本文介绍如何在MaxCompute客户端上运行SQL命令并通过Tunnel Download导出结果数据。
前提条件
已向MaxCompute的表中导入数据。更多导入数据操作,请参见
导入数据。
背景信息
MaxCompute客户端支持DDL、DML、DQL等操作,您可以结合相应语法运行SQL命令。
MaxCompute客户端的常用SQL命令,请参见常用命令列表。
步骤一:运行SQL命令
- 在MaxCompute客户端,基于非分区表bank_data和分区表bank_data_pt,查询各个学历下的贷款买房的单身人士数量,并将结果分别保存到result_table1和result_table2中。
命令示例如下。
--查询非分区表bank_data中各个学历下的贷款买房的单身人士数量并将查询结果写入result_table1。
insert overwrite table result_table1
select education, count(marital) as num
from bank_data
where housing = 'yes' and marital = 'single'
group by education;
--查询分区表bank_data_pt中各个学历下的贷款买房的单身人士数量并将查询结果写入result_table2。
set odps.sql.allow.fullscan=true;
insert overwrite table result_table2
select education, count(marital) as num, credit
from bank_data_pt
where housing = 'yes' and marital = 'single'
group by education, credit;
- 查询result_table1和result_table2的写入结果。
命令示例如下。
select * from result_table1;
select * from result_table2;
返回结果如下。
--result_table1中的数据。
+------------+------------+
| education | num |
+------------+------------+
| basic.4y | 227 |
| basic.6y | 172 |
| basic.9y | 709 |
| high.school | 1641 |
| illiterate | 1 |
| professional.course | 785 |
| university.degree | 2399 |
| unknown | 257 |
+------------+------------+
--result_table2中的数据。
+------------+------------+------------+
| education | num | credit |
+------------+------------+------------+
| basic.4y | 164 | no |
| basic.4y | 63 | unknown |
| basic.6y | 104 | no |
| basic.6y | 68 | unknown |
| basic.9y | 547 | no |
| basic.9y | 162 | unknown |
| high.school | 1469 | no |
| high.school | 172 | unknown |
| illiterate | 1 | unknown |
| professional.course | 721 | no |
| professional.course | 64 | unknown |
| university.degree | 2203 | no |
| university.degree | 196 | unknown |
| unknown | 206 | no |
| unknown | 51 | unknown |
+------------+------------+------------+
步骤二:导出结果数据
基于Tunnel Download将MaxCompute表中的数据导出到本地。更多Tunnel操作,请参见Tunnel命令。导出结果数据的操作流程如下:
- 确认数据文件的导出路径。
数据文件的导出路径有两种选择:您可以直接将数据以文件形式导出至
MaxCompute
客户端的
bin目录中,导出路径为
文件名.后缀名;也可以导出至其他路径下,例如
D
盘的
test
文件夹,导出路径为
D:\test\文件名.后缀名。
假设,表result_table1的数据导出至MaxCompute客户端的bin目录中,result_table2的数据导出至D盘的test文件夹下。
- 在MaxCompute客户端,执行Tunnel Download命令导出数据。
命令示例如下。
tunnel download result_table1 result_table1.txt;
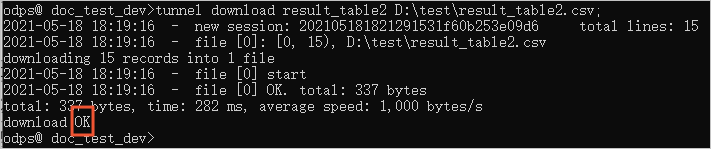
tunnel download result_table2 D:\test\result_table2.csv;
当出现图示
OK字样,说明导出完成。
- 在导出路径下确认数据文件的存在性及完整性。
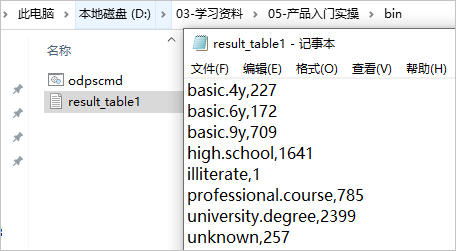
result_table1的导出结果确认如下。
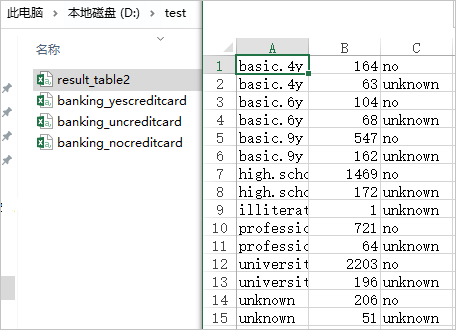
result_table2的导出结果确认如下。
后续步骤
如果您不再需要示例数据或MaxCompute项目,可以删除数据或MaxCompute项目,以免产生不必要的资源浪费及账单费用。删除数据或MaxCompute项目的操作,请参见删除表或MaxCompute项目。