
通过DataWorks大数据开发治理平台,您可以使用ODPS SQL将MaxCompute中表格存储的增量数据转换为全量数据格式。
前提条件
已为当前DataWorks工作空间绑定MaxCompute计算资源。
已下载merge_udf.jar包。
步骤一:新建JAR资源
新建JAR资源,并上传merge_udf.jar包到DataWorks。
数据开发(Data Studio)旧版
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入数据开发。
新建JAR资源。
在DataStudio控制台的数据开发页面,单击新建,然后选择。
您也可以打开相应的业务流程,右键单击MaxCompute,选择
在新建资源对话框,配置资源的相关参数,然后单击新建。
重要如果资源未在MaxCompute客户端上传过,则必须勾选上传为ODPS资源;如果资源已上传至MaxCompute客户端,则必须取消勾选上传为ODPS资源。
如果上传时勾选了上传为ODPS资源,则在DataWorks和MaxCompute中均会存储该资源。
资源名称必须以
.jar作为后缀。
提交JAR资源。
单击
 图标。
图标。在提交对话框,根据需要填写变更描述。
单击确认。
数据开发(Data Studio)新版
进入资源管理页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入Data Studio。
在左侧导航栏单击资源管理
 图标,进入资源管理页面。
图标,进入资源管理页面。
新建JAR资源。
在资源管理页面,单击
 图标,然后选择。
图标,然后选择。在新建资源和函数对话框,选择路径并填写资源名称,然后单击确认。
重要资源名称必须以
.jar作为后缀。在新建的资源中,根据下表配置上传资源的相关参数。
参数
说明
文件来源
目标文件的来源,包括本地和OSS两种来源。
文件内容
如果选择本地,在上传文件中单击点击上传即可上传本地文件。
如果选择OSS,在选择文件下拉框中选择对应的OSS文件。
数据源
上传的MaxCompute资源所属的数据源。
单击保存,保存配置。
发布JAR资源。
单击发布。
在资源的发布页签,根据需要输入发布描述,然后单击开始发布生产。
根据发布流程引导,单击确认发布。
步骤二:新建函数
数据开发(Data Studio)旧版
新建函数。
在DataStudio控制台的数据开发页面,右键单击目标业务流程,然后选择。
在新建函数对话框,选择路径并填写函数名称。
单击新建。
注册函数。
根据下表配置函数的相关参数,然后单击
 图标,保存配置。
图标,保存配置。参数
说明
函数类型
选择其他函数。
类名
根据Tablestore源表的类型和模式,填写相应的类名。
说明您可通过Tablestore源表的最大版本数(MaxVersion)属性判断其为单版本表或多版本表。
单版本表
类名:
com.aliyun.ots.stream.utils.mergecell.oneversion.MergeCell
多版本表
类名:
com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV1类名:
com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV2
重要多版本模式V1和V2是两种不同的策略。
多版本模式V1,以行级为单位管理版本,在输出结果中,每个版本均保留整行数据的完整快照。
多版本模式V2,以列级为单位管理版本,在输出结果中,不同列的版本独立,仅保留列的增量变化。
资源列表
选择步骤一新增的资源名称。
提交函数。
单击
图标。在提交对话框,根据需要填写变更描述。
单击确认。
数据开发(Data Studio)新版
新建函数。
在资源管理页面,单击
 图标,然后选择。
图标,然后选择。在新建资源和函数对话框,选择路径并填写函数名称,然后单击确认。
在新建的函数中,根据下表配置函数的相关参数。
参数
说明
函数类型
选择OTHER(其他函数)。
数据源
MaxCompute函数所属的数据源。
类名
根据Tablestore源表的类型和模式,填写相应的类名。
说明您可通过Tablestore源表的最大版本数(MaxVersion)属性判断其为单版本表或多版本表。
单版本表
