和INF_MAX类型组成的虚拟点,虚拟点的列数必须与主键相同。其中INF_MIN表示无限小,任何类型的值都比它大;INF_MAX表示无限大,任何类型的值都比它小。数据表中的行按主键从小到大排序,读取范围是一个左闭右开的区间,返回的数据是大于等于起始主键且小于结束主键的所有行。
主键区间分布(结束)
切分配置信息
自定义切分配置信息,普通情况下不建议配置。
当Tablestore数据存储发生热点,且使用Tablestore Reader自动切分的策略不能生效时,建议使用自定义的切分规则。切分指定的是在主键起始和结束区间内的切分点,仅配置切分键,无需指定全部的主键。格式为JSON数组。
数据去向
参数
说明
数据源
默认显示上一步选择的Tablestore数据源。
表
目标数据表。
主键信息
目标数据表的主键信息。
写入模式
数据写入表格存储的模式,支持以下两种模式:
PutRow:对应于Tablestore API PutRow,插入数据到指定的行。如果该行不存在,则新增一行。如果该行存在,则覆盖原有行。
UpdateRow:对应于Tablestore API UpdateRow,更新指定行的数据。如果该行不存在,则新增一行。如果该行存在,则根据请求的内容在这一行中新增、修改或者删除指定列的值。
配置字段映射。
配置数据来源与数据去向后,需要指定来源字段和目标字段的映射关系。配置字段映射关系后,任务将根据字段映射关系,将源表字段写入目标表对应类型的字段中。更多信息,请参见配置字段映射关系。
重要在来源字段中必须指定主键信息,以便读取主键数据。
由于在上一步的数据去向下已配置了目标表的主键信息,因此在目标字段中不可再配置主键信息。
当字段的数据类型为INTEGER时,您需要将其配置为INT,DataWorks会自动将其转换为INTEGER类型。如果直接配置为INTEGER类型,日志将会出现错误,导致任务无法顺利完成。
配置通道控制。
您可以通过通道配置,控制数据同步过程相关属性。相关参数说明详情可参见离线同步并发和限流之间的关系。
单击
 图标,保存配置。
图标,保存配置。
脚本模式
在配置任务步骤,单击
 图标,然后在弹出的对话框中单击确定。
图标,然后在弹出的对话框中单击确定。
在脚本配置页面,编辑脚本。
脚本配置示例如下,请根据您的同步信息和需求替换配置文件内的参数信息。
{ "transform": false, "type": "job", "version": "2.0", "steps": [ { "stepType": "ots", "parameter": { "datasource": "MySourceTablestoreDatasource", "table": "source_data_table", "newVersion": "true", "mode": "normal", "envType": 1, "column": [ { "name": "pk" }, { "name": "column_string" }, { "name": "column_long" }, { "name": "column_double" }, { "name": "column_binary" }, { "name": "column_bool" } ] }, "name": "Reader", "category": "reader" }, { "stepType": "ots", "parameter": { "datasource": "MyTargetTablestoreDatasource", "table": "target_data_table", "newVersion": "true", "mode": "normal", "writeMode": "PutRow", "envType": 1, "column": [ { "name": "column_string", "type": "STRING" }, { "name": "column_long", "type": "INT" }, { "name": "column_double", "type": "DOUBLE" }, { "name": "column_binary", "type": "BINARY" }, { "name": "column_bool", "type": "BOOL" } ], "primaryKey": [ { "name": "pk", "type": "string" } ] }, "name": "Writer", "category": "writer" } ], "setting": { "executeMode": null, "failoverEnable": null, "errorLimit": { "record": "0" }, "speed": { "concurrent": 2, "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }重要在Tablestore Reader的column中必须指定主键信息,以便读取主键数据。
当字段的数据类型为INTEGER时,您需要将其配置为INT,DataWorks会自动将其转换为INTEGER类型。如果直接配置为INTEGER类型,日志将会出现错误,导致任务无法顺利完成。
Tablestore Reader需要替换的参数说明如下:
参数名称
说明
datasource
源表的Tablestore数据源名称。
table
源表名称。
column
读取源表的列信息。
Tablestore Writer需要替换的参数说明如下:
