
Designer通过工作流的方式来实现模型构建。您需要先创建一个工作流,再根据建模需求在工作流中排布不同组件的处理调度逻辑。本文通过创建一个空白工作流,以构建二分类模型实现心脏疾病预测为例,带您完成从0~1的可视化模型构建和部署。
前提条件
已开通PAI并创建工作空间,详情请参见开通并创建默认工作空间。
工作空间已关联MaxCompute资源,详情请参见快速入门-准备工作。
步骤一:新建工作流
前往可视化建模(Designer),选择工作空间并进入Designer页面。新建并进入工作流。

参数 | 说明 |
工作流名称 | 自定义名称。 |
工作流数据存储 | 建议您配置该参数,将其配置为OSS Bucket存储路径,用于存储运行中产出的临时数据和模型。若不设置,则取工作空间的默认存储。 系统会在每次运行时,自动为您创建 |
可见范围 |
|
步骤二:数据准备与预处理
构建模型前,您需要准备好所要使用的数据源,并完成数据的预处理,以便后续根据业务需求进行模型训练。
准备数据
在工作流中通过添加源/目标类型组件实现数据读取,支持读取MaxCompute、OSS等数据,详情可参见组件参考:源/目标下具体组件文档。本文直接使用读数据表组件来读取PAI提供的心脏病案例公开数据,数据集详情请参见Heart Disease Data Set。

选择合适源/目标组件来读取数据。
在左侧组件列表中,单击源/目标文件,将读数据表组件拖入右侧画布中,用于读取MaxCompute表数据。画布中会自动生成一个名称为读数据表-1的工作流节点。
在节点配置页面配置源数据表名。
