
本文介绍您在创建集群、使用集群、管理集群等过程中可能遇到的常见问题及对应解决方案。
索引
关于控制台访问、组件、节点、Pod、存储、网络等异常,可参见故障排除进行排查。
一级分类 | 二级分类 | FAQ |
集群创建和管理 | 集群创建 | |
集群删除 | ||
集群版本和升级 | 集群版本 | |
集群升级 | ||
集群连接和KubeConfig管理 | 获取KubeConfig | |
清除KubeConfig | ||
KubeConfig回收站 | ||
集群迁移 | 基础版至Pro版 | |
专有集群至托管集群 | ||
自建集群 | ||
其他 |
| |
如何将自建的Kubernetes集群迁移到ACK上来?
ACK提供了迁移方案,支持将自建Kubernetes集群平滑迁移至ACK集群,并尽量确保迁移期间对业务无影响。具体流程,请参见Kubernetes迁移方案概述。
Alibaba Cloud Linux操作系统的集群兼容CentOS的容器镜像吗?
兼容。更多信息,请参见Alibaba Cloud Linux 3。
创建集群选择了containerd容器运行时,是否可以改为Docker?
集群创建后,容器运行时不可更改。您可以创建不同类型运行时的节点池,节点池与节点池的运行时可以不同。更多信息,请参见创建和管理节点池。
如需将节点容器运行时从Docker迁移到containerd。具体操作,请参见将节点容器运行时从Docker迁移到containerd。
v1.24及之后的集群版本不再支持将Docker作为内置容器运行时。请在v1.24及之后的集群中使用containerd作为节点池运行时。
容器运行时containerd、Docker、安全沙箱有什么区别?
容器服务 Kubernetes 版支持containerd、Docker、安全沙箱三种运行时。推荐您使用containerd运行时。Docker运行时仅支持v1.22版本及以下的集群;安全沙箱运行时仅支持v1.24版本及以下的集群。更多运行时的对比信息,请参见containerd、安全沙箱、Docker运行时的对比。将ACK集群升级至v1.24及更高版本时,需将节点容器运行时从Docker迁移到containerd。具体操作,请参见将节点容器运行时从Docker迁移到containerd。
容器服务ACK通过等保三级认证了吗?
您可以为您的集群开启等保加固、配置基线检查策略,基于Alibaba Cloud Linux实现等保2.0三级版以及配置等保合规的基线检查,以便满足以下等保合规要求:
身份鉴别
访问控制
安全审计
入侵防范
恶意代码防范
更多信息,请参见ACK等保加固使用说明。
ACK集群是否支持Istio?
支持。您可以使用阿里云服务网格ASM。ASM是完全兼容社区Istio的服务网格产品,控制面全托管,让您更专注于业务应用的开发部署。ASM适配ACK节点的各种操作系统以及集群中部署的各类网络插件。您可以将创建好的ACK集群添加到ASM实例中,使用ASM提供的流量管理、故障处理、统一监控和日志管理等功能。具体操作,请参见添加集群到ASM实例。关于ASM涉及的计费,请参见ASM计费说明。
如何收集Kubernetes集群诊断信息?