类名:
com.aliyun.ots.stream.utils.mergecell.oneversion.MergeCell
多版本表
类名:
com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV1类名:
com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV2
重要多版本模式V1和V2是两种不同的策略。
多版本模式V1,以行级为单位管理版本,在输出结果中,每个版本均保留整行数据的完整快照。
多版本模式V2,以列级为单位管理版本,在输出结果中,不同列的版本独立,仅保留列的增量变化。
类型
选择资源函数。
资源列表
选择步骤一新增的资源名称。
单击保存,保存配置。
发布函数。
单击发布。
在函数的发布页签,根据需要输入发布描述,然后单击开始发布生产。
根据发布流程引导,单击确认发布。
步骤三:编写ODPS SQL并运行
数据开发(Data Studio)旧版
新建ODPS SQL节点。
在DataStudio控制台的数据开发页面,单击新建,然后选择。
您也可以右键单击目标业务流程,然后选择。
在新建节点对话框,选择路径并填写名称。
单击确认。
在节点编辑页面,编写ODPS SQL语句。
SQL语句的格式如下:
SELECT function_name(para_list) AS (custom_para_list) FROM( SELECT * FROM stream_table_name DISTRIBUTE BY primary_keys SORT by primary_keys, SequenceID )t;参数说明如下:
参数
说明
function_name
函数名称。填写步骤二新增的函数名称。
para_list
参数列表,配置Tablestore源表和MaxCompute增量表的相关参数。
custom_para_list
自定义参数列表,定义返回结果中的字段名称。
stream_table_name
MaxCompute中存储Tablestore增量数据的表名称。
primary_keys
Tablestore源表的主键列表。
SequenceID
时序信息。填写sequenceInfo。
运行ODPS SQL。
单击
图标,运行结果将显示在结果页签下。
数据开发(Data Studio)新版
在DataStudio控制台的数据开发页面,单击
图标,然后选择。在新建节点对话框,选择路径并填写名称,然后单击确认。
在节点编辑页面,编写ODPS SQL语句。
SQL语句的格式如下:
SELECT function_name(para_list) AS (custom_para_list) FROM( SELECT * FROM stream_table_name DISTRIBUTE BY primary_keys SORT by primary_keys, SequenceID )t;参数说明如下:
参数
说明
function_name
函数名称。填写步骤二新增的函数名称。
para_list
参数列表,配置Tablestore源表和MaxCompute增量表的相关参数。
custom_para_list
自定义参数列表,定义返回结果中的字段名称。
stream_table_name
MaxCompute中存储Tablestore增量数据的表名称。
primary_keys
Tablestore源表的主键列表。
SequenceID
时序信息。填写sequenceInfo。
运行ODPS SQL。
单击运行,运行结果将显示在结果页签下。
 图标,然后选择
图标,然后选择附录:模式选择
模式包括单版本模式、多版本模式V1和多版本模式V2,请根据Tablestore表类型选择合适的模式。
单版本模式
类名
com.aliyun.ots.stream.utils.mergecell.oneversion.MergeCell
参数列表
参数列表的格式为pknum,colnum,colnames,pknames,colname,version,colvalue,optype,sequenceinfo,详细信息请参见下表。
参数 | 类型 | 说明 |
pknum |
| Tablestore源表的主键数量。 |
colnum |