在画布中选中读数据表-1节点,在右侧节点配置页面的表名中填写对应的MaxCompute表名。本文填写为
pai_online_project.heart_disease_prediction,读取PAI提供的公开的心脏病案例数据表。将右侧的节点配置页面切换到字段信息页签,查看此公开数据的字段详情。
数据预处理
本文心脏病预测示例可以归属于二分类问题,使用的逻辑回归模型组件要求输入数据为DOUBLE(或BIGINT)类型,因此本部分将完成对心脏病案例数据的类型转换等预处理,为模型训练做准备。
数据预处理:将非数值类型字段转换为数值类型。

搜索SQL脚本组件并将其拖入画布中,画布中生成一个名称为SQL脚本-1的工作流节点。
通过连线,将读数据表-1节点作为SQL脚本-1节点的t1输入源。
配置节点。
单击SQL脚本-1节点,在右侧配置页面输入以下代码(此时右侧参数设置面板的输入源为t1)。
select age, (case sex when 'male' then 1 else 0 end) as sex, (case cp when 'angina' then 0 when 'notang' then 1 else 2 end) as cp, trestbps, chol, (case fbs when 'true' then 1 else 0 end) as fbs, (case restecg when 'norm' then 0 when 'abn' then 1 else 2 end) as restecg, thalach, (case exang when 'true' then 1 else 0 end) as