
本文介绍如何使用DataWorks将表格存储中时序表的全量数据或者增量数据同步到另一个时序表。
背景信息
数据集成是一个稳定高效、弹性伸缩的数据同步平台,致力于提供在复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动及同步能力。您可以在数据开发(DataStudio)界面直接创建离线同步节点,用于离线(批量)数据周期性同步。
同步类型
全量数据同步
将源时序表中现有的所有时序数据同步到目标时序表中。
增量数据同步
定时(例如每隔一天)将源时序表中新增的数据同步到目标时序表中。
前提条件
已为阿里云账号或具有表格存储权限的RAM用户创建AccessKey。
已开通DataWorks服务,并在源表或目标表所在地域创建工作空间。
已创建Serverless资源组并绑定到工作空间。有关计费信息,请参见Serverless资源组计费。
如果源表和目标表不在同一地域,请参考以下操作步骤创建VPC对等连接实现跨地域网络连通。
此处以DataWorks工作空间和源表实例所在地域一致,都位于华东1(杭州)地域为例进行介绍,目标表位于华东2(上海)地域。
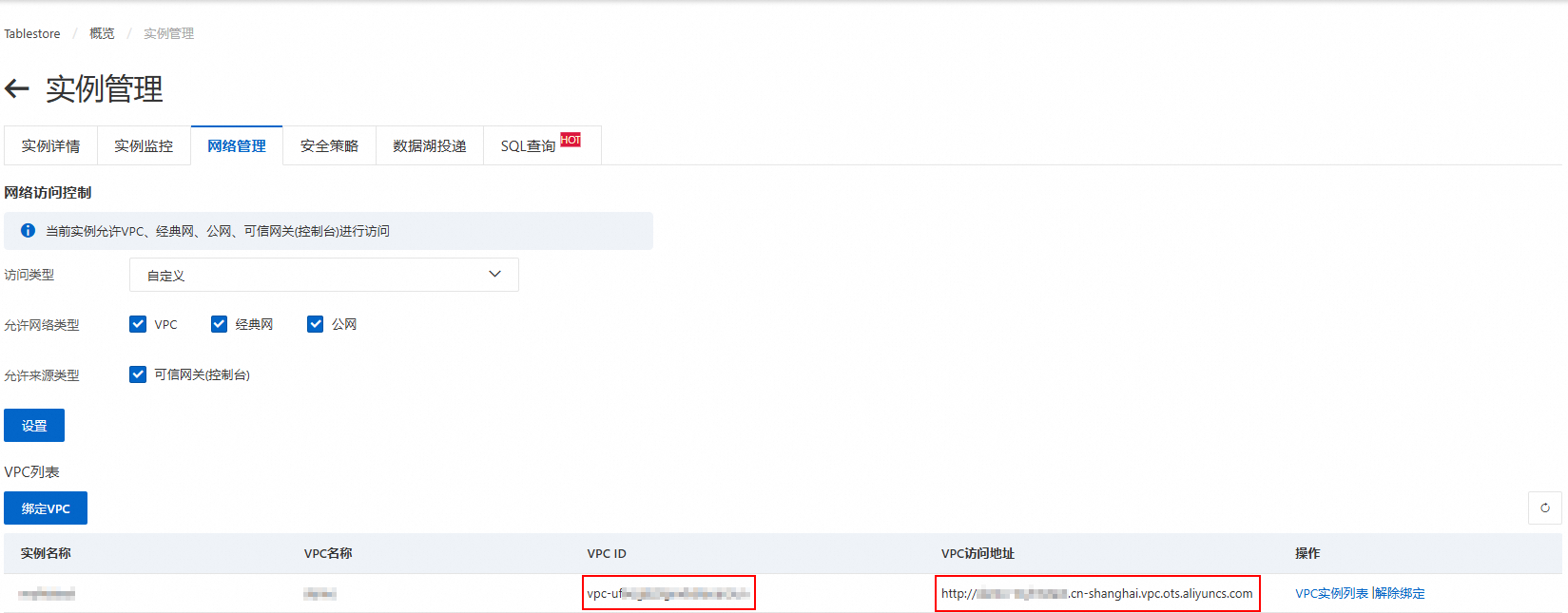
为Tablestore实例绑定VPC。
登录表格存储控制台,在页面上方选择目标表所在地域。
单击实例别名进入实例管理页面。
切换到网络管理页签,单击绑定VPC,选择VPC和交换机并填写VPC名称,然后单击确定。
请耐心等待一段时间,VPC绑定成功后页面将自动刷新,您可以在VPC列表查看绑定的VPC ID和VPC访问地址。
说明后续在DataWorks控制台添加Tablestore数据源时,将使用该VPC访问地址。
获取DataWorks工作空间资源组的VPC信息。
登录DataWorks控制台,在页面上方选择工作空间所在地域,然后单击左侧工作空间菜单,进入工作空间列表页面。
单击工作空间名称进入空间详情页面,单击左侧资源组菜单,查看工作空间绑定的资源组列表。
在目标资源组右侧单击网络设置,在资源调度 & 数据集成区域查看绑定的专有网络,即VPC ID。
创建VPC对等连接并配置路由。
登录专有网络VPC控制台。在页面左侧单击专有网络菜单,依次选择Tablestore实例和DataWorks工作空间所在地域,并记录VPC ID对应的网段地址。

在页面左侧单击VPC对等连接菜单,然后在VPC对等连接页面单击创建对等连接。
在创建对等连接页面,输入对等连接名称,选择发起端VPC实例、接收端账号类型、接收端地域和接收端VPC实例,单击确定。
在VPC对等连接页面,找到已创建的VPC对等连接,分别在发起端VPC实例列和接收端VPC实例列单击配置路由条目。
目标网段需填写对端VPC的网段地址。即在发起端VPC实例配置路由条目时,填写接收端VPC实例的网段地址;在接收端VPC实例配置路由条目时,填写发起端VPC实例的网段地址。
全量数据同步
步骤一:新增数据源
分别为源时序表和目标时序表所在的实例新增表格存储数据源。
进入数据集成页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
在左侧导航栏,单击数据源。
在数据源列表页面,单击新增数据源。
在新增数据源对话框,搜索并选择数据源类型为Tablestore。
在新增OTS数据源对话框,根据下表配置数据源参数。
参数
说明
数据源名称
数据源名称必须以字母、数字、下划线(_)组合,且不能以数字和下划线(_)开头。
数据源描述
对数据源进行简单描述,不得超过80个字符。
地域
选择Tablestore实例所属地域。
Table Store实例名称
Tablestore实例的名称。
Endpoint
Tablestore实例的服务地址,推荐使用VPC地址。
AccessKey ID
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。
AccessKey Secret
