
应用结构
数据推送到行业算法版后会先保存到离线数据表中,在此阶段,为了方便用户推送数据,数据表允许用户根据实际业务场景定义多个表(需要指定关联字段),并提供了数据处理的插件。数据处理完毕后会join成一张索引表,这种索引表主要定义搜索属性,供引擎构建索引及查询使用。
数据表字段
数据表主要用于数据导入,不同的数据处理插件对类型有不同的要求。具体字段取值范围,请参见使用限制-字段相关部分说明。超过取值范围将溢出或者截断,请务必保证选择类型正确。
|
类型 |
说明 |
|
INT |
int64整型 |
|
INT_ARRAY |
int64整型数组 |
|
FLOAT |
浮点型 |
|
FLOAT_ARRAY |
浮点型数组 |
|
DOUBLE |
浮点型 |
|
DOUBLE_ARRAY |
浮点型数组 |
|
LITERAL |
字符串常量,仅支持精确匹配 |
|
LITERAL_ARRAY |
字符串常量数组,单个元素仅支持精确匹配 |
|
SHORT_TEXT |
短文本,长度在100字节内,支持若干分词方式 |
|
TEXT |
长文本,支持若干分词方式 |
|
TIMESTAMP |
uint64整型,时间戳数据 |
|
GEO_POINT |
字符串常量,经纬度字段,格式为:”经度 纬度” |
|
用于表示JSON对象数组,采用扁平化(Flattened)存储,丢失对象边界。 |
|
|
用于表示JSON对象数组,采用主子文档独立存储,保留对象完整性。 |
保留字段说明:
-
[‘service_id’, ‘ops_app_name’, ‘inter_timestamp’, ‘index_name’, ‘pk’, ‘ops_version’, ‘ha_reserved_timestamp’,‘summary’] 这些字段名称为保留字段,暂时无法作为字段名称配置。
ARRAY数组类型说明:
-
如果应用字段创建为ARRAY类型,数据源字段映射时,该字段可以关联varchar/string(字符串类型),并使用数据源插件说明解析数据源字段。
-
若该ARRAY类型字段使用API/SDK推送,则请按数组类型推送,不要按string推送。如:String[] literal_array = {“阿里云”,”开放搜索”};
时间戳字段说明:
-
INT和TIMESTAMP类型可以映射数据源字段中的datetime/timestamp字段,会自动将其转化为毫秒数。搜索时可以通过range,按时间区间过滤召回。
支持的数据源字段类型
|
数据源 |
支持的字段类型 |
|
RDS |
TINYINT,SMALLINT,INTEGER,BIGINT,FLOAT,REAL,DOUBLE,NUMERIC,DECIMAL,TIME,DATE,TIMESTAMP,VARCHAR |
