
Tablestore中的增量数据及全量数据可以通过DataWorks的数据集成同步到MaxCompute中。
实现原理
DataWorks数据集成主要用于离线(批量)数据同步。离线(批量)的数据通道通过定义数据来源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(Reader)、数据写入插件(Writer),并基于此框架设计一套简化版的中间数据传输格式,从而实现任意结构化、半结构化数据源之间的数据传输。
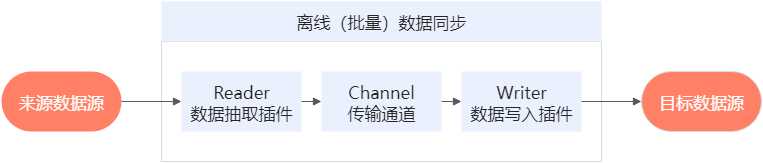
同步表格存储数据到MaxCompute时,离线同步任务中会涉及到配置表格存储相关的Reader插件和MaxCompute相关的Writer插件。相关插件说明如下:
表格存储相关的Reader插件
根据数据同步方式不同,要使用的表格存储相关的Reader插件不同。具体说明请参见下表。
同步方式
所用插件
插件说明
全量导出
Tablestore(OTS) Reader
用于读取表格存储表中的数据,并可以通过指定抽取数据范围实现数据增量抽取的需求。更多信息,请参见Tablestore数据源。
增量同步
OTSStream Reader
用于增量导出表格存储表中的数据。更多信息,请参见Tablestore Stream数据源。
MaxCompute相关的Write插件
不论使用的同步方式是全量导出还是增量同步,DataWorks均使用MaxCompute Writer插件向MaxCompute中写入数据。更多信息,请参见MaxCompute数据源。
同步方式
离线同步任务可以通过配置数据过滤并结合调度参数使用来决定同步全量数据还是增量数据。
同步方式 | 说明 | 相关文档 |
全量导出 | 将表格存储的全量数据一次性导出到MaxCompute中备份或者使用。 使用此同步方式时,只需执行一次离线同步任务即可,无需为离线同步任务配置调度属性。 | |
增量同步 | 将表格存储中新增和变化的数据定期同步到MaxCompute中备份或者使用。 使用此同步方式时,需要配置离线同步任务的调度属性用于周期性同步增量数据。 增量数据同步到MaxCompute后,您可以在MaxCompute中使用merge_udf.jar包将表格存储的增量数据转换为全量数据格式。 |