测试资源组连通性。创建数据源时,您需要测试资源组的连通性,以保证同步任务使用的资源组能够与数据源连通,否则将无法正常执行数据同步任务。
在连接配置区域,单击相应资源组连通状态列的测试连通性。
测试连通性通过后,连通状态显示可连通,单击完成。您可以在数据源列表中查看新建的数据源。
说明如果测试连通性结果为无法通过,您可使用连通性诊断工具自助解决。如仍无法连通资源组与数据源,请提交工单处理。
步骤二:配置离线同步任务
数据开发(Data Studio)旧版
一、新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入数据开发。
在DataStudio控制台的数据开发页面,单击业务流程节点下的目标业务流程。
如果需要新建业务流程,请参见创建业务流程。
在数据集成节点上右键单击,然后选择新建节点 > 离线同步。
在新建节点对话框,选择路径并填写名称,然后单击确认。
在数据集成节点下,将显示新建的离线同步节点。
二、配置同步任务
在数据集成节点下,双击打开新建的离线同步任务节点。
配置网络与资源。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
在网络与资源配置步骤,选择数据来源为Tablestore,并选择数据源名称为新增的源数据源。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
说明Serverless资源组支持为同步任务指定运行CU上限,如果您的同步任务因资源不足出现OOM现象,请适当调整资源组的CU占用取值。
选择数据去向为Tablestore,并选择数据源名称为新增的目标数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置任务并保存。
在配置任务步骤,单击
 图标,然后在弹出的对话框中单击确定。
图标,然后在弹出的对话框中单击确定。
在脚本配置页面,编辑脚本。
脚本配置示例如下,请根据您的同步信息和需求替换配置文件内的参数信息。
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "ots", "parameter": { "datasource": "MySourceTablestoreDatasource", "table": "source_timeseries_table", "newVersion": "true", "mode": "normal", "isTimeseriesTable": "true", "envType": 1, "column": [ { "name": "_m_name" }, { "name": "_data_source" }, { "name": "_tags" }, { "name": "_time" }, { "name": "string_col", "type": "STRING" }, { "name": "bool_col", "type": "BOOL" }, { "name": "int_col", "type": "INT" }, { "name": "double_col", "type": "DOUBLE" } ] }, "name": "Reader", "category": "reader" }, { "stepType": "ots", "parameter": { "datasource": "MyTargetTablestoreDatasource", "table": "target_timeseries_table", "newVersion": "true", "mode": "normal", "isTimeseriesTable": "true", "envType": 1, "column": [ { "name": "_m_name" }, { "name": "_data_source" }, { "name": "_tags" }, { "name": "_time" }, { "name": "string_col", "type": "STRING" }, { "name": "bool_col", "type": "BOOL" }, { "name": "int_col", "type": "INT" }, { "name": "double_col", "type": "DOUBLE" } ] }, "name": "Writer", "category": "writer" } ], "setting": { "errorLimit": { "record": "" }, "locale": "zh", "speed": { "throttle": false, "concurrent": 2 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }重要当字段的数据类型为INTEGER时,您需要将其配置为INT,DataWorks会自动将其转换为INTEGER类型。如果直接配置为INTEGER类型,日志将会出现错误,导致任务无法顺利完成。
Tablestore Reader需要替换的参数说明如下:
参数名称
说明
datasource
源表的Tablestore数据源名称。
table
源表名称。
column
读取源表的列信息。
Tablestore Writer需要替换的参数说明如下:
参数名称
说明
datasource
目标表的Tablestore数据源名称。
table
目标表名称。
column
需要写入的属性列。
重要写入目标表的列顺序必须与读取源表的列顺序保持一致。
单击
 图标,保存配置。
图标,保存配置。
三、运行同步任务
单击
 图标。
图标。在参数对话框,选择运行资源组的名称。
单击运行。
数据开发(Data Studio)新版
一、新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入Data Studio。
在DataStudio控制台的数据开发页面,单击项目目录右侧的
 图标,然后选择。说明
图标,然后选择。说明首次使用项目目录时,也可以直接单击新建节点按钮。
在新建节点对话框,选择路径并填写名称,然后单击确认。
在项目目录下,将显示新建的离线同步节点。
二、配置同步任务
在项目目录下,单击打开新建的离线同步任务节点。
配置网络与资源。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
在网络与资源配置步骤,选择数据来源为Tablestore,并选择数据源名称为新增的源数据源。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
说明Serverless资源组支持为同步任务指定运行CU上限,如果您的同步任务因资源不足出现OOM现象,请适当调整资源组的CU占用取值。
选择数据去向为Tablestore,并选择数据源名称为新增的目标数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置任务并保存。
在配置任务步骤,单击脚本模式,然后在弹出的对话框中单击确定。

在脚本配置页面,编辑脚本。
脚本配置示例如下,请根据您的同步信息和需求替换配置文件内的参数信息。
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "ots", "parameter": { "datasource": "MySourceTablestoreDatasource", "table": "source_timeseries_table", "newVersion": "true", "mode": "normal", "isTimeseriesTable": "true", "envType": 1, "column": [ { "name": "_m_name" }, { "name": "_data_source" }, { "name": "_tags" }, { "name": "_time" }, { "name": "string_col", "type": "STRING" }, { "name": "bool_col", "type": "BOOL" }, { "name": "int_col", "type": "INT" }, { "name": "double_col", "type": "DOUBLE" } ] }, "name": "Reader", "category": "reader" }, { "stepType": "ots", "parameter": { "datasource": "MyTargetTablestoreDatasource", "table": "target_timeseries_table", "newVersion": "true", "mode": "normal", "isTimeseriesTable": "true", "envType": 1, "column": [ { "name": "_m_name" }, { "name": "_data_source" }, { "name": "_tags" }, { "name": "_time" }, { "name": "string_col", "type": "STRING" }, { "name": "bool_col", "type": "BOOL" }, { "name": "int_col", "type": "INT" }, { "name": "double_col", "type": "DOUBLE" } ] }, "name": "Writer", "category": "writer" } ], "setting": { "errorLimit": { "record": "" }, "locale": "zh", "speed": { "throttle": false, "concurrent": 2 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }重要当字段的数据类型为INTEGER时,您需要将其配置为INT,DataWorks会自动将其转换为INTEGER类型。如果直接配置为INTEGER类型,日志将会出现错误,导致任务无法顺利完成。
Tablestore Reader需要替换的参数说明如下:
参数名称
说明
datasource
源表的Tablestore数据源名称。
table
源表名称。
column
读取源表的列信息。
Tablestore Writer需要替换的参数说明如下:
参数名称
说明
datasource
目标表的Tablestore数据源名称。
table
目标表名称。
column
需要写入的属性列。
重要写入目标表的列顺序必须与读取源表的列顺序保持一致。
单击保存,保存配置。
三、运行同步任务
单击任务右侧的调试配置,选择运行的资源组。
单击运行。
步骤三:查看同步结果
运行同步任务后,您可以通过日志查看任务的执行状态,并在表格存储控制台查看目标时序表的同步结果。
查看任务执行状态。
在同步任务的结果页签,查看
Current task status对应的状态。当
Current task status的值为FINISH时,表示任务运行完成。如需查看更详细的运行日志,您可以单击
Detail log url对应的链接。
查看目标时序表的同步结果。
进入实例管理页面。
登录表格存储控制台。
在页面上方,选择资源组和地域。
在概览页面,单击实例别名或在实例操作列单击实例管理。
在实例详情页签,单击时序表列表页签。
在时序表列表页签,单击目标时序表操作列的数据管理。
在数据管理页签,即可查看同步到该时序表中的数据。
增量数据同步
步骤一:新增数据源
分别为源时序表和目标时序表所在的实例新增数据源。
步骤二:配置离线同步任务
数据开发(Data Studio)旧版
一、新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入数据开发。
在DataStudio控制台的数据开发页面,单击业务流程节点下的目标业务流程。