当Kubernetes集群出现问题或者节点异常时,您可通过容器服务ACK提供的一键故障诊断功能,辅助您定位集群中出现的问题,详情请参见使用集群诊断。
如果集群诊断功能无法满足需求,您需要分别在Master节点和异常的Worker节点上收集Kubernetes集群的诊断信息时,请根据下文步骤收集Linux节点或Windows节点的诊断信息。
收集Linux节点诊断信息
不同节点所使用的操作系统有所限制,Worker节点可以使用Linux系统和Windows系统,Master节点只能使用Linux系统,以下方法同时适用于Linux系统的Master和Worker节点,该操作以Master节点为例。
登录Kubernetes集群的Master节点,执行以下命令,下载诊断脚本。
curl -o /usr/local/bin/diagnose_k8s.sh http://aliacs-k8s-cn-hangzhou.oss-cn-hangzhou.aliyuncs.com/public/diagnose/diagnose_k8s.sh说明Linux节点的诊断脚本仅支持从华东1(杭州)地域下载。
执行以下命令,给诊断脚本添加执行权限。
chmod u+x /usr/local/bin/diagnose_k8s.sh执行以下命令,进入指定目录。
cd /usr/local/bin执行以下命令,运行诊断脚本。
diagnose_k8s.sh系统显示类似如下,每次执行诊断脚本,产生的日志文件名称不同,本文以diagnose_1514939155.tar.gz为例,现场以实际环境为准。
...... + echo 'please get diagnose_1514939155.tar.gz for diagnostics' please get diagnose_1514939155.tar.gz for diagnostics + echo '请上传 diagnose_1514939155.tar.gz' 请上传 diagnose_1514939155.tar.gz执行如下命令,查看存放集群诊断信息的文件。
ls -ltr | grep diagnose_1514939155.tar.gz说明将diagnose_1514939155.tar.gz替换为现场环境产生的日志文件名称。
收集Windows节点诊断信息
Windows系统的Worker节点,请下载并运行diagnose诊断脚本,收集集群诊断信息,具体操作如下。
Windows系统仅充当Worker节点。
登录异常Worker节点,打开命令行工具。
执行以下命令,进入PowerShell模式。
powershell执行以下命令,下载并运行诊断脚本。
Windows节点的诊断脚本支持从所属地域下载,请根据集群所在地域替换命令行中的
[$Region_ID]。Invoke-WebRequest -UseBasicParsing -Uri http://aliacs-k8s-[$Region_ID].oss-[$Region_ID].aliyuncs.com/public/pkg/windows/diagnose/diagnose.ps1 | Invoke-Expression预期输出如下,表示收集诊断信息成功。
INFO: Compressing diagnosis clues ... INFO: ...done INFO: Please get diagnoses_1514939155.zip for diagnostics说明diagnoses_1514939155.zip文件会保存在脚本执行时所在目录。
如何排查ACK集群出现的问题?
1、检查集群节点
执行以下命令,查看集群中的节点状态,确认所有的Node节点都存在并且状态是Ready。
执行以下命令,查看节点上的详细信息以及节点上的事件。
替换
[$NODE_NAME]为您的节点名称。kubectl describe node [$NODE_NAME]说明关于kubectl输出的信息解析,请参见Node status。

2、检查集群组件
如果检查完集群Node节点后仍然无法确认问题,请继续在控制平面上检查集群组件日志。
执行以下命令,查看kube-system命名空间下所有的组件。
kubectl get pods -n kube-system预期输出如下。