参数名称
说明
datasource
目标表的Tablestore数据源名称。
table
目标表名称。
column
目标表的主键列。
primaryKey
需要写入的属性列。
重要写入目标表的列顺序必须与读取源表的列顺序保持一致。
单击
图标,保存配置。
三、运行同步任务
单击
 图标。
图标。在参数对话框,选择运行资源组的名称。
单击运行。
数据开发(Data Studio)新版
一、新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入Data Studio。
在DataStudio控制台的数据开发页面,单击项目目录右侧的
 图标,然后选择。说明
图标,然后选择。说明首次使用项目目录时,也可以直接单击新建节点按钮。
在新建节点对话框,选择路径并填写名称,然后单击确认。
在项目目录下,将显示新建的离线同步节点。
二、配置同步任务
在项目目录下,单击打开新建的离线同步任务节点。
配置网络与资源。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
在网络与资源配置步骤,选择数据来源为Tablestore,并选择数据源名称为新增的源数据源。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
说明Serverless资源组支持为同步任务指定运行CU上限,如果您的同步任务因资源不足出现OOM现象,请适当调整资源组的CU占用取值。
选择数据去向为Tablestore,并选择数据源名称为新增的目标数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置任务并保存。
向导模式
在配置任务步骤的配置数据来源与去向区域,根据实际情况配置数据来源和数据去向。
数据来源
参数
说明
数据源
默认显示上一步选择的Tablestore数据源。
表
源数据表。
主键区间分布(起始)
数据读取的起始主键和结束主键,格式为JSON数组。
起始主键和结束主键需要是有效的主键或者是由
INF_MIN和INF_MAX类型组成的虚拟点,虚拟点的列数必须与主键相同。其中INF_MIN表示无限小,任何类型的值都比它大;INF_MAX表示无限大,任何类型的值都比它小。数据表中的行按主键从小到大排序,读取范围是一个左闭右开的区间,返回的数据是大于等于起始主键且小于结束主键的所有行。
主键区间分布(结束)
切分配置信息
自定义切分配置信息,普通情况下不建议配置。
当Tablestore数据存储发生热点,且使用Tablestore Reader自动切分的策略不能生效时,建议使用自定义的切分规则。切分指定的是在主键起始和结束区间内的切分点,仅配置切分键,无需指定全部的主键。格式为JSON数组。
数据去向
参数
说明
数据源
默认显示上一步选择的Tablestore数据源。
表
目标数据表。
主键信息
目标数据表的主键信息。
写入模式
数据写入表格存储的模式,支持以下两种模式:
PutRow:对应于Tablestore API PutRow,插入数据到指定的行。如果该行不存在,则新增一行。如果该行存在,则覆盖原有行。
UpdateRow:对应于Tablestore API UpdateRow,更新指定行的数据。如果该行不存在,则新增一行。如果该行存在,则根据请求的内容在这一行中新增、修改或者删除指定列的值。
配置字段映射。
配置数据来源与数据去向后,需要指定来源字段和目标字段的映射关系。配置字段映射关系后,任务将根据字段映射关系,将源表字段写入目标表对应类型的字段中。更多信息,请参见配置字段映射关系。
重要在来源字段中必须指定主键信息,以便读取主键数据。
由于在上一步的数据去向下已配置了目标表的主键信息,因此在目标字段中不可再配置主键信息。
当字段的数据类型为INTEGER时,您需要将其配置为INT,DataWorks会自动将其转换为INTEGER类型。如果直接配置为INTEGER类型,日志将会出现错误,导致任务无法顺利完成。
配置通道控制。
您可以通过通道配置,控制数据同步过程相关属性。相关参数说明详情可参见离线同步并发和限流之间的关系。
单击保存,保存配置。
脚本模式
在配置任务步骤,单击脚本模式,然后在弹出的对话框中单击确定。

在脚本配置页面,编辑脚本。
脚本配置示例如下,请根据您的同步信息和需求替换配置文件内的参数信息。
{ "transform": false, "type": "job", "version": "2.0", "steps": [ { "stepType": "ots", "parameter": { "datasource": "MySourceTablestoreDatasource", "table": "source_data_table", "newVersion": "true", "mode": "normal", "envType": 1, "column": [ { "name": "pk" }, { "name": "column_string" }, { "name": "column_long" }, { "name": "column_double" }, { "name": "column_binary" }, { "name": "column_bool" } ] }, "name": "Reader", "category": "reader" }, { "stepType": "ots", "parameter": { "datasource": "MyTargetTablestoreDatasource", "table": "target_data_table", "newVersion": "true", "mode": "normal", "writeMode": "PutRow", "envType": 