exang, oldpeak, (case slop when 'up' then 0 when 'flat' then 1 else 2 end) as slop, ca, (case thal when 'norm' then 0 when 'fix' then 1 else 2 end) as thal, (case status when 'sick' then 1 else 0 end) as ifHealth from ${t1};单击画布左上方的保存,保存工作流配置。
右键单击SQL脚本-1组件,单击从根节点执行到此处,调试运行本工作流。
工作流将根据节点顺序依次运行各节点。当节点成功运行完成后,节点的右上角会显示
 。说明
。说明您也可以单击画布左上方的
 (运行)图标,直接运行整个工作流。当工作流比较复杂时,建议您分模块运行某个节点或部分节点,以方便进行调试。如果运行失败,可右键单击对应节点选择查看日志,排查失败原因。
(运行)图标,直接运行整个工作流。当工作流比较复杂时,建议您分模块运行某个节点或部分节点,以方便进行调试。如果运行失败,可右键单击对应节点选择查看日志,排查失败原因。运行成功后,您可以右键单击目标节点(例如SQL脚本-1),选择查看当前节点输出数据的正确性。
数据预处理:将字段转换为DOUBLE类型,使得处理后的字段满足逻辑回归模型的输入数据要求。
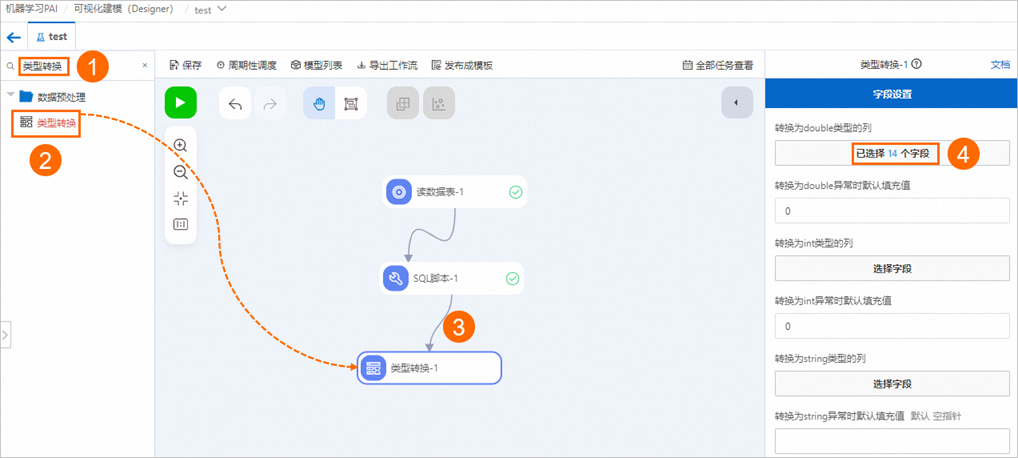
参考上一步,拖入类型转换组件并连线,使其作为SQL脚本-1节点的下游节点,单击节点后在字段设置页签,单击转换为double类型的列下的选择字段,全选将所有字段转换为DOUBLE类型。