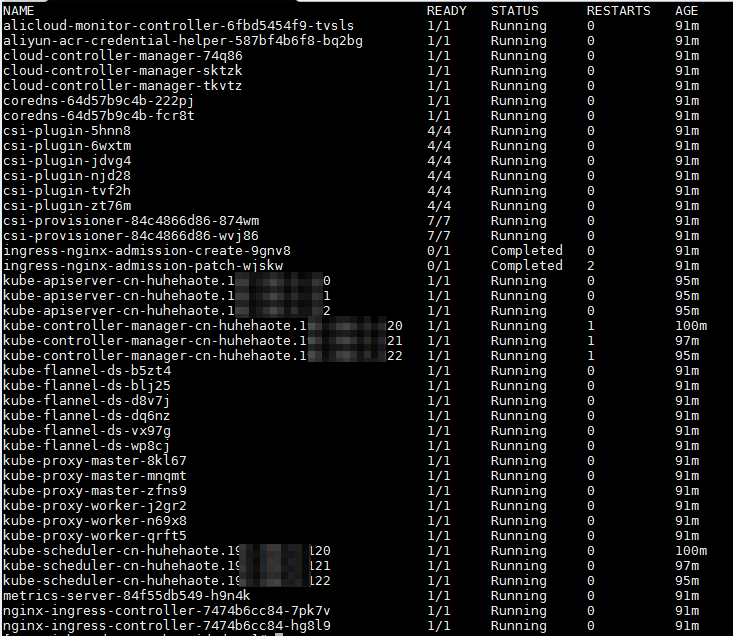 其中,以kube-开头的Pod都是Kubernetes集群的系统组件,coredns-开头的是DNS插件。预期输出表明,组件状态正常。如果组件状态异常,请执行下一步。
其中,以kube-开头的Pod都是Kubernetes集群的系统组件,coredns-开头的是DNS插件。预期输出表明,组件状态正常。如果组件状态异常,请执行下一步。执行以下命令,查看其日志信息,定位并解决问题。
替换
[$Component_Name]为异常组件名称。kubectl logs -f [$Component_Name] -n kube-system
3、检查kubelet组件
执行以下命令,查看kubelet的运行状态。
systemctl status kubelet如果您的kubelet运行状态不是active (running),那么您需要执行以下命令,进一步查看kubelet的日志,定位并解决问题。
journalctl -u kubelet
集群常见问题
下表罗列了一部分ACK集群常见的故障原因以及处理方法。
故障场景 | 处理方法 |
API Server组件停止或Master组件停止:
| ACK组件本身有一定高可用的功能,建议您查看组件本身是否有异常。例如,ACK集群的API Server默认使用CLB实例,您可以排查CLB状态异常的原因。 |
API Server后端数据丢失:
| 若您创建了快照,在出现问题时,可以通过快照恢复正常的数据。若没有创建快照,可联系我们。问题解决后,请参见以下方法预防该问题:
|
个别节点关机,即该节点上的所有Pod不再运行。 | 使用Deployment、StatefulSet、DaemonSet等工作负载创建Pod,而不是直接创建Pod,避免Pod无法调度到其他正常节点。 |
kubelet组件故障:
|
|
人为配置或其他问题。 | 若您创建了快照,在出现问题时,可以通过快照恢复正常的数据。若没有创建快照,请联系我们反馈问题。问题解决后,周期性地为kubelet软件所使用的数据卷创建快照。详细信息,请参见为单个云盘存储卷创建快照。 |
使用RAM用户操作ACK集群时,如何进行精细化授权?
默认情况下,RAM用户或RAM角色没有使用云服务OpenAPI的任何权限,您需要为其授予容器服务的系统权限AliyunCSFullAccess或所需的自定义权限才能使用ACK并管理ACK集群,请参见使用RAM授予集群及云资源访问权限。
基于Kubernetes RBAC机制,需使用RBAC为集群内资源操作授权,RAM用户才能管理集群的内部资源,例如创建Deployment、Service等。
针对需要细粒度控制资源读写权限的场景,请参见使用自定义RBAC限制集群内资源操作通过自定义ClusterRole和Role实现更精细化的RBAC权限配置。
使用RAM用户访问控制台时,还需配置对应的云服务权限后才能正常使用,例如通过控制台查看节点池伸缩活动、查看集群监控大盘等,请参见容器服务控制台权限依赖。
配置集群API Server的SLB访问控制策略时需要放行哪些IP网段?
API Server的SLB的ACL控制规则必须放行以下网段。
容器服务 Kubernetes 版管控的网段100.104.0.0/16。
集群专有网络VPC的主网段及附加网段(如有),或集群节点所在的交换机vSwitch网段。
用户侧需访问API Server连接端点的客户端出口网段。
除放行以上网段之外,ACK Edge集群还需要放行边缘节点出口网段。
除放行以上网段之外,ACK灵骏集群还需要放行灵骏VPD网段。
详细信息,请参见配置API Server的访问控制策略。
ACK托管集群的控制面是如何确保高可用的?
ACK托管集群的控制面由阿里云侧托管,并提供节点与节点池、工作负载、负载均衡等数据面维度的高可用推荐配置,以构建稳定、安全、可靠的集群和应用架构,详情请参见集群高可用架构推荐配置。
ACK托管集群的API Server域名能否跨VPC解析?
ACK集群的API Server域名(apiserver.<cluster-id>.<region-id>.cs.aliyuncs.com)默认通过内网DNS解析(PrivateZone)解析,其解析记录仅在集群所在的VPC内生效,无法在另一个VPC中被正常解析。
为何ACK托管集群的API Server域名解析失败?