如果需要新建业务流程,请参见创建业务流程。
在数据集成节点上右键单击,然后选择新建节点 > 离线同步。
在新建节点对话框,选择路径并填写名称,然后单击确认。
在数据集成节点下,将显示新建的离线同步节点。
二、配置同步任务
在数据集成节点下,双击打开新建的离线同步任务节点。
配置网络与资源。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
在网络与资源配置步骤,选择数据来源为Tablestore Stream,并选择数据源名称为新增的源数据源。
说明Tablestore Stream插件主要用于导出Tablestore增量数据,详情请参见Tablestore Stream配置同步任务。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
说明如果数据源与资源组网络不通,请参考界面提示或文档进行网络连通配置。详情请参见网络连通方案。
Serverless资源组支持为同步任务指定运行CU上限,如果您的同步任务因资源不足出现OOM现象,请适当调整资源组的CU占用取值。
选择数据去向为Tablestore,并选择数据源名称为新增的目标数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置同步任务并保存。
在配置任务步骤,单击
图标,然后在弹出的对话框中单击确定。在脚本配置页面,编辑脚本。
脚本配置示例如下,请根据您的同步信息和需求替换配置文件内的参数信息。
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "otsstream", "parameter": { "datasource": "MySourceTablestoreDatasource", "dataTable": "source_timeseries_table", "newVersion": "true", "statusTable": "TableStoreStreamReaderStatusTable", "maxRetries": 30, "isExportSequenceInfo": false, "mode": "single_version_and_update_only", "isTimeseriesTable": "true", "startTimeString": "${startTime}", "endTimeString": "${endTime}", "envType": 1, "column": [ { "name": "_m_name" }, { "name": "_data_source" }, { "name": "_tags" }, { "name": "_time" }, { "name": "string_col", "type": "STRING" }, { "name": "bool_col", "type": "BOOL" }, { "name": "int_col", "type": "INT" }, { "name": "double_col", "type": "DOUBLE" } ] }, "name": "Reader", "category": "reader" }, { "stepType": "ots", "parameter": { "datasource": "MyTargetTablestoreDatasource", "table": "target_timeseries_table", "newVersion": "true", "mode": "normal", "isTimeseriesTable": "true", "envType": 1, "column": [ { "name": "_m_name" }, { "name": "_data_source" }, { "name": "_tags" }, { "name": "_time" }, { "name": "string_col", "type": "STRING" }, { "name": "bool_col", "type": "BOOL" }, { "name": "int_col", "type": "INT" }, { "name": "double_col", "type": "DOUBLE" } ] }, "name": "Writer", "category": "writer" } ], "setting": { "errorLimit": { "record": "" }, "locale": "zh", "speed": { "throttle": false, "concurrent": 2 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }Tablestore Stream Reader需要替换的参数说明如下:
参数名称
说明
datasource
源表的Tablestore数据源名称。
dataTable
源表名称。
column
读取源表的列信息。
Tablestore Writer需要替换的参数说明如下:
参数名称
说明
datasource
目标表的Tablestore数据源名称。
table
目标表名称。
column
需要写入的属性列。
重要写入目标表的列顺序必须与读取源表的列顺序保持一致。
单击
图标,保存配置。
三、配置调度属性
单击任务右侧的调度配置。
在调度配置面板的调度参数部分,单击新增参数,根据下表说明新增参数。更多信息,请参见调度参数支持的格式。
参数
参数值
startTime
$[yyyymmddhh24-2/24]$[miss-10/24/60]
endTime
$[yyyymmddhh24-1/24]$[miss-10/24/60]
配置示例如下图所示。
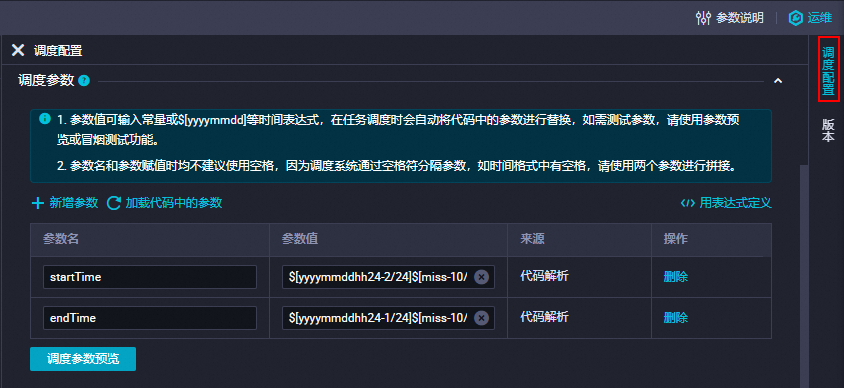
假如任务运行时的时间为2023年04月23日19:00:00,则startTime为20230423175000,endTime为20230423185000。任务将会同步17:50到18:50时段内新增的数据。
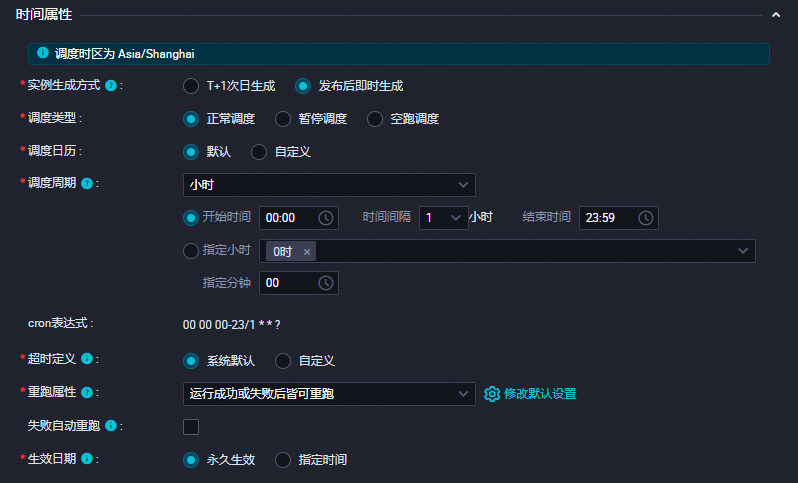
在时间属性部分,配置时间属性。更多信息,请参见时间属性配置说明。
此处以任务整点每小时自动运行为例介绍配置,如下图所示。
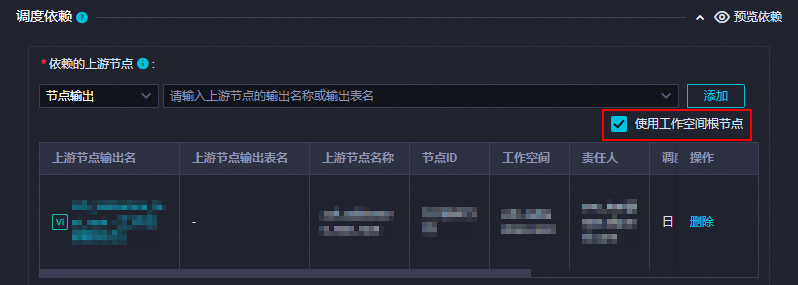
在调度依赖部分,单击使用工作空间根节点,系统会自动生成依赖的上游节点信息。
使用工作空间根节点表示该任务无上游的依赖任务。
配置完成后,关闭配置调度面板。
单击
图标,保存配置。
四、(可选)调试脚本代码
通过调试脚本代码,确保同步任务能成功同步源时序表的增量数据到目标时序表中。
调试脚本代码时配置的时间范围内的数据可能会多次导入到目标时序表,相同时间线会覆盖写入到目标时序表。
单击
图标。在参数对话框,选择运行资源组的名称,并配置自定义参数。
自定义参数的格式为
yyyyMMddHHmmss,例如20230423175000。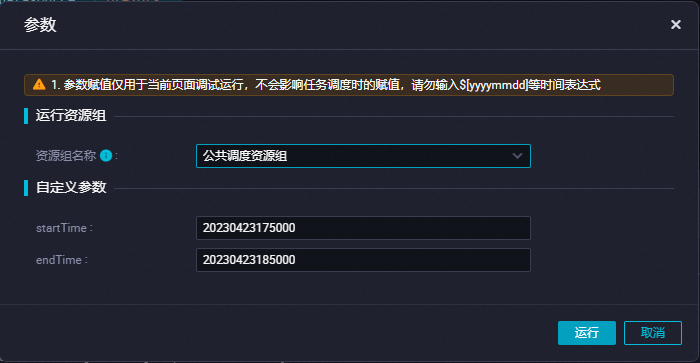
单击运行。
任务运行完成后,您可以在表格存储控制台查看目标时序表数据同步结果。
五、提交同步任务
提交同步任务后,同步任务会按照配置的调度属性运行。
单击
 图标。
图标。在提交对话框,根据需要填写变更描述。
单击确认。
数据开发(Data Studio)新版
一、新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入Data Studio。
在DataStudio控制台的数据开发页面,单击项目目录右侧的
图标,然后选择。说明首次使用项目目录时,也可以直接单击新建节点按钮。
在新建节点对话框,选择路径并填写名称,然后单击确认。
在项目目录下,将显示新建的离线同步节点。
二、配置同步任务
在项目目录下,单击打开新建的离线同步任务节点。
配置网络与资源。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