| 需合并增量变更的Tablestore属性列数量。 |
colnames |
| 需合并增量变更的Tablestore属性列名称,使用逗号(,)分隔。 |
pknames |
| Tablestore源表的主键列表,使用逗号(,)分隔。 |
colname |
| 属性列(由增量表字段colname提供)。 |
version |
| 版本号(由增量表字段version提供)。 |
colvalue |
| 增量值(由增量表字段colvalue提供)。 |
optype |
| 增量操作类型(由增量表字段optype提供)。 |
sequenceinfo |
| 时序信息(由增量表字段sequenceInfo提供)。 |
示例
假设Tablestore源表和MaxCompute增量表结构如下:
Tablestore源表结构:主键为
pk1,pk2,属性列为col1,col2,col3。MaxCompute增量表结构:
pk1,pk2,colname,version,colvalue,optype,sequenceinfo。
如果要将MaxCompute增量表中的增量数据转换为全量数据格式,则需设置参数列表为2,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo,并设置自定义参数列表为pk1,pk2,col1,col1_is_deleted,col2,col2_is_deleted,col3,col3_is_deleted。
ODPS SQL语句示例如下:
SELECT mergeCell(2,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo)
AS (pk1,pk2,col1,col1_is_deleted,col2,col2_is_deleted,col3,col3_is_deleted)
FROM(
SELECT * FROM stream_table_name
DISTRIBUTE BY pk1,pk2
SORT by pk1,pk2,sequenceInfo
)t;执行ODPS SQL语句后,输出结果的示例数据请参见下表。
pk1 | pk2 | col1 | co1_is_deleted | col2 | col2_is_deleted | col3 | col3_is_deleted |
test | 0 | \N | \N | 20 | \N | \N | True |
输出结果的说明如下:
当col列和col_is_deleted列均为
\N时,表示col列无任何增量操作。当col列为具体的值且col_is_deleted列为
\N时,表示col列的值被修改为对应值。当col列为
\N且col_is_deleted列为true时,表示col列被删除。
多版本模式V1
类名
com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV1
参数列表
参数列表的格式为pknum,colnum,colnames,pknames,colname,version,colvalue,optype,sequenceinfo,详细信息请参见下表。
参数 | 类型 | 说明 |
pknum |
| Tablestore源表的主键数量。 |
colnum |
| 需合并增量变更的Tablestore属性列数量。 |
colnames |
| 需合并增量变更的Tablestore属性列名称,使用逗号(,)分隔。 |
pknames |
| Tablestore源表的主键列表,使用逗号(,)分隔。 |
colname |
| 属性列(由增量表字段colname提供)。 |
version |
| 版本号(由增量表字段version提供)。 |
colvalue |
| 增量值(由增量表字段colvalue提供)。 |
optype |
| 增量操作类型(由增量表字段optype提供)。 |
sequenceinfo |
| 时序信息(由增量表字段sequenceInfo提供)。 |
示例
假设Tablestore源表和MaxCompute增量表结构如下:
Tablestore源表结构:主键为
pk1,pk2,属性列为col1,col2,col3。MaxCompute增量表结构:
pk1,pk2,colname,version,colvalue,optype,sequenceinfo。
如果要将MaxCompute增量表中的增量数据转换为全量数据格式,则需设置参数列表为2,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo,并设置自定义参数列表为pk1,pk2,version,col1,col1_is_deleted,col2,col2_is_deleted,col3,col3_is_deleted。
ODPS SQL语句示例如下:
SELECT mergeCell(2,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo)
AS (pk1,pk2,version,col1,col1_is_deleted,col2,col2_is_deleted,col3,col3_is_deleted)
FROM(
SELECT * FROM stream_table_name
DISTRIBUTE BY pk1,pk2
SORT by pk1,pk2,sequenceInfo
)t;执行ODPS SQL语句后,输出结果的示例数据请参见下表。
pk1 | pk2 | version | col1 | co1_is_deleted | col2 | col2_is_deleted | col3 | col3_is_deleted |
test | 0 | 123 | \N | \N | 20 | \N | \N | True |
输出结果的说明如下:
当version列为具体的值,且col列和col_is_deleted列均为
\N时,表示col列对应版本没有任何增量操作。当version列和col列均为具体的值,且col_is_deleted列为
\N时,表示col列对应版本的值被修改为具体的值。当version列为具体的值,col列为
\N,且col_is_deleted列为true时,表示col列对应版本被删除。当version列和col列均为
\N,且col_is_deleted列为true时,表示存在删除一列所有版本的操作。
多版本模式V2
类名
com.aliyun.ots.stream.utils.mergecell.multiversion.MergeCellV2
参数列表
参数列表的格式为pknum,colnum,maxversion,colnames,pknames,colname,version,colvalue,optype,sequenceinfo,详细信息请参见下表。
参数 | 类型 | 说明 |
pknum |
| Tablestore源表的主键数量。 |
colnum |
| 需合并增量变更的Tablestore属性列数量。 |
maxversion |
| Tablestore源表的最大版本数。 |
colnames |
| 需合并增量变更的Tablestore属性列名称,使用逗号(,)分隔。 |
pknames |
| Tablestore源表的主键列表,使用逗号(,)分隔。 |
colname |
| 属性列(由增量表字段colname提供)。 |
version |
| 版本号(由增量表字段version提供)。 |
colvalue |
| 增量值(由增量表字段colvalue提供)。 |
optype |
| 增量操作类型(由增量表字段optype提供)。 |
sequenceinfo |
| 时序信息(由增量表字段sequenceInfo提供)。 |
示例
假设Tablestore源表和MaxCompute增量表结构如下:
Tablestore源表结构:主键为
pk1,pk2,属性列为col1,col2,col3且最大版本数为3。MaxCompute增量表结构:
pk1,pk2,colname,version,colvalue,optype,sequenceinfo。
如果要将MaxCompute增量表中的增量数据转换为全量数据格式,则需设置参数列表为2,3,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo,并设置自定义参数列表为pk1,pk2,col1,col2,col3。
ODPS SQL语句示例如下:
SELECT mergeCell(2,3,3,"col1","col2","col3",pk1,pk2,colname,version,colvalue,optype,sequenceinfo)
AS (pk1,pk2,col1,col2,col3)
FROM(
SELECT * FROM stream_table_name
DISTRIBUTE BY pk1,pk2
SORT by pk1,pk2,sequenceInfo
)t;执行ODPS SQL语句后,输出结果的示例数据请参见下表。
pk1 | pk2 | col1 | col2 | col3 |
test | 02 | {"data":[{"version":1621330803390,"value":"value001"},{"version":1621330795198,"value":"value002"},{"version":1621330785936,"value":"value003"}],"needDeleteAllVersionFirst":true,"deleteVersions":[]} | \N | \N |
输出结果的说明如下:
data表示新写入的数据列表,按照版本号降序排序。最多保留maxversion个版本的数据。
needDeleteAllVersionFirst表示该列是否需要删除原有全部版本。当出现删除一行DeleteRow或删除一列的所有版本DeleteColumns时,该值为true,否则为false。
deleteVersions表示该列需要删除的版本列表,按照版本号降序排序。最多保留maxversion个版本。
deleteVersions中的版本号不会与data中的版本号相同,当needDeleteAllVersionFirst为true时,deleteVersions为空列表。
常见问题
执行SQL语句进行表格存储数据格式转换时出现类型转换错误问题
问题现象
在DataWorks中通过数据开发执行SQL语句进行表格存储数据格式转换时出现如下错误:
FAILED ODPS -0010000:System internal error -fuxi job failed, causer by: Failed in UDF/UDTF/UDAF com.aliyun.otsstream.utils.mergecell.oneversion.MergeCell class, at query location of line 1, column 8可能原因
odps.sql.type.system.odps2参数的配置不正确(即odps.sql.type.system.odps2=true)。数据同步时Tablestore和MaxCompute中字段类型不一致。
解决方案
在SQL语句前添加
set odps.sql.type.system.odps2=false;,并与SQL语句一起提交运行。检查同步任务中是否有字段类型不一致情况。如果字段类型不一致,请修改后重新同步,再从增量转全量。
属性列映射不到值且未查到值的属性列均显示被删除
问题现象
执行SQL语句后,返回结果中存在属性列无法映射到实际值,并且与该属性列对应的is_deleted字段值为
True。例如,属性列col1的值均为
\N且col1_is_deleted列值均为True,表示col1列已被删除,但实际col1列的值不为空。可能原因
在配置离线同步任务时,导出时序信息的参数配置错误(即
"isExportSequenceInfo": false),导致系统误判属性列已被删除。说明sequenceInfo字段用于存储属性列的历史版本信息。如果未导出sequenceInfo,在将增量数据转换为全量数据格式时,可能无法正确解析版本信息,从而导致相应版本的数据无法映射至目标行中。
解决方案
在步骤三:配置离线同步任务中,修改导出时序信息的参数配置,随后重新同步Tablestore增量数据,最后再执行SQL语句进行数据格式转换。
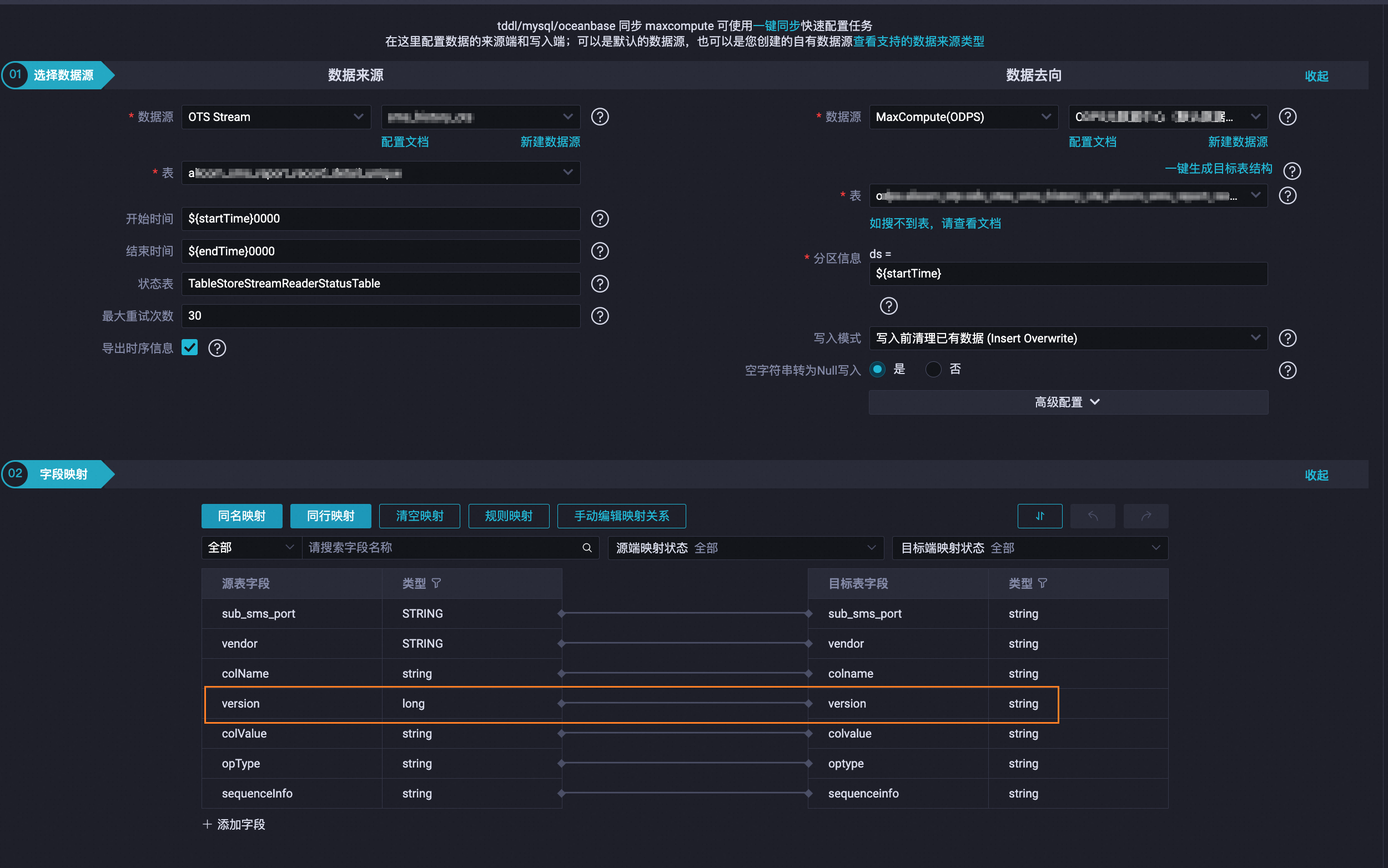
向导模式
在配置任务步骤的配置数据来源与去向区域,请勾选导出时序信息的单选框,然后保存和提交任务。
脚本模式
修改Tablestore Stream Reader中isExportSequenceInfo参数的值为
true,然后保存和提交任务。