ACK会将ACK托管集群的API Server域名注册到内网DNS解析(PrivateZone)。当节点使用自定义DNS服务器,即非阿里云默认的100.100.2.136和100.100.2.138时,可能出现API Server域名解析失败的问题。
此时,需将API Server域名(apiserver.<cluster-id>.<region-id>.cs.aliyuncs.com)解析上游服务器(Upstream)设定为100.100.2.136和100.100.2.138。
如果自定义DNS服务器与ACK托管集群处于不同VPC,请进一步提交工单完成跨VPC解析配置。
ACK托管集群API Server自动创建的CLB实例是否支持复用?
不可以。API Server的内网CLB是访问控制面的核心入口,专用于API Server。任何复用或修改该CLB实例配置(如添加监听、修改后端服务器组等)的操作,都可能导致API Server访问异常,进而影响整个集群的稳定性。请勿对该CLB实例进行任何修改。
如何访问Master节点?
ACK专有集群:具体操作,请参见通过SSH连接ACK专有集群的Master节点。
ACK托管集群:ACK托管集群下控制面节点完全托管,您无法登录到控制面节点的终端。如果需要登录到控制面节点,您可以考虑使用ACK专有集群。
误删了ACK专有集群的一个Master节点后,还能升级集群吗?
不能。删除ACK专有集群的Master节点后,无法添加Master节点,也无法进行集群的版本升级。您可以重新创建ACK专有集群(已停止新建)。
ACK专有集群的Master节点可以移除或新增吗?有哪些是高危操作?
不可以。自行增加或减少ACK专有集群的Master节点都可能导致集群无法使用,且不可恢复。
对于ACK专有集群的Master节点,错误的操作可能导致Master节点不可用,甚至集群不可用。自行更换Master或etcd 证书、自行修改核心组件、删除或格式化节点/etc/kubernetes等核心目录数据、重装操作系统等均属于高危操作,详情请参见集群相关高危操作。
ACK专有集群API Server提示api/v1/namespaces/xxx/resourcequotes": x509: certificate has expired or is not yet valid: current time XXX is after xxx怎么办?
问题现象
当您在ACK专有集群中创建Pod时,API Server返回证书过期的错误,或kube-controller-manager的日志或Event中显示证书过期的错误。报错信息如下。
"https://localhost:6443/api/v1/namespaces/xxx/resourcequotes": x509: certificate has expired or is not yet valid: current time XXX is after XXX"https://[::1]:6443/api/v1/namespaces/xxx/resourcequotes": x509: certificate has expired or is not yet valid: current time XXX is after XXX问题原因
在Kubernetes中,API Server内置了用于其内部LoopbackClient服务端工作的证书。该证书在社区版本中有效期为1年且无法自动轮转,只有当API Server Pod发生重启时,才会自动轮转更新。如果Kubernetes版本长时间未升级(超过 1 年),内部证书会过期,导致 API 请求失败。详细信息,请参见#86552。
为了降低社区版本中证书有效期较短带来的稳定性风险,ACK在1.24及以上版本的集群中调整了该内置证书的默认过期时间,有效期延长至10年。具体变更内容及影响范围请参见【产品变更】ACK集群API Server内部证书有效时长变更公告。
解决方案
您可以登录Master节点,执行以下命令,查询LoopbackClient证书过期时间。
其中,XX.XX.XX.XX为Master节点的本地IP。
curl --resolve apiserver-loopback-client:6443:XX.XX.XX.XX -k -v https://apiserver-loopback-client:6443/healthz 2>&1 |grep expire对于已过期或即将过期的1年期证书集群,请参见手动升级集群将集群升级至1.24或以上版本。推荐迁移至ACK托管集群Pro版(热迁移ACK专有集群至ACK托管集群Pro版)。
对于短期无法操作升级的ACK专有集群,请逐一登录Master节点,手动重启API Server,以生成新的有效证书。
containerd节点
crictl pods | grep kube-apiserver- | awk '{print $1}' | xargs -I '{}' crictl stopp {}Docker节点
docker ps | grep kube-apiserver- | awk '{print $1}' | xargs -I '{}' docker restart {}