|
PolarDB |
TINYINT,SMALLINT,INTEGER,BIGINT,FLOAT,REAL,DOUBLE,NUMERIC,DECIMAL,TIME,DATE,TIMESTAMP,VARCHAR |
|
MaxCompute(原odps) |
BIGINT,DOUBLE,BOOLEAN,DATETIME,STRING,DECIMAL,MAP,ARRAY,TINYINT,SMALLINT,INT,FLOAT,CHAR,VARCHAR,DATE,TIMESTAMP,BINARY,INTERVAL_DAY_TIME,INTERVAL_YEAR_MONTH,STRUCT |
行业算法版表的字段类型与数据库表的字段类型的对应关系
|
行业算法版表 |
RDS表 |
PolarDB表 |
MaxCompute(原odps)表 |
|
INT |
BIGINT,TINYINT,SMALLINT,INTEGER |
BIGINT,TINYINT,SMALLINT,INTEGER |
BIGINT,TINYINT,SMALLINT,INT |
|
INT_ARRAY |
VARCHAR、STRING等字符串类型,需用数据源插件MultiValueSpliter转换 |
VARCHAR、STRING等字符串类型,需用数据源插件MultiValueSpliter转换 |
VARCHAR、STRING等字符串类型,需用数据源插件MultiValueSpliter转换 |
|
FLOAT |
FLOAT,NUMERIC,DECIMAL |
FLOAT,NUMERIC,DECIMAL |
FLOAT,DECIMAL |
|
FLOAT_ARRAY |
VARCHAR、STRING等字符串类型,需用数据源插件MultiValueSpliter转换 |
VARCHAR、STRING等字符串类型,需用数据源插件MultiValueSpliter转换 |
VARCHAR、STRING等字符串类型,需用数据源插件MultiValueSpliter转换 |
|
DOUBLE |
DOUBLE,NUMERIC,DECIMAL |
DOUBLE,NUMERIC,DECIMAL |
DOUBLE,DECIMAL |
|
DOUBLE_ARRAY |
VARCHAR等字符串类型,需用数据源插件MultiValueSpliter转换 |
VARCHAR等字符串类型,需用数据源插件MultiValueSpliter转换 |
VARCHAR、STRING等字符串类型,需用数据源插件MultiValueSpliter转换 |
|