数据预处理:归一化处理,将每个特征的数值范围转换为0~1,去除量纲对结果的影响。
参考上一步,拖入归一化组件并连线,使其作为类型转换-1节点的下游节点,单击节点后在字段设置页签,选择所有字段。
数据预处理:将数据拆分为训练集和预测集,为后续模型训练和预测做准备。
拖入拆分组件并连线,使其作为归一化-1节点的下游节点,拆分后输出2个数据表。
拆分组件默认将数据按4:1拆分为模型训练集和模型预测集。您可以单击拆分组件,在右侧参数设置页签,设置切分比例,其他参数详情请参见拆分。
右键单击类型转换-1组件,单击从此处开始执行,运行工作流中的剩余节点。
步骤三:模型训练
因为本示例中每个样本只会患病或健康,所以心脏病预测属于二分类问题,本部分使用逻辑回归二分类组件,构建心脏病预测模型。
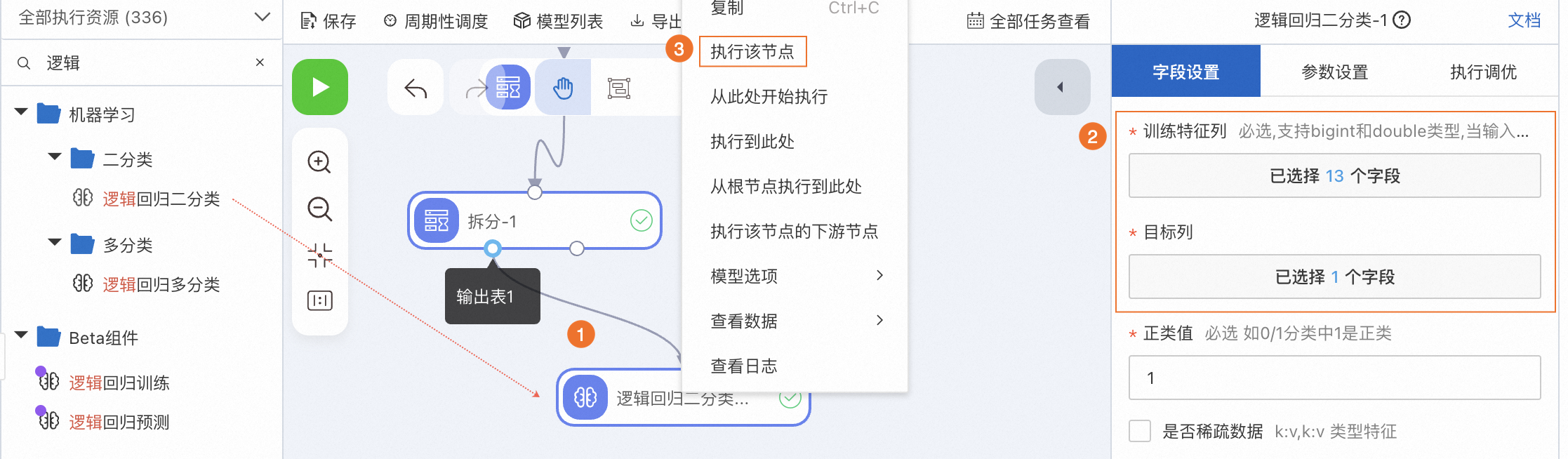
拖入逻辑回归二分类组件并连线,使其作为拆分-1节点输出表1的下游节点。
配置节点。
单击逻辑回归二分类-1节点,在右侧字段设置页签,将目标列设置为ifhealth,将训练特征列设置为除目标列以外的所有列。更多参数详情请参见逻辑回归二分类。
说明如果您需要完成后续的步骤六:模型部署(可选),需选中逻辑回归二分类节点,在右侧字段设置页签勾选是否生成PMML复选框。
运行该节点。
步骤四:模型预测
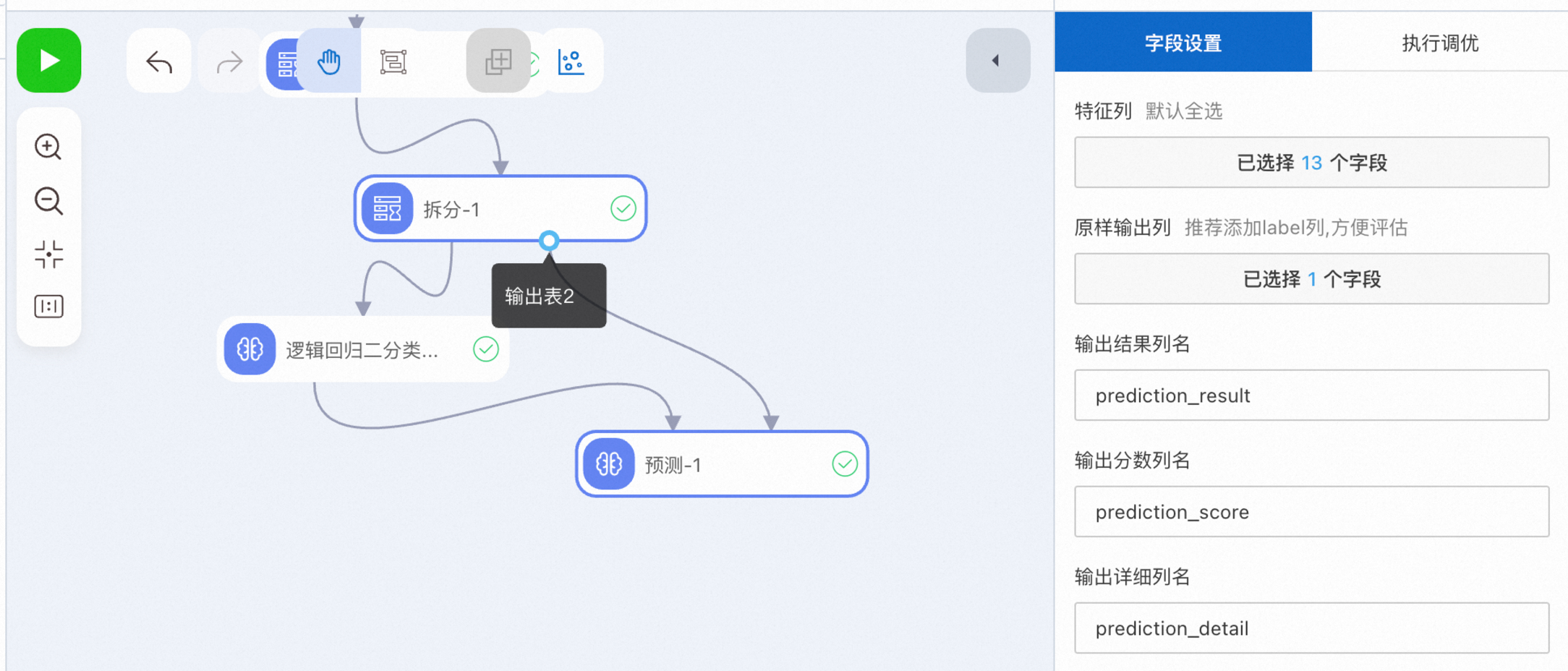
运行预测节点并查看预测结果。
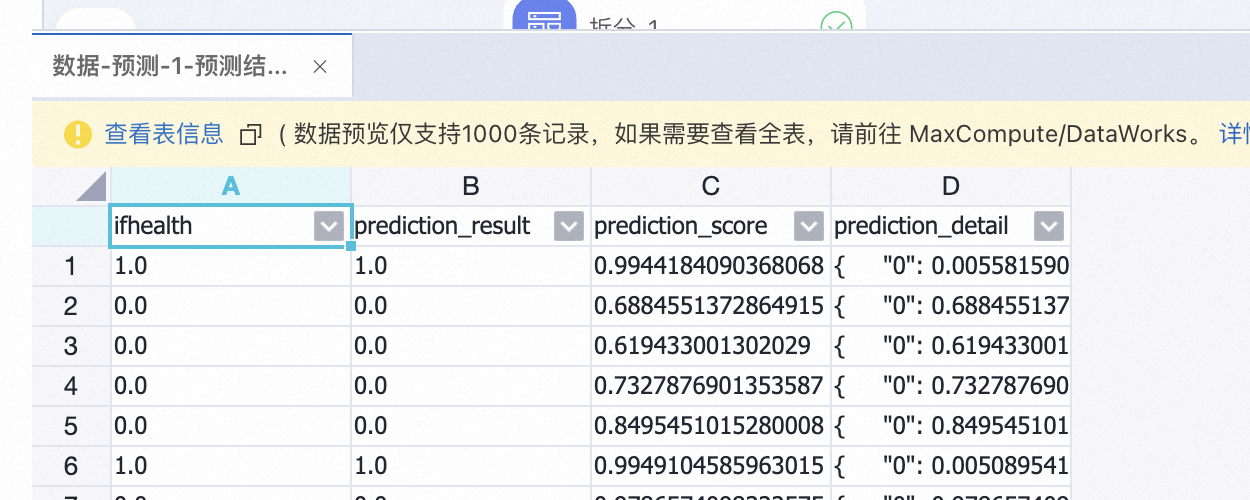