1, "column": [ { "name": "column_string", "type": "STRING" }, { "name": "column_long", "type": "INT" }, { "name": "column_double", "type": "DOUBLE" }, { "name": "column_binary", "type": "BINARY" }, { "name": "column_bool", "type": "BOOL" } ], "primaryKey": [ { "name": "pk", "type": "string" } ] }, "name": "Writer", "category": "writer" } ], "setting": { "executeMode": null, "failoverEnable": null, "errorLimit": { "record": "0" }, "speed": { "concurrent": 2, "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }重要在Tablestore Reader的column中必须指定主键信息,以便读取主键数据。
当字段的数据类型为INTEGER时,您需要将其配置为INT,DataWorks会自动将其转换为INTEGER类型。如果直接配置为INTEGER类型,日志将会出现错误,导致任务无法顺利完成。
Tablestore Reader需要替换的参数说明如下:
参数名称
说明
datasource
源表的Tablestore数据源名称。
table
源表名称。
column
读取源表的列信息。
Tablestore Writer需要替换的参数说明如下:
参数名称
说明
datasource
目标表的Tablestore数据源名称。
table
目标表名称。
column
目标表的主键列。
primaryKey
需要写入的属性列。
重要写入目标表的列顺序必须与读取源表的列顺序保持一致。
单击保存,保存配置。
三、运行同步任务
单击任务右侧的调试配置,选择运行的资源组。
单击运行。
步骤四:查看同步结果
运行同步任务后,您可以通过日志查看任务的执行状态,并在表格存储控制台查看目标数据表的同步结果。
查看任务执行状态。
在同步任务的结果页签,查看
Current task status对应的状态。当
Current task status的值为FINISH时,表示任务运行完成。如需查看更详细的运行日志,您可以单击
Detail log url对应的链接。
查看目标数据表的同步结果。
进入实例管理页面。
登录表格存储控制台。
在页面上方,选择资源组和地域。
在概览页面,单击实例别名或在实例操作列单击实例管理。
在实例详情页签,单击数据表列表页签。
在数据表列表页签,单击目标数据表名。
在数据管理页签,即可查看同步到该数据表中的数据。
数据同步任务完成后,如果您不再需要使用工作空间和资源组,建议及时退订释放,以避免产生不必要的费用。
使用命令行工具同步数据
在使用命令行工具进行数据同步时,您需要手动将源表的数据导出为本地JSON文件,随后再将其导入到目标表。此方法仅适用于少量数据的迁移场景。针对大规模数据迁移,不建议采用此方法。
步骤一:准备工作
步骤二:导出源表数据
启动命令行工具,通过config命令配置源表所在实例的接入信息。更多信息,请参见启动并配置接入信息。
执行前请使用源表所在的实例访问地址、实例名称、AccessKey ID、AccessKey Secret替换命令中的endpoint、instance、id、key。
config --endpoint https://myinstance.cn-hangzhou.ots.aliyuncs.com --instance myinstance --id NTSVL******************** --key 7NR2****************************************导出数据。
执行
use命令以使用源表。此处以source_table为例。use --wc -t source_table导出源表中的数据到本地JSON文件中。具体操作,请参见导出数据。
scan -o /tmp/sourceData.json
步骤三:导入目标表数据
通过config命令配置目标表所在实例的接入信息。
执行前请使用目标表所在的实例访问地址、实例名称、AccessKey ID、AccessKey Secret替换命令中的endpoint、instance、id、key。
config --endpoint https://myinstance.cn-hangzhou.ots.aliyuncs.com --instance myinstance --id NTSVL******************** --key 7NR2****************************************导入数据。
执行
use命令以使用目标表。此处以target_table为例。use --wc -t target_table导入本地JSON文件中的数据到目标表中。具体操作,请参见导入数据。
import -i /tmp/sourceData.json