在网络与资源配置步骤,选择数据来源为Tablestore Stream,并选择数据源名称为新增的源数据源。
说明Tablestore Stream插件主要用于导出Tablestore增量数据,详情请参见Tablestore Stream配置同步任务。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
说明如果数据源与资源组网络不通,请参考界面提示或文档进行网络连通配置。详情请参见网络连通方案。
Serverless资源组支持为同步任务指定运行CU上限,如果您的同步任务因资源不足出现OOM现象,请适当调整资源组的CU占用取值。
选择数据去向为Tablestore,并选择数据源名称为新增的目标数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置同步任务并保存。
在配置任务步骤,单击脚本模式,然后在弹出的对话框中单击确定。
在脚本配置页面,编辑脚本。
脚本配置示例如下,请根据您的同步信息和需求替换配置文件内的参数信息。
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "otsstream", "parameter": { "datasource": "MySourceTablestoreDatasource", "dataTable": "source_timeseries_table", "newVersion": "true", "statusTable": "TableStoreStreamReaderStatusTable", "maxRetries": 30, "isExportSequenceInfo": false, "mode": "single_version_and_update_only", "isTimeseriesTable": "true", "startTimeString": "${startTime}", "endTimeString": "${endTime}", "envType": 1, "column": [ { "name": "_m_name" }, { "name": "_data_source" }, { "name": "_tags" }, { "name": "_time" }, { "name": "string_col", "type": "STRING" }, { "name": "bool_col", "type": "BOOL" }, { "name": "int_col", "type": "INT" }, { "name": "double_col", "type": "DOUBLE" } ] }, "name": "Reader", "category": "reader" }, { "stepType": "ots", "parameter": { "datasource": "MyTargetTablestoreDatasource", "table": "target_timeseries_table", "newVersion": "true", "mode": "normal", "isTimeseriesTable": "true", "envType": 1, "column": [ { "name": "_m_name" }, { "name": "_data_source" }, { "name": "_tags" }, { "name": "_time" }, { "name": "string_col", "type": "STRING" }, { "name": "bool_col", "type": "BOOL" }, { "name": "int_col", "type": "INT" }, { "name": "double_col", "type": "DOUBLE" } ] }, "name": "Writer", "category": "writer" } ], "setting": { "errorLimit": { "record": "" }, "locale": "zh", "speed": { "throttle": false, "concurrent": 2 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }Tablestore Stream Reader需要替换的参数说明如下:
参数名称
说明
datasource
源表的Tablestore数据源名称。
dataTable
源表名称。
column
读取源表的列信息。
Tablestore Writer需要替换的参数说明如下:
参数名称
说明
datasource
目标表的Tablestore数据源名称。
table
目标表名称。
column
需要写入的属性列。
重要写入目标表的列顺序必须与读取源表的列顺序保持一致。
单击保存,保存配置。
三、配置调度属性
单击任务右侧的调度配置。
在调度配置面板的调度参数部分,单击添加参数,根据下表说明新增参数。更多信息,请参见调度参数支持格式。
参数
参数值
startTime
$[yyyymmddhh24-2/24]$[miss-10/24/60]
endTime
$[yyyymmddhh24-1/24]$[miss-10/24/60]
配置示例如下图所示。
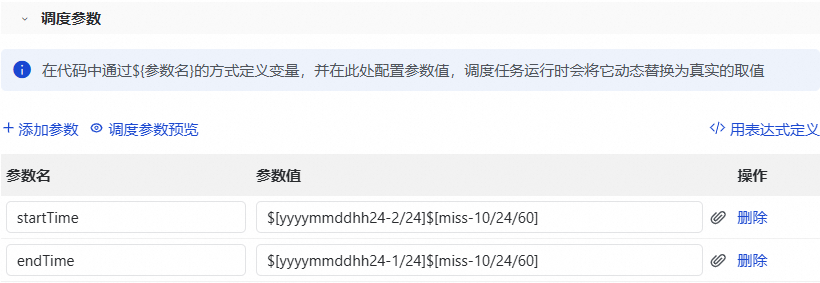
假如任务运行时的时间为2023年04月23日19:00:00,startTime为20230423175000,endTime为20230423185000。任务将会同步在17:50到18:50时段内新增的数据。
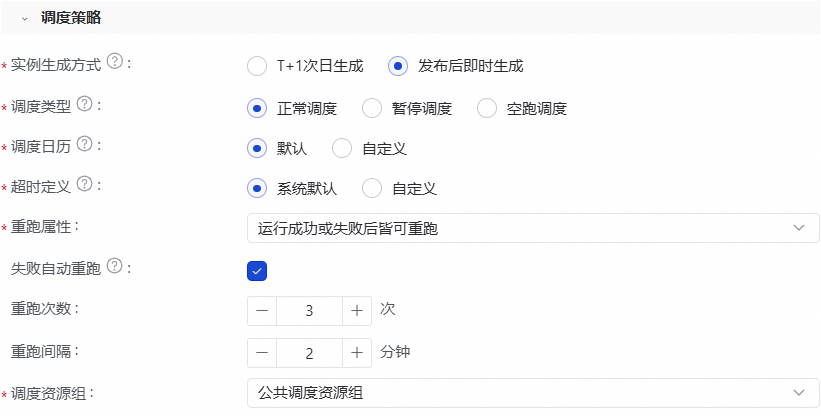
在调度策略部分,配置调度策略。更多信息,请参见实例生成方式:发布后即时生成。
在调度时间部分,配置调度时间。更多信息,请参见调度时间。
此处以任务整点每小时自动运行为例,如下图所示。
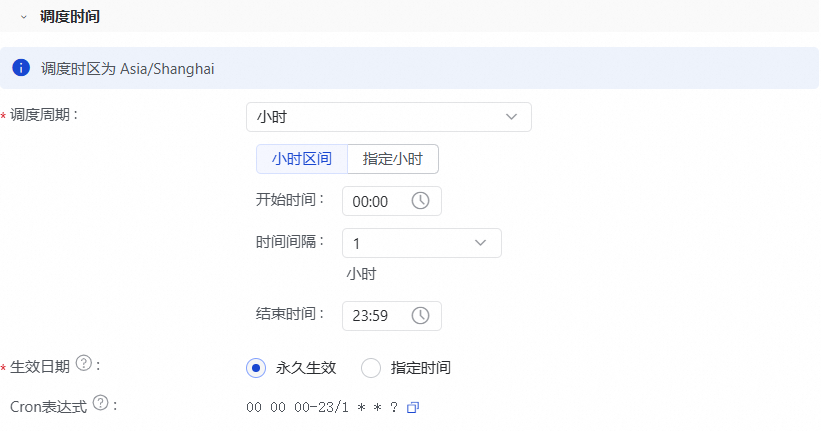
在调度依赖部分,单击使用工作空间根节点,系统会自动生成依赖的上游节点信息。
说明使用工作空间根节点表示该任务无上游的依赖任务。
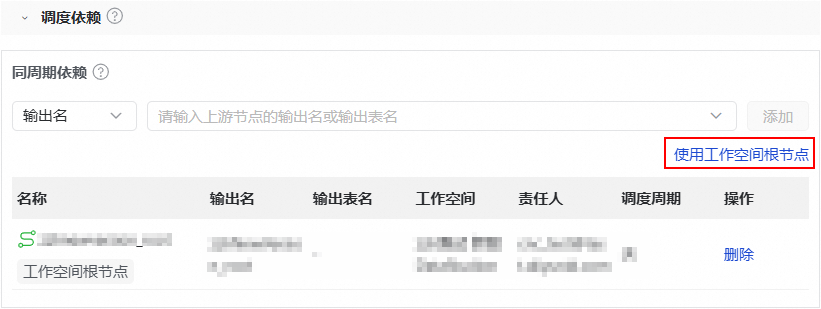
配置完成后,关闭调度配置面板。
单击保存,保存配置。
四、(可选)调试脚本代码
通过调试脚本代码,确保同步任务能成功同步源时序表的增量数据到目标时序表中。
调试脚本代码时配置的时间范围内的数据可能会多次导入到目标时序表,相同时间线会覆盖写入到目标时序表。
单击任务右侧的调试配置,选择运行的资源组,并配置脚本参数。
自定义参数的格式为
yyyyMMddHHmmss,例如20250528160000。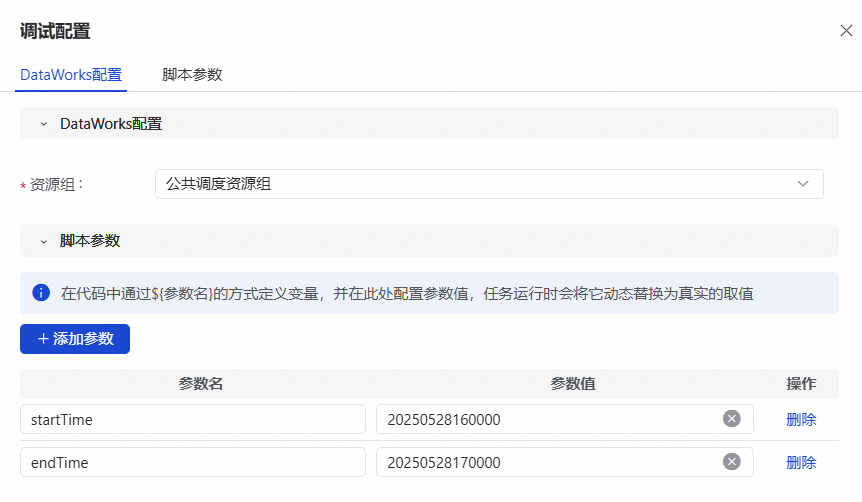
配置完成后,关闭调试配置面板。
单击运行。
任务运行完成后,您可以在表格存储控制台查看目标时序表数据同步结果。
五、发布同步任务
发布同步任务后,该同步任务将根据配置的调度属性运行。
单击发布。
在同步任务的发布页签,根据需要输入发布描述,然后单击开始发布生产。
根据发布流程引导,单击确认发布。
步骤三:查看同步结果
在DataWorks控制台查看任务运行状态。
数据开发(Data Studio)旧版
单击同步任务工具栏右侧的运维。
在周期实例页面的实例视角页签,查看实例的运行详情。更多信息,请参见周期实例视角。
数据开发(Data Studio)新版
单击前往运维查看周期实例。
在周期实例页面的实例视角页签,查看实例的运行详情。更多信息,请参见周期实例视角。
查看目标时序表的同步结果。
进入实例管理页面。
登录表格存储控制台。
在页面上方,选择资源组和地域。
在概览页面,单击实例别名或在实例操作列单击实例管理。
在实例详情页签,单击时序表列表页签。
在时序表列表页签,单击目标时序表操作列的数据管理。
在数据管理页签,即可查看同步到该时序表中的数据。