LITERAL |
VARCHAR等字符串类型 |
VARCHAR等字符串类型 |
VARCHAR、STRING等字符串类型 |
|
LITERAL_ARRAY |
VARCHAR等字符串类型,需用数据源插件MultiValueSpliter转换 |
VARCHAR等字符串类型,需用数据源插件MultiValueSpliter转换 |
VARCHAR、STRING等字符串类型,需用数据源插件MultiValueSpliter转换 |
|
SHORT_TEXT |
VARCHAR等字符串类型 |
VARCHAR等字符串类型 |
VARCHAR、STRING等字符串类型 |
|
TEXT |
VARCHAR等字符串类型 |
VARCHAR等字符串类型 |
VARCHAR、STRING等字符串类型 |
|
TIMESTAMP |
datetime/timestamp类型 |
datetime/timestamp类型 |
datetime/timestamp类型 |
|
GEO_POINT |
VARCHAR等字符串类型 |
VARCHAR等字符串类型 |
VARCHAR、STRING等字符串类型,格式为: lon lat。lon表示经度,lat表示纬度,都为double类型,二者之间用空格分隔。lon的范围: [-180, 180], lat范围[-90, 90]。 |
注意:
-
数据源字段数据类型如果是FLOAT或DOUBLE类型,建议改为DECIMAL类型,否则可能会出现精度不正确的情况。
创建应用结构方式介绍
行业算法版提供如下4种方式创建应用结构(行业算法版的表结构):
-
通过数据源的方式创建(RDS、MaxCompute、PolarDB);
-
手动创建(请参考下面的配置多表JOIN);
配置多表JOIN
这里以手动创建的方式介绍如何配置多表join,以两张表为例:main(主表)、test_tb_1(辅表):
-
登录控制台,点击配置:在Ha3引擎页面的应用列表中,找到目标应用,单击其操作列的配置。
-
选择主表,设置主表主键:
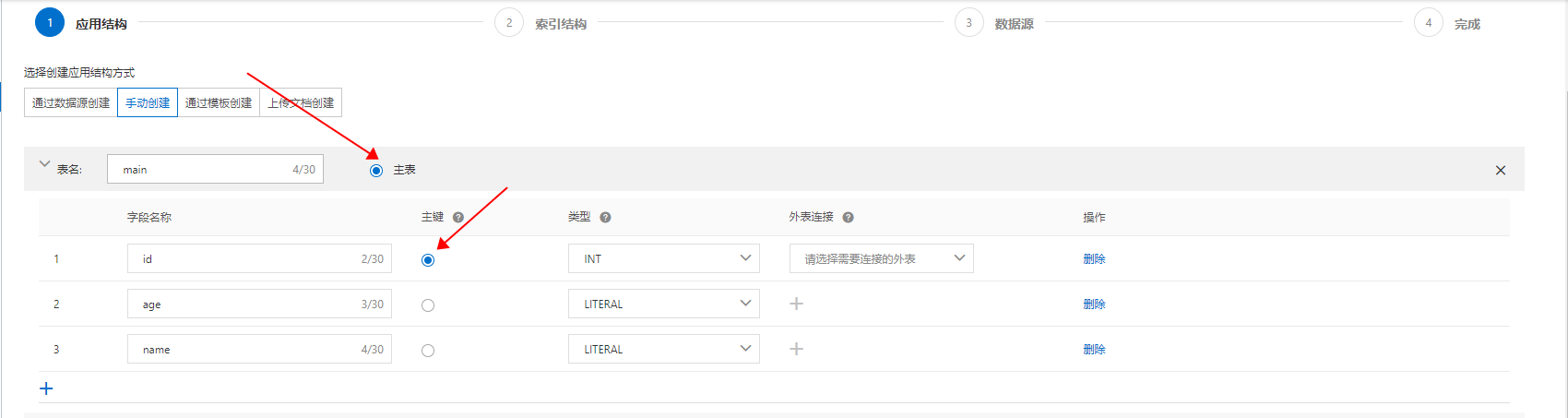
-
设置辅表主键:

-
设置主辅表关联关系(在主表里设置):
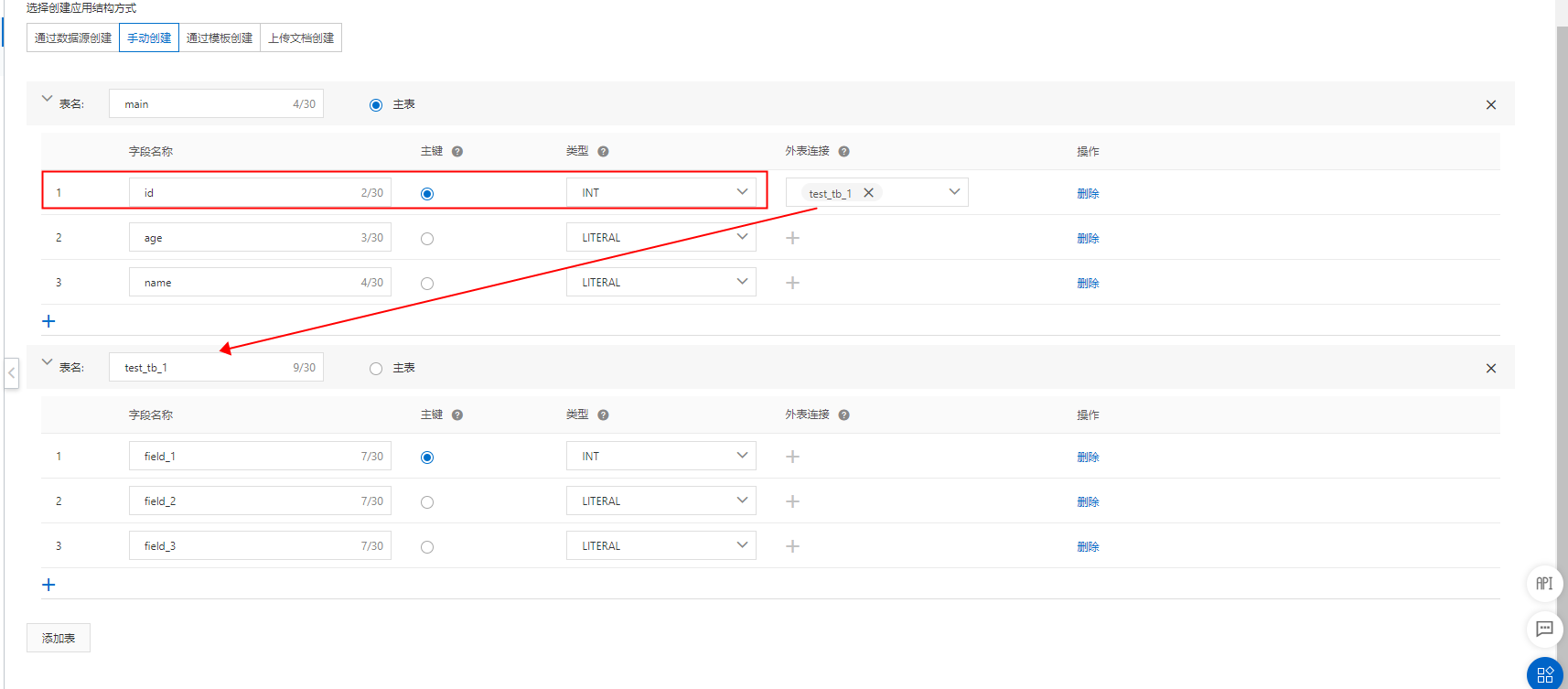
-
行业算法版支持的主辅表数据关联关系可参考创建多表join。
-
只有int 或 literal字段类型可以做关联字段。
-
主辅表join时,join的字段必须类型相同,要是int都是int,要是literal都是literal。
-
辅表join主表时,必须用辅表的主键join主表的某个字段,不能用辅表的非主键字段join主表。