运行成功后,您可以右键单击预测节点,选择,查看预测数据。
步骤五:模型评估
拖入二分类评估组件并连线,使其作为预测-1节点的下游节点。
单击二分类评估-1节点,在右侧字段设置页签,将原始标签列列名设置为ifhealth。
运行评估节点,并查看模型评估结果。
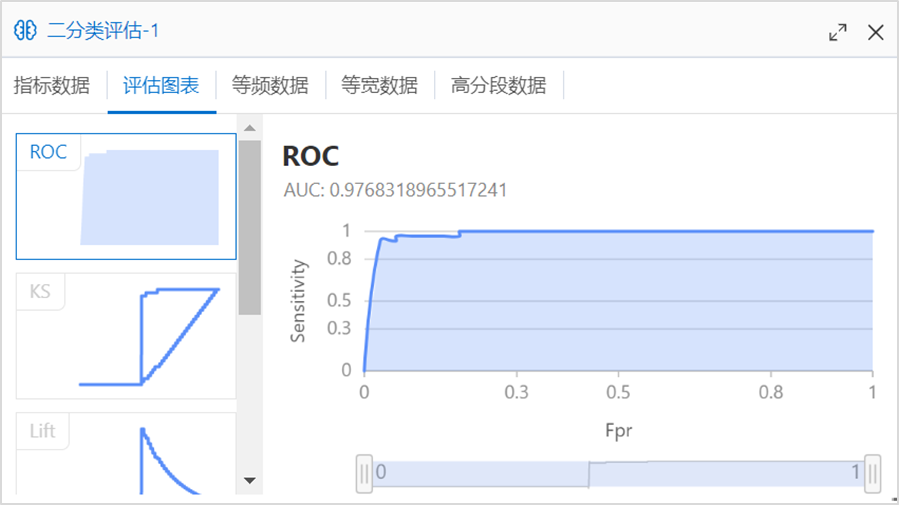
运行结束后,右键单击二分类评估组件,选择可视化分析,支持以可视化方式查看不同评估指标数据。
步骤六:模型部署(可选)
Designer和EAS在使用链路上进行了无缝对接,您可以在离线训练、离线预测和评估流程完成后,将单个模型部署至EAS,以创建一个在线模型服务。
工作流运行成功后,单击模型列表,选择要部署的模型,单击部署至EAS。
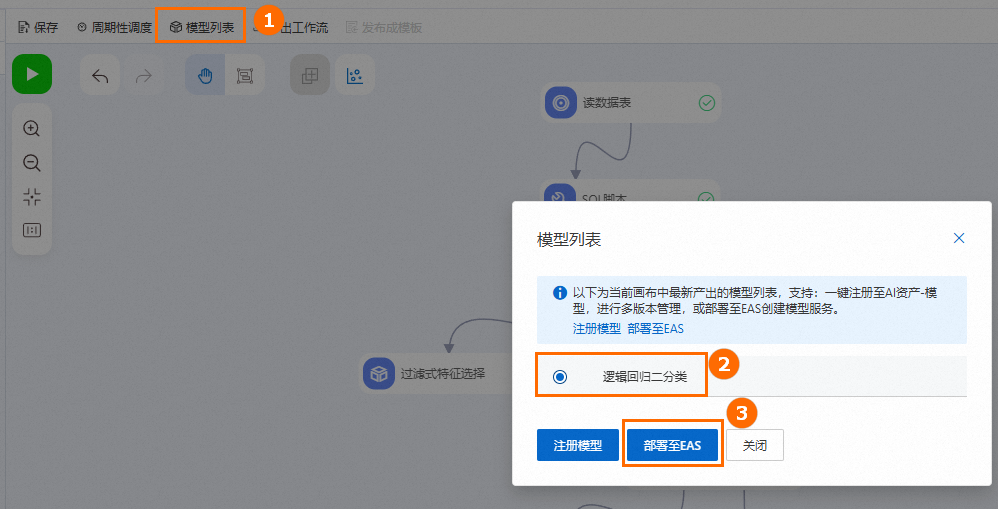
确认配置参数,详情请参见单模型部署在线服务。
在EAS部署页面,模型文件和Processor种类默认已配置完成,其他参数可根据实际需要进行配置。
单击部署。
当服务状态从创建中变为运行中时,表示模型部署成功。
重要如果后续不使用已部署的在线模型,可以单击操作列的停止,避免产生不必要的费用。
相关文档
Designer提供了丰富的工作流模板,您也可以直接基于模板快速构建模型,详情请参见模板工作流。
您可以通过DataWorks实现离线工作流的离线调度,周期性地更新模型,详情请参见使用DataWorks离线调度Designer工作流。
支持在工作流中配置全局变量,可用于在线工作流以及DataWorks离线调度工作流,提升工作流的灵活性和效率,详情请